Értékelések
Nincs még értékelés. Legyél Te az első!
Mit olvastak a többiek, ha ezzel végeztek?





Tartalmi kivonat
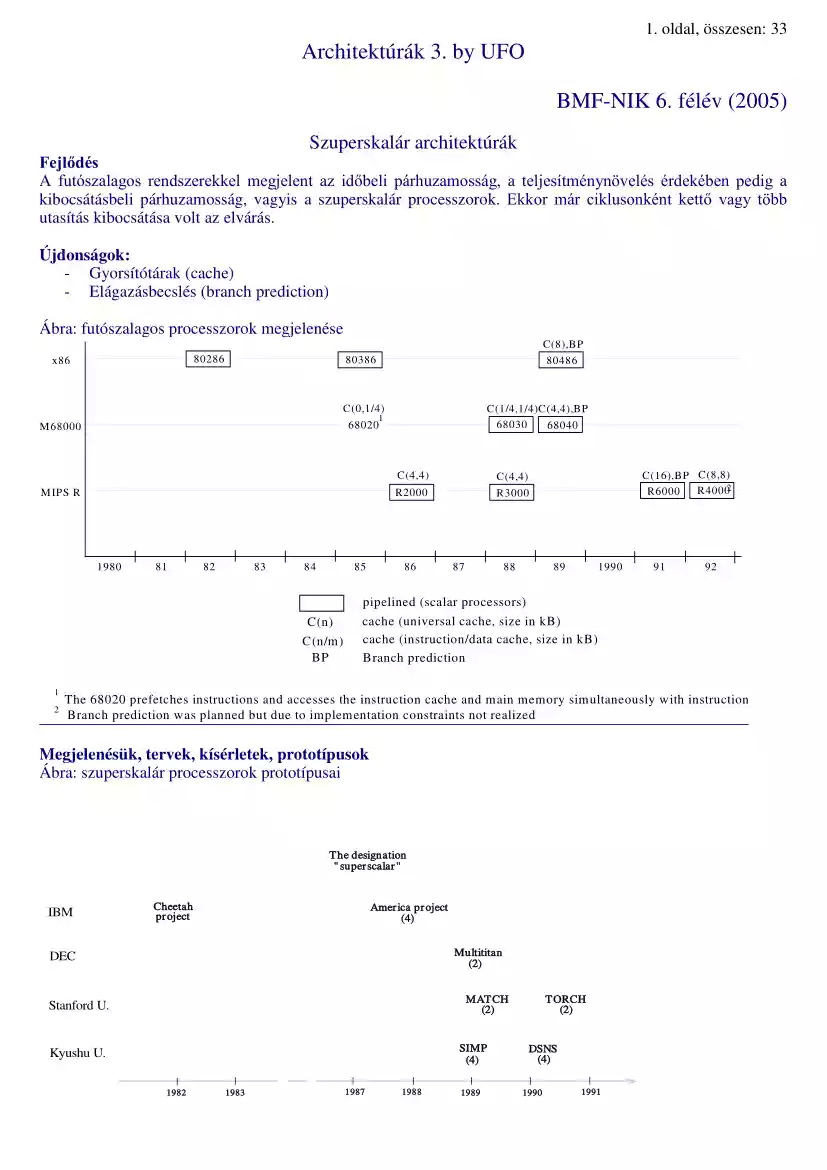
1. oldal, összesen: 33 Architektúrák 3. by UFO BMF-NIK 6. félév (2005) Szuperskalár architektúrák Fejlődés A futószalagos rendszerekkel megjelent az időbeli párhuzamosság, a teljesítménynövelés érdekében pedig a kibocsátásbeli párhuzamosság, vagyis a szuperskalár processzorok. Ekkor már ciklusonként kettő vagy több utasítás kibocsátása volt az elvárás. Újdonságok: - Gyorsítótárak (cache) - Elágazásbecslés (branch prediction) Ábra: futószalagos processzorok megjelenése 80286 x86 C(8),BP 80486 80386 C(0,1/4) M IPS R 1980 81 82 83 84 85 C(n) C(n/m) BP 1 2 C(1/4,1/4)C(4,4),BP 68030 68040 1 68020 M 68000 C(4,4) C(4,4) R2000 R3000 86 87 88 C(16),BP C(8,8) R40002 R6000 89 1990 91 92 pipelined (scalar processors) cache (universal cache, size in kB) cache (instruction/data cache, size in kB) Branch prediction The 68020 prefetches instructions and accesses the instruction cache and main memory simultaneously with
instruction Branch prediction was planned but due to implementation constraints not realized Megjelenésük, tervek, kísérletek, prototípusok Ábra: szuperskalár processzorok prototípusai The designation " super scalar " IBM Cheetah pr oject Amer ica pr oject (4) Multititan (2) DEC Stanford U. MATCH (2) Kyushu U. SIMP (4) 1982 1983 1987 1988 1989 TORCH (2) DSNS (4) 1990 1991 2. oldal, összesen: 33 az IBM már a 80-as évek elején kísérletezett a szuperskalár architektúrákkal (ekkor jelent meg elsőként ez a kifejezés - 1987), s amikor látszott, hogy a futószalag elv a végét járja, gőzerővel indult be a fejlesztés (America Project – RS/6000) - A DEC volt a világ második legnagyobb számítógépgyártója, erősségeit a kisszámítógépek jelentették (PDP8, PDP11, VAX) - MultiTitan kétszeres kibocsátású prototípus rendszer volt - Stanford: kétszeres kibocsátású, statikus ütemezésű szuperskalár processzor, amelyben a
végrehajtandó utasításokat egy globális ütemező rendezte előzetesen megfelelő sorrendbe. Megjelenésük a kereskedelmi rendszerekben - Ábra: szuperskalárok megjelenése (a 'négyzetnélküliek' futószalagosak, a 'négyzetesek' szuperskalárok) RISC processors Intel 960 960KA/KB M 88000 MC 88100 960CA (3) MC 88110 (2) HP PA PA 7000 PA7100 (2) SPARC MicroSparc SuperSparc (3) R 4000 MIPS R R 8000 (4) 29040 29000 sup (4) Am 29000 Power1(4) RS/6000 IBM Power α 21064(2) DEC α PPC 601 (3) PPC 603 (3) PowerPC 88 89 90 91 92 93 94 95 CISC processors i486 Intel x86 Pentium(2) M 68040 M 68000 M 68060 (2) Gmicro/100p Gmicro Gmicro500(2) AMD K5 K5 (4) CYRIX M1 M1 (2) Denotes superscalar processors. RISC - Az Intel 960CA az első kereskedelmi forgalomba került szuperskalár volt, azonban beágyazott rendszerekbe (szerverekbe) készült - Az első, asztali rendszerekbe szánt szuperskalár a Power1 volt - A SPARC 2 évvel a
tervezettnél később jelent meg, ezért, a teljesítménye nem volt kielégítő, megbukott - DEC Alpha21064: 64bites rendszer, kétszeres kibocsátás, a kiöregedett VAX helyett - Motorola, MIPS: túl későn - Am29000: beágyazott CPU. Az eddig készült processzorok egy meglévő processzor szuperskalárosításával keletkeztek, a későbbiek azonban eleve szuperskalár feldolgozást feltételező, új architektúrák (DEC, IBM) CISC - csak később váltak szuperskalárokká, amelynek kettős oka van: o Komplexebb technológia, mivel a memóriaarchitektúrájú CISC processzorok csak jóval nagyobb ráfordítással valósíthatók meg, mint a RISC LOAD/STORE architektúrák o Változó hosszúságú utasításokat kell dekódolniuk, ezért nehéz megoldani a ciklusonkénti több utasítás-lehívást (ezért a CISC-ek vékonyabbak, tipikusan 2 és 4) - 1993-ban jelentek meg az első szuperskalár CISC-ek: o Motorola MC 68060, Pentium: egy már meglévő skalár CISC család
szuperskalár modelljei o Cyrix M1, AMD K5: eleve szuperskalárnak tervezték őket o A legtöbb CISC processzort (Pentium, K5, Nx586, K5) egy szuperskalár RISC maggal valósították meg, amelyre a négyszeres kibocsátás jellemző. 3. oldal, összesen: 33 Fejlődésük áttekintése - generációk Super scalar s Features: Width: Core: Caches: Fir st gener ation ("Thin superscalars") Second gener ation ("Wide superscalars") 2-3 RISC instructions/cycle or 2 CISC instructions/cycle "wide" 4 RISC instructions/cycle or 3 CISC instructions/cycle "wide" No predecoding Predecoding Static branch prediction Unbuffered issue No renaming No ROB Dynamic branch prediction Buffered issue (shelving) Renaming ROB Single ported data caches Blocking L1 data caches or nonblocking caches with up to a single pending cache miss allowed Off-chip L2 caches attached via the processor bus Dual ported data caches Nonblocking L1 data caches with multiple
cache misses allowed ISA: Examples: Off-chip direct coupled L2 caches Alpha 21064 1 Alpha 21264 PA 7100 PA 8000 SuperSparc Power2 3 PowerPC 604 PowerPC 620 1,4 1,4 UltraSparc I, II Pentium 2 Pentium Pro K6 1 On-chip L2 caches FX- and FP-SIMD instructions No MM/3D support PowerPC 601 Thir d gener ation ("Wide superscalars with MM/3D support") Power 4 Pentium III (0.18 µ) Pentium 4 Athlon (model 4) Athlon MP (model 6) No renaming. 2 Optionally dynamic branch prediction is also supported, futhermore the Pentium has a dual ported data cache. 3 No off-chip direct coupled L2. 4 Only single ported data cache. - - - Első generáció: vékony szuperskalárok (kb. 1990) o A kibocsátási rátájuk: maximum 2-3 utasítás perc ciklus, CISC esetén csak 2-es o Kibocsátási szűk keresztmetszet: az adatfüggőségek miatt az utasítások kibocsátásakor korlátba ütközünk, mivel a kibocsátás direkt (nem pufferelt). Így csak a független utasításokat lehet
kibocsátani, ilyen pedig alapból kevés van. Ezért jellemzően csak 2-es szélességű, a nagyobb nem lenne kihasználva. o Ezért egy adatcache elég: a LOAD-STORE aránya 40% körül van. o Az L2 a CPU buszán van o A fejlesztés útja: a szélességet bővíteni. Megoldás: a pufferelt kibocsátás és a regiszter átnevezés Második generáció (kb. 1995) o Elődekódolás, ROB, nemblokkoló cache o L2 dedikált sínen o Jellemzően 4-es szélesség o Az általános célú alkalmazásokban lévő párhuzamosság kihasználása ezzel kimerült Harmadik generáció (kb. 2000, P3-P4) o Általános célú alkalmazásokban nem hoz teljesítmény-növekedést, de a speciális célú alkalmazásokban többletet jelent (multimédia) o SIMD (Single Instruction Multiple Data): a fixpontos SIMD a 2,5. generáció (P2, kb 1997) o FX/FP SIMD: az igazi harmadik generáció (MM+3D) (ehhez a logikai architektúra bővítésre szorult) o A CPU lapkáján van az L2 cache. Kétportos cache-re van
szükség, mert a szimpla már kevés - 4. oldal, összesen: 33 1995-ben következett be a RISC-ek CISC-ekbe történő átmenete. Ennek oka, hogy eddig a RISC-ek voltak gyorsabbak (különösen a DEC processzorok), 2000-re azonban a CISC-ek már egyértelműen átvették a vezetést A RISC processzorok élete - A szóhossz vonatkozásában o A szóhossz növekedése jelentette a fejlődés alapvető irányvonalát (az első mikropocesszor: Intel 4004 = 4 bit). A szuperskalároknál a DEC gyártott elsőként 64 bites CPU-t; ekkor a legtöbb processzor 32 bites volt o Architektúra: PA RISC, CPU: R8000 (szuperskalárosított) o A 32 bites RISC-ekből szuperskalár és a szuperskalárosított CPU-k léteztek. Ezek a kilencvenes évek végére egységesen 64 bitesekké váltak. o A CISC-ek döntő többsége 32 bites volt, egészen 2000-ig, amikor az AMD 64 bites szóhosszal egészítette ki az x86 architektúrát Ábra: Az FX-SIMD és az FP-SIMD utasítások összeolvadása a
mikroprocesszorok esetében RISC processors Compaq/DEC Alpha Alpha 21064 84 83 85 Alpha 21164 21164PC 125 2126486 Alpha 21364 87 Motorola MC 88000 HP PA IBM Power Power PC Alliance PowerPC MC88110 PA7100 Power1(4) 89 88 PA-7100LC 193 Power2(6/4) PPC 601 (3) PPC 603 (3) MIPS R Sun/Hal SPARC PA-7200 90 PA8000 94 96 PPC 604 (4) 97 PPC 602 (2) 98 91 P2SC(6/4) 104 PPC 620 (4) R 10000 107 91 101 100 99 R 80000 126 PA 8500 92 102 Power3 (4) G3 (3) G4 (3) 103 Power 4 113 R14000 105 R 12000 110 108 SuperSPARC PA-8200 PA 8600 PA 8700 126 95 128 129 R16000 130 118 UltraSPARC-3 UltraSPARC-3-Cu UltraSPARC-2 UltraSPARC 127 109 SPARC64 CISC processors 112 Intel Pentium 80x86 CYRIX /VIA M AMD/NexGen Nx/K 114 Pentium/MMX PentiumPro113 M1 119 Nx586 117 MII 120 1991 1992 1993 1994 118 K5 1995 1996 131 P4 10 Pentium 4 Pentium II K6 1990 116 Pentium III 115 1997 121 K6-2 122 K6-3123 1998 132
Opteron K7 1999 124 2000 2001 2002 2003 Multimedia support (FX-SIMD) Support of 3D (FP-SIMD) o Ez azért volt meglepő, mivel az Intel-HP páros szerint a 32 bites CISC CPU-kat a VLIW (EPIC) technológiának kellene leváltania. Ilyen volt az Itanium processzor, amelynek fejlesztését 1994ben kezdték meg De annak ellenére, hogy 1999-re ígérték, csak 2001-ben jelent meg, így némileg elkésett, mivel az AMD keresztülhúzta számításaikat. o Az Intel mégis tartotta magát a Merced kódnéven ismertté vált projekthez, de titokban az x86 architektúrát kiegészítő 64 bites technológián is dolgozott o 2004-ben az Intel az EMT (Extended Memory Technology) bejelentésével –ami lényegében egy x86-32/64 volt- elismerte, hogy az Itanium megbukott. Ábra: Általános célú VLIW processzorok (zárójelben a mag szélessége látható) 5. oldal, összesen: 33 Crusoe (4) TM 3120 TM 5500 TM 5800 TM 5400 Transmeta Efficeon (8) Intel TM 8600 Itanium (6) 2000
Itanium (Merced) Itanium2 (McKinley) Itanium2 (Madison) 2001 2002 2003 - Az Intel hibás víziójának megfelelően fejlesztő processzorgyártók megbuktak, kiszálltak a processzorpiacból. - DEC: Alpha 264-gyel befejeződött a fejlesztés - Motorola, HP, PPC 620, MIPS leállt - SPARC ma is versenyben van: 2004-ben a Sparc 5-öt befejezi, Niagara rendszerét továbbfejleszti (8 magos, magonként 4 szál – 2006-ra ígérik) - A RISC családból egyetlen túlélő: az IBM A CISC processzorok élete: - Cyrix beolvadt a VIA-ba, a Transmeta haldoklik - Maradt az AMD – Intel páros 2004-re 2004-es helyzet - Februárban az Intel EMT-t bejelentették, így az Itanium fejlesztése leállt; az Intel ’növeljük az egekig a frekvenciát’ politikája kudarcot vallott, ezért 3,8GHz-nél nagyobb órajelű P4 processzorra nem számíthatunk. A fizikai határt is elérték: a Prescott túllépi disszipációban a 130W-ot, így az ilyen irányú fejlesztéseknek nincs többé értelme
(fogyasztás, hűtés, zaj) - Az Intel filozófiájának (’egyszerű architektúra + nagy frekvencia’) megváltoztatására kényszerül. Azonban ugyanez kétmagos rendszer képében szintén elképzelhetetlen (2x100W kis helyen) - AZ AMD viszont 2003-tól egyre nagyobb teljesítményű rendszereket mutat be, s a piac 5 szegmenséből legalább hármat ural, teljesítmény tekintetében.(desktopmultiprocesszoros rendszerek) Kiemelten fontos szuperskalár rendszerek IBM Ábra: az IBM desktop processzorai (az ábrák tetején vastagon az ISA, vagyis az utasításszintű architektúra neve) - Alapfilozófia: legyen két nagy alkalmazási szektor: üzleti szektor (domináns, képviselője az AS/400, OS: OS/400), műszaki, tudományos szektor (RISC 6000, OS: AIX) - Azonos OS mellett a PowerPC, mint új architektúra, a kommersz alkalmazásokhoz igazodóan. Első generációs szuperskalárok: CISC-ből RISC lett, majd szuperskalár - AS/64: fejlettebb első generációs, 64 bites család
- Új filozófia: legyen definiálva egy általános architektúra, amely egyaránt használható a kommersz és a tudományos szektorban is. Ennek képviselői a Power4 (kétmagos), majd a Power5 (kétmagos, magonként kétszálas) processzorok. - PSC = Power Single Chip (Pl. Power2, amely egychipes) - A PPC64 egy subsetje a PowerPC/64, a harmadik generáció a Power3 - Az OS-ben bevezették a logikai partíciókat, amely valójában virtuális megvalósítást jelent: ugyanaz a hardver használható eltérő szoftveres konfiguráció elvégzése után. Pl OS/400 vagy AIX szimulálása 6. oldal, összesen: 33 Intel Ábra: Intel Pentium II. és III magok 3/99 10/99 ^ ^ ^ ^ Drake Tanner Cascades Tualatin 0.25 µ /75 mtrs 400/450 M Hz 0.25 µ /95 mtrs 500/550 M Hz 0.18 µ /28 mtrs 600/667/733 M Hz 0.13 µ 1.13/126 GHz Dir. 512K/1M /2M L2 (1x) 100 M Hz FSB Dir. 512K/1M /2M L2 (1x) 100 M Hz FSB On-die 256K L2 133 M Hz FSB On-die 512K L2 133 M Hz FSB 7/01 Xeon-line
(Servers/ Workstations) Desktop-line 5/97 1/98 2/99 10/99 ^ ^ ^ ^ ^ Klamath Deshutes Katmai Coppermine Tualatin-256 0.35 µ /75 mtrs 233/266/300 M Hz 0.25 µ /75 mtrs 333 M Hz 0.25 µ /95 mtrs 450/500 M Hz 0.18 µ /28 mtrs 500 - 733 M Hz 0.13 µ 1.13/12 GHz Dir. 512K L2 (05x) Dir. 512K L2 (05x) Dir. 512K L2 (05x) On-die 256K L2 66 M Hz FSB 66 M Hz FSB 100 M Hz FSB 100/133 M Hz FSB Celeron-line ("economy class" cores) 1997 - - On-die 256K L2 133 M Hz FSB 1 4/98 8/98 3/00 1/01 ^ ^ ^ ^ ^ 10/01 Covington Mendocino Coppermine-128-A Coppermine-128-B Tualatin-256 0.25 µ /75 mtrs 266 M Hz 0.25 µ /19 mtrs 300/333 M Hz 0.18 µ /28 mtrs 566/600 M Hz 0.18 µ /28 mtrs 800 M Hz 0.13 µ /44 mtrs 1.2 GHz No on-die L2 66 M Hz FSB On-die 128K L2 66 M Hz FSB On-die 128K L2 On-die 128K L2 66 M Hz FSB 100 M Hz FSB On-die 256K L2 100 M Hz FSB 1998 1999 Pentium II (M M X) 1 7/01 6/98 2000 2001 Pentium III (SSE) Coppermine cores
with 100 M Hz FSB are tagged by E, whereas those running at 133 M Hz with EB. (Katmai cores are designated by B) Pentium, majd 1995-ben Pentium Pro, amely az alapját képezte a PII-PIII-nak, P4: gyökeres váltás 1997: Klamath, majd azonos felépítés mellett 0,25 mikron, magasabb órajel Economy class – kisebb teljesítményű CPU-k: a meglévő magot meghagyták, de a cache méretét és sebességét, illetve az FSB-t csökkentették Celeron Convington: ha a gyártás során az L2-cache rossznak bizonyul, letiltják és felcímkézik Celeronnak Mendocino: nagyobb tranzisztorszám, a cache miatt. A mag lebutításával 40% teljesítménycsökkenés következett be, s így az AMD-K6-2-vel már nem volt versenyképes. (ezzel semmiképp' sem értek egyet) A fejlesztések iránya általában felülről lefelé mutatott (Xeondesktop) Xeon Drake: nagyobb cache, egyszeres L2 sebesség, slot2, 100MHz rendszerbusz MMX: gyenge fejlesztés, a lebegőpontos regiszterek használata
