Comments
No comments yet. You can be the first!
Most popular documents in this category





Content extract
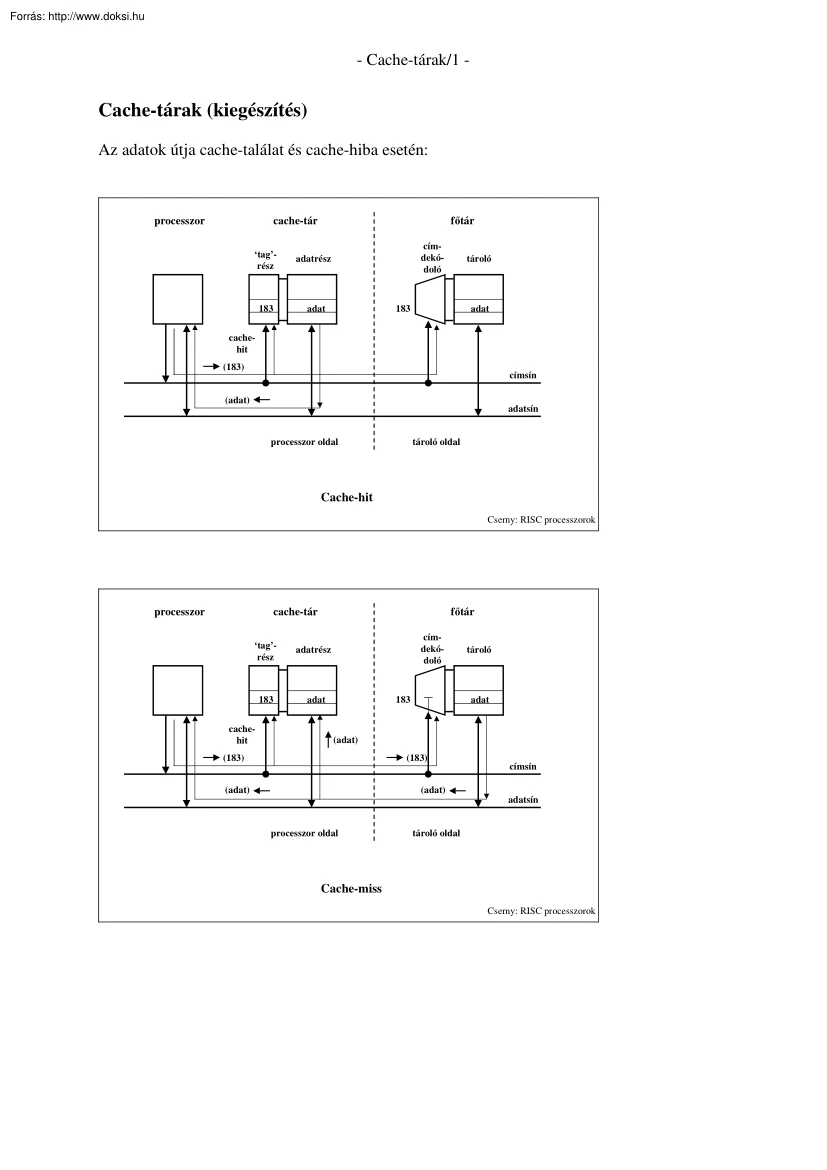
- Cache-tárak/1 - Cache-tárak (kiegészítés) Az adatok útja cache-találat és cache-hiba esetén: processzor cache-tár főtár ‘tag’rész adatrész 183 adat címdekódoló tároló 183 adat cachehit (183) címsín (adat) adatsín processzor oldal tároló oldal Cache-hit Cserny: RISC processzorok processzor cache-tár főtár ‘tag’rész adatrész 183 adat cachehit címdekódoló 183 tároló adat (adat) (183) (183) címsín (adat) (adat) adatsín processzor oldal tároló oldal Cache-miss Cserny: RISC processzorok - Cache-tárak/2 - A találati arány (cache-hit) A tervezéskor törekednek a magas találati arány elérésére. Találati arány: h = találatok száma/összes tárhoz fordulások száma Hiba arány: 1-h Átlagos elérési idő = h * tc + (1 - h) tmiss tc : cache-tár elérési ideje (~ 25 ns) tmiss : cache-tár elérési ideje + blokk beolvasása a főtárból + cache-be írás (~ 250 ns) Cache hiba
esetén az adatok elérési ideje 8 - 10-szerese a cache tár elérési idejének. Az átlagos elérési idő 95%-os találati arány esetén kb. 50%-kal nagyobb a cache elérési idejénél A cache tárak jellemzői, típusai Visszakeresés a keresett adat címe alapján történik. A címet (vagy annak egy része), amelynek alapján a visszakeresés történik "tag"-nek nevezik. A címen és az adaton kívül a cache az az adatok állapotára vonatkozó, a vezérlést segítő és a helyettesítési eljárást segítő adatokat is tartalmaz. Vezérlő bit-ek: V (Validity bit), érvényességi bit Az adat a megadott címhez tartozik, és helyes. A cache tár törlésekor (flush) az összes V-bit 0-ra vált. D (Dirty bit) A blokk egy része módosult. Nem lehet a helyére új blokkot betölteni, amíg ki nem írjuk a főtárba. C (Coherence bit) A 'V' és 'D' bit-tel együtt a főtár tartalma és a cache blokkjai közötti
egyezőség biztosítását segíti. SV (Supervisor bit) Jelzi, hogy a blokk felhasználói- vagy rendszeradat. A hozzáférési védelmet segíti. - Cache-tárak/3 PID (process identifier bits) Jelzik a blokk valamely feladathoz tartozását. Megakadályozzák az illetéktelen felhasználásokat. Használata esetén, nem kell a cache-t kiüríteni taszk váltáskor Helyettesítési bit-ek (replacement bits) A blokkok cseréjéhez nyújtanak információt. A visszakeresés módja szerint: Teljesen asszociatív cache A blokk bármely sorban lehet: rugalmas, hatékony, de költséges a sok öszszehasonlító áramkör miatt. Közvetlen leképzésű cache A blokk csak egyetlen sorban lehet. merev, a "tag" rövidebb Olcsó, mert nem kell asszociatív memória, de a találati arány alacsonyabb. Csoport asszociatív cache A fenti két megoldás között helyezkedik el, elég hatékony, és nem túl költséges. Tartalmának karbantartása A
tartalom betöltése az igény felmerülésekor (demand fetching) előkészítéssel (prefetch) Aktualizálás azonnali átírás (write through) visszaírás (write back) Helyettesítési eljárások véletlenszerű csere FIFO-elv (First-In-First-Out) Legkevésbé használt elemek cseréje (LRU) Adategyezőség biztosítása A főtár és a cache tartalmának egyezőségét biztosítani kell! A főtár és a cache tartalma több okból is eltérhet: a processzor a cache-ben módosít, majd csak később aktualizálja a tárat (writeback módszer) a főtár tartalmát egy másik egység módosítja (lapváltás, I/O DMA-val) több processzor is használja a tárat több cache is van a rendszerben - Cache-tárak/4 (a) Visszaírási módszerek A közvetlen átírás (write-through) módszer problémamentes. A cache módosításával együtt a főtár is aktualizálva lesz A visszaírási (write-back) módszer problémát okozhat,
ha a tárat más egység is használja (DMA). (b) A cache tár strukturális elhelyezkedése az adatáramlási útvonalon 1. Címfordítás szempontjából A virtuális tárkezeléshez kapcsolódik. Processzor - Tárolókezelő (MMU) - Cache tár - Főtár elrendezés A cache tár fizikai címeket kap. Egyértelmű megfeleltetés van a cache tár címei és a főtár között. A cache használata lassulhat. Processzor - Cache tár - Tárolókezelő (MMU) - Főtár elrendezés A cache virtuális címekkel dolgozik, így a cache működése gyors. Különböző folyamatokhoz tartozó virtuális címeket ugyanahhoz a fizikai címhez rendelheti az MMU (szinonimák). Ezt a problémát külön áramkörökkel (TLB, ITB ) kezelik. 2. I/O átvitelek szempontjából Az I/O átvitel közvetlenül a főtárba/-ból Figyelő rendszert (snoop logic) alkalmaznak, amely minden címet ellenőriz a cache-ben, amelyhez tartozó adat a sínen áthalad. Ha a főtár tartalma változik,
és az adat a cache-ben is megtalálható, a figyelő logika a cache tartalmát érvényteleníti (V-bit), vagy aktualizálja a cache-t. A főtárból olvasáskor, ha az adat a cache-ben is megtalálható, a cache-ből szolgálja ki az adatot. Az I/O átvitel a cache-en keresztül (I/O through cache) Nincs adat-egyezőségi probléma. A cache forgalma megnő A cache-hez többszörös hozzáférést kell biztosítani MESI protokoll Több processzoros rendszerekben még nehezebb az adategyezőség biztosítása (különösen, ha több cache is van). Elterjedt a MESI protokoll használata. A MESI elnevezés a cache blokkjai aktuális állapotainak: Modified, Exclusive, Shared, Invalid kezdőbetűiből tevődik össze. - Cache-tárak/5 - SHR Lehetséges állapotok: SHW I S RMS RH SHR M E S I modified exclusive shared invalid WH SHW WM SHR RME Állapotátmenetek: SHW RH M WH E RH WH RH read-hit WH write-hit RMS read-miss, shared RME read-miss, exclusive WM
write-miss SHR snoop-hit on a read SHW snoop-hit on a write /read with intent to modify MESI protokoll állapotdiagramja Cserny: RISC processzorok A cache blokkok állapotai az alábbi 4 állapot valamelyikében lehetnek: Módosított (modified) A cache blokkja a főtárhoz képest módosítva lett, és ez az egyetlen érvényes adatblokk. Kizárólagos (exclusive) A cache blokk a főtárral egyezik, érvényes, és más cache-ben nem fordul elő a blokk. Megosztott (shared) A cache blokk a főtárral egyezik, érvényes, de legalább még egy cache-ben megtalálható a blokk. Érvénytelen (invalid) A cache blokk érvénytelen adatot tartalmaz. Az egyes állapotok közötti átmenetet kiválthatja olvasás/írás a cache-ből/-be a figyelő logika - Futószalagos és szisztolikus architektúrák/1 Futószalagos és szisztolikus adatpárhuzamos architektúrák Mindkét architektúrára jellemző, hogy egy nagy adatkészlet elemein képes
hatékonyan elvégezni ugyanazokat a számításokat anélkül, hogy a vezérlésen változtatni kellene. Az egymás utáni eredmények olyan ütemben keletkeznek, amilyen ütemben a bemeneti adatok eljuthatnak a rendszerhez. Futószalagos architektúrák Legfontosabb alkalmazása a képfeldolgozás. Az alkalmazás legfontosabb jellemzői: azonos műveleteket kell elvégezni egy hosszú adatfolyamon a számítások eredménye minden pontban csak korlátozott számú szomszédos képpont függvénye Az ábra elvi megoldást mutat arra, hogyan lehet a fenti két jellemzőt kiaknázni a képfeldolgozás teljesítményének növelésére. Bemenő adatok Léptetőregiszter Léptetőregiszter Kimenő adatok Adatpárhuzamos futószalag Sima: Korszerű számítógép architektúrák A képpontokból alkotott adatáram léptetőregiszteren keresztül éri el a tárolóelemeket, amelyekből aztán a feldolgozóelem a szomszédossági követelményeknek megfelelő adatokat
közvetlenül felhasználhatja. A léptetőregiszterek annyi tárolóelemből állnak, ahány képpont alkotja a feldolgozandó kép sorait. A párhuzamosságot itt az jelenti, hogy a feldolgozóelem egyszerre képes fogadni a környezetében lévő adatokat, - és a processzor bonyolultságától függően - az eredmény kialakításában párhuzamosan működhetnek feldolgozóelemek. - Futószalagos és szisztolikus architektúrák/2 Pl. ha a szomszédos képpontok szürkeségi szintjeinek átlagát kell kiszámítani, párhuzamosan négy összeadó áramkör működhet az adatpárok összeadásakor. Nyolc több-bites bemenet Összeadó Összeadó Összeadó Összeadó Osztó Összeadó Összeadó Összeadó Kimenet Processzorművelet: átlagolás Sima: Korszerű számítógép architektúrák A futószalagról kikerülő eredmény azonnal a második, hasonló futószalag bemeneti léptetőregiszterébe kerülhet. A párhuzamosság alacsony fokú, a feldolgozandó
környezet méretétől függ. Ez elérheti a 25x25 kiterjedést is A feldolgozóelem bonyolultsága az egyes rendszerekben nagyon különböző lehet. A feldolgozandó környezet méretének változtatása a regisztertár átkonfigurálását teszi szükségessé. Ugyanez szükségessé teszi a processzor párhuzamosan működő feldolgozóelemeinek átkonfigurálását is. A párhuzamos futószalag elven működő számítógépek speciális alkalmazásokban akár több nagyságrenddel felülmúlhatják egy munkaállomás teljesítményét. - Futószalagos és szisztolikus architektúrák/3 Szisztolikus architektúrák Ebben a rendszerben a bevitt adatokat keresztülpumpálják egy műveletvégző rendszeren, az eredmény általában egy hosszú adatsor. A "szisztolikus" elnevezés a szív hasonló pumpáló mozgásának analógiájából született. A működési elvet egy mátrixszorzás példáján követhetjük. i n j m i Egy sor X Egy oszlop A j B m = n
Cmn Az eredmény egy eleme C Mátrixok szorzása Sima: Korszerű számítógép architektúrák Két négyzetes mátrix szorzásának eredménye egy ugyanolyan méretű négyzetes mátrix, mint a szorzó és a szorzandó mátrixok mérete. A szisztolikus elv alkalmazása: Az eredménymátrix minden elemének kiszámításakor azonos műveleteket kell elvégezni. A mátrix adott oszlopában (vagy sorában) az eredmények kiszámításához a bemenő mátrix adott oszlopának (vagy sorának) minden elemére szükség van. A szükséges adatok könnyen bevihetők sorosan oszloponként vagy soronként a rendszerbe. A sok részeredmény (egy sor- és egy oszlopelem szorzata) párhuzamosan számítható. - Futószalagos és szisztolikus architektúrák/4 A fenti jellemzők alapján készíthető szisztolikus rendszer főbb paraméterei: A műveletvégző egységek egy négyzetben helyezkednek el, amelynek mérete megegyezik az összeszorzandó mátrixok