miatt Katmai: több tranzisztor, nagyobb órajel. Coppermine: 28m tranzisztor, az on-die cache megjelenése 0,18 mikronos Celeron: ismét ugyanaz a mag, mind a három célú processzorban (jelentős árkülönbséggel) Ábra: Intel Pentium 4 magok (a Netburst architektúra megvalósításai) - 2000. november: Netburst architektúra, Willamette mag, a P3 0,13-al zárult, ez mégis 0,18-ról indul On-die 256K, 400MHz FSB, min. egyharmad FSB kell az órajelhez, hogy ne legyen szűk keresztmetszet, SSE2: kibővített utasításkészlet Új S478 tokozás, on-die cache, a jobb tápellátás érdekében A korábban használt cache slotot -amelyhez külön buszra volt szükség-, felváltotta a direkt csatolású cache Northwood: o minél nagyobb frekvencia, 1 év alatt 2-ről 3GHz-re o 512 Kb cache, több tranzisztor, később 800MHz-es FSB Northwood B: o Megjelenik a HyperThreading, ami egymagos, kétszálas processzort takar. Így 5%-os többlethardver segítségével 10-20%
teljesítménytöbbletet sikerült elérni. Xeon: 603 tokozás, Xeon MP-kisebb L2, de nagy L3 cache P4 Celeron tranzisztorszám ugyanannyi, mint a P4-é, ezért nem is publikálják ezt az adatot A Prescott-ban benne volt a 64bites kiterjesztés -ezt mutatja 125 milliós tranzisztorszám-, de nem volt aktiválva. Később a Prescott F-ben már igen - 7. oldal, összesen: 33 LGA 775-ös tokozás: a korábban megszokott tüskék az alaplapra kerülnek, így a processzor kevésbé sérülékeny, az alaplap így drágább lesz, a processzorcsere pedig bonyolultabbá válik. (2004 nyara) Pentium 4 Extreme Edition: workstation-ökre, nagyobb FSB és cache Az ábrán lévő Potomac típus és az áthúzottak fejlesztését leállították. A netburst architektúra pedig zsákutcát jelent a túlzott disszipáció miatt. AMD Ábra: Az AMD Opteron vonala - Opteron: az első szám a processzorok száma, a második az órajel - Direkt-csatolt memória rendszer: a memória rajta van a chipen,
csak 80W-ot fogyaszt - A Hypertransport busz megemelve 1066-ra, 90W-os fogyasztás - Athlon64 FX: egylinkes HT, kétcsatornás memóriavezérlő (a szerverpiacra) - Athlon64: egycsatornás memóriavezérlő, 3,5Ghz-es számozástól kétcsatornás (desktop). Módosítani kellett a socket-et is. A 939 lett az egységes socket, minden felhasználáshoz Ábra: Az AMD Athlon64 FX és Athlon64 vonala Szuperskalár processzorok megvalósítása Tervezési tér - Utasítás-lehívás (instruction fetch) - Dekódolás - Utasítás-kibocsátás (issue) - Párhuzamos végrehajtás (execution) - A szekvenciális konzisztencia biztosítása, az utasítások végrehajtásának szempontjából (pertaining sequential consistency regarding of instruction processing) - A szekvenciális konzisztencia biztosítása a megszakítások kezelésének szempontjából ( interrupt processing) Szekvenciális végrehajtás esetén az első négy jelen van, s ezek mindegyike párhuzamos jellegű. A szekvenciális
konzisztencia biztosítása - elvárjuk, hogy az utasítások a programozásnak megfelelő logikai sorrendben hajtódjanak végre úgy, mintha a processzor szekvenciálisan működne - szuperskalárok esetén ennek biztosítására szolgál az utasításpuffer. Az utasításokat ide hívjuk le: például egyszerre hármat, ha a dekódoló egyszerre hármat képes dekódolni. Így három VE párhuzamos működése biztosított, azonban a végrehajtás sorrendje eltér az utasítások szekvenciális sorrendjétől, mivel a CPU az állapotteret eltérően módosítja (memória, regiszterek). A szekvenciális konzisztencia biztosításának eszköze: ROB (ReOrder Buffer) - Ez lényegében egy kör alakú puffer: egy körív mentén az adott [(i) (i+n)]-edik utasítások azonosítói helyezkednek el. A programállapot módosítását csak szekvenciálisan engedi meg úgy, hogy egy utasítás által előírt memória -és regiszterutasításokat csak akkor engedélyezi, ha minden előtte
lévő utasítás már teljesen végrehajtódott, s eredményeik már ki vannak már írva a tárba. 8. oldal, összesen: 33 A megszakítás-kezelés - A feldolgozás során történhetnek események, megszakítások. Ezeket addig kell várakoztatni, amíg a vonatkozó utasítás nem kerül soros végrehajtásra. Ha egyből érvényre jutna, egy olyan állapot állna elő, amely bizonytalanságot szülne, például egy félig feldolgozott utasítás miatt. Utasítás-lehívás - nem tárgyaljuk az előlehívást (prefetching) és az utasításpuffer feltöltésének módját - nem tárgyaljuk az elágazás-kezelés megvalósításait, csak egy gyakran használt eljárást A feldolgozás elve PC – Program Counter. Initial PC – kell egy kezdeti PC érték BTA – Branch Target Address: gondoskodni kell az ugrási cím értékeiről - Prefetch esetén: IFP – Instruction Fetch Pointer: az utasításcache-ből az utasításpufferbe kerül az utasítás, majd a dekódolás
következik Elágazás-kezelés: - az elágazási cím meghatározása o a BTA cím kiszámítása: PC := (PC) + Delta //Delta = 1/4/16 o szuperskalároknál ilyen nincs, de BTAC van (Branch Target Address Cache) o nem szükséges a címet kiszámítani. Ha tudjuk, hogy milyen cím után mire fog ugrani Pl a ciklusokban előforduló utasítások esetén, a címszámítás után tároljuk a címet, s ezt használjuk fel o Előny, hogy az elágazások 70-80%-a ciklusokból származik o Elve: BTAC Vegyünk egy asszociatív struktúrát BA-ról ugrani kell BTA-ra A keresés a tartalom szerint történik, párhuzamos jelleggel Ezt beiktatva az előző rendszerbe, így megvan a működés alapelve. Megnézheti, hogy később lesz-e elágazás, s az új címet tárolhatja el A következő cím vizsgálata történik meg, időben párhuzamosan. Lesz-e a következő címre ugrás. Ha nem, akkor időkésés nélkül kezeli Mivel asszociatív, csak azokat a címeket
tartalmazza, ahonnan az elágazásbecslés elágazást jósol - Elágazásbecslés o BH (Branch History): feltételezünk egy kétbites, dinamikus elágazásbecslést o Elágazás-becslési eljárások: Statikus (egyszerűbb) eljárások: a kód alapján dönti el, hogy lehetséges-e elágazás. Ha egy utasításban a D értéke negatív, akkor ez feltehetően egy cikluszáró utasítás, vagyis elugrás következhet be. JC = Jump Conditional, D: Displacement (eltolás), F: feltétel, B: Base (az egész egy utasítás) Dinamikus (komplexebb, hatékonyabb) eljárások: Az elágazás-történetből, vagyis a múltbeli eseményekből lesz levezetve. • 1-bites eljárás: ha az előző ugrás teljesült, akkor valószínűleg ez is fog. • 2-bites eljárás (Smith-eljárás): Négy lehetséges állapot. Kiindul egy kezdőértékből, pl. 00-ból, és vizsgálja az egymást követő eljárások teljesülését Telített számlálóként működik. Ha teljesül, jobbra megy, ha
nem, balra Állapotdiagram: ha az állapot 10 vagy 11, akkor a következő is teljesülni fog. Ha 00 vagy 01, akkor az ugrás nem fog teljesülni. Ugrási címenként kell egy-egy négybites számláló. (a Pentium Pro-tól napjainkig) Az eljárás finomítása: bevezetnek egy kétszintes elágazásbecslést. Az eddigi lokális történet volt, ez most a globális történet változata (nem tárgyaljuk) Megvalósítása: BHT (Branch History Table): • asszociatív struktúra • az aktív elágazási címek vannak tárolva, • vagyis azok, ahonnan elágazásokat detektáltunk • felismeri, ha nem ugrási cím kell, hanem egy eltárolt cím 9. oldal, összesen: 33 BTB (Branch Target Buffer) = BTAC + BHT – mindkettő az elágazási címből épül fel (BA), ezért összevonhatóak. • az elágazási címeket és a becslést egy időben kell kezelni • Egy History Bit és az ugrási cím tárolása • Ha van elágazás, kiveszi a címet, s ez íródik be a PC-be, ez a
cím fogja az utasításcache-ben a következő négy utasítás tartalmát meghatározni. • A legelterjedtebb módszer A cégek mind másképp nevezik ezeket, hogy egyedi technikának tűnjenek. • A Pentium Pro esetében: BTB 512 bájtnyi bejegyzéssel • Az AMD K8-nál a BTB 2 kilobájtnyi Dekódolás - - Látható, hogy a skalár processzornak ciklusonként csak egyetlen utasítást kell dekódolnia, illetve ellenőriznie kell azt is, hogy a kibocsátandó utasítás függ-e a végrehajtás alatt állóktól. A szuperskalár processzornak viszont meg kell vizsgálnia, hogy a kibocsátásra váró utasítások függenek-e a jelenleg végrehajtás alatt állóktól, illetve vannak-e függőségek a következő ciklusban kibocsátandó utasítások között. Mivel a VE-k száma nagyobb és több utasítás is van egy időben végrehajtás alatt, a függőségvizsgálatok során is jóval több összehasonlításra van szükség. A problémát az okozza, hogy nagyobb
kibocsátási ráta esetén (több utasítás, egyre kisebb mértékben növekvő kibocsátás) túlzottan megnőhet a dekódolás hossza, több ciklusra is szükség lehet. 10. oldal, összesen: 33 A gyorsítás útja az elődekódolás használata: o A dekódolási feladatok egy részét a processzor már aközben végrehajtja, amikor az utasításokat az L2 cache-ből vagy a memóriából az L1 cache-be írja. o Ennek szélessége jellemzően 128 vagy 256 bit ciklusonként. Az elődekóder 4-7 bitet fűz hozzá az utasításokhoz. Ebben kódolják például az utasítás típusát, erőforrás-igényét, elősegítve ezzel a dekódolást. o Az AMD K5-ben az elődekódolás meghatározhatja az utasítás kezdetét és végét is, illetve azt, hogy az utasításban hol vannak a műveleti kódok, a prefixek, stb. Ehhez minden egyes bájtot 5 többletbittel egészít ki, amely több mint 60%-kal növeli a kód méretét az utasítás-gyorsítótárban. o Az első generáció keskeny
volt, a másodikban felszámolták a kibocsátási szűk keresztmetszetet, utasításpufferrel. A következő lépcsőt az elődekódolás jelentette Jellemzően a második generációs RISC-ek esetében, de a CISC-ek is használják. - hagyományos eljárás, az elsőgenerációs szuperskalárokban (Pentium) o skalár és szuperskalár rendszerekben. o Prescott: 10 futószalag a dekódolásra. - CISC-RISC konverzió útján, második generáció felett (Pro-PII-PIII) o A CPU a CISC utasításokat RISC utasításokká konvertálja, majd ezeket az egyszerűbb utasításokat egy RISC maggal hajtja végre, ezután pedig visszakonvertálás következik. A RISC utasításhossza fix, csak LOAD/STORE kell a memóriakezeléshez. Ábra Fig 5.19 o Példa: BTB, ITLB utasításlehívás, dekódoló elem, Decoded Inst: pufferbe helyezi, regiszterátnevezés. Belül egy egyszerű RISC mag Utasításcache-ből lehozza, puffer, dekódol, várakozó puffer, átnevezi, normál RISC mag. Külön
dekódoló rész Ábra: FetchEDEC. o MikroROM, amely a komplikált utasításokat tárolja, ezeket csak lehívjuk, nem dekódolunk. Az első komplex dekódolóhosszabbakat is képes dekódolni. 3 dekóder: egy komplex, két egyszerű 11. oldal, összesen: 33 Utasítások dekódolása – IFU1-IFU3: 16 byte-ot dolgoz fel – Két eltérő jellegű dekóder: a komplex bármilyen utasítást képes dekódolni, amely maximum 3 RISC utasítássá alakítható. Az egyszerűk csak olyan utasítások dekódolására képesek, amelyek egy RISC utasítássá alakíthatók. – A RISC-ek LOAD-STORE architektúrák, tehát a memóriakezelésre csak ezeket lehet használni, az operatív műveletekben pedig csak a regiszterműveletek megengedettek. Pl egy RISC LOAD-ból egy CISC LOAD + ADD lesz. – A dekóderek csak sorrendben történő dekódolást engednek meg. Csak akkor működik a szimpla dekóder, ha a rá jutó utasítás egyszerű. Sebessége ciklusonként: kb 1,5 dekódolás – Az
összes többi utasítás kódjából egy pointer lesz kialakítva: ez címzi meg a MIS megfelelő elemét; a két rész (dekóder és MIS) kizárólagosan, egymást blokkolva működnek. – 118 bit a CISC utasítás hossza. Az átnevezett utasításokat egy puffer tárolja 20 elemű RS, a végrehajtás innen történik meg. A szekvencialitást a 40 bejegyzésű ROB biztosítja AMD K6 Ábra: Upper and lower portions of the processor – Az utasításpufferből megtörténik a lehívás, a Pentium Pro-nál megismert módon. 4 utasítás párhuzamosságát garantáló eszköz a puffer felé. Ábra: K7-K8 Ábra Athlon block AMD K7 - 3db dekóder, elődekódolás, elágazásbecslés - 64KB L1 cache, ICU = ROB - Az AMD-k makroutasításokat is tud kezelni, amelyek kettő mikrót tartalmazhatnak. Az operációs kód után: [OP Rd, X, Rs] [OP X, Rs1, Rs2] [L Rx, X] [OP Rd, Rx] - Makrókat dekódol, és a végrehajtásban bomlik két utasítássá, de ehhez már nem kellenek regiszterek, a
puffereket használja AMD K8 - A dekódólókat szélesítették és megemelték a várakoztató állomások számát, 5-ről 8-ra. Szélesebb a dekódolás, mindegyik elem képes kettőre, a mikro dekódolásra már nem volt szükség. - komplexebb, két elemi utasításból álló RISC utasításokat enged meg a rendszer. A Trace Cache – Jellemzően az Intel P4-ben, vagyis egy harmadik generációs CISC rendszerben jelent meg – Lényege az a felismerés, hogy az utasítások kb. 80%-át a ciklusok végrehajtása jelenti, így azonos utasítások folyamatos lehívásával és dekódolásával felesleges műveleteket végzünk – Ötlet: a dekódolt utasításokat tárolni kell, s a ciklusok végrehajtását a tároltak lehívásával gyorsítani Ábra: Basic Pentium 4 Processor Misprediction Pipeline – Egy helytelenül jósolt ugrás P4 esetén kb. 20 többletciklust jelent – A P3 teljes lebegőpontos ciklusa 20 fokozatból áll, a Prescottban ez 40 fokozatot jelent. – Az
utasítások lehívása egyetlen komplex dekóderrel történik. A dekódolt utasításokat a Trace Cache tárolja: • 12 Kb mikroutasítás • Komplex ALU: FP és MM/3D, • Csoportos várakoztatás. AGU: címszámító • külön elágazásbecslő rendszer, 512 bejegyzéssel • saját BTB, a normál utasítások elágazás-becslésére • külön eszköz a mikroutasítások elágazás-becslésére • a Trace cache-ben nem tárolják a hosszú ciklusokat, hanem egy pointer mutatása íródik be. (?) • két nagy puffer: egy memória és egy műveleti • nem terjedt el 12. oldal, összesen: 33 Utasítás kibocsátás (issue, dispatch) Általában: – az egyes gyártók eltérően jelölik ezt a folyamatot – Célja: a dekódolás után megjelenő utasításokat a rendszernek végrehajtásra kell kibocsátania a rendelkezésre álló VE-k felé. A probléma oka, hogy a kibocsátás feltétele az utasítások független mivolta (a végrehajtás alatt lévő utasításoktól
és a kibocsátandóknak is egymástól) – Jellemzően a skalár, futószalagos processzorokban jelentkezik ez a probléma a feltételes elágazások vagy az adatfüggőségek miatt. – A feltétes elágazások kezelése az első generáció példányainál blokkolással, a második generáció esetében pedig elágazásbecsléssel történt (486). A blokkoló kibocsátás erősen korlátozza a kibocsátási teljesítményt, ezért szükségessé vált az utasításvárakoztatás bevezetése. Szuperskalárok esetén a tervezési tér (feltételezzük, hogy az elágazásbecslés jelen van): – KIBOCSÁTÁSI POLITIKA: a kibocsátás hogyan viszonyul a függőségekhez. Jellemzően négy szempontot jelent (HOGYAN): 1. Rögzített vagy Csúszó ablakból történik a kibocsátás (inorder / out of order): 13. oldal, összesen: 33 – – Kibocsátási ablak (issue window): itt kerül sor a függőségek vizsgálatára. Az ablak n utasítás széles, ha n a kibocsátási ráta.