méretével. Minden műveletvégző elem egy szorzó, egy összeadó és egy tárolóegységből áll. A tömb minden eleme ugyanazokat a meghatározott műveleteket végzi. Minden elem csak a legközelebbi szomszédjához kapcsolódik, és a kapcsolat csak egyirányú. A rendszert egyetlen vezérlő órajel vezérli, amely a műveleteket szinkronizálja. A bemeneti adatok a tömb két oldaláról érkeznek, egyenesen haladnak végig Az eredménymátrix a tömb másik oldalán távozik. 1. Bemenő adat Adatelemek Feldolgozóelemek Késleltetőelemek Eredmény Szisztolikus mátrixszorzás rendszerkapcsolása Sima: Korszerű számítógép architektúrák A két mátrix sorai ill. oszlopai balról és felülről érkeznek a rendszerbe A mátrixok egymás utáni sorait ill. oszlopait azonban késleltetni kell, ugyanis a tömb közbülső feldolgozóelemei a sor- és oszlopadatokat a tőlük balra, ill a felettük lévő feldolgozóelemtől kapják
Ilyen módon az első ütemidőben csak az F1,1 feldolgozóegység fog működni és elvégzi az első részletszorzat és részösszeg kiszámítását. A második ütemidőben már az F1,2 és az F2,1 feldolgozóegység is működésbe lép, hiszen balról és fentről megérkeznek a számításhoz szükséges adatok. Minden ütemidőben több egység lép működésbe mindaddig, amíg a legelső egység be nem fejezi az utolsó részletszorzat és összeg kiszámítását. Ezután minden ütemidőben egyre több műveletvégző egység áll le. - Futószalagos és szisztolikus architektúrák/5 - Működő cella Nem működő cella Műveletek végrehajtása a szisztolikus tömbben Sima: Korszerű számítógép architektúrák A műveletvégző egység az alábbi ábrán látható. Fentről Balról Szorzó Tároló Jobbra Összeadó Alulra Szisztolikus mátrixszorzás műveletvágző egysége Sima: Korszerű számítógép architektúrák - VLIW architektúrák/1
- Hosszú utasításszavú architektúrák Very Long Instruction Word (VLIW) Az utasításszintű párhuzamosságot hasznosítja. Több párhuzamosan működő végrehajtóegységgel rendelkezik. A fixpontos és a lebegőpontos adatokhoz használhat közös vagy külön regisztertárat. Mindét megoldásra van példa. A VLIW és a szuperskalár processzorok közötti fő különbség az utasításaik felépítésében és az ütemezés módjában van. A VLIW processzorok utasításai minden végrehajtóegységhez külön-külön vezérlőmezőt tartalmaznak. Gyorsítótár/ memó -ria F Egyetlen több műveletes utasítás VE VE Gyorsítótár/ memó -ria F Többszörös utasítás VE VE VE VE Regisztertár Regisztertár VLIW megoldás D utasítás/vezérlés adat D dekódoló egység F: utasítás lehívó egység VE: végrehajtó egység Szuperskalár megoldás A szuperskalár és VLIW processzorok közötti főbb különbségek Sima: Korszerű
számítógép architektúrák - VLIW architektúrák/2 Az utasítások hossza függ: a végrehajtóegységek számától és az egyes végrehajtóegységek vezérléséhez szükséges mezők hosszától Hagyományos VLIW (széles utasításszavú) architektúrák 5-30 végrehajtóegység 16-32 bites vezérlőszó végrehajtó-egységenként (100-1024 bit) Pl.: Trace 28/200 gép 28 utasítást képes végrehajtani ciklusonként, szóhosszúsága 1024 bit A túl hosszú utasításszó hátrányai: Nem lehet minden ciklusban kihasználni az összes vezérlőmezőt, ezért a programok nagy tárigényűek. Nagy memória sávszélességet igényel. Assembly szinten manuálisan nem programozható (sok végrehajtóegységet kellene egyszerre figyelembe venni) Pl. a Trace számítógépre fordított FORTRAN programok háromszor hosszabbak egy VAX gépre fordított programnál. Keskeny VLIW architektúrák 2-3 utasításmezőt tartalmaznak. (Pl.: Az Intel-HP IA-64
architektúra 3 műveleti mezőt tartalmaz) Utasításszavúk 100 bit-nél rövidebb. A VLIW processzorok statikus ütemezése A függőségek észrevétele és kezelése teljes egészében a fordítóprogramra hárul. A statikus ütemezése előnye, hogy a processzor egyszerűbbé válik (nem szükséges az adatfüggőségek észrevétele, az utasításvárakoztatás, a regiszterátnevezés a soros konzisztencia biztosítása). A processzor kevesebb áramköri elemet tartalmaz Az alacsonyabb bonyolultság miatt nagyobb órajelfrekvencia valósítható meg. A statikus ütemezése hátránya, hogy sokkal bonyolultabb fordítóprogramot igényel. A fordítóprogramnak ismernie kell a processzor és a memória minden jellemzőjét, amely az utasítások ütemezéséhez szükséges. Ismernie kell a végrehajtóegységek számát, típusát, késleltetési és ismétlési értékeiket, a gyorsítótár késleltetési idejét, stb. Tehát a fordítóprogramnak technológiafüggő
paramétereket is figyelembe kell vennie. Egy processzorcsalád különböző tagjaihoz általában nem használható ugyanaz a fordítóprogram, vagyis a VLIW fordítók tecnológiafüggőek. Ez az egyik legnagyobb korlátjuk. A technológiaérzékenységhez tartozik a gyorsítótár találati hibáinak problémája. - VLIW architektúrák/3 Az adatok behívásakor lényeges eltérés van az adatok rendelkezésre állásának idejében cache találat és cache hiba esetén. A fordítóprogramnak az adatfüggőségek vizsgálatakor a legroszszabb esetet kell figyelembe vennie, ami jelentősen ronthatja a teljesítményt A VLIW architektúra a szuperskalár architektúrával van versenyben. A VLIW architektúra jövőjét az határozza meg, hogy a csökkentett bonyolultságból származó előnyöket ki tudja-e használni a nagyobb teljesítmény eléréséhez. A technológia fejlődésével a szuperskalár processzorok teljesítménye is növekszik. A szuperskalár processzorok
végrehajtási párhuzamossága is eléri azt a határt, amelyet a programokban lévő párhuzamosság mértéke még indokol Ez általános célú programok esetén 6-8, műszaki-tudományos programoknál 10-20 Néhány mai szuperskalár processzor is rendelkezik többműveletes utasításokkal (HP PA, Power, PowwrPC). Egyetlen utasításban megadható egy lebegőpontos szorzás és összeadás Tehát ezek a processzorok bizonyos esetben VLIW processzorként viselkednek. Kevés VLIW architektúrájú gép jelent meg kereskedelmi forgalomban. A Trace 200 család 3 modellje (1980-as évek végén jelent meg): Trace 7/200, 14/200 és 28/200. A magasabb sorszámú modellek a 7/200-as modellek összekapcsolásával készültek Összehasonlító teljesítményadatok: Típus Trace 7/200 Trace 14/200 DEC 8700 Cray XMP Ciklusidő [ns] 130 130 45 8 Linpack teljesítmény (MFLOPS) 6 10 0,97 24 A Trace gépek jelentősen felülmúlják a drágább DEC gép teljesítményét, és
összemérhető a Cray XMP szuperszámítógép teljesítményével. A Trace család gépei UNIX 4.3 BSD operációs rendszert használtak Műszaki-tudományos feladatokhoz használták Fortran programnyelven. A Multiflow cég fejlesztette. - Vektorarchitektúrák/1 - Vektorarchitektúrák Az adatpárhuzamos megoldások legsikeresebb megvalósítása a vektoros szuperszámítógépek. Legsikeresebben a nagy teljesítményt igénylő tudományos számításoknál alkalmazzák őket. Nagy teljesítményük a vektorozott felépítésnek és a modern technológiának köszönhető. Gyártóik: Cray, Convex A vektorizálás főbb komponensei: Nagyfokú adatpárhuzamosság, amelynek forrása a szószervezés A szóhosszt hatékonyabban használják ki, mint más rendszerek. A szavak nagyobbak is lehetnek, mint a soros számítógépeké A szószervezés a gép teljes architektúrájára jellemző (memóriaszervezés, kommunikációs csatornák). Az adatszavak elhelyezése
vektorokban A vektorok az adatszavak százait tömörítheti, és ezeket a vezérlésfolyam egyedi adatként kezeli. Ez elérheti a 64KB-ot is Egy-egy utasítás ideális esetben ennyi adatelemen végez műveleteket. Ez előnyös azáltal, hogy egyetlen utasításlehívással sok adaton lehet elvégezni a kijelölt műveletet, és a vektorok összefüggő memóriaterületeken helyezkednek el, amelyeknek a betöltését is hatékonyan lehet elvégezni. A futószalagos feldolgozás mikro- és makroszinten Az egyes elemi műveleteknél, és több műveleti elem esetén is alkalmazzák a futószalagot. Az adat be- és kivitelnél, az adatvektorok kezelésénél szintén alkalmazzák a futószalag elvet A műveleti elemek párhuzamosítása A vektorok párhuzamos árama is feldolgozható, például több lebegőpontos összeadó, szorzó és több egész típusú műveleti egység működtetésével. A fenti négy technika egyenkénti alkalmazása kb. 10-10-szeres gyorsítást
jelent, együttesen mintegy 1 000-10 000 -szeres gyorsítás érhető el. A hatékony működtetés feltétele a megfelelő alkalmazások kiválasztása, és az adatok megfelelő formátumú összeállítása. Az utóbbi feladatban nagy szerepe van a párhuzamos fordítóprogramoknak Az ilyen számítógépek teljesítménye 1-10 GFlop. A vektorszámítógépek a legbonyolultabb rendszerek az adatpárhuzamos gépek között. Szóhossz A szóhosszt a számábrázoláshoz igazítják (pl. 64 és 32 bites szabványos IEEE lebegőpontos számábrázolás). A fixpontos számábrázolási formákat is úgy alakítják ki, hogy az a szóhosszúsághoz jól illeszkedjék. - Vektorarchitektúrák/2 - Vektorizálás A művelet végrehajtásának fázisai: 1. Az első cím kiszámítása 2. Az első adat betöltése t1 3. A második cím kiszámítása 4. A második adat betöltése t2 5. Az eredmény kiszámítása 6. Az eredmény címének kiszámítása t3 7. Az eredmény
tárolása Nem vektorizált számítási mód Egy eredmény számítási ideje: N eredmény számítási ideje: t1 + t2 + t3 N (t1 + t2 + t3) Vektorizált számítási mód N eredmény számítási ideje: (t1 + N t2 + t3) A cím kiszámítása és az adatok előkészítése, majd az eredmények visszatárolása jelentős időt vesz igénybe. A vektorizálással a cím kiszámítására csak egyszer van szükség, hiszen az adatokat egy összefüggő címtartományról vesszük elő Az adatlehívás is vektoronként történik A művelet végrehajtásának fázisai még a futószalag technikának is alá van vetve. A hatékonyság attól függ, hogy mennyire eredményesen lehet az adatokat vektorizálni, és hogy a vektorizálás a teljes folyamat lelassulása nélkül elvégezhető-e. A futtatás előtt gyakran az adatok átrendezése szükséges. Futószalagos adatkezelés A soros processzoroknál megismert futószalag technikát alkalmazzák. Nagyon fontos, hogy a futószalag