– Rögzített ablak (aligned): a rendszer mindaddig nem vizsgálja újabb utasítások kibocsáthatóságát, amíg a jelenlegi ablak összes utasítását ki nem bocsátotta. – Csúszó ablak (unaligned): amint egy utasítást kiküldtek, a felszabadult helyre újat kell lehívni (az ablakban mindig négy utasítás található). Annál hatékonyabb lehet, minél több utasítás van az ablakban. (utasítás-várakoztatás nélkül van csak értelme) Az ábrán csoportok alul a típusokkal. A felső csoport jellemzően első generációs (rögzített majd csúszó ablak) processzorokat tartalmaz. A második csoport első generációsakat is tartalmaz. A harmadik pedig visszatért a rögzített ablakra. 2. A kibocsátás sorrendi vagy sorrenden kívüli (fixed / diving) Sorrendi: az első függő (blokkolt) utasításig bocsát ki. Rögzített esetén például, ha a 4 betöltött utasításból a 2 középső függő, akkor csak az első függetlent bocsátja ki a rendszer. –
Sorrenden kívüli: az előbbi példában mindkét független utasítás kiküldhető, hatékonyabb. – Hátrányai: a soros konzisztencia megőrzése sokkal nagyobb ráfordítást igényel, illetve utasításvárakoztatásra képes processzorok esetén felesleges, ugyanis várakoztatásnál az utasítások kibocsátása csak erőforráskorlátok esetén blokkolódik. Alkalmazása: néhány, utasításvárakoztatást még nem alkalmazó (első generációs) szuperskalár processzor (Pl. PowerPC 601) használja csak a sorrenden kívüli kibocsátást Azonban ezt csak – – 14. oldal, összesen: 33 részlegesen valósították meg. A PowerPC 601 esetében az elágazások, illetve a lebegőpontos utasítások vonatkozásában. 3. a rendszer pufferelt vagy nem pufferelt kibocsátású – utasításvárakoztatás (direct / shelving) – – Nem pufferelt: az utasításpufferből a dekóder az utolsó 2-3 utasítást dekódolja. Ha azok függetlenek, és a szükséges erőforrások
rendelkezésre állnak (busz, feldolgozó egység), akkor kibocsátja őket. [Ni < 2] Pufferelt (dynamic instruction scheduling): a feldolgozó egységek elé építsünk be egy-egy várakozó puffert. Ekkor a dekódernek nem kell tekintettel lennie a függőségekre, mert a VP-ben addig várakozhatnak az utasítások, amíg függetlenné nem válnak. Nincs függőségvizsgálat, megszűnik a kibocsátási szűk keresztmetszet. Az egész folyamat két részre bomlik: bekerülés a VP-be (kibocsátás), illetve kikerülés a VP-ből (kiküldés). [Ni ~ 4] 4. Ál-adatfüggőségek kezelése: nincs regiszter-átnevezés vagy van (register renaming) – Célja az ál-adatfüggőségek megszüntetése: WAR, WAW. A kibocsátási szűk keresztmetszetet, amit a pufferelt megszüntet, tovább tágítja. – - KIBOCSÁTÁSI RÁTA: Az [Ni] kibocsátási ráta azt adja meg, hogy ciklusonként hány utasítást képes kibocsátani a rendszer, vagyis a dekóder által továbbküldött
utasítások maximális számával egyenlő. Az átlaga a rendszer átbocsátási képességét mutatja meg. (MENNYI) Az utasítás-várakoztatás Tervezési tér: o Várakozó pufferek megvalósítása Típusok 1. Várakoztató állomás: csak várakoztatásra szolgál 2. Kombinált puffer: Várakoztatásra, utasításátrendezésre, és regiszter-átnevezésre is szolgál egyidejűleg. Kapacitás o Operandus-lehívási politika A várakozó pufferek típusai 1. Várakoztató-állomás (Reservation Station - RS): kizárólag az utasítások várakoztatása szolgál, más funkciót nem lát el. A várakoztatás lényegében leválasztja a függőségek ellenőrzését az utasítások kibocsátásától, így ez a kiküldési fázisra marad. A processzor kibocsátáskor mindössze azt vizsgálja, hogy egy szabad puffer hiánya, vagy a szükségesnél keskenyebb adatsín nem-e akadályozzák meg az utasítások kibocsátását. 15. oldal, összesen: 33 - - - Egyedi:
minden egyes végrehajtó egységnek saját puffere van o Példa: AMD K5, PowerPC 620 (ábra – 7.102) o Ráfordítás: nagy o Teljesítmény: az egyik pufferből a másikba nem lehet utasításokat áttenni o Kapacitás: 2-4 hely Csoport: az azonos típusú (pl. FX) VE-k egy közös pufferből táplálkoznak Ehhez nyilván nagyobb pufferre van szükség. (P4, Athlon, Opteron - tendencia) o Példa: Pentium 4, Athlon, Opteron, R10000 (ábra – 7.100): két buszon keresztül történik az utasítások kiküldése Az egyik a fixpontoshoz, a másik a LP és gyökvonáshoz. Az LP osztás 20-40 ciklusig tart Ez egy buszról táplálva, nem hoz érdemi teljesítménycsökkenést, mivel a LP utasítások aránya 10% még a műszaki programokban is. o Teljesítmény: bármelyik VE-be kerülhetnek a várakozó utasítások o Kapacitás: 8-16 Központi: Minden VE egyetlen pufferből táplálkozik, ezért nagy kapacitásúra szükség. o Példa: P2, P3 (ábra 7.105) Pentium Pro: egy 20
elemű központi állomás szolgálja ki mind a 10 VE-t. Egy buszon keresztül lassú egységeket látnak el: +/ LP/*. o Ráfordítás: a pufferméret csökkenthető az egyedihez képest. Nagyobb ráfordítású, de nem gyorsabb, mint a csoport típusú. o Teljesítmény: az LP VE nem tudja végrehajtani az FX-et, és fordítva 2. Kombinált pufferek: - Az átnevező-puffert úgy bővítik ki, hogy egyúttal utasításvárakoztatásra és regiszterátnevezésre is használható legyen. (várakoztatás, átrendezés, átnevezés) o Példa: Metaflow Lightning (megvalósítási problémák miatt nem került forgalomba) Várakozó pufferek kapacitása - Ha van átnevezés, a VP csak központi lehet - Egyedi: 2-4 - Csoport: 10-20 - Központi: 20+ A kiküldési ablak A várakoztató pufferek összessége kiküldési ablakként is felfogható. Így az összesen rendelkezésre álló várakoztató helyek száma szabja meg a kiküldési ablak szélességét. - Az éppen végrehajtásra
várakozó utasítások ebben a pufferben vannak elhelyezve, mint egy ablakban - A kiküldés sorrenden kívüli, a processzor optimalizálja a sorrendet is (ezért a neve dinamikus utasításütemezés) - Ábra: a kiküldési ablak jellemző mérete (7.2 táblázat): szélesség: 3, 50, 100-200 (a generációk szerint 12-3) 16. oldal, összesen: 33 Operandus-lehívási politikák Kibocsátáshoz kötött operandus-lehívás - - - Egyedi várakoztatóállomásokat és az FX-LP adatok számára közös regisztertárat tételezünk fel. Az utasítások kibocsátása közben a processzor a kibocsátott utasításokban előforduló forrásregiszterek azonosítóit a regisztertárba továbbítja a hivatkozott operandusok behívása céljából. Ezen felül a processzor a műveleti kódokat (OC), a kibocsátott utasítások célregisztereinek azonosítóit (Rc) és a behívott operandusértékeket (Op1, Op2) beírja az allokált várakoztatóállomásba. A jellemző regiszterszám 32
bit, FX esetén 64 bit, illetve 150 bit környékén van a teljes hosszúság A beírás időtartama attól függ, hogy a regisztertár milyen gyorsan képes produkálni az adatokat. Megvalósítása o Az operandusok rendelkezésre állásának kezelése o A várakozó pufferek frissítése Az operandusok rendelkezésre állásának kezelése - Az operandusok lehívásakor a processzornak ellenőriznie kell, hogy a hivatkozott forrásoperandusok a regisztertárban rendelkezésre állnak-e. Nyilvánvalóan egy hivatkozott operandus értéke csak azután olvasható ki a regisztertárból, miután a létrehozó utasítás azt előállította. Az utasítások feldolgozása sorrenden kívüli, további függőségek alakulhatnak ki. add r1,r2,r3 sub r5,r1,r6 - A regisztertárban az érvényességet nyilván kell tartani, vagyis egy plusz V bitet (Valid) kell beiktatni. A V-bitek azt jelzik, hogy a hozzájuk rendelt regiszterben lévő adat érvényes-e. Amikor a processzor egy utasítást
kibocsát, az utasításban hivatkozott célregiszter V-bitjét nullázza annak érdekében, hogy a következő utasítások kibocsátása során megakadályozza e regiszter tartalmának kiolvasását mindaddig, amíg az nem áll rendelkezésre. Amint a VE végrehajtotta az ominózus utasítást, az eredményt beírja a célregiszterbe, s V-bitjét 1-ra állítja. Ettől fogva, e regiszter tartalma kiolvasható mindaddig, amíg amíg egy később kibocsátott utasítás ezt a regisztert nem használja újra célregiszterként. - A behívási folyamat áttekintése o Tételezzük fel, hogy a behívandó forrásoperandus Vbitje 1; ekkor az értéke beírható a VP megfelelő mezejébe, majd a VP-beli V-bitje 1-re állítható. Ellenkező esetben, ha a behívandó operandus értéke még nem áll rendelkezésre, a processzor az operandus értéke helyett egy azonosítót ír (pl. a hivatkozott regiszter számát) a VP megfelelő mezejébe, és a hozzárendelt érvényességbitet
nullázza. o Pl. add r1, r2, r3 //r3 (r1) + (r2) 17. oldal, összesen: 33 o A fenti utasítás operandusainak behívása esetén feltételezzük, hogy a regisztertárban az r1 Vbitje 1, míg r2-é 0 értékű. Az ábrán feltüntetett add utasítás esetében (r1) behívható, értéke (10) beíródik az Op1 mezőbe, és a hozzá tartozó V-bitet 1-re állítja. Ezzel ellentétben a második forrásoperandus még nem elérhető, ezért annak értéke helyett az (r2) azonosító íródik az Op2 mezőbe, és a hozzárendelt V-bitet nullázza. Várakozó pufferek frissítése - Miután egy VE a rábízott művelet végrehajtását befejezte, az előállított eredménnyel aktualizálni kell a regisztertárat és VP-ket. A frissítéshez az eredménysínen az eredmény értékének és azonosítójának (pl a célregiszter számának) kell megjelennie. A VP-k frissítéséhez először meg kell vizsgálni, hogy a létrehozott eredmény azonosítója szerepel-e a VP-k
forrásoperandus mezőiben. Ehhez asszociatív 18. oldal, összesen: 33 keresésre / beírásra van szükség, mivel más is várakozhat erre a regiszterre. A megegyező azonosítókat a processzor az eredmény értékével helyettesíti, és a hozzájuk rendelt V-biteket 1-re állítja. - Globális (többszörös) frissítés: a létrehozott eredményeket minden olyan VP-be továbbítani kell, amelyben a létrehozott eredményre várakozó utasítások lehetnek. Ehhez gyakorlatilag minden VP-t frissíteni kell, az azonos típusú adatokat előállító (pl. FX) VE-k eredményeivel Ehhez a VE-k eredménysíneit vissza kell csatolni minden ugyanilyen típusú VP-hez. A VPk frissítéséhez általában többszörös asszociatív keresésre van szükség: annyiszorosra, ahány eredménysín érkezik a tekintett pufferhez. - A cpu megvalósítása valójában osztott regiszterű: Fig 18. ISSUE BOUND FETCH, Egy FX és egy LP processzorfél Összefoglalás Ábra: Fig. 21 Basic Shelving
o Az összes kombináció előfordul, A bekarikázottak a dominánsak Kiküldéshez kötött lehívás - - A processzor az utasításokat a forrásregiszterek azonosítóival együtt tárolja el a VP-k megfelelő mezőiben (Rs1, Rs2). A hivatkozott operandusokat a processzor csak később hívja le, a végrehajtandó utasításoknak a VE-kbe való kiküldésekor. Kiküldés közben a műveleti kódokat (OC) és a kiküldött utasítások célregiszterazonosítóit (Rc) a processzor a VP-ből a megfelelő VE-be továbbítja, míg a Rs1, Rs2-t az operandusok lehívása érdekében a regisztertárba küldi. Így némi késleltetéssel Rs1 és Rs2 is megjelenik a megfelelő VE bemenetén. Ekkor nincs szükség a forrásoperandusok rendelkezésre állásának ellenőrzésére, mivel kiküldéskor már biztosra vehetjük azok meglétét. Ez esetben a VP-k aktualizálására sincs szükség Mindkét megoldást széles körben használják. Mára a kiküldéshez kötött dominánssá vált
Az utasítások kiküldésének módja o Kiküldési politika: ez szabja meg a végrehajtásra kiküldendő utasítások kiválasztásának és a kiküldési blokkolódások kezelésének módját. o Kiküldési ráta: meghatározza, hogy maximálisan hány utasítás küldhető ki ciklusonként, a VPkből a VE-kbe 19. oldal, összesen: 33 o Operandusok rendelkezésre állása: annak megállapítása, hogy egy operandus rendelkezésre áll-e - Kiküldési politika o A szelekciós szabály határozza meg, hogy a VP-ben tárolt utasítások mikor minősülnek végrehajthatónak. Azok az utasítások hajthatók végre, melyeknek minden forrásoperandusa rendelkezésre áll. o A döntési szabályra akkor van szükség, ha a továbbíthatónál több végrehajtásra alkalmas utasítás létezik. A megoldás az idősebb utasítások előnyben részesítése (Power2, Pentium Pro) o A követett kiküldési sorrend szabja meg azt, hogy egy nem végrehajtható utasítás megakadályozza-e a
sorban következő végrehajtható utasítás kiküldését. Sorrendben történő kiküldéskor csökken a teljesítmény, viszont elég csak a VP-k utolsó bejegyzéseit vizsgálni (egy VE esetén jó) A részben sorrenden kívüli kiküldés azt jelenti, hogy adattípusonként eltérő a megvalósítás. Például a Power2 csak a lebegőpontos utasításokat várakoztatja, és kiküldéskor csak egyetlen nem végrehajtható lebegőpontos utasítást „tud átlépni”. Sorrenden kívüli esetén bárhonnan kiküldhető a független utasítás, tehát a VP-ben lévő minden utasításról el kell dönteni, hogy végrehajtható-e (hatékonyabb, komplikáltabb, domináns). Csoport- vagy központi várakoztató állomások használata esetén hatékony, pl. Pentium Pro Az utasítások dinamikus gyakorisága miatt az FX-eket érdemes sorrenden kívül, az FPket pedig sorrenden kívül kiküldeni. Általános célú felhasználás esetén: FX 40%, L/S 35%, B 20%, FP 5-10%
- Kiküldési ráta o egy VE esetén 1-nél több utasítás kiküldésének nincs értelme. Több VE esetén viszont 1-nél többet kell. Ideális esetben egy VP-nek annyi utasítást kellene kiküldenie ciklusonként, ahány VE-t a VP kiszolgál. A CPU kiküldési rátája: a VP-ek kiküldési rátájának összege o A CPU kiküldési rátája hogyan viszonyul a CPU kibocsátási rátájához? A kettő átlagának időben azonosnak kell lennie. A kibocsátási ráta a második generációban jellemzően 4 (RISC), és 3 (CISC). o Míg a várakoztatás a függőségvizsgálat későbbre halasztásával a legtöbb ciklusban lehetővé teszi a kibocsátási rátának megfelelő számú utasítás kibocsátását, addig bonyolult LP utasítások több ciklusra is lefoglalhatják a VE-ket. Így a feldolgozás szűk keresztmetszetének elkerülésére a processzornak ciklusonként több utasítást kell tudnia kiküldeni, mint amennyit a VP-kbe tud kibocsátani. 20. oldal, összesen: 33
o 7.3 táblázat: Nagy részük második generációs rendszer 1995-96 A kiküldési ráta kb 50%-kal magasabb. - Operandusok rendelkezésre állása o Direkt-vizsgálat: az operandusok rendelkezésre állását a V-bitek vizsgálatával állapítja meg. Ezt a módszert használják kiküldéshez kötött operanduslehívás esetén, mivel ebben az esetben a 21. oldal, összesen: 33 VP-kben tárolt utasítások nem tartalmaznak explicit utalást arra nézve, hogy a forrásoperandusaik rendelkezésre állnak-e vagy sem. o Explicit érvényességbitek: feltételezzük, hogy a VP-kben az operandusokhoz hozzá van rendelve egy Valid bit, amely a rendelkezésre állást jelzi. A CPU ezeket vizsgálja, hogy kiküldhetők-e a VE-k felé. Van egy Valid bitje a regisztertárnak is, mert tudni kell, hogy a lehívott érték érvényes-e. Ezt a módszert tipikusan kibocsátáshoz kötött operanduslehívás esetén alkalmazzák. A Regiszter-átnevezés (register renaming, RR) o Az első
generációból a másodikra való átmenetnél szükséges a kibocsátási szűk keresztmetszet kiküszöbölése, vagyis az ál-adatfüggőségek feloldása. (WAR, WAW) o Az átnevezés elve, pl. WAW esetén I 1 : add r 1 , r 2 , r 3 I 2 : mul r 1 , r 4 , r 5 I 3 : R 4,2 := r 1 , mul r 4,2 , r 4 , r 5 o A megvalósítás Ha nincs átnevezés, az eredmények beíródnak a regisztertárba Ha van, egy átnevező regisztertár jelenik meg (puffer) A CPU nem az architekturális regiszterbe teszi, hanem a RRF-be, csak később kerül az ARF-be o A megvalósítás főbb kérdései: Az álfüggőségek megszüntetése volt a cél, amihez elvben csak függőségek esetén kellene az átnevezést megvalósítani. Az egyszerűség érdekében azonban minden célregisztert át kell nevezni, hogy ne kelljen bonyolult függőség-ellenőrzést végezni. Következmény: minden forrásregisztert át kell nevezni lehíváskor. Meg kell keresni, hogy az átnevezett
forrásnak melyik puffer felel meg. Pl • Mul r 1 , r 4 , r 5 • r 4,4 := r 1 • Sub r 10 , r 1 , r 9 //Az r 1 már nincsen, át lett nevezve • r 10 , r 4,4 Az átnevezések nyilvántartása: • Átnevezőtábla: a táblának annyi bejegyzése van, ahány regiszter van. Pl r 0 r 31 Indexelt tábla, amely nyilvántartja, hogy pl. az r 1 r 4,4 lett • Asszociatív átnevezőtábla: nem indexelt, hanem asszociatív struktúra Az átnevezések érvényessége: kibocsátáskor nevezzük át a regisztert. Szekvenciálisan konzisztens módon, amikor sorrendben írja ki a CPU az eredményeket. Akkor szűnik meg az átnevezés, amikor kiírjuk az ARF-be (ROB) • Add r 1 , r 2 , r 3 • Add r 4,4 , r 2 , r 3 - Az operandusok rendelkezésre állásának elve o Operandusok lehetnek: RRF-ben / ARF-ben. A lehívást mindkettőből meg kell oldani: ha nincs az RRF-ben (prioritás), akkor az ARF-ből kell venni. - A regiszter-átnevezés megjelenése Ábra: Fig. 2
Chronology of the introduction of renaming o Alpha: 1998-ban vezette be az RR-t, ezek voltak a leggyorsabbak o Filozófia: hatékonyabb, kisebb órajel. Lassabban működik Az RR lassít, ezért nem vezették be 22. oldal, összesen: 33 - Az RR megvalósítása, tervezési tere o Átnevező pufferek megvalósítása: • Önálló RRF: csak az átnevezésre szolgál. FX-re és FP-re külön RRF és ARF van (PowerPC) • ROB: az átnevezés a ROB-ban valósul meg. Kibocsátáskor minden utasítás kap egy azonosítót: egy állapotmezőt és egy adatmezőt. Amikor az utasítás kiírjuk, akkor az adat is kiíródik. Pl Pentium Pro, Athlon • Összevont ARF és RRF: ez korszerű. Kiíráskor nem kell az utasítást kiküldeni, elég átcímkézni azt. • Átnevező pufferek megvalósítása osztott pufferek esetén: o külön fixpontos és lebegőpontos regiszterre tagolódik o A CPU egy fixpontos, illetve egy lebegőpontos részből áll o Az átnevező regiszterek száma -