szemcsézettsége optimális legyen, a futószalag fázisainak végrehajtási ideje azonos legyen. - Vektorarchitektúrák/3 - Párhuzamos számítási folyamatok Funkciópárhuzamos, adatpárhuzamos vagy a kettőt egyesítő megoldást alkalmaznak a tervezők. A funkcionális párhuzamosság itt azt jelenti, hogy külön végrehajtóegység van a fixpontos és a lebegőpontos számításokhoz, amelyek párhuzamosan működtethetők. Ennek kihasználásához az alkalmazásokban lennie kell olyan számítási egységeknek, amelyek hasznosíthatók Az adatpárhuzamosság úgy valósítható meg, hogy minden típusú végrehajtóegységből több is készül, amelyek párhuzamosan működnek. Ezek kihasználásához az adatok sorozatát, amelyeken azonos típusú műveleteket kell elvégezni, darabokra kell bontani, és a rendelkezésre álló egységekkel elvégeztetni. Számítások Egyes egység FX Többszörös egység FX LP 2 4 LP + 2 4 + Párhuzamos számítások
Sima: Korszerű számítógép architektúrák A Cray család 1976-ban jelent meg az első Cray szuperszámítógép. A technológia folyamatosan fejlődött és a párhuzamosság egyre növekedett. A Cray család 4 generációjának teljesítménye: Rendszer Központi Órajel [MHz] egység Cray-1 X-MP Y-MP C90 1 4 8 16 80 105 166 240 Lebegőpontos eredmények órajelenként 2 2 2 4 Mozgatott MFlop ráta szavak óraje- [Adatszó/órajel] lenként 1 80 3 840 3 2667 6 15360 - Vektorarchitektúrák/4 - Fő jellemzőjük a vektoros feldolgozás, egy-egy programlépés adatelemek csoportján indít el műveletet. Vektorregisztereket alkalmaznak, amelyekben a beolvasott adatvektorokat átmenetileg tárolják. Ezáltal a processzoron belüli műveletvégzés és a memória közötti adatmozgás függetlenné válik A futószalagot az utasítások feldolgozása és az aritmetikai egységek esetében egyaránt alkalmazzák. A memóriához többszörös hozzáférést alkalmaznak,
amellyel jelentősen megnő a memóriaigényes alkalmazások végrehajtási sebessége. A Cray90 rendszer felépítése 2, 4, 8 vagy 16 processzort tartalmazhat. C916 főbb jellemzői: 16 processzor van. A 8GB nagysebességű memória egyformán hozzáférhető minden processzor számára. A maximálisan 256 ki/bemeneti csatorna 13,6 GB/s sávszélességet biztosít a perifériák és a hálózat eléréséhez. Összeköttetés a nagymértékben párhuzamos Cray T3D-hez. Opcionális szilárdtest tárolók, amelyek 32 GB kapacitásúak, 14,6 GB/s sávszélességgel. Egyidejű skaláris és vektoros feldolgozás. Minden processzornak két független műveleti szegmense van. A vektoros feldolgozás az iteratív műveletek teljesítménye miatt jóval gyorsabban szolgáltat eredményt, mint a hagyományos skalár feldolgozás, míg a skalár műveletek kiegészítik a vektoros alkalmazásokat olyan esetben, amikor a probléma nem adaptálható vektoros
technikára. Memóriaszervezés A központi memóriát az összes CPU használhatja, és mindegyik a teljes címtartományt elérheti. Minden CPU 4 dupla szélességű porttal csatlakozik a memóriához. Többszörös adatátvitel folyhat a memória és a CPU-k között. Az elrendezés hierarchikus: 8 független szekció Szekciónként 8 alegység Minden alegységben 2 feldolgozócsoport Minden csoportban 8 feldolgozóegység (összesen 1024 feldolgozóegység) - Vektorarchitektúrák/5 - Közös regiszterek és valós órajel 0. CPU 2. CPU . . . 1. CPU Központi memória 8 rész, 64 alegység, 1024 feldolgozóegység, 1024 Mszó 14. CPU 3. CPU . . . 15. CPU Ki/bemeneti alrendszer A processzorok és a memória közti adatforgalom Sima: Korszerű számítógép architektúrák Minden CPU-nak független összeköttetési útvonala van minden szekcióhoz, amellyel 128 64bites memóriaművelet végezhető órajelenként. A programkód és az adatok ugyanabban
a memóriában vannak. Minden szó 80-bites (64 adatbit + 16 bit a hibafelismerésre és javításra). A memóriát a processzorok és a ki/bemeneti alrendszer közösen használják. A processzor felépítése A processzorok egyforma felépítésűek. A processzorok műveleti regiszterekből, funkcionális egységekből, és egy utasításvezérlő hálózatból áll. A műveleti regiszterek és a funkcionális egységek 3-féle feldolgozásban szerepelhetnek: cím, skalár és vektor A címfeldolgozás a belső információk (címek, indexek), a vektorok hosszának és a léptetések számának vezérlésénél használatos. Ezt 2 fixpontos ALU látja el A skaláris feldolgozás egyedi számokon, számpárokon végez aritmetikai műveleteket. 5 funkcionális egység kizárólag skaláris feldolgozást végez, 3 lebegőpontos egység megosztva végzi a vektorműveleteket. A skalár és vektorműveletek párhuzamosan is végrehajthatók a lebegőpontos műveletek
kivételével. A vektoros funkcionális egységek két vektor vagy egy vektor és egy skalár között végez műveleteket. Az eredmények a vektor-regiszterekbe kerülnek 2 lebegőpontos funkcionális egység van A vektorműveletekben az egyik a páros, a másik a páratlan elemeken végez műveleteket - Vektorarchitektúrák/6 - Vektorműveletek A vektor lehet egy 1 dimenziós tömb, vagy egy 2 dimenziós tömb sora, oszlopa vagy átlója. A hosszú vektorok 128 elemű egységekben (vagy maradék formájában) vesznek részt a vektorműveletekben. A vektorok tördelését a fordítóprogramok végzik A műveletek két elempáron hajtódnak végre egyszerre. A vektor elemeinek feldolgozását az elemszámláló regiszter ütemezi. A vektorizálás önmagában mintegy 10-szeresére növeli a sebességet. A vektorregiszterek és a központi memória közti adatmozgás blokkonként történik. A memóriaművelethez meg kell adni az első szó címét, a növekményt vagy
csökkenést, és a vektor hosszát. Az adatmozgás sebessége 2 szó/órajel sebességű. Gyártástechnológia A technológia emittercsatolt (ECL) logikára épül. Az integráltság foka: Rendszer Cray-1 X-MP Y-MP C90 1000 kapu/lapka 2 16 2 500 10 000 Szoftver A hardverben rejlő párhuzamosság csak a megfelelő felhasználói programokkal használható ki. Operációs rendszer: UNICOS (UNIX System V alapokon). Interaktív, helyi kötegelt és távoli kötegelt feldolgozást támogat. Számos, - a Cray által készített - függvény kiegészítést tartalmaz a teljesítmény növelésére. Egy-egy program több processzoron futhat: Önelosztó megoldás Automatikusan szétosztja a párhuzamos Fortran vagy C program kódot a proceszszorok között, ezzel a párhuzamosságot a ciklusok szintjén valósítja meg. Ehhez nincs szükség programozói beavatkozásra. Ciklusszintű megoldás (micro-tasking) A DO ciklusok szintjén valósítja meg a párhuzamosságot a
Fortran vagy C programokban. A program kódot nem kell módosítani, a programozó mindössze direktívákat épít be, amelyekkel jelzi a párhuzamosságot A szinkronizálás egyszerű, mivel a kicsi kódrészek eredményesen partícionálhatók. Makro-szintű megoldás Alprogramok szintjén teszi lehetővé a kód több processzoron történő végrehajtását. A programozó egy szubrutinkészlet segítségével szinkronizálja az alprogramokat a Fortran, C vagy Ada programokban. - SIMD architektúrák/1 - SIMD architektúrák A kereskedelmileg is sikeres architektúrák egyike a SIMD-rendszer (a vektorszuperszámítógépek és a MIMD-rendszerek a másik kettő). A sikerhez az alábbi tényezők járultak hozzá: a koncepció egyszerűsége és a jó programozhatóság a szerkezet szabályossága a méret és a teljesítmény egyszerű skálázhatósága számos olyan területen való közvetlen felhasználhatósága, ahol szükség van a párhuzamosságra a
megfelelő teljesítmény eléréséhez A SIMD rendszerek legfontosabb elvei (Steven Unger): Az elemek egy kétdimenziós tömbben helyezkednek el, és mindegyik a négy legközelebbi szomszédjához kapcsolódik Minden processzor párhuzamosan ugyanazt a műveletet hajtja végre. Minden processzornak van saját belső memóriája. A processzorok programozhatók, és különböző feladatok elvégzésére alkalmasak. Az adatok gyorsan haladnak át a tömbön. Kell egy központi számítógép, ami az utasítások forrása és egy külön rendszer az adatbevitelre, az eredmények megjelenítésére és tárolására. Processzortömb Tömbvezérlő Központiszámítógép Adatillesztő Adat ki/be Háttértároló A SIMD-rendszer jellemző felépítése Sima: Korszerű számítógép architektúrák - SIMD architektúrák/2 - Néhány kereskedelmi megvalósítás: DAP (Distributed Array Processor) 1976, ICL. 32x32 elemű processzortömb. MPP
(Massively Paralell Processor) 1983, Goodyear Corp. 128x128 elemű processzortömb. Bitsoros elemekkel és közeli összeköttetésekkel dolgozott. Connection Machine 1985 Bonyolult hiperkocka hálózat Thinking Machine Inc. gyártotta MasPar 1990 Egy bitesnél bonyolultabb feldolgozóelemekkel rendelkezett. A távoli összeköttetéseket többszintű crossbar kapcsolókkal oldotta meg. Az IBM, Cray, DEC, nCUBE is gyártanak SIMD elven működő számítógépeket. A gépek tervezésénél eldöntendő kérdések: a feldolgozóelemek bonyolultsága (processzor alap-adattípusa, utasításkészlet bonyolultsága, memória nagysága) az egyes elemek lokális autonómiájának meghatározása az elemek összeköttetésének módja a feldolgozóelemek száma, az összeköttetések elrendezése a tartalék egységek elosztása a megvalósítás technológiája A szemcsézettség Meghatározza a viszonyt a feldolgozóelemek száma és az adatkészlet
párhuzamossága között. Finom szemcsézettségű rendszerek: Minden feldolgozóelemhez csak kevés számú adatelem tartozik Durva szemcsézettségű rendszerek: Minden feldolgozóelemhez sok adatelem tartozik Az ideális az 1:1-es megfeleltetés lenne, de a jellemző alkalmazásokban ez a technológia mai fejlettségi fokán még nem megvalósítható. - SIMD architektúrák/3 Másik probléma a különböző alkalmazásokban használt adatkészletek eltérő mérete. Nehéz rugalmasan bővíthető SIMD rendszereket készíteni. Az adatelemenként elvégzendő számítások bonyolultsága hatással van a feldolgozóelemek típusára és bonyolultságára. Ez pedig technológiai és gazdaságossági szempontból hatással van a maximálisan elérhető párhuzamosságra. A megoldások általában a két végletet célozzák meg: Finom szemcsézettség egyszerű feldolgozóelemekkel Durva szemcsézettség bonyolult feldolgozóelemekkel Összeköttetési módok