Összevont esetén egy fizikai blokkban van az ARF és az RRF: az ábrán a kettő összege szerepel. Az átnevező puffernek kell a legnagyobbnak lennie, mert itt sok félkész utasítás van. Ettől kisebb az átnevező pufferek száma, illetve az ablak. - Power4: összevont, 80 fixpontos és 72 lebegőpontos regisztert alkalmaz. 23. oldal, összesen: 33 o Pufferek kezelése Önálló RRF: kibocsátáskor a célregiszter kap egy puffert. Ekkor értéke még nem érvényes, mert még nincs kiszámítva. Ha a VE kiszámolta a regiszter tartalmát, akkor az utasítás státusza finished lesz. Kiíráskor a puffer értékét az ARF-be írjuk, ekkor completed. A puffer újra rendelkezésre bocsátható: reclaim. Összevont ARF+RRF: Inicializálás, amikor az átnevezés megtörténik, akkor pufferré válik, még nincs benne érvényes utasítás. Kiíráskor az AR hordozza az ARF értékét. Címkeváltás történik áttöltés helyett: r44-ből r1 lesz. Ha az r1-et újra átnevezik,
ez feleslegessé válik, az előbbi újra szabad puffer lesz. o A regiszter-nyilvántartás megvalósítása 24. oldal, összesen: 33 Indexelt forma: egyszerűbb elérés, de minden egyes lehetséges értékhez hozzá kell rendelni egy Valid mezőt és a puffer azonosítóját. Ezek adott architekturális regiszterhez vannak rendelve. Asszociatív megoldás: a szükséges elemszám kisebb, mint a lehetséges; a megvalósítás viszont lényegesen komplexebb. Az előkerülés sorrendjében történik a beírás Összevonják az átnevező pufferrel. Mezők: Valid bit, Célregiszter, Számérték – operandus-érték, Eredmény-érvényesség bit, Utolsó bit: ha azonos regszámra történik a bejegyzés, akkor az egy időben érvényes többszörös lekéréseket lehet kivédeni. Átnevező eljárások áttekintése: • • • • • RR megvalósítása (típus és darabszám): összevont, önálló, ROB átnevezés nyilvántartása: átnevező ráta (nem
minőségi szempont) Lightning: túl komplex volt, nem fejezték be, ehelyett a K6 kell az ábrára Átnevezési ráta: egyenlő a kibocsátási rátával 25. oldal, összesen: 33 Az átnevezés folyamatának megvalósítása Kibocsátáshoz kötött operandus-lehívás – – – – – A mikroArchitektúra egy egyszerűsített változata: – egy VE, egy várakoztató állomás – egy önálló regiszter az architekturális regiszterhez, leképező tábla – feltételezzük, hogy az utasítások lehívása, kibocsátása sorrendben történik (sorrendi dekódolás) Kibocsátás: Megérkeznek az utasítások, meg van adva a forrás- és célregiszter. Az operációs kód bekerül a várakozó állomásba. A célregisztert átnevezi, ehhez kell hozzárendelni egy új átnevező puffert Megvizsgálja, van-e még szabad regiszter, ha van, hozzárendeli, a kapcsolatot rögzíti az átnevező táblában. Meg kell nézni, van-e hozárendelt átnevezőpuffer, ha nincs, az ARF-ből
kell venni a forrásoperandust. Ez egy időben két logikai döntést igényelne, ezért a megvalósítás párhuzamos. Egy prioritás-logika: ha mindkettő létezik, az átnevezőpuffer részét továbbítja. ARF-be csak akkor kerülnek értékek, ha azok érvényesek, ezért nem kell Valid bit. Kiküldés: Amikor az eredmény megszületett, vele együtt a célregiszter azonosítóját is továbbítani kell. Az RS-ben lévő értékeket frissíteni kell, mert lehet, hogy erre a regiszterre egy másik utasítás vár. Szekvenciális kiíráskor: programállapot módosítás. Ekkor módosíthatja az ARF értékét, majd az RRF allokációt vissza lehet vonni, meg lehet szüntetni az átnevező táblában az erre utaló összefüggést. Kiküldéshez kötött operandus-lehívás – Az utasítások bekerülnek egy RS-be: utasítás kód, célregiszter, két forrásregiszter. Ekkor következik a lehívás, majd végrehajtás. A CPU-nak vizsgálnia kell az RRF-et, hogy az operandus
rendelkezésre áll-e A kiszámolt érték nem módosítja az RRF-et, nincs aktualizáció. Komplikáltabbá válik az átnevező pufferek megszüntetése. Lehet, hogy a következő utasítás használja ennek az értékét – Kibocsátás: Egy új átnevező reg a célregiszterhez, ha a megadott forrásregekhez létezik érvényes átnevezés, az átnevezett értékeket írja be a várakoztató állomásba. Az operandus nem kerül lehívásra – Kiküldés: vizsgálni kell az opok meglétét, lehívás párhuzamosan. – Szekvenciális kiküldéskor: a programállapotot módosítjuk, a RR tartalma átkerül az ARF-be. Az átnevező reg visszaadása komplikáltabb, lehet hogy az eredményre utasítások várnak. Pl – – – 26. oldal, összesen: 33 add r1,r2,r3 mul r1,r3,r5 Egy számlálót növelnek minden egyes bejegyzéskor, ha az operandus használja. Csökkenti, ha az op ki lett küldve. Ha minden opot a CPU felhasznált, a számláló nulla, meg lehet szüntetni az
átnevezést a táblában is. Ez egy megvalósítás, a többi kismértékben tér el ettől Párhuzamos végrehajtás - Globális tervezési tér o Utasítás-lehívás o Dekódolás o Kibocsátás (V / Á) o Végrehajtás o Szekvenciális konzisztencia Az utasítás-végrehajtás tekintetében A megszakítás-kezelés tekintetében - Végrehajtás o Tendencia a CPU-k végrehajtási szélességének növelése (RISC 3. gen: 4+) RISC 1. gen: 2-3 (FX-FP-L/S VE-k) RISC 2. gen: 4 (3db FX – 2 db L/S – 3 db FP) (+,-,/ külön, mert akár 20 ciklusig is dolgozhat) • Az utasítások eloszlása azonban dinamikus, sztochasztikusan változik: általános célú programokban ez az eloszlás: FX (40%), L/S (2/3 L, 1/3 S, 30-40%), Elágazás (20%), FP (5%) Ma kb. 10 VE jellemző o Utasítás/Ciklus vagy frekvencia növelése a követendő két különböző fejlesztési lehetőség - 27. oldal, összesen: 33 Szekvenciális konzisztencia o Az utasítás-feldolgozás
szempontjából Egy program logikája olyan, hogy az utasítások sorrendje releváns. Mivel a CPU regisztertere és memóriatere eltérően módosulhat, a beírás-olvasás viszonya eltérő lehet párhuzamos végrehajtás esetén. Döntően a beírás szempontjából és a LOAD-STORE közötti viszony. (nem cserélhető fel kettejük sorrendje) Feltétel, amit teljesíteni kell: mintha egy szekvenciális processzor lenne, úgy kell működnie a rendszernek: szekvenciálisan konzisztens működés A megvalósítás módja, a 2. generációs szuperskalároktól kezdve a ROB • Körpuffer bejegyzésekkel, jellemzően két pointer: beíró-kiíró, utasítások egyéni azonosítója a pufferen belül, illetve az állapota: várakozik, végrehajtott. Az utasításokat a ROB kibocsátáskor befogadja. Minden utasítást a CPU a ROB-ba bejegyez. Jelölve: kibocsátva Az állapotmódosításokat a CPU kezeli Ha végrehajtva az utasítás, jelölve van a ROB-ban. • Csak
sorrendben engedi meg a kiírást a pufferből, vagyis a regiszterekbe, illetve a memóriába. A pointernek azt kell vizsgálnia, hogy az összes korábbi utasítás végre van-e már hajtva. Ha igen, a kiírás megtörténik o A megszakítás-kezelés szempontjából Ha logikailag korábbi, időben későbbi a megszakításkérés, akkor az INT megszakítja az utasítások végrehajtását Megvalósítása: az utasítás megszakítását addig jegelni kell, amíg az utasítást ki nem írjuk, vagyis az érvényre jutás csak a kiírás után megengedett. Processzor-struktúrák (processor data path - adatút) - A ráfordítás mérésének fontos részei a széles adatutak (2x64 bit), kevésbé fontos részei pedig a regisztertárak - Mitől függ ezek szélessége? o Lehívás (32 bit), Dekódolás o Kibocsátás: várakoztatás, RR o Az utasítás kibocsátás mikéntje a várakoztatás és az átnevezés módján múlik, továbbá az operandusok lehívásának mikéntje is
fontos (kib. vagy kik kötött) A lehetséges cpu struktúrákat ez a három alapfeladat megvalósítása szabja meg. - A lehetséges CPU-struktúrák szempontjai o A kibocsátás tekintetében melyek a legfontosabb eljárások, amelyekben érdemben eltérő adatutak vannak? Ábra: Fig. 541 Basic structure Főbb típusok, az utasítás lehívásának módja Átnevezés: balra, függőlegesen Az egyes megvalósítások egymást kizárhatják: ld. a kihúzott részeket Elvben 24 eltérő cpu struktúra lehetséges A változások azért következhettek be, mert nem voltak a megoldások elég jók Operandus csak a Merge-ből indul el a feldolgozóegységekhez, az eredmény pedig innen megy a VE-hez. Ez a nyerő megoldás a cpu felépítésében Ábra: Fig. 9 Basic datapath o Esettanulmányok PowerPC 620 (ábra) • 6 db feldolgozó egység • Minden VE-nek saját puffere van 2-4-es mérettel • Átnevezés, ROB, ARF MIPS R10000 (ábra) • Csoport
várakozóállomás • Kiküldéshez kötött az utasítás-végrehajtás Pentium Pro (ábra) • Központi várakozóállomás Pentium 4 • Trace cache: a dekódolt utasításokat tároló cache • Elágazásbecslés, átnevezés 28. oldal, összesen: 33 Különböző filozófia - AMD: elődekódolás: 3 bit / byte, makroutasítások dekódolása o K8 kiküszöböli a mikro-t, az időkorlátot megszünteti, L1 64k - Intel: trace cache o Mikroutasítások dekódolása, L1 8k Szálszintű architektúrák (multi threaded a. / micro a) Megjelenésük szükségessége - Nem kikerülhető fejlődési fokozat - Soros proc (i286(1982)), Futószalagos proc (i386 - i486), szuperskalár (Pentium, Pentium Pro) - Az általános célú programokban az utasításszintű párhuzamosság kimerült a: o multimédia támogatással (PII), illetve o a multimédia + 3D támogatással (PIII, PIV) - A dedikált növelés is kimerült - A következő lépcsőfokot a hardveresen többszálú
architektúrák jelentik Technikák - Egyszálas: egyetlen utasításfolyamban a processzor már kimeríti a rendelkezésre álló párhuzamosságot (párhuzamosan feldolgozható utasítások – utasításfolyam) - Többszálas: több szál egyidejű futtatása o Tudnia kell a két szál között különbséget tenni, illetve több állapotot kell kezelnie o Pl. IBM Power4 (2001), P4 Prestonia (2002), Pentium 4 Northwood (2002) 3,06GHz-től Megvalósítás - Többmagos egyszálas: egy lapkán két vagy több processzor-maggal o A cache-ekben osztoznak, a megvalósítás az egyes rendszerekben eltér o Egy mag egy szálat dolgoz fel, közös cache o Értékelés: Többlethardver: 60-70%-kal több Többletteljesítmény: 50-60% általános célú alkalmazásokban - Többszálas egymagos: egyetlen többszálas processzor-maggal o SMT, pl. kétszálas mag: ezen belül tesznek különbséget az állapotok között, pl külön regiszterkészlettel o Értékelés:
Többlethardver: 5%-kal több Többletteljesítmény: erősen alkalmazásfüggő: -10-20%-tól +20%-ig (zavarhatják egymást) o Az egyprocesszoros rendszerekben a disszipáció okozza a korlátot. Két mag 200W+, léghűtéssel érdemben nem kezelhető. A többmagos technikához csökkenteni kell a disszipációt Tényleges megvalósítások Ábra: többszálas processzorok jelene és jövője - többmagos egyszálas o IBM Power4: kétmagos o UltraSparc IV o Sun Niagara: 8 mag, 4 szál,2006-7 (5 futószalag fokozat, egyszerű magok) o AMD Opteron Dual o Intel két Prescott maggal: Tulsa Többmagos egyszálas HT helyett, Pentium M-mel. Kétmagos VLIW Itanium: két szálat kezel - egymagos többszálas o Intel Hyperthreading, ami megfelel az SMT-nek = Symmetrical MultiThreading o A feldolgozás keverve történik, a jelzőbitek kezelik az állapotmódosításokat o Szimmetrikus, a kettő között nincs különbség - többmagos többszálas 29. oldal, összesen: 33 o
Power5: AS/400 és OS/400 összehozva, a Power5 már mindkét célra alkalmas (konvergencia), kialakult a virtuális technika, logikai particionálás (a hardver erőforrásokat futás közben kezeli). Figyeli a kihasználtságokat, átcsoportosítani is képes. Dinamikus allokáció - Rendszerarchitektúrák teljes számítógépes rendszer: cpu, cpu-busz, lapkakészlet, kiegészítő chipek, lan, scsi, video A fejlődés áttekintése Ábra: Fig 24 system architecture - ISA: minden ezen keresztül valósult meg - PCI: egyszerűbb, fejlettebb - Portalapú rendszerek, sínrendszerek helyett: P3-P4 A fejlődés főbb állomásai - ISA o a buszvezérlő gondoskodik a memória és a billentyűzet kezeléséről o minden kártyákon keresztül valósul meg (ISA based system architectures) - Straight forward PCI-based system architecture o A vezérlés kettéválik, északi és déli híd, amelyek a PCI-on keresztül kapcsolódik o Északi: L2 és memóriakezelés, itt nagyobb
sávszélesség szükséges o A perifériák PCI vagy ISA buszra is kialakíthatók, jellemzően 4-5 PCI slot és 2-3 ISA - PCI-based system a with IDE/ATA and USB ports o A déli híd a vinyók kezelését, két csatorna, négy eszköz, és néhány usb-s rendszer o Megmarad az ISA, de a a sebessége miatt a PCI dominál - PCI-based system a with AGP, IDE/ATA and USB ports o ISA a háttérbe szorul (1 vagy semennyi) - Ports-based o Szinte minden portokon keresztül kapcsolódik a rendszerhez, az ISA nem tartozék, csak egy hídon keresztül csatlakoztatható (opcionális) o A PCI is elvesztette jelentőségét, mivel minden a déli hídhoz kötődik o Super IO: keyb, ms, fd, sp, pp, ir o AC ’97 o FPM-EDO-SD RAM - Soros buszokat és portokat használó rendszerarchitektúra o A párhuzamos buszok ideje lejárt, mert Az FSB (Front Side Bus) 64bites, megjelennek a 0-1 átmenetek, az északi híd bemenetén megjelenik egy SKEW, ami a futási idők eltéréseit jelenti. Azért van
eltérés, mert az egyes biteknek eltérő távolságot kell megtenniük a híd és a proci között. Korlátozza a teljesítményt. A kapacitív terhelés sem azonos: különböző meredekségű a felfutás A buszkorlátot 3-4Ghz környékén érték el. HT: soros buszok, annyi van belőle, amennyi kell. 1 bit = 2 Gbit sávszél 2GHz mellett RS-242 USB, ATA SATA, SCSI SAS, PCI PCI X, AGP 16 bit PCI Express AMD FSB HyperTransport, az Intel is megjelenik majd a soros busszal A rendszer-arhitektúra főbb elemei - FSB o Szélesség (address bus - data bus) 8086 (20-16), 8088 (20-8), 80286 (24-16), 80386 (32-32), 80486 (32-32), Pentium (3264), Pentium Pro – P4 (36-64+8) o Frekvencia, a P4 példáján 400MHz FSB, 1,5GHz Willamette = 400 / 1,5 = 0,25, 2Ghz, 0,2 elérése esetén váltás (tapasztalat), ezért emelik rendszeresen a buszfrekvenciát. (1066MHz a vége jelenleg) A buszon keresztül történik a kommunikáció a memóriával, az
AGP-vel és a déli híddal is, ezért a busz szűk keresztmetszetté válik Ezen segít a soros busz, sávszélessége lényegesem nagyobb lehet - Lapkakészlet (chipset) Ábra: Xeon MP o 286-tól, 386-ban már mindegyik rendszerben van chipset 30. oldal, összesen: 33 o Pentium 4 Az összes családnak egy mag az alapja, az eltérés a cache-ben, órajelben van DP = kétprocis, MP = multiprocis (A Netburst-öt 10GHz-ig hirdették anno) Többszálas, 64 bites kiterjesztés o A Desktop vonal áttekintése, lapkakészlet szempontjából (Fig. 28) G: integrált video Fontosak a procikhoz illeszkedő lapkakészletek: 845- 865 – 915 Ábra: 845xx family, Figure 2.2 • Memory control hub, Egycsatornás memóriavezérlő, SD / DDR RAM • P4 elsők Rambus rammal 850-860 chipkészlet, helytelen döntés volt • Buffered (nagy kapacitás esetén, szerverek – 16 Gb), unbuffered (jellemző, 24Gb), ECC • Gyors fejlődés: Ábra: fig 3.2, a teljes család o ICH =
I/O Control Hub, Kétcsatornás: 4 gb o HI: 16 bites, 266MB/s o DMI: 2Gb / s, 4 bites soros rendszer o HDA = High Definition Acoustic Interface Lapkakészletek sávszélességének vizsgálata - Különböző buszok: memóriabusz, grafika, stb. - Processzorbusz: 64 bit, sávszélesség 8byte x Fc (órajel) - SDRAM: 8xFsdram - Hagyományos: HI 1.5 – 8 bit 266MB/s (duplája a PCI-ének) o A fejlesztés alapöltlete az volt, hogy két PCI busz jön a déli hídból. 2x133 = 266MB/s - 910-es chipben PCI express, 4x1bit, soros busz, 2000MB/s, bitenként és irányonként - PCI: 2,5 Gbit/s, kódolása 10 bites, mert órát nem tartalmaz. Nettó sávszélessége irányonként 2 Gbit - HI: 16 bites, 2x266MB - CSA (Communications System Arch): 848, 865 – 8 bit, 266MB - HI 2.0 szerverekben: 16 bit: 1066MB/s - PCI E x8 = 8x1bit, 4000MB/s Ábra: Table 5.4 peak bandwidth - AGP8 – 2132MB - SCSI Ultra 320 = 320MB – fenntartott sebesség: 60-90MB egységenként - SATA 1.0 – 150 - PCI –
133MB/s - PCI-x 64 /66MHz – 533 A sávszélességviszonyok két chipkészletben Ábra: Fig 5.5 – peak bandwidth - CPUbusz – 3200MB/s, szűk - Déli és északi között szűk keresztmetszet - probléma - Ezt oldották fel a 915xx családdal Ábra: Fig. 56 peak b values - PCIx 16 – 8000MB - Északi-Déli között 2000MB - GigaBit Ethernet = 500MB, négyet is ellát belőle - A processzorbusz lesz a keskeny sávszélesség, szükséges itt is a soros busz megjelenése Lapkakészletek megvalósítása - A GigaBit Ethernet Controller csatolása alapesetben, desktop család Ábra: Fig. 64 widely o PCI buszon, 125MB kell, 133 van (elég) o Intel 848-tól az északi hídra új CSA busz, 266MB, kétcsatornáshoz elég o Szerverekben egy vagy kétcsatornás megoldás. A nagyobb HI 2 interfészre egy PCIx hidat tesznek, erre kapcsolódik a GBE vezérlő o Aztán PCIx 64, a kontroller erre kapcsolódik o Mindegyik megoldás sántít, mert a déli északi közötti kapcsolat szűk 31.