Kívánatos lenne: ha bármelyik processzor bármelyik másik processzorral egységnyi idő alatt tudna kommunikálni. ha a kommunikációs események párhuzamosan mehetnének végbe. ha a kiindulás és a cél előre meghatározható lenne. ha a rendszer bizonyos redundanciával rendelkezne a hibás elemek és összeköttetések helyettesítése céljából. A fenti szempontoknak eleget tevő hálózat kiválasztása a legnehezebb döntés. A megismert összeköttetési módok alkalmazhatók: SIMD-összeköttetés Közeli szomszédok Fa Piramis Hiperkocka Jellemzők Nagy átmérő, nagy sávszélesség Kis átmérő és sávszélesség Kis átmérő, bonyolult programozás Kis átmérő és nagy sávszélesség A processzorok bonyolultsága Ez határozza meg a rendszer felhasználhatóságát. Az alkalmazás jellege is meghatározza, hogy milyen műveletekre van szükség: Tudományos kutatás: lebegőpontos műveletek Képfeldolgozás: logikai műveletek Az
áramkörök precizitása Ugyanaz a műveleti pontosság elérhető különböző precizitású processzorokkal. Gyakran egybites feldolgozóelemeket használnak, mert ez rugalmasan felhasználható különböző pontosságú számításokhoz. Például a képfeldolgozásban különböző pontosságú adatelemekkel dolgoznak, és ez leghatékonyabban egybites feldolgozóelemekkel valósítható meg. Az egybites feldolgozóelemek lényegesen egyszerűbbek és nagyobb méretű tömbök alakíthatók ki, és az összeköttetések is egyszerűbben megvalósíthatók. - SIMD architektúrák/4 - Finom szemcsézettségű SIMD-architektúrák Legfontosabb jellemzőik: A feldolgozóelemek minimális bonyolultsággal és a lehető legkisebb autonómiával rendelkeznek. A processzorok maximális számát gazdaságossági megfontolások határozzák meg. A programozási modell feltételezi, hogy a feldolgozóelemek száma megegyezik az adatelemek számával. Az
összeköttetés modellje: 4 pontú közeliszomszédos. A szokásos programozási nyelv soros, párhuzamos adatokra vonatkozó kiegészítésekkel. Az újabb rendszerek néhány ponton eltérnek a fenti modelltől: A feldolgozóelemek bonyolultsága nő: vagy több-bites alapon működnek, vagy kiegészülnek speciális aritmetikai elemekkel. A szokásos rács mellett további összeköttetések is léteznek: hiperkocka, crossbar. A helyi memória mérete növekszik. Az MPP finom szemcsézettségű rendszere Massively Paralell Processor Kimenet Kapcsoló Vezérlő VAX 11/780 128x128-as processzortömb Osztott memória Kapcsoló Bemenet Az MPP-rendszer Sima: Korszerű számítógép architektúrák A feldolgozóelemek 128x128-as négyzetrácsban helyezkednek el. Az MPP a NASA számára készült, és főleg képfeldolgozásra használják. A 88 tömbkártya mindegyike 24 processzorlapkát (192 processzorral) támogat a hozzátartozó memóriával együtt.
Tokonként 8 processzor Tömbönként négy tartalék processzoroszlop van elhelyezve, amely a hibatűrést biztosítja. - SIMD architektúrák/5 A feldolgozóelemek a közeliszomszédokkal vannak összekapcsolva. Az adatok bevitelét és kivitelét különválasztották, és ún. lépcsős memóriaszervezést valósítottak meg, amely könnyű átalakítást tesz lehetővé a bit-formátum és az egész adattípus között. A tömböt egy VAX 11/780-as számítógép és egy önálló tömbvezérlő vezérli. Programozási nyelv: párhuzamos Fortran és párhuzamos Pascal. A szabványos nyelvet kiegészítették az adattömb adattípussal, és egy előfeldolgozás során az adattömbre vonatkozó műveleteket olyan szubrutin-hívással helyettesítik, amely a vezérlő kifejezést a megfelelő interfészhez irányítja. A műveletvégző egységek: Minden adatcsatorna, regiszter és funkcionális egység 1 bites. Önálló összeadóval, tömbléptetővel és
logikai műveletvégző egységgel rendelkezik, amelyek párhuzamosan működnek. A szomszédoktól érkező bemeneti adatok multiplexeren keresztül érkeznek. Egyetlen kimeneti adat van, amely a szomszédokhoz kerül. Egy különálló regiszterbit (S) kapcsolódik a többi processzor megfelelő elemeihez, és ezzel egy olyan bemeneti/kimeneti léptető regiszter jön létre, amely önállóan képes működni a processzor többi elemétől. Ezzel átfedhető a számítás és az adattovábbítás. A helyi memóriát egy másik berendezés szolgáltatja. Összeadó Léptetőregiszter B P A C Logika adat ki S adat be MUX Külső memória Szomszédokhoz Szomszédoktól Az MPP-processzor elemei Sima: Korszerű számítógép architektúrák - SIMD architektúrák/6 Az MPP áramkör teljesítménye Művelet Adat bevitel/kivitel Összeadás Szorzás Közeli szomszéd Helyi 3x3 átlag Körbejárás (3x3) Tömb mozgatása 1 képponttal Pontosság 1 bites 16 bites 32 bites