oldal, összesen: 33 Ábra: fig. 65 alternatives o PCIx: 1 bites is elég, 400MB, ezekre kötik a kontrollert, vagy 4 bites híd o A legjobb megoldás: 8 bit külön kezelhető o SCSI Gyors, nagy megbízhatóság, szerverekbe Ultra 160 ill. 320, mindkettőben egy- és kétcsatornás megoldás Északi híd + PCIx híd + SCSI Ábra: Fig. 73 alternatives SCSI o Grafika Ábra: Fig. 74 P4-based Szerverekben az északi hídba építve, nincs rá nagyobb szükség Desktop-ban külön kártya, PCI x16 Vagy grafika a PCI buszon nagy szerverek Alaplapok Megjelenésük - Az IBM PC megjelenése a kiindulás (1981, 8 bites CPU busz) - IBM PC-XT (1983), AT – 16 bites busz - Ezután jöttek a klóngépek – Compaq: hamar chipkészleteket kezdett használni, csökkennek a méretek (baby AT) - IBM AT – nincs lapkakészlet, nincs kártyás RAM, 305x350 AT méret Fejlődésük: Ábra: Fig. 92 - LPX: Riser Card: alaplapra szerelhető, erre kerülnek rá a slotok - ATX:
funkcionális javítás - BTX: jobb hőkezelés Ábra: Fig. 93 o Méret: szélesség x mélység, I/O hátul o A Maximális mélység, az I/O helye, a slotok helyei és a furatpozíció adott Az egyes típusok főbb jellemzői - AT o 8(rövid) /16 bit (hosszú) ISA, max 8 db slot o tápcsati bárhol lehet, keyboard o IBM: A BASIC ROM-ban volt, nincs lapkakészlet, billentyűzet van, I/O a kártyákon, kazettásmagnó a fő tároló - Baby AT o Méretcsökkenés a kártyás SIPP RAM-nak köszönhetően (30 pin, 1byte 4 byte), 386-tól o SIMM (kétoldalas, 30pin majd, 30-72-168 pin az út) Fig. 96 rajz o 386 CPU, L2 DIPPként, SIMM 30 RAM, ISA 8/16, billentyűzet o Tápcsati akárhol - Pentium alapú Baby AT o Pentium CPU, L2-ből 2 chip az alaplapon o SIMM 72 RAM, ISA 16 o PCI 32 bit, számuk nem szabványos o Alaplapra integrált vezérlők: FDD, HDD - LPX (1986) o Keskeny dobozokhoz Ábra: Fig. 99 o Pentium, L2, SIMM 72, HD-FD, IO: a lap teljes hosszán - ATX o Az első igazi
standard o 1994 – Pentium Pro o Jellemzők: Kétsoros IO csatlakozók, kisebb szélesség - NLX o o BTX o o o 32. oldal, összesen: 33 CPU a táp mellé, egy venti elég a tápban, 15W kb. FD, HDD közel az előlaphoz, nem kell hosszú kábel, kisebb sugárzás Könnyen elérhető RAM 6 slot: ISA + PCI, vagy combo ISA-PCI slot, csak az egyik használható Korai P2-P3 ATX • Slot1, L2 külön buszon, ez igényelte a slotot • DIMM 168pin, 64bit • Emeletes IO • ISA háttérbe szorul, AGP – 1997-től támogatja az ATX P4 ATX legújabb • 3PCI + socket CPU, L2 chipen belül • DIMM 168 • PCI X 2x1bit • PCI E 16 grafika • SATA 4 port, elég egy ATA A funkcionális javítást szolgálja Slot1, riser cardon slotok, HD, FD Cél a hűtés megoldása picoBTX : 1 slot, mikro: 3-4, BTX: 6-7 slot CPU, chipset egy sorban a jobb hűtésért Alaplapok élettartama Ábra: Fig. 928 - Vezérlések: kártya – lapon – chipsetben - Sorrend: kártyás
IO alaplapra dedikált vezérlő lapkakészleten belül Processzortípusok Ábra: Fig. 926 Memóriák Ábra: Fig. 927 IO Ábra: Fig. 928 - LPC: key, mouse, soros, párh port UI: ezt a doksit szinte szégyellem a nevem alatt kiadni, de hát Sima Dezső óráin jegyzetelni a kevés lehetetlen feladat közé sorolom. UFO http://doksi.hu 33. oldal, összesen: 33 Ez az első előadáson hangzott el, mintegy ELIGAZÍTÁSként. Ne nyomtasd ki! Óvd a fákat! Eligazítás Követelmény - Elvárások o Tömör, strukturált válasz a zh kérdésekre, a tendenciák bemutatása o zh a végén, az anyag változik a tavalyihoz képest (Pl. PCI Express, rendszer-architektúra) - Államvizsga: 10 perces előadás, megadott tételek alapján o Az előadás-fóliákat lehet használni a magyarázatokhoz o Előtte konzultáció, minden kérdésről érdemes vázlatot készíteni - Szakdolgozat: o Mérnöki munka, nem csak programozás o Pontos specifikáció, lehetséges megoldási módok, ha
vannak a megoldáshoz használható, már működő rendszerek, ezek leírása o Kritériumok kidolgozása: mi a legfontosabb számunkra a feladat megoldása során. Értékeljük a lehetséges megoldási módokat o Implementációs fázis, Dokumentáció o Előszó, összefoglaló részek – hogyan értékeljük mi magunk a megoldást; korlátok, illetve mi valósult meg a kitűzött célokból, mit kéne megvalósítani; saját munka méltatása (ezt olvassák el a legtöbben) o Irodalomjegyzék: ne alacsony színvonalú szakirodalmat használjunk fel, hanem elismert szaktekintélyek munkáit. Lehetőleg angol nyelvű is legyen köztük bizonyítandó, hogy otthonosan mozgunk az angol szaknyelvben is - Ajánlott irodalom: o SFK: Korszerű számítógép-architektúrák o Szuperskalár architektúrák
instruction Branch prediction was planned but due to implementation constraints not realized Megjelenésük, tervek, kísérletek, prototípusok Ábra: szuperskalár processzorok prototípusai The designation " super scalar " IBM Cheetah pr oject Amer ica pr oject (4) Multititan (2) DEC Stanford U. MATCH (2) Kyushu U. SIMP (4) 1982 1983 1987 1988 1989 TORCH (2) DSNS (4) 1990 1991 2. oldal, összesen: 33 az IBM már a 80-as évek elején kísérletezett a szuperskalár architektúrákkal (ekkor jelent meg elsőként ez a kifejezés - 1987), s amikor látszott, hogy a futószalag elv a végét járja, gőzerővel indult be a fejlesztés (America Project – RS/6000) - A DEC volt a világ második legnagyobb számítógépgyártója, erősségeit a kisszámítógépek jelentették (PDP8, PDP11, VAX) - MultiTitan kétszeres kibocsátású prototípus rendszer volt - Stanford: kétszeres kibocsátású, statikus ütemezésű szuperskalár processzor, amelyben a
végrehajtandó utasításokat egy globális ütemező rendezte előzetesen megfelelő sorrendbe. Megjelenésük a kereskedelmi rendszerekben - Ábra: szuperskalárok megjelenése (a 'négyzetnélküliek' futószalagosak, a 'négyzetesek' szuperskalárok) RISC processors Intel 960 960KA/KB M 88000 MC 88100 960CA (3) MC 88110 (2) HP PA PA 7000 PA7100 (2) SPARC MicroSparc SuperSparc (3) R 4000 MIPS R R 8000 (4) 29040 29000 sup (4) Am 29000 Power1(4) RS/6000 IBM Power α 21064(2) DEC α PPC 601 (3) PPC 603 (3) PowerPC 88 89 90 91 92 93 94 95 CISC processors i486 Intel x86 Pentium(2) M 68040 M 68000 M 68060 (2) Gmicro/100p Gmicro Gmicro500(2) AMD K5 K5 (4) CYRIX M1 M1 (2) Denotes superscalar processors. RISC - Az Intel 960CA az első kereskedelmi forgalomba került szuperskalár volt, azonban beágyazott rendszerekbe (szerverekbe) készült - Az első, asztali rendszerekbe szánt szuperskalár a Power1 volt - A SPARC 2 évvel a
tervezettnél később jelent meg, ezért, a teljesítménye nem volt kielégítő, megbukott - DEC Alpha21064: 64bites rendszer, kétszeres kibocsátás, a kiöregedett VAX helyett - Motorola, MIPS: túl későn - Am29000: beágyazott CPU. Az eddig készült processzorok egy meglévő processzor szuperskalárosításával keletkeztek, a későbbiek azonban eleve szuperskalár feldolgozást feltételező, új architektúrák (DEC, IBM) CISC - csak később váltak szuperskalárokká, amelynek kettős oka van: o Komplexebb technológia, mivel a memóriaarchitektúrájú CISC processzorok csak jóval nagyobb ráfordítással valósíthatók meg, mint a RISC LOAD/STORE architektúrák o Változó hosszúságú utasításokat kell dekódolniuk, ezért nehéz megoldani a ciklusonkénti több utasítás-lehívást (ezért a CISC-ek vékonyabbak, tipikusan 2 és 4) - 1993-ban jelentek meg az első szuperskalár CISC-ek: o Motorola MC 68060, Pentium: egy már meglévő skalár CISC család
szuperskalár modelljei o Cyrix M1, AMD K5: eleve szuperskalárnak tervezték őket o A legtöbb CISC processzort (Pentium, K5, Nx586, K5) egy szuperskalár RISC maggal valósították meg, amelyre a négyszeres kibocsátás jellemző. 3. oldal, összesen: 33 Fejlődésük áttekintése - generációk Super scalar s Features: Width: Core: Caches: Fir st gener ation ("Thin superscalars") Second gener ation ("Wide superscalars") 2-3 RISC instructions/cycle or 2 CISC instructions/cycle "wide" 4 RISC instructions/cycle or 3 CISC instructions/cycle "wide" No predecoding Predecoding Static branch prediction Unbuffered issue No renaming No ROB Dynamic branch prediction Buffered issue (shelving) Renaming ROB Single ported data caches Blocking L1 data caches or nonblocking caches with up to a single pending cache miss allowed Off-chip L2 caches attached via the processor bus Dual ported data caches Nonblocking L1 data caches with multiple
cache misses allowed ISA: Examples: Off-chip direct coupled L2 caches Alpha 21064 1 Alpha 21264 PA 7100 PA 8000 SuperSparc Power2 3 PowerPC 604 PowerPC 620 1,4 1,4 UltraSparc I, II Pentium 2 Pentium Pro K6 1 On-chip L2 caches FX- and FP-SIMD instructions No MM/3D support PowerPC 601 Thir d gener ation ("Wide superscalars with MM/3D support") Power 4 Pentium III (0.18 µ) Pentium 4 Athlon (model 4) Athlon MP (model 6) No renaming. 2 Optionally dynamic branch prediction is also supported, futhermore the Pentium has a dual ported data cache. 3 No off-chip direct coupled L2. 4 Only single ported data cache. - - - Első generáció: vékony szuperskalárok (kb. 1990) o A kibocsátási rátájuk: maximum 2-3 utasítás perc ciklus, CISC esetén csak 2-es o Kibocsátási szűk keresztmetszet: az adatfüggőségek miatt az utasítások kibocsátásakor korlátba ütközünk, mivel a kibocsátás direkt (nem pufferelt). Így csak a független utasításokat lehet
kibocsátani, ilyen pedig alapból kevés van. Ezért jellemzően csak 2-es szélességű, a nagyobb nem lenne kihasználva. o Ezért egy adatcache elég: a LOAD-STORE aránya 40% körül van. o Az L2 a CPU buszán van o A fejlesztés útja: a szélességet bővíteni. Megoldás: a pufferelt kibocsátás és a regiszter átnevezés Második generáció (kb. 1995) o Elődekódolás, ROB, nemblokkoló cache o L2 dedikált sínen o Jellemzően 4-es szélesség o Az általános célú alkalmazásokban lévő párhuzamosság kihasználása ezzel kimerült Harmadik generáció (kb. 2000, P3-P4) o Általános célú alkalmazásokban nem hoz teljesítmény-növekedést, de a speciális célú alkalmazásokban többletet jelent (multimédia) o SIMD (Single Instruction Multiple Data): a fixpontos SIMD a 2,5. generáció (P2, kb 1997) o FX/FP SIMD: az igazi harmadik generáció (MM+3D) (ehhez a logikai architektúra bővítésre szorult) o A CPU lapkáján van az L2 cache. Kétportos cache-re van
szükség, mert a szimpla már kevés - 4. oldal, összesen: 33 1995-ben következett be a RISC-ek CISC-ekbe történő átmenete. Ennek oka, hogy eddig a RISC-ek voltak gyorsabbak (különösen a DEC processzorok), 2000-re azonban a CISC-ek már egyértelműen átvették a vezetést A RISC processzorok élete - A szóhossz vonatkozásában o A szóhossz növekedése jelentette a fejlődés alapvető irányvonalát (az első mikropocesszor: Intel 4004 = 4 bit). A szuperskalároknál a DEC gyártott elsőként 64 bites CPU-t; ekkor a legtöbb processzor 32 bites volt o Architektúra: PA RISC, CPU: R8000 (szuperskalárosított) o A 32 bites RISC-ekből szuperskalár és a szuperskalárosított CPU-k léteztek. Ezek a kilencvenes évek végére egységesen 64 bitesekké váltak. o A CISC-ek döntő többsége 32 bites volt, egészen 2000-ig, amikor az AMD 64 bites szóhosszal egészítette ki az x86 architektúrát Ábra: Az FX-SIMD és az FP-SIMD utasítások összeolvadása a
mikroprocesszorok esetében RISC processors Compaq/DEC Alpha Alpha 21064 84 83 85 Alpha 21164 21164PC 125 2126486 Alpha 21364 87 Motorola MC 88000 HP PA IBM Power Power PC Alliance PowerPC MC88110 PA7100 Power1(4) 89 88 PA-7100LC 193 Power2(6/4) PPC 601 (3) PPC 603 (3) MIPS R Sun/Hal SPARC PA-7200 90 PA8000 94 96 PPC 604 (4) 97 PPC 602 (2) 98 91 P2SC(6/4) 104 PPC 620 (4) R 10000 107 91 101 100 99 R 80000 126 PA 8500 92 102 Power3 (4) G3 (3) G4 (3) 103 Power 4 113 R14000 105 R 12000 110 108 SuperSPARC PA-8200 PA 8600 PA 8700 126 95 128 129 R16000 130 118 UltraSPARC-3 UltraSPARC-3-Cu UltraSPARC-2 UltraSPARC 127 109 SPARC64 CISC processors 112 Intel Pentium 80x86 CYRIX /VIA M AMD/NexGen Nx/K 114 Pentium/MMX PentiumPro113 M1 119 Nx586 117 MII 120 1991 1992 1993 1994 118 K5 1995 1996 131 P4 10 Pentium 4 Pentium II K6 1990 116 Pentium III 115 1997 121 K6-2 122 K6-3123 1998 132
Opteron K7 1999 124 2000 2001 2002 2003 Multimedia support (FX-SIMD) Support of 3D (FP-SIMD) o Ez azért volt meglepő, mivel az Intel-HP páros szerint a 32 bites CISC CPU-kat a VLIW (EPIC) technológiának kellene leváltania. Ilyen volt az Itanium processzor, amelynek fejlesztését 1994ben kezdték meg De annak ellenére, hogy 1999-re ígérték, csak 2001-ben jelent meg, így némileg elkésett, mivel az AMD keresztülhúzta számításaikat. o Az Intel mégis tartotta magát a Merced kódnéven ismertté vált projekthez, de titokban az x86 architektúrát kiegészítő 64 bites technológián is dolgozott o 2004-ben az Intel az EMT (Extended Memory Technology) bejelentésével –ami lényegében egy x86-32/64 volt- elismerte, hogy az Itanium megbukott. Ábra: Általános célú VLIW processzorok (zárójelben a mag szélessége látható) 5. oldal, összesen: 33 Crusoe (4) TM 3120 TM 5500 TM 5800 TM 5400 Transmeta Efficeon (8) Intel TM 8600 Itanium (6) 2000
Itanium (Merced) Itanium2 (McKinley) Itanium2 (Madison) 2001 2002 2003 - Az Intel hibás víziójának megfelelően fejlesztő processzorgyártók megbuktak, kiszálltak a processzorpiacból. - DEC: Alpha 264-gyel befejeződött a fejlesztés - Motorola, HP, PPC 620, MIPS leállt - SPARC ma is versenyben van: 2004-ben a Sparc 5-öt befejezi, Niagara rendszerét továbbfejleszti (8 magos, magonként 4 szál – 2006-ra ígérik) - A RISC családból egyetlen túlélő: az IBM A CISC processzorok élete: - Cyrix beolvadt a VIA-ba, a Transmeta haldoklik - Maradt az AMD – Intel páros 2004-re 2004-es helyzet - Februárban az Intel EMT-t bejelentették, így az Itanium fejlesztése leállt; az Intel ’növeljük az egekig a frekvenciát’ politikája kudarcot vallott, ezért 3,8GHz-nél nagyobb órajelű P4 processzorra nem számíthatunk. A fizikai határt is elérték: a Prescott túllépi disszipációban a 130W-ot, így az ilyen irányú fejlesztéseknek nincs többé értelme
(fogyasztás, hűtés, zaj) - Az Intel filozófiájának (’egyszerű architektúra + nagy frekvencia’) megváltoztatására kényszerül. Azonban ugyanez kétmagos rendszer képében szintén elképzelhetetlen (2x100W kis helyen) - AZ AMD viszont 2003-tól egyre nagyobb teljesítményű rendszereket mutat be, s a piac 5 szegmenséből legalább hármat ural, teljesítmény tekintetében.(desktopmultiprocesszoros rendszerek) Kiemelten fontos szuperskalár rendszerek IBM Ábra: az IBM desktop processzorai (az ábrák tetején vastagon az ISA, vagyis az utasításszintű architektúra neve) - Alapfilozófia: legyen két nagy alkalmazási szektor: üzleti szektor (domináns, képviselője az AS/400, OS: OS/400), műszaki, tudományos szektor (RISC 6000, OS: AIX) - Azonos OS mellett a PowerPC, mint új architektúra, a kommersz alkalmazásokhoz igazodóan. Első generációs szuperskalárok: CISC-ből RISC lett, majd szuperskalár - AS/64: fejlettebb első generációs, 64 bites család
- Új filozófia: legyen definiálva egy általános architektúra, amely egyaránt használható a kommersz és a tudományos szektorban is. Ennek képviselői a Power4 (kétmagos), majd a Power5 (kétmagos, magonként kétszálas) processzorok. - PSC = Power Single Chip (Pl. Power2, amely egychipes) - A PPC64 egy subsetje a PowerPC/64, a harmadik generáció a Power3 - Az OS-ben bevezették a logikai partíciókat, amely valójában virtuális megvalósítást jelent: ugyanaz a hardver használható eltérő szoftveres konfiguráció elvégzése után. Pl OS/400 vagy AIX szimulálása 6. oldal, összesen: 33 Intel Ábra: Intel Pentium II. és III magok 3/99 10/99 ^ ^ ^ ^ Drake Tanner Cascades Tualatin 0.25 µ /75 mtrs 400/450 M Hz 0.25 µ /95 mtrs 500/550 M Hz 0.18 µ /28 mtrs 600/667/733 M Hz 0.13 µ 1.13/126 GHz Dir. 512K/1M /2M L2 (1x) 100 M Hz FSB Dir. 512K/1M /2M L2 (1x) 100 M Hz FSB On-die 256K L2 133 M Hz FSB On-die 512K L2 133 M Hz FSB 7/01 Xeon-line
(Servers/ Workstations) Desktop-line 5/97 1/98 2/99 10/99 ^ ^ ^ ^ ^ Klamath Deshutes Katmai Coppermine Tualatin-256 0.35 µ /75 mtrs 233/266/300 M Hz 0.25 µ /75 mtrs 333 M Hz 0.25 µ /95 mtrs 450/500 M Hz 0.18 µ /28 mtrs 500 - 733 M Hz 0.13 µ 1.13/12 GHz Dir. 512K L2 (05x) Dir. 512K L2 (05x) Dir. 512K L2 (05x) On-die 256K L2 66 M Hz FSB 66 M Hz FSB 100 M Hz FSB 100/133 M Hz FSB Celeron-line ("economy class" cores) 1997 - - On-die 256K L2 133 M Hz FSB 1 4/98 8/98 3/00 1/01 ^ ^ ^ ^ ^ 10/01 Covington Mendocino Coppermine-128-A Coppermine-128-B Tualatin-256 0.25 µ /75 mtrs 266 M Hz 0.25 µ /19 mtrs 300/333 M Hz 0.18 µ /28 mtrs 566/600 M Hz 0.18 µ /28 mtrs 800 M Hz 0.13 µ /44 mtrs 1.2 GHz No on-die L2 66 M Hz FSB On-die 128K L2 66 M Hz FSB On-die 128K L2 On-die 128K L2 66 M Hz FSB 100 M Hz FSB On-die 256K L2 100 M Hz FSB 1998 1999 Pentium II (M M X) 1 7/01 6/98 2000 2001 Pentium III (SSE) Coppermine cores
with 100 M Hz FSB are tagged by E, whereas those running at 133 M Hz with EB. (Katmai cores are designated by B) Pentium, majd 1995-ben Pentium Pro, amely az alapját képezte a PII-PIII-nak, P4: gyökeres váltás 1997: Klamath, majd azonos felépítés mellett 0,25 mikron, magasabb órajel Economy class – kisebb teljesítményű CPU-k: a meglévő magot meghagyták, de a cache méretét és sebességét, illetve az FSB-t csökkentették Celeron Convington: ha a gyártás során az L2-cache rossznak bizonyul, letiltják és felcímkézik Celeronnak Mendocino: nagyobb tranzisztorszám, a cache miatt. A mag lebutításával 40% teljesítménycsökkenés következett be, s így az AMD-K6-2-vel már nem volt versenyképes. (ezzel semmiképp' sem értek egyet) A fejlesztések iránya általában felülről lefelé mutatott (Xeondesktop) Xeon Drake: nagyobb cache, egyszeres L2 sebesség, slot2, 100MHz rendszerbusz MMX: gyenge fejlesztés, a lebegőpontos regiszterek használata
miatt Katmai: több tranzisztor, nagyobb órajel. Coppermine: 28m tranzisztor, az on-die cache megjelenése 0,18 mikronos Celeron: ismét ugyanaz a mag, mind a három célú processzorban (jelentős árkülönbséggel) Ábra: Intel Pentium 4 magok (a Netburst architektúra megvalósításai) - 2000. november: Netburst architektúra, Willamette mag, a P3 0,13-al zárult, ez mégis 0,18-ról indul On-die 256K, 400MHz FSB, min. egyharmad FSB kell az órajelhez, hogy ne legyen szűk keresztmetszet, SSE2: kibővített utasításkészlet Új S478 tokozás, on-die cache, a jobb tápellátás érdekében A korábban használt cache slotot -amelyhez külön buszra volt szükség-, felváltotta a direkt csatolású cache Northwood: o minél nagyobb frekvencia, 1 év alatt 2-ről 3GHz-re o 512 Kb cache, több tranzisztor, később 800MHz-es FSB Northwood B: o Megjelenik a HyperThreading, ami egymagos, kétszálas processzort takar. Így 5%-os többlethardver segítségével 10-20%
teljesítménytöbbletet sikerült elérni. Xeon: 603 tokozás, Xeon MP-kisebb L2, de nagy L3 cache P4 Celeron tranzisztorszám ugyanannyi, mint a P4-é, ezért nem is publikálják ezt az adatot A Prescott-ban benne volt a 64bites kiterjesztés -ezt mutatja 125 milliós tranzisztorszám-, de nem volt aktiválva. Később a Prescott F-ben már igen - 7. oldal, összesen: 33 LGA 775-ös tokozás: a korábban megszokott tüskék az alaplapra kerülnek, így a processzor kevésbé sérülékeny, az alaplap így drágább lesz, a processzorcsere pedig bonyolultabbá válik. (2004 nyara) Pentium 4 Extreme Edition: workstation-ökre, nagyobb FSB és cache Az ábrán lévő Potomac típus és az áthúzottak fejlesztését leállították. A netburst architektúra pedig zsákutcát jelent a túlzott disszipáció miatt. AMD Ábra: Az AMD Opteron vonala - Opteron: az első szám a processzorok száma, a második az órajel - Direkt-csatolt memória rendszer: a memória rajta van a chipen,
csak 80W-ot fogyaszt - A Hypertransport busz megemelve 1066-ra, 90W-os fogyasztás - Athlon64 FX: egylinkes HT, kétcsatornás memóriavezérlő (a szerverpiacra) - Athlon64: egycsatornás memóriavezérlő, 3,5Ghz-es számozástól kétcsatornás (desktop). Módosítani kellett a socket-et is. A 939 lett az egységes socket, minden felhasználáshoz Ábra: Az AMD Athlon64 FX és Athlon64 vonala Szuperskalár processzorok megvalósítása Tervezési tér - Utasítás-lehívás (instruction fetch) - Dekódolás - Utasítás-kibocsátás (issue) - Párhuzamos végrehajtás (execution) - A szekvenciális konzisztencia biztosítása, az utasítások végrehajtásának szempontjából (pertaining sequential consistency regarding of instruction processing) - A szekvenciális konzisztencia biztosítása a megszakítások kezelésének szempontjából ( interrupt processing) Szekvenciális végrehajtás esetén az első négy jelen van, s ezek mindegyike párhuzamos jellegű. A szekvenciális
konzisztencia biztosítása - elvárjuk, hogy az utasítások a programozásnak megfelelő logikai sorrendben hajtódjanak végre úgy, mintha a processzor szekvenciálisan működne - szuperskalárok esetén ennek biztosítására szolgál az utasításpuffer. Az utasításokat ide hívjuk le: például egyszerre hármat, ha a dekódoló egyszerre hármat képes dekódolni. Így három VE párhuzamos működése biztosított, azonban a végrehajtás sorrendje eltér az utasítások szekvenciális sorrendjétől, mivel a CPU az állapotteret eltérően módosítja (memória, regiszterek). A szekvenciális konzisztencia biztosításának eszköze: ROB (ReOrder Buffer) - Ez lényegében egy kör alakú puffer: egy körív mentén az adott [(i) (i+n)]-edik utasítások azonosítói helyezkednek el. A programállapot módosítását csak szekvenciálisan engedi meg úgy, hogy egy utasítás által előírt memória -és regiszterutasításokat csak akkor engedélyezi, ha minden előtte
lévő utasítás már teljesen végrehajtódott, s eredményeik már ki vannak már írva a tárba. 8. oldal, összesen: 33 A megszakítás-kezelés - A feldolgozás során történhetnek események, megszakítások. Ezeket addig kell várakoztatni, amíg a vonatkozó utasítás nem kerül soros végrehajtásra. Ha egyből érvényre jutna, egy olyan állapot állna elő, amely bizonytalanságot szülne, például egy félig feldolgozott utasítás miatt. Utasítás-lehívás - nem tárgyaljuk az előlehívást (prefetching) és az utasításpuffer feltöltésének módját - nem tárgyaljuk az elágazás-kezelés megvalósításait, csak egy gyakran használt eljárást A feldolgozás elve PC – Program Counter. Initial PC – kell egy kezdeti PC érték BTA – Branch Target Address: gondoskodni kell az ugrási cím értékeiről - Prefetch esetén: IFP – Instruction Fetch Pointer: az utasításcache-ből az utasításpufferbe kerül az utasítás, majd a dekódolás
következik Elágazás-kezelés: - az elágazási cím meghatározása o a BTA cím kiszámítása: PC := (PC) + Delta //Delta = 1/4/16 o szuperskalároknál ilyen nincs, de BTAC van (Branch Target Address Cache) o nem szükséges a címet kiszámítani. Ha tudjuk, hogy milyen cím után mire fog ugrani Pl a ciklusokban előforduló utasítások esetén, a címszámítás után tároljuk a címet, s ezt használjuk fel o Előny, hogy az elágazások 70-80%-a ciklusokból származik o Elve: BTAC Vegyünk egy asszociatív struktúrát BA-ról ugrani kell BTA-ra A keresés a tartalom szerint történik, párhuzamos jelleggel Ezt beiktatva az előző rendszerbe, így megvan a működés alapelve. Megnézheti, hogy később lesz-e elágazás, s az új címet tárolhatja el A következő cím vizsgálata történik meg, időben párhuzamosan. Lesz-e a következő címre ugrás. Ha nem, akkor időkésés nélkül kezeli Mivel asszociatív, csak azokat a címeket
tartalmazza, ahonnan az elágazásbecslés elágazást jósol - Elágazásbecslés o BH (Branch History): feltételezünk egy kétbites, dinamikus elágazásbecslést o Elágazás-becslési eljárások: Statikus (egyszerűbb) eljárások: a kód alapján dönti el, hogy lehetséges-e elágazás. Ha egy utasításban a D értéke negatív, akkor ez feltehetően egy cikluszáró utasítás, vagyis elugrás következhet be. JC = Jump Conditional, D: Displacement (eltolás), F: feltétel, B: Base (az egész egy utasítás) Dinamikus (komplexebb, hatékonyabb) eljárások: Az elágazás-történetből, vagyis a múltbeli eseményekből lesz levezetve. • 1-bites eljárás: ha az előző ugrás teljesült, akkor valószínűleg ez is fog. • 2-bites eljárás (Smith-eljárás): Négy lehetséges állapot. Kiindul egy kezdőértékből, pl. 00-ból, és vizsgálja az egymást követő eljárások teljesülését Telített számlálóként működik. Ha teljesül, jobbra megy, ha
nem, balra Állapotdiagram: ha az állapot 10 vagy 11, akkor a következő is teljesülni fog. Ha 00 vagy 01, akkor az ugrás nem fog teljesülni. Ugrási címenként kell egy-egy négybites számláló. (a Pentium Pro-tól napjainkig) Az eljárás finomítása: bevezetnek egy kétszintes elágazásbecslést. Az eddigi lokális történet volt, ez most a globális történet változata (nem tárgyaljuk) Megvalósítása: BHT (Branch History Table): • asszociatív struktúra • az aktív elágazási címek vannak tárolva, • vagyis azok, ahonnan elágazásokat detektáltunk • felismeri, ha nem ugrási cím kell, hanem egy eltárolt cím 9. oldal, összesen: 33 BTB (Branch Target Buffer) = BTAC + BHT – mindkettő az elágazási címből épül fel (BA), ezért összevonhatóak. • az elágazási címeket és a becslést egy időben kell kezelni • Egy History Bit és az ugrási cím tárolása • Ha van elágazás, kiveszi a címet, s ez íródik be a PC-be, ez a
cím fogja az utasításcache-ben a következő négy utasítás tartalmát meghatározni. • A legelterjedtebb módszer A cégek mind másképp nevezik ezeket, hogy egyedi technikának tűnjenek. • A Pentium Pro esetében: BTB 512 bájtnyi bejegyzéssel • Az AMD K8-nál a BTB 2 kilobájtnyi Dekódolás - - Látható, hogy a skalár processzornak ciklusonként csak egyetlen utasítást kell dekódolnia, illetve ellenőriznie kell azt is, hogy a kibocsátandó utasítás függ-e a végrehajtás alatt állóktól. A szuperskalár processzornak viszont meg kell vizsgálnia, hogy a kibocsátásra váró utasítások függenek-e a jelenleg végrehajtás alatt állóktól, illetve vannak-e függőségek a következő ciklusban kibocsátandó utasítások között. Mivel a VE-k száma nagyobb és több utasítás is van egy időben végrehajtás alatt, a függőségvizsgálatok során is jóval több összehasonlításra van szükség. A problémát az okozza, hogy nagyobb
kibocsátási ráta esetén (több utasítás, egyre kisebb mértékben növekvő kibocsátás) túlzottan megnőhet a dekódolás hossza, több ciklusra is szükség lehet. 10. oldal, összesen: 33 A gyorsítás útja az elődekódolás használata: o A dekódolási feladatok egy részét a processzor már aközben végrehajtja, amikor az utasításokat az L2 cache-ből vagy a memóriából az L1 cache-be írja. o Ennek szélessége jellemzően 128 vagy 256 bit ciklusonként. Az elődekóder 4-7 bitet fűz hozzá az utasításokhoz. Ebben kódolják például az utasítás típusát, erőforrás-igényét, elősegítve ezzel a dekódolást. o Az AMD K5-ben az elődekódolás meghatározhatja az utasítás kezdetét és végét is, illetve azt, hogy az utasításban hol vannak a műveleti kódok, a prefixek, stb. Ehhez minden egyes bájtot 5 többletbittel egészít ki, amely több mint 60%-kal növeli a kód méretét az utasítás-gyorsítótárban. o Az első generáció keskeny
volt, a másodikban felszámolták a kibocsátási szűk keresztmetszetet, utasításpufferrel. A következő lépcsőt az elődekódolás jelentette Jellemzően a második generációs RISC-ek esetében, de a CISC-ek is használják. - hagyományos eljárás, az elsőgenerációs szuperskalárokban (Pentium) o skalár és szuperskalár rendszerekben. o Prescott: 10 futószalag a dekódolásra. - CISC-RISC konverzió útján, második generáció felett (Pro-PII-PIII) o A CPU a CISC utasításokat RISC utasításokká konvertálja, majd ezeket az egyszerűbb utasításokat egy RISC maggal hajtja végre, ezután pedig visszakonvertálás következik. A RISC utasításhossza fix, csak LOAD/STORE kell a memóriakezeléshez. Ábra Fig 5.19 o Példa: BTB, ITLB utasításlehívás, dekódoló elem, Decoded Inst: pufferbe helyezi, regiszterátnevezés. Belül egy egyszerű RISC mag Utasításcache-ből lehozza, puffer, dekódol, várakozó puffer, átnevezi, normál RISC mag. Külön
dekódoló rész Ábra: FetchEDEC. o MikroROM, amely a komplikált utasításokat tárolja, ezeket csak lehívjuk, nem dekódolunk. Az első komplex dekódolóhosszabbakat is képes dekódolni. 3 dekóder: egy komplex, két egyszerű 11. oldal, összesen: 33 Utasítások dekódolása – IFU1-IFU3: 16 byte-ot dolgoz fel – Két eltérő jellegű dekóder: a komplex bármilyen utasítást képes dekódolni, amely maximum 3 RISC utasítássá alakítható. Az egyszerűk csak olyan utasítások dekódolására képesek, amelyek egy RISC utasítássá alakíthatók. – A RISC-ek LOAD-STORE architektúrák, tehát a memóriakezelésre csak ezeket lehet használni, az operatív műveletekben pedig csak a regiszterműveletek megengedettek. Pl egy RISC LOAD-ból egy CISC LOAD + ADD lesz. – A dekóderek csak sorrendben történő dekódolást engednek meg. Csak akkor működik a szimpla dekóder, ha a rá jutó utasítás egyszerű. Sebessége ciklusonként: kb 1,5 dekódolás – Az
összes többi utasítás kódjából egy pointer lesz kialakítva: ez címzi meg a MIS megfelelő elemét; a két rész (dekóder és MIS) kizárólagosan, egymást blokkolva működnek. – 118 bit a CISC utasítás hossza. Az átnevezett utasításokat egy puffer tárolja 20 elemű RS, a végrehajtás innen történik meg. A szekvencialitást a 40 bejegyzésű ROB biztosítja AMD K6 Ábra: Upper and lower portions of the processor – Az utasításpufferből megtörténik a lehívás, a Pentium Pro-nál megismert módon. 4 utasítás párhuzamosságát garantáló eszköz a puffer felé. Ábra: K7-K8 Ábra Athlon block AMD K7 - 3db dekóder, elődekódolás, elágazásbecslés - 64KB L1 cache, ICU = ROB - Az AMD-k makroutasításokat is tud kezelni, amelyek kettő mikrót tartalmazhatnak. Az operációs kód után: [OP Rd, X, Rs] [OP X, Rs1, Rs2] [L Rx, X] [OP Rd, Rx] - Makrókat dekódol, és a végrehajtásban bomlik két utasítássá, de ehhez már nem kellenek regiszterek, a
puffereket használja AMD K8 - A dekódólókat szélesítették és megemelték a várakoztató állomások számát, 5-ről 8-ra. Szélesebb a dekódolás, mindegyik elem képes kettőre, a mikro dekódolásra már nem volt szükség. - komplexebb, két elemi utasításból álló RISC utasításokat enged meg a rendszer. A Trace Cache – Jellemzően az Intel P4-ben, vagyis egy harmadik generációs CISC rendszerben jelent meg – Lényege az a felismerés, hogy az utasítások kb. 80%-át a ciklusok végrehajtása jelenti, így azonos utasítások folyamatos lehívásával és dekódolásával felesleges műveleteket végzünk – Ötlet: a dekódolt utasításokat tárolni kell, s a ciklusok végrehajtását a tároltak lehívásával gyorsítani Ábra: Basic Pentium 4 Processor Misprediction Pipeline – Egy helytelenül jósolt ugrás P4 esetén kb. 20 többletciklust jelent – A P3 teljes lebegőpontos ciklusa 20 fokozatból áll, a Prescottban ez 40 fokozatot jelent. – Az
utasítások lehívása egyetlen komplex dekóderrel történik. A dekódolt utasításokat a Trace Cache tárolja: • 12 Kb mikroutasítás • Komplex ALU: FP és MM/3D, • Csoportos várakoztatás. AGU: címszámító • külön elágazásbecslő rendszer, 512 bejegyzéssel • saját BTB, a normál utasítások elágazás-becslésére • külön eszköz a mikroutasítások elágazás-becslésére • a Trace cache-ben nem tárolják a hosszú ciklusokat, hanem egy pointer mutatása íródik be. (?) • két nagy puffer: egy memória és egy műveleti • nem terjedt el 12. oldal, összesen: 33 Utasítás kibocsátás (issue, dispatch) Általában: – az egyes gyártók eltérően jelölik ezt a folyamatot – Célja: a dekódolás után megjelenő utasításokat a rendszernek végrehajtásra kell kibocsátania a rendelkezésre álló VE-k felé. A probléma oka, hogy a kibocsátás feltétele az utasítások független mivolta (a végrehajtás alatt lévő utasításoktól
és a kibocsátandóknak is egymástól) – Jellemzően a skalár, futószalagos processzorokban jelentkezik ez a probléma a feltételes elágazások vagy az adatfüggőségek miatt. – A feltétes elágazások kezelése az első generáció példányainál blokkolással, a második generáció esetében pedig elágazásbecsléssel történt (486). A blokkoló kibocsátás erősen korlátozza a kibocsátási teljesítményt, ezért szükségessé vált az utasításvárakoztatás bevezetése. Szuperskalárok esetén a tervezési tér (feltételezzük, hogy az elágazásbecslés jelen van): – KIBOCSÁTÁSI POLITIKA: a kibocsátás hogyan viszonyul a függőségekhez. Jellemzően négy szempontot jelent (HOGYAN): 1. Rögzített vagy Csúszó ablakból történik a kibocsátás (inorder / out of order): 13. oldal, összesen: 33 – – Kibocsátási ablak (issue window): itt kerül sor a függőségek vizsgálatára. Az ablak n utasítás széles, ha n a kibocsátási ráta.
– Rögzített ablak (aligned): a rendszer mindaddig nem vizsgálja újabb utasítások kibocsáthatóságát, amíg a jelenlegi ablak összes utasítását ki nem bocsátotta. – Csúszó ablak (unaligned): amint egy utasítást kiküldtek, a felszabadult helyre újat kell lehívni (az ablakban mindig négy utasítás található). Annál hatékonyabb lehet, minél több utasítás van az ablakban. (utasítás-várakoztatás nélkül van csak értelme) Az ábrán csoportok alul a típusokkal. A felső csoport jellemzően első generációs (rögzített majd csúszó ablak) processzorokat tartalmaz. A második csoport első generációsakat is tartalmaz. A harmadik pedig visszatért a rögzített ablakra. 2. A kibocsátás sorrendi vagy sorrenden kívüli (fixed / diving) Sorrendi: az első függő (blokkolt) utasításig bocsát ki. Rögzített esetén például, ha a 4 betöltött utasításból a 2 középső függő, akkor csak az első függetlent bocsátja ki a rendszer. –
Sorrenden kívüli: az előbbi példában mindkét független utasítás kiküldhető, hatékonyabb. – Hátrányai: a soros konzisztencia megőrzése sokkal nagyobb ráfordítást igényel, illetve utasításvárakoztatásra képes processzorok esetén felesleges, ugyanis várakoztatásnál az utasítások kibocsátása csak erőforráskorlátok esetén blokkolódik. Alkalmazása: néhány, utasításvárakoztatást még nem alkalmazó (első generációs) szuperskalár processzor (Pl. PowerPC 601) használja csak a sorrenden kívüli kibocsátást Azonban ezt csak – – 14. oldal, összesen: 33 részlegesen valósították meg. A PowerPC 601 esetében az elágazások, illetve a lebegőpontos utasítások vonatkozásában. 3. a rendszer pufferelt vagy nem pufferelt kibocsátású – utasításvárakoztatás (direct / shelving) – – Nem pufferelt: az utasításpufferből a dekóder az utolsó 2-3 utasítást dekódolja. Ha azok függetlenek, és a szükséges erőforrások
rendelkezésre állnak (busz, feldolgozó egység), akkor kibocsátja őket. [Ni < 2] Pufferelt (dynamic instruction scheduling): a feldolgozó egységek elé építsünk be egy-egy várakozó puffert. Ekkor a dekódernek nem kell tekintettel lennie a függőségekre, mert a VP-ben addig várakozhatnak az utasítások, amíg függetlenné nem válnak. Nincs függőségvizsgálat, megszűnik a kibocsátási szűk keresztmetszet. Az egész folyamat két részre bomlik: bekerülés a VP-be (kibocsátás), illetve kikerülés a VP-ből (kiküldés). [Ni ~ 4] 4. Ál-adatfüggőségek kezelése: nincs regiszter-átnevezés vagy van (register renaming) – Célja az ál-adatfüggőségek megszüntetése: WAR, WAW. A kibocsátási szűk keresztmetszetet, amit a pufferelt megszüntet, tovább tágítja. – - KIBOCSÁTÁSI RÁTA: Az [Ni] kibocsátási ráta azt adja meg, hogy ciklusonként hány utasítást képes kibocsátani a rendszer, vagyis a dekóder által továbbküldött
utasítások maximális számával egyenlő. Az átlaga a rendszer átbocsátási képességét mutatja meg. (MENNYI) Az utasítás-várakoztatás Tervezési tér: o Várakozó pufferek megvalósítása Típusok 1. Várakoztató állomás: csak várakoztatásra szolgál 2. Kombinált puffer: Várakoztatásra, utasításátrendezésre, és regiszter-átnevezésre is szolgál egyidejűleg. Kapacitás o Operandus-lehívási politika A várakozó pufferek típusai 1. Várakoztató-állomás (Reservation Station - RS): kizárólag az utasítások várakoztatása szolgál, más funkciót nem lát el. A várakoztatás lényegében leválasztja a függőségek ellenőrzését az utasítások kibocsátásától, így ez a kiküldési fázisra marad. A processzor kibocsátáskor mindössze azt vizsgálja, hogy egy szabad puffer hiánya, vagy a szükségesnél keskenyebb adatsín nem-e akadályozzák meg az utasítások kibocsátását. 15. oldal, összesen: 33 - - - Egyedi:
minden egyes végrehajtó egységnek saját puffere van o Példa: AMD K5, PowerPC 620 (ábra – 7.102) o Ráfordítás: nagy o Teljesítmény: az egyik pufferből a másikba nem lehet utasításokat áttenni o Kapacitás: 2-4 hely Csoport: az azonos típusú (pl. FX) VE-k egy közös pufferből táplálkoznak Ehhez nyilván nagyobb pufferre van szükség. (P4, Athlon, Opteron - tendencia) o Példa: Pentium 4, Athlon, Opteron, R10000 (ábra – 7.100): két buszon keresztül történik az utasítások kiküldése Az egyik a fixpontoshoz, a másik a LP és gyökvonáshoz. Az LP osztás 20-40 ciklusig tart Ez egy buszról táplálva, nem hoz érdemi teljesítménycsökkenést, mivel a LP utasítások aránya 10% még a műszaki programokban is. o Teljesítmény: bármelyik VE-be kerülhetnek a várakozó utasítások o Kapacitás: 8-16 Központi: Minden VE egyetlen pufferből táplálkozik, ezért nagy kapacitásúra szükség. o Példa: P2, P3 (ábra 7.105) Pentium Pro: egy 20
elemű központi állomás szolgálja ki mind a 10 VE-t. Egy buszon keresztül lassú egységeket látnak el: +/ LP/*. o Ráfordítás: a pufferméret csökkenthető az egyedihez képest. Nagyobb ráfordítású, de nem gyorsabb, mint a csoport típusú. o Teljesítmény: az LP VE nem tudja végrehajtani az FX-et, és fordítva 2. Kombinált pufferek: - Az átnevező-puffert úgy bővítik ki, hogy egyúttal utasításvárakoztatásra és regiszterátnevezésre is használható legyen. (várakoztatás, átrendezés, átnevezés) o Példa: Metaflow Lightning (megvalósítási problémák miatt nem került forgalomba) Várakozó pufferek kapacitása - Ha van átnevezés, a VP csak központi lehet - Egyedi: 2-4 - Csoport: 10-20 - Központi: 20+ A kiküldési ablak A várakoztató pufferek összessége kiküldési ablakként is felfogható. Így az összesen rendelkezésre álló várakoztató helyek száma szabja meg a kiküldési ablak szélességét. - Az éppen végrehajtásra
várakozó utasítások ebben a pufferben vannak elhelyezve, mint egy ablakban - A kiküldés sorrenden kívüli, a processzor optimalizálja a sorrendet is (ezért a neve dinamikus utasításütemezés) - Ábra: a kiküldési ablak jellemző mérete (7.2 táblázat): szélesség: 3, 50, 100-200 (a generációk szerint 12-3) 16. oldal, összesen: 33 Operandus-lehívási politikák Kibocsátáshoz kötött operandus-lehívás - - - Egyedi várakoztatóállomásokat és az FX-LP adatok számára közös regisztertárat tételezünk fel. Az utasítások kibocsátása közben a processzor a kibocsátott utasításokban előforduló forrásregiszterek azonosítóit a regisztertárba továbbítja a hivatkozott operandusok behívása céljából. Ezen felül a processzor a műveleti kódokat (OC), a kibocsátott utasítások célregisztereinek azonosítóit (Rc) és a behívott operandusértékeket (Op1, Op2) beírja az allokált várakoztatóállomásba. A jellemző regiszterszám 32
bit, FX esetén 64 bit, illetve 150 bit környékén van a teljes hosszúság A beírás időtartama attól függ, hogy a regisztertár milyen gyorsan képes produkálni az adatokat. Megvalósítása o Az operandusok rendelkezésre állásának kezelése o A várakozó pufferek frissítése Az operandusok rendelkezésre állásának kezelése - Az operandusok lehívásakor a processzornak ellenőriznie kell, hogy a hivatkozott forrásoperandusok a regisztertárban rendelkezésre állnak-e. Nyilvánvalóan egy hivatkozott operandus értéke csak azután olvasható ki a regisztertárból, miután a létrehozó utasítás azt előállította. Az utasítások feldolgozása sorrenden kívüli, további függőségek alakulhatnak ki. add r1,r2,r3 sub r5,r1,r6 - A regisztertárban az érvényességet nyilván kell tartani, vagyis egy plusz V bitet (Valid) kell beiktatni. A V-bitek azt jelzik, hogy a hozzájuk rendelt regiszterben lévő adat érvényes-e. Amikor a processzor egy utasítást
kibocsát, az utasításban hivatkozott célregiszter V-bitjét nullázza annak érdekében, hogy a következő utasítások kibocsátása során megakadályozza e regiszter tartalmának kiolvasását mindaddig, amíg az nem áll rendelkezésre. Amint a VE végrehajtotta az ominózus utasítást, az eredményt beírja a célregiszterbe, s V-bitjét 1-ra állítja. Ettől fogva, e regiszter tartalma kiolvasható mindaddig, amíg amíg egy később kibocsátott utasítás ezt a regisztert nem használja újra célregiszterként. - A behívási folyamat áttekintése o Tételezzük fel, hogy a behívandó forrásoperandus Vbitje 1; ekkor az értéke beírható a VP megfelelő mezejébe, majd a VP-beli V-bitje 1-re állítható. Ellenkező esetben, ha a behívandó operandus értéke még nem áll rendelkezésre, a processzor az operandus értéke helyett egy azonosítót ír (pl. a hivatkozott regiszter számát) a VP megfelelő mezejébe, és a hozzárendelt érvényességbitet
nullázza. o Pl. add r1, r2, r3 //r3 (r1) + (r2) 17. oldal, összesen: 33 o A fenti utasítás operandusainak behívása esetén feltételezzük, hogy a regisztertárban az r1 Vbitje 1, míg r2-é 0 értékű. Az ábrán feltüntetett add utasítás esetében (r1) behívható, értéke (10) beíródik az Op1 mezőbe, és a hozzá tartozó V-bitet 1-re állítja. Ezzel ellentétben a második forrásoperandus még nem elérhető, ezért annak értéke helyett az (r2) azonosító íródik az Op2 mezőbe, és a hozzárendelt V-bitet nullázza. Várakozó pufferek frissítése - Miután egy VE a rábízott művelet végrehajtását befejezte, az előállított eredménnyel aktualizálni kell a regisztertárat és VP-ket. A frissítéshez az eredménysínen az eredmény értékének és azonosítójának (pl a célregiszter számának) kell megjelennie. A VP-k frissítéséhez először meg kell vizsgálni, hogy a létrehozott eredmény azonosítója szerepel-e a VP-k
forrásoperandus mezőiben. Ehhez asszociatív 18. oldal, összesen: 33 keresésre / beírásra van szükség, mivel más is várakozhat erre a regiszterre. A megegyező azonosítókat a processzor az eredmény értékével helyettesíti, és a hozzájuk rendelt V-biteket 1-re állítja. - Globális (többszörös) frissítés: a létrehozott eredményeket minden olyan VP-be továbbítani kell, amelyben a létrehozott eredményre várakozó utasítások lehetnek. Ehhez gyakorlatilag minden VP-t frissíteni kell, az azonos típusú adatokat előállító (pl. FX) VE-k eredményeivel Ehhez a VE-k eredménysíneit vissza kell csatolni minden ugyanilyen típusú VP-hez. A VPk frissítéséhez általában többszörös asszociatív keresésre van szükség: annyiszorosra, ahány eredménysín érkezik a tekintett pufferhez. - A cpu megvalósítása valójában osztott regiszterű: Fig 18. ISSUE BOUND FETCH, Egy FX és egy LP processzorfél Összefoglalás Ábra: Fig. 21 Basic Shelving
o Az összes kombináció előfordul, A bekarikázottak a dominánsak Kiküldéshez kötött lehívás - - A processzor az utasításokat a forrásregiszterek azonosítóival együtt tárolja el a VP-k megfelelő mezőiben (Rs1, Rs2). A hivatkozott operandusokat a processzor csak később hívja le, a végrehajtandó utasításoknak a VE-kbe való kiküldésekor. Kiküldés közben a műveleti kódokat (OC) és a kiküldött utasítások célregiszterazonosítóit (Rc) a processzor a VP-ből a megfelelő VE-be továbbítja, míg a Rs1, Rs2-t az operandusok lehívása érdekében a regisztertárba küldi. Így némi késleltetéssel Rs1 és Rs2 is megjelenik a megfelelő VE bemenetén. Ekkor nincs szükség a forrásoperandusok rendelkezésre állásának ellenőrzésére, mivel kiküldéskor már biztosra vehetjük azok meglétét. Ez esetben a VP-k aktualizálására sincs szükség Mindkét megoldást széles körben használják. Mára a kiküldéshez kötött dominánssá vált
Az utasítások kiküldésének módja o Kiküldési politika: ez szabja meg a végrehajtásra kiküldendő utasítások kiválasztásának és a kiküldési blokkolódások kezelésének módját. o Kiküldési ráta: meghatározza, hogy maximálisan hány utasítás küldhető ki ciklusonként, a VPkből a VE-kbe 19. oldal, összesen: 33 o Operandusok rendelkezésre állása: annak megállapítása, hogy egy operandus rendelkezésre áll-e - Kiküldési politika o A szelekciós szabály határozza meg, hogy a VP-ben tárolt utasítások mikor minősülnek végrehajthatónak. Azok az utasítások hajthatók végre, melyeknek minden forrásoperandusa rendelkezésre áll. o A döntési szabályra akkor van szükség, ha a továbbíthatónál több végrehajtásra alkalmas utasítás létezik. A megoldás az idősebb utasítások előnyben részesítése (Power2, Pentium Pro) o A követett kiküldési sorrend szabja meg azt, hogy egy nem végrehajtható utasítás megakadályozza-e a
sorban következő végrehajtható utasítás kiküldését. Sorrendben történő kiküldéskor csökken a teljesítmény, viszont elég csak a VP-k utolsó bejegyzéseit vizsgálni (egy VE esetén jó) A részben sorrenden kívüli kiküldés azt jelenti, hogy adattípusonként eltérő a megvalósítás. Például a Power2 csak a lebegőpontos utasításokat várakoztatja, és kiküldéskor csak egyetlen nem végrehajtható lebegőpontos utasítást „tud átlépni”. Sorrenden kívüli esetén bárhonnan kiküldhető a független utasítás, tehát a VP-ben lévő minden utasításról el kell dönteni, hogy végrehajtható-e (hatékonyabb, komplikáltabb, domináns). Csoport- vagy központi várakoztató állomások használata esetén hatékony, pl. Pentium Pro Az utasítások dinamikus gyakorisága miatt az FX-eket érdemes sorrenden kívül, az FPket pedig sorrenden kívül kiküldeni. Általános célú felhasználás esetén: FX 40%, L/S 35%, B 20%, FP 5-10%
- Kiküldési ráta o egy VE esetén 1-nél több utasítás kiküldésének nincs értelme. Több VE esetén viszont 1-nél többet kell. Ideális esetben egy VP-nek annyi utasítást kellene kiküldenie ciklusonként, ahány VE-t a VP kiszolgál. A CPU kiküldési rátája: a VP-ek kiküldési rátájának összege o A CPU kiküldési rátája hogyan viszonyul a CPU kibocsátási rátájához? A kettő átlagának időben azonosnak kell lennie. A kibocsátási ráta a második generációban jellemzően 4 (RISC), és 3 (CISC). o Míg a várakoztatás a függőségvizsgálat későbbre halasztásával a legtöbb ciklusban lehetővé teszi a kibocsátási rátának megfelelő számú utasítás kibocsátását, addig bonyolult LP utasítások több ciklusra is lefoglalhatják a VE-ket. Így a feldolgozás szűk keresztmetszetének elkerülésére a processzornak ciklusonként több utasítást kell tudnia kiküldeni, mint amennyit a VP-kbe tud kibocsátani. 20. oldal, összesen: 33
o 7.3 táblázat: Nagy részük második generációs rendszer 1995-96 A kiküldési ráta kb 50%-kal magasabb. - Operandusok rendelkezésre állása o Direkt-vizsgálat: az operandusok rendelkezésre állását a V-bitek vizsgálatával állapítja meg. Ezt a módszert használják kiküldéshez kötött operanduslehívás esetén, mivel ebben az esetben a 21. oldal, összesen: 33 VP-kben tárolt utasítások nem tartalmaznak explicit utalást arra nézve, hogy a forrásoperandusaik rendelkezésre állnak-e vagy sem. o Explicit érvényességbitek: feltételezzük, hogy a VP-kben az operandusokhoz hozzá van rendelve egy Valid bit, amely a rendelkezésre állást jelzi. A CPU ezeket vizsgálja, hogy kiküldhetők-e a VE-k felé. Van egy Valid bitje a regisztertárnak is, mert tudni kell, hogy a lehívott érték érvényes-e. Ezt a módszert tipikusan kibocsátáshoz kötött operanduslehívás esetén alkalmazzák. A Regiszter-átnevezés (register renaming, RR) o Az első
generációból a másodikra való átmenetnél szükséges a kibocsátási szűk keresztmetszet kiküszöbölése, vagyis az ál-adatfüggőségek feloldása. (WAR, WAW) o Az átnevezés elve, pl. WAW esetén I 1 : add r 1 , r 2 , r 3 I 2 : mul r 1 , r 4 , r 5 I 3 : R 4,2 := r 1 , mul r 4,2 , r 4 , r 5 o A megvalósítás Ha nincs átnevezés, az eredmények beíródnak a regisztertárba Ha van, egy átnevező regisztertár jelenik meg (puffer) A CPU nem az architekturális regiszterbe teszi, hanem a RRF-be, csak később kerül az ARF-be o A megvalósítás főbb kérdései: Az álfüggőségek megszüntetése volt a cél, amihez elvben csak függőségek esetén kellene az átnevezést megvalósítani. Az egyszerűség érdekében azonban minden célregisztert át kell nevezni, hogy ne kelljen bonyolult függőség-ellenőrzést végezni. Következmény: minden forrásregisztert át kell nevezni lehíváskor. Meg kell keresni, hogy az átnevezett
forrásnak melyik puffer felel meg. Pl • Mul r 1 , r 4 , r 5 • r 4,4 := r 1 • Sub r 10 , r 1 , r 9 //Az r 1 már nincsen, át lett nevezve • r 10 , r 4,4 Az átnevezések nyilvántartása: • Átnevezőtábla: a táblának annyi bejegyzése van, ahány regiszter van. Pl r 0 r 31 Indexelt tábla, amely nyilvántartja, hogy pl. az r 1 r 4,4 lett • Asszociatív átnevezőtábla: nem indexelt, hanem asszociatív struktúra Az átnevezések érvényessége: kibocsátáskor nevezzük át a regisztert. Szekvenciálisan konzisztens módon, amikor sorrendben írja ki a CPU az eredményeket. Akkor szűnik meg az átnevezés, amikor kiírjuk az ARF-be (ROB) • Add r 1 , r 2 , r 3 • Add r 4,4 , r 2 , r 3 - Az operandusok rendelkezésre állásának elve o Operandusok lehetnek: RRF-ben / ARF-ben. A lehívást mindkettőből meg kell oldani: ha nincs az RRF-ben (prioritás), akkor az ARF-ből kell venni. - A regiszter-átnevezés megjelenése Ábra: Fig. 2
Chronology of the introduction of renaming o Alpha: 1998-ban vezette be az RR-t, ezek voltak a leggyorsabbak o Filozófia: hatékonyabb, kisebb órajel. Lassabban működik Az RR lassít, ezért nem vezették be 22. oldal, összesen: 33 - Az RR megvalósítása, tervezési tere o Átnevező pufferek megvalósítása: • Önálló RRF: csak az átnevezésre szolgál. FX-re és FP-re külön RRF és ARF van (PowerPC) • ROB: az átnevezés a ROB-ban valósul meg. Kibocsátáskor minden utasítás kap egy azonosítót: egy állapotmezőt és egy adatmezőt. Amikor az utasítás kiírjuk, akkor az adat is kiíródik. Pl Pentium Pro, Athlon • Összevont ARF és RRF: ez korszerű. Kiíráskor nem kell az utasítást kiküldeni, elég átcímkézni azt. • Átnevező pufferek megvalósítása osztott pufferek esetén: o külön fixpontos és lebegőpontos regiszterre tagolódik o A CPU egy fixpontos, illetve egy lebegőpontos részből áll o Az átnevező regiszterek száma -
Összevont esetén egy fizikai blokkban van az ARF és az RRF: az ábrán a kettő összege szerepel. Az átnevező puffernek kell a legnagyobbnak lennie, mert itt sok félkész utasítás van. Ettől kisebb az átnevező pufferek száma, illetve az ablak. - Power4: összevont, 80 fixpontos és 72 lebegőpontos regisztert alkalmaz. 23. oldal, összesen: 33 o Pufferek kezelése Önálló RRF: kibocsátáskor a célregiszter kap egy puffert. Ekkor értéke még nem érvényes, mert még nincs kiszámítva. Ha a VE kiszámolta a regiszter tartalmát, akkor az utasítás státusza finished lesz. Kiíráskor a puffer értékét az ARF-be írjuk, ekkor completed. A puffer újra rendelkezésre bocsátható: reclaim. Összevont ARF+RRF: Inicializálás, amikor az átnevezés megtörténik, akkor pufferré válik, még nincs benne érvényes utasítás. Kiíráskor az AR hordozza az ARF értékét. Címkeváltás történik áttöltés helyett: r44-ből r1 lesz. Ha az r1-et újra átnevezik,
ez feleslegessé válik, az előbbi újra szabad puffer lesz. o A regiszter-nyilvántartás megvalósítása 24. oldal, összesen: 33 Indexelt forma: egyszerűbb elérés, de minden egyes lehetséges értékhez hozzá kell rendelni egy Valid mezőt és a puffer azonosítóját. Ezek adott architekturális regiszterhez vannak rendelve. Asszociatív megoldás: a szükséges elemszám kisebb, mint a lehetséges; a megvalósítás viszont lényegesen komplexebb. Az előkerülés sorrendjében történik a beírás Összevonják az átnevező pufferrel. Mezők: Valid bit, Célregiszter, Számérték – operandus-érték, Eredmény-érvényesség bit, Utolsó bit: ha azonos regszámra történik a bejegyzés, akkor az egy időben érvényes többszörös lekéréseket lehet kivédeni. Átnevező eljárások áttekintése: • • • • • RR megvalósítása (típus és darabszám): összevont, önálló, ROB átnevezés nyilvántartása: átnevező ráta (nem
minőségi szempont) Lightning: túl komplex volt, nem fejezték be, ehelyett a K6 kell az ábrára Átnevezési ráta: egyenlő a kibocsátási rátával 25. oldal, összesen: 33 Az átnevezés folyamatának megvalósítása Kibocsátáshoz kötött operandus-lehívás – – – – – A mikroArchitektúra egy egyszerűsített változata: – egy VE, egy várakoztató állomás – egy önálló regiszter az architekturális regiszterhez, leképező tábla – feltételezzük, hogy az utasítások lehívása, kibocsátása sorrendben történik (sorrendi dekódolás) Kibocsátás: Megérkeznek az utasítások, meg van adva a forrás- és célregiszter. Az operációs kód bekerül a várakozó állomásba. A célregisztert átnevezi, ehhez kell hozzárendelni egy új átnevező puffert Megvizsgálja, van-e még szabad regiszter, ha van, hozzárendeli, a kapcsolatot rögzíti az átnevező táblában. Meg kell nézni, van-e hozárendelt átnevezőpuffer, ha nincs, az ARF-ből
kell venni a forrásoperandust. Ez egy időben két logikai döntést igényelne, ezért a megvalósítás párhuzamos. Egy prioritás-logika: ha mindkettő létezik, az átnevezőpuffer részét továbbítja. ARF-be csak akkor kerülnek értékek, ha azok érvényesek, ezért nem kell Valid bit. Kiküldés: Amikor az eredmény megszületett, vele együtt a célregiszter azonosítóját is továbbítani kell. Az RS-ben lévő értékeket frissíteni kell, mert lehet, hogy erre a regiszterre egy másik utasítás vár. Szekvenciális kiíráskor: programállapot módosítás. Ekkor módosíthatja az ARF értékét, majd az RRF allokációt vissza lehet vonni, meg lehet szüntetni az átnevező táblában az erre utaló összefüggést. Kiküldéshez kötött operandus-lehívás – Az utasítások bekerülnek egy RS-be: utasítás kód, célregiszter, két forrásregiszter. Ekkor következik a lehívás, majd végrehajtás. A CPU-nak vizsgálnia kell az RRF-et, hogy az operandus
rendelkezésre áll-e A kiszámolt érték nem módosítja az RRF-et, nincs aktualizáció. Komplikáltabbá válik az átnevező pufferek megszüntetése. Lehet, hogy a következő utasítás használja ennek az értékét – Kibocsátás: Egy új átnevező reg a célregiszterhez, ha a megadott forrásregekhez létezik érvényes átnevezés, az átnevezett értékeket írja be a várakoztató állomásba. Az operandus nem kerül lehívásra – Kiküldés: vizsgálni kell az opok meglétét, lehívás párhuzamosan. – Szekvenciális kiküldéskor: a programállapotot módosítjuk, a RR tartalma átkerül az ARF-be. Az átnevező reg visszaadása komplikáltabb, lehet hogy az eredményre utasítások várnak. Pl – – – 26. oldal, összesen: 33 add r1,r2,r3 mul r1,r3,r5 Egy számlálót növelnek minden egyes bejegyzéskor, ha az operandus használja. Csökkenti, ha az op ki lett küldve. Ha minden opot a CPU felhasznált, a számláló nulla, meg lehet szüntetni az
átnevezést a táblában is. Ez egy megvalósítás, a többi kismértékben tér el ettől Párhuzamos végrehajtás - Globális tervezési tér o Utasítás-lehívás o Dekódolás o Kibocsátás (V / Á) o Végrehajtás o Szekvenciális konzisztencia Az utasítás-végrehajtás tekintetében A megszakítás-kezelés tekintetében - Végrehajtás o Tendencia a CPU-k végrehajtási szélességének növelése (RISC 3. gen: 4+) RISC 1. gen: 2-3 (FX-FP-L/S VE-k) RISC 2. gen: 4 (3db FX – 2 db L/S – 3 db FP) (+,-,/ külön, mert akár 20 ciklusig is dolgozhat) • Az utasítások eloszlása azonban dinamikus, sztochasztikusan változik: általános célú programokban ez az eloszlás: FX (40%), L/S (2/3 L, 1/3 S, 30-40%), Elágazás (20%), FP (5%) Ma kb. 10 VE jellemző o Utasítás/Ciklus vagy frekvencia növelése a követendő két különböző fejlesztési lehetőség - 27. oldal, összesen: 33 Szekvenciális konzisztencia o Az utasítás-feldolgozás
szempontjából Egy program logikája olyan, hogy az utasítások sorrendje releváns. Mivel a CPU regisztertere és memóriatere eltérően módosulhat, a beírás-olvasás viszonya eltérő lehet párhuzamos végrehajtás esetén. Döntően a beírás szempontjából és a LOAD-STORE közötti viszony. (nem cserélhető fel kettejük sorrendje) Feltétel, amit teljesíteni kell: mintha egy szekvenciális processzor lenne, úgy kell működnie a rendszernek: szekvenciálisan konzisztens működés A megvalósítás módja, a 2. generációs szuperskalároktól kezdve a ROB • Körpuffer bejegyzésekkel, jellemzően két pointer: beíró-kiíró, utasítások egyéni azonosítója a pufferen belül, illetve az állapota: várakozik, végrehajtott. Az utasításokat a ROB kibocsátáskor befogadja. Minden utasítást a CPU a ROB-ba bejegyez. Jelölve: kibocsátva Az állapotmódosításokat a CPU kezeli Ha végrehajtva az utasítás, jelölve van a ROB-ban. • Csak
sorrendben engedi meg a kiírást a pufferből, vagyis a regiszterekbe, illetve a memóriába. A pointernek azt kell vizsgálnia, hogy az összes korábbi utasítás végre van-e már hajtva. Ha igen, a kiírás megtörténik o A megszakítás-kezelés szempontjából Ha logikailag korábbi, időben későbbi a megszakításkérés, akkor az INT megszakítja az utasítások végrehajtását Megvalósítása: az utasítás megszakítását addig jegelni kell, amíg az utasítást ki nem írjuk, vagyis az érvényre jutás csak a kiírás után megengedett. Processzor-struktúrák (processor data path - adatút) - A ráfordítás mérésének fontos részei a széles adatutak (2x64 bit), kevésbé fontos részei pedig a regisztertárak - Mitől függ ezek szélessége? o Lehívás (32 bit), Dekódolás o Kibocsátás: várakoztatás, RR o Az utasítás kibocsátás mikéntje a várakoztatás és az átnevezés módján múlik, továbbá az operandusok lehívásának mikéntje is
fontos (kib. vagy kik kötött) A lehetséges cpu struktúrákat ez a három alapfeladat megvalósítása szabja meg. - A lehetséges CPU-struktúrák szempontjai o A kibocsátás tekintetében melyek a legfontosabb eljárások, amelyekben érdemben eltérő adatutak vannak? Ábra: Fig. 541 Basic structure Főbb típusok, az utasítás lehívásának módja Átnevezés: balra, függőlegesen Az egyes megvalósítások egymást kizárhatják: ld. a kihúzott részeket Elvben 24 eltérő cpu struktúra lehetséges A változások azért következhettek be, mert nem voltak a megoldások elég jók Operandus csak a Merge-ből indul el a feldolgozóegységekhez, az eredmény pedig innen megy a VE-hez. Ez a nyerő megoldás a cpu felépítésében Ábra: Fig. 9 Basic datapath o Esettanulmányok PowerPC 620 (ábra) • 6 db feldolgozó egység • Minden VE-nek saját puffere van 2-4-es mérettel • Átnevezés, ROB, ARF MIPS R10000 (ábra) • Csoport
várakozóállomás • Kiküldéshez kötött az utasítás-végrehajtás Pentium Pro (ábra) • Központi várakozóállomás Pentium 4 • Trace cache: a dekódolt utasításokat tároló cache • Elágazásbecslés, átnevezés 28. oldal, összesen: 33 Különböző filozófia - AMD: elődekódolás: 3 bit / byte, makroutasítások dekódolása o K8 kiküszöböli a mikro-t, az időkorlátot megszünteti, L1 64k - Intel: trace cache o Mikroutasítások dekódolása, L1 8k Szálszintű architektúrák (multi threaded a. / micro a) Megjelenésük szükségessége - Nem kikerülhető fejlődési fokozat - Soros proc (i286(1982)), Futószalagos proc (i386 - i486), szuperskalár (Pentium, Pentium Pro) - Az általános célú programokban az utasításszintű párhuzamosság kimerült a: o multimédia támogatással (PII), illetve o a multimédia + 3D támogatással (PIII, PIV) - A dedikált növelés is kimerült - A következő lépcsőfokot a hardveresen többszálú
architektúrák jelentik Technikák - Egyszálas: egyetlen utasításfolyamban a processzor már kimeríti a rendelkezésre álló párhuzamosságot (párhuzamosan feldolgozható utasítások – utasításfolyam) - Többszálas: több szál egyidejű futtatása o Tudnia kell a két szál között különbséget tenni, illetve több állapotot kell kezelnie o Pl. IBM Power4 (2001), P4 Prestonia (2002), Pentium 4 Northwood (2002) 3,06GHz-től Megvalósítás - Többmagos egyszálas: egy lapkán két vagy több processzor-maggal o A cache-ekben osztoznak, a megvalósítás az egyes rendszerekben eltér o Egy mag egy szálat dolgoz fel, közös cache o Értékelés: Többlethardver: 60-70%-kal több Többletteljesítmény: 50-60% általános célú alkalmazásokban - Többszálas egymagos: egyetlen többszálas processzor-maggal o SMT, pl. kétszálas mag: ezen belül tesznek különbséget az állapotok között, pl külön regiszterkészlettel o Értékelés:
Többlethardver: 5%-kal több Többletteljesítmény: erősen alkalmazásfüggő: -10-20%-tól +20%-ig (zavarhatják egymást) o Az egyprocesszoros rendszerekben a disszipáció okozza a korlátot. Két mag 200W+, léghűtéssel érdemben nem kezelhető. A többmagos technikához csökkenteni kell a disszipációt Tényleges megvalósítások Ábra: többszálas processzorok jelene és jövője - többmagos egyszálas o IBM Power4: kétmagos o UltraSparc IV o Sun Niagara: 8 mag, 4 szál,2006-7 (5 futószalag fokozat, egyszerű magok) o AMD Opteron Dual o Intel két Prescott maggal: Tulsa Többmagos egyszálas HT helyett, Pentium M-mel. Kétmagos VLIW Itanium: két szálat kezel - egymagos többszálas o Intel Hyperthreading, ami megfelel az SMT-nek = Symmetrical MultiThreading o A feldolgozás keverve történik, a jelzőbitek kezelik az állapotmódosításokat o Szimmetrikus, a kettő között nincs különbség - többmagos többszálas 29. oldal, összesen: 33 o
Power5: AS/400 és OS/400 összehozva, a Power5 már mindkét célra alkalmas (konvergencia), kialakult a virtuális technika, logikai particionálás (a hardver erőforrásokat futás közben kezeli). Figyeli a kihasználtságokat, átcsoportosítani is képes. Dinamikus allokáció - Rendszerarchitektúrák teljes számítógépes rendszer: cpu, cpu-busz, lapkakészlet, kiegészítő chipek, lan, scsi, video A fejlődés áttekintése Ábra: Fig 24 system architecture - ISA: minden ezen keresztül valósult meg - PCI: egyszerűbb, fejlettebb - Portalapú rendszerek, sínrendszerek helyett: P3-P4 A fejlődés főbb állomásai - ISA o a buszvezérlő gondoskodik a memória és a billentyűzet kezeléséről o minden kártyákon keresztül valósul meg (ISA based system architectures) - Straight forward PCI-based system architecture o A vezérlés kettéválik, északi és déli híd, amelyek a PCI-on keresztül kapcsolódik o Északi: L2 és memóriakezelés, itt nagyobb
sávszélesség szükséges o A perifériák PCI vagy ISA buszra is kialakíthatók, jellemzően 4-5 PCI slot és 2-3 ISA - PCI-based system a with IDE/ATA and USB ports o A déli híd a vinyók kezelését, két csatorna, négy eszköz, és néhány usb-s rendszer o Megmarad az ISA, de a a sebessége miatt a PCI dominál - PCI-based system a with AGP, IDE/ATA and USB ports o ISA a háttérbe szorul (1 vagy semennyi) - Ports-based o Szinte minden portokon keresztül kapcsolódik a rendszerhez, az ISA nem tartozék, csak egy hídon keresztül csatlakoztatható (opcionális) o A PCI is elvesztette jelentőségét, mivel minden a déli hídhoz kötődik o Super IO: keyb, ms, fd, sp, pp, ir o AC ’97 o FPM-EDO-SD RAM - Soros buszokat és portokat használó rendszerarchitektúra o A párhuzamos buszok ideje lejárt, mert Az FSB (Front Side Bus) 64bites, megjelennek a 0-1 átmenetek, az északi híd bemenetén megjelenik egy SKEW, ami a futási idők eltéréseit jelenti. Azért van
eltérés, mert az egyes biteknek eltérő távolságot kell megtenniük a híd és a proci között. Korlátozza a teljesítményt. A kapacitív terhelés sem azonos: különböző meredekségű a felfutás A buszkorlátot 3-4Ghz környékén érték el. HT: soros buszok, annyi van belőle, amennyi kell. 1 bit = 2 Gbit sávszél 2GHz mellett RS-242 USB, ATA SATA, SCSI SAS, PCI PCI X, AGP 16 bit PCI Express AMD FSB HyperTransport, az Intel is megjelenik majd a soros busszal A rendszer-arhitektúra főbb elemei - FSB o Szélesség (address bus - data bus) 8086 (20-16), 8088 (20-8), 80286 (24-16), 80386 (32-32), 80486 (32-32), Pentium (3264), Pentium Pro – P4 (36-64+8) o Frekvencia, a P4 példáján 400MHz FSB, 1,5GHz Willamette = 400 / 1,5 = 0,25, 2Ghz, 0,2 elérése esetén váltás (tapasztalat), ezért emelik rendszeresen a buszfrekvenciát. (1066MHz a vége jelenleg) A buszon keresztül történik a kommunikáció a memóriával, az
AGP-vel és a déli híddal is, ezért a busz szűk keresztmetszetté válik Ezen segít a soros busz, sávszélessége lényegesem nagyobb lehet - Lapkakészlet (chipset) Ábra: Xeon MP o 286-tól, 386-ban már mindegyik rendszerben van chipset 30. oldal, összesen: 33 o Pentium 4 Az összes családnak egy mag az alapja, az eltérés a cache-ben, órajelben van DP = kétprocis, MP = multiprocis (A Netburst-öt 10GHz-ig hirdették anno) Többszálas, 64 bites kiterjesztés o A Desktop vonal áttekintése, lapkakészlet szempontjából (Fig. 28) G: integrált video Fontosak a procikhoz illeszkedő lapkakészletek: 845- 865 – 915 Ábra: 845xx family, Figure 2.2 • Memory control hub, Egycsatornás memóriavezérlő, SD / DDR RAM • P4 elsők Rambus rammal 850-860 chipkészlet, helytelen döntés volt • Buffered (nagy kapacitás esetén, szerverek – 16 Gb), unbuffered (jellemző, 24Gb), ECC • Gyors fejlődés: Ábra: fig 3.2, a teljes család o ICH =
I/O Control Hub, Kétcsatornás: 4 gb o HI: 16 bites, 266MB/s o DMI: 2Gb / s, 4 bites soros rendszer o HDA = High Definition Acoustic Interface Lapkakészletek sávszélességének vizsgálata - Különböző buszok: memóriabusz, grafika, stb. - Processzorbusz: 64 bit, sávszélesség 8byte x Fc (órajel) - SDRAM: 8xFsdram - Hagyományos: HI 1.5 – 8 bit 266MB/s (duplája a PCI-ének) o A fejlesztés alapöltlete az volt, hogy két PCI busz jön a déli hídból. 2x133 = 266MB/s - 910-es chipben PCI express, 4x1bit, soros busz, 2000MB/s, bitenként és irányonként - PCI: 2,5 Gbit/s, kódolása 10 bites, mert órát nem tartalmaz. Nettó sávszélessége irányonként 2 Gbit - HI: 16 bites, 2x266MB - CSA (Communications System Arch): 848, 865 – 8 bit, 266MB - HI 2.0 szerverekben: 16 bit: 1066MB/s - PCI E x8 = 8x1bit, 4000MB/s Ábra: Table 5.4 peak bandwidth - AGP8 – 2132MB - SCSI Ultra 320 = 320MB – fenntartott sebesség: 60-90MB egységenként - SATA 1.0 – 150 - PCI –
133MB/s - PCI-x 64 /66MHz – 533 A sávszélességviszonyok két chipkészletben Ábra: Fig 5.5 – peak bandwidth - CPUbusz – 3200MB/s, szűk - Déli és északi között szűk keresztmetszet - probléma - Ezt oldották fel a 915xx családdal Ábra: Fig. 56 peak b values - PCIx 16 – 8000MB - Északi-Déli között 2000MB - GigaBit Ethernet = 500MB, négyet is ellát belőle - A processzorbusz lesz a keskeny sávszélesség, szükséges itt is a soros busz megjelenése Lapkakészletek megvalósítása - A GigaBit Ethernet Controller csatolása alapesetben, desktop család Ábra: Fig. 64 widely o PCI buszon, 125MB kell, 133 van (elég) o Intel 848-tól az északi hídra új CSA busz, 266MB, kétcsatornáshoz elég o Szerverekben egy vagy kétcsatornás megoldás. A nagyobb HI 2 interfészre egy PCIx hidat tesznek, erre kapcsolódik a GBE vezérlő o Aztán PCIx 64, a kontroller erre kapcsolódik o Mindegyik megoldás sántít, mert a déli északi közötti kapcsolat szűk 31.
oldal, összesen: 33 Ábra: fig. 65 alternatives o PCIx: 1 bites is elég, 400MB, ezekre kötik a kontrollert, vagy 4 bites híd o A legjobb megoldás: 8 bit külön kezelhető o SCSI Gyors, nagy megbízhatóság, szerverekbe Ultra 160 ill. 320, mindkettőben egy- és kétcsatornás megoldás Északi híd + PCIx híd + SCSI Ábra: Fig. 73 alternatives SCSI o Grafika Ábra: Fig. 74 P4-based Szerverekben az északi hídba építve, nincs rá nagyobb szükség Desktop-ban külön kártya, PCI x16 Vagy grafika a PCI buszon nagy szerverek Alaplapok Megjelenésük - Az IBM PC megjelenése a kiindulás (1981, 8 bites CPU busz) - IBM PC-XT (1983), AT – 16 bites busz - Ezután jöttek a klóngépek – Compaq: hamar chipkészleteket kezdett használni, csökkennek a méretek (baby AT) - IBM AT – nincs lapkakészlet, nincs kártyás RAM, 305x350 AT méret Fejlődésük: Ábra: Fig. 92 - LPX: Riser Card: alaplapra szerelhető, erre kerülnek rá a slotok - ATX:
funkcionális javítás - BTX: jobb hőkezelés Ábra: Fig. 93 o Méret: szélesség x mélység, I/O hátul o A Maximális mélység, az I/O helye, a slotok helyei és a furatpozíció adott Az egyes típusok főbb jellemzői - AT o 8(rövid) /16 bit (hosszú) ISA, max 8 db slot o tápcsati bárhol lehet, keyboard o IBM: A BASIC ROM-ban volt, nincs lapkakészlet, billentyűzet van, I/O a kártyákon, kazettásmagnó a fő tároló - Baby AT o Méretcsökkenés a kártyás SIPP RAM-nak köszönhetően (30 pin, 1byte 4 byte), 386-tól o SIMM (kétoldalas, 30pin majd, 30-72-168 pin az út) Fig. 96 rajz o 386 CPU, L2 DIPPként, SIMM 30 RAM, ISA 8/16, billentyűzet o Tápcsati akárhol - Pentium alapú Baby AT o Pentium CPU, L2-ből 2 chip az alaplapon o SIMM 72 RAM, ISA 16 o PCI 32 bit, számuk nem szabványos o Alaplapra integrált vezérlők: FDD, HDD - LPX (1986) o Keskeny dobozokhoz Ábra: Fig. 99 o Pentium, L2, SIMM 72, HD-FD, IO: a lap teljes hosszán - ATX o Az első igazi
standard o 1994 – Pentium Pro o Jellemzők: Kétsoros IO csatlakozók, kisebb szélesség - NLX o o BTX o o o 32. oldal, összesen: 33 CPU a táp mellé, egy venti elég a tápban, 15W kb. FD, HDD közel az előlaphoz, nem kell hosszú kábel, kisebb sugárzás Könnyen elérhető RAM 6 slot: ISA + PCI, vagy combo ISA-PCI slot, csak az egyik használható Korai P2-P3 ATX • Slot1, L2 külön buszon, ez igényelte a slotot • DIMM 168pin, 64bit • Emeletes IO • ISA háttérbe szorul, AGP – 1997-től támogatja az ATX P4 ATX legújabb • 3PCI + socket CPU, L2 chipen belül • DIMM 168 • PCI X 2x1bit • PCI E 16 grafika • SATA 4 port, elég egy ATA A funkcionális javítást szolgálja Slot1, riser cardon slotok, HD, FD Cél a hűtés megoldása picoBTX : 1 slot, mikro: 3-4, BTX: 6-7 slot CPU, chipset egy sorban a jobb hűtésért Alaplapok élettartama Ábra: Fig. 928 - Vezérlések: kártya – lapon – chipsetben - Sorrend: kártyás
IO alaplapra dedikált vezérlő lapkakészleten belül Processzortípusok Ábra: Fig. 926 Memóriák Ábra: Fig. 927 IO Ábra: Fig. 928 - LPC: key, mouse, soros, párh port UI: ezt a doksit szinte szégyellem a nevem alatt kiadni, de hát Sima Dezső óráin jegyzetelni a kevés lehetetlen feladat közé sorolom. UFO http://doksi.hu 33. oldal, összesen: 33 Ez az első előadáson hangzott el, mintegy ELIGAZÍTÁSként. Ne nyomtasd ki! Óvd a fákat! Eligazítás Követelmény - Elvárások o Tömör, strukturált válasz a zh kérdésekre, a tendenciák bemutatása o zh a végén, az anyag változik a tavalyihoz képest (Pl. PCI Express, rendszer-architektúra) - Államvizsga: 10 perces előadás, megadott tételek alapján o Az előadás-fóliákat lehet használni a magyarázatokhoz o Előtte konzultáció, minden kérdésről érdemes vázlatot készíteni - Szakdolgozat: o Mérnöki munka, nem csak programozás o Pontos specifikáció, lehetséges megoldási módok, ha
vannak a megoldáshoz használható, már működő rendszerek, ezek leírása o Kritériumok kidolgozása: mi a legfontosabb számunkra a feladat megoldása során. Értékeljük a lehetséges megoldási módokat o Implementációs fázis, Dokumentáció o Előszó, összefoglaló részek – hogyan értékeljük mi magunk a megoldást; korlátok, illetve mi valósult meg a kitűzött célokból, mit kéne megvalósítani; saját munka méltatása (ezt olvassák el a legtöbben) o Irodalomjegyzék: ne alacsony színvonalú szakirodalmat használjunk fel, hanem elismert szaktekintélyek munkáit. Lehetőleg angol nyelvű is legyen köztük bizonyítandó, hogy otthonosan mozgunk az angol szaknyelvben is - Ajánlott irodalom: o SFK: Korszerű számítógép-architektúrák o Szuperskalár architektúrák