lebegőpontos 16 bites egész 32 bites lebegőpontos 1 bites 8 bites 8 bites 8 bites Idő[µs] 0,1 2,5 33 10 60 1,5 12,4 9,5 1,7 Blokkok száma 1 25 330 100 600 15 124 95 17 Példa az alkalmazásra Képek szegmentálása Feladata a képeket olyan összefüggő részekre osztani, amelyek képpontjai bizonyos szempontból összetartoznak. Az alkalmazott szempont (feltétel) lehet például a szürkeségi szint, a textúra, az alak. A leggyakoribb felosztási módszer, hogy a kép minden (előre megadott) kis területére megvizsgálják a feltételt, és azokat a részeket összekapcsolják, amelyek között az eltérés egy küszöbszint alatt van. A módszer több iteráció során jut el a megoldáshoz. A párhuzamosan elvégezhető művelet a területek közötti hasonlóság vagy eltérés számítása a megadott feltétel alapján. 3.5 A RISC gépek Reduced Instruction Set Computer - csökkentett utasítás készletű gép Ezeket megelőzték a Complex Instruction Set
Computer - bonyolult utasítás készletű gépek 3.51 A CISC gépek fejlődése A számítástechnika kezdeti szakaszában az operatív tár rendkívül drága erőforrás volt. Ez adta az alapját annak a gondolkodásmódnak, hogy a legjobb architektúra az, amely - a memóriabeli helyfoglalást tekintve - a legrövidebb programot eredményezi. Más, az architektúra minőségét mérő tényezők voltak az utasításonkénti bitek száma vagy a program-végrehajtás során befetchelt program- és adatbitek száma. A mikroprogramozás bevezetése után gyorsították az utasításoknak a memóriából történő fetchelését, ami javította a végrehajtás hatékonyságát. Mivel egyre több funkciót hajtottak végre mikrokóddal, annak mérete növekedett. Mivel már akkora volt, hogy nem lehetett hibamentes, ezért írható memóriába tették (WCM Writable Control Memory) Ez lehetővé tette, hogy a mikrokódot a használt programnyelvhez vagy alkalmazáshoz lehessen adaptálni.
A funkciók mikrokód formájában való megvalósításának másik oka az volt, hogy ezeket a funkciókat könnyebb volt öszehangolni a támogató fordítóprogramokkal. Amennyiben egy magasszintű programnyelv elemet (statement) egyetlen gépi nyelvű utasítássá fordítható, akkor a compiler-ek írása egyszerűbbnek tűnik. Továbbá, amennyiben a gépi nyelv tartalmaz olyan utasításokat, amelyek közeli kapcsolatban állnak a magasszintű programnyelv elemeivel, akkor összezárul az a szemantikai rés (gap), amely a magasszintű programnyelv és a gépi nyelv között van. Példaképen néhány utasítás, amelyet a VAX-11 gépi nyelvéhez adtak a magasszintű programnyelvek jobb támogatása érdekében: az INDEX, a CASE és a CALL utasítás vagy a MC68020-éhoz a CHK utasítás. A fentről lefelé történő kompatibilitás igénye arra kényszeríti a számítógép gyártókat, hogy állandóan növeljék az utasítás-készletüket az újabb és hatékonyabb
modelljeikben. Az utasításkészlet ilyen gazdagítása párhuzamosan folyt a címzési módok számának a hasonlóan gyors növekedésével. Például, míg a MC68000 12, MC68020 már 18 címzési móddal rendelkezett A kódsűrűségi mutató és a sok utasítás szükségesé tette, hogy változó hosszúságú utasítás-formátumokat használjanak. Így az utasítások opcodja és operandus-specifikáló mezője változó hosszúságú A VAX-11-nél például nem lehet megmondani, hogy hol kezdődik a következő utasítás specifikáló mezője, amíg az előző utasítás specifikáló mezőjét nem dekódoltuk. A különféle utasítás-hosszak azt eredményezhetik, hogy az utasítások tetszőleges bájtokon, sőt bizonyos architektúráknál tetszőleges biteken kezdődjenek, ami bizony nem eredményez hatékony utasítás-fetchelést, sem pedig hatékony adatátvitelt. A már korábban bevezetett utasításokat nem lehet elhagyni, hiszen ezeket alkalmazták a
felhasználói programokban és ez szoftver-inkompatibilitáshoz vezetne. Tehát az egyes processzorok utasításkészlete - a szoftver-kompatibilitási kényszer miatt - állandóan csak növekedhet. Nézzünk meg néhány ismert CISC architektúrát: Jellemző Bevezetési év Az utasítások száma A Control Memory mérete: Kbájt Utasítás-hossz (bit) IBM 370/168 1973 208 420 16-48 VAX 11/780 1978 303 480 16-456 iAPX-432 1982 222 64 6-321 3.52 1980: RISC fizikai és logikai architektúra kialakulása Fizikai architektúra Az University of California, Berkeley (UCB) kutatócsoportja a 70-es évek végén azon dolgozott, hogy egyetlen chip-en kialakítson egy nagyteljesítményű processzort, ezért a tervezés során mindent igyekeztek egyszerűsíteni. Több éves program-elemzés eredményeképpen megállapították, hogy a CISC gépek utasításainak mintegy 25%a használja a gépidő 95%-át (s ráadásul ezek pont a legegyszerűbb utasítások voltak). Ez impliciten
magában hordozza, hogy a hardver által támogatott utasításoknak a 75%-át szinte egyáltalán nem használják. S a ritkán használatos utasítások a bonyolultabb utasítások közé tartoztak. Természetesen felmerült a logikus kérdés: Miért kell elpazarolni az értékes lapka-területet ritkán használt utasítások számára? A modern számítógép CPU áramköreinek többsége az utasítás-dekódolást és a végrehajtásuk vezérlését végzi. A mikroprogramozott CISC számítógépeknél is az áramkörök több, mint a fele a vezérlési célra szolgál. Az UCB kutatók észrevették, hogy a kis utasítás-készlet kisebb vezérlő-áramkör mennyiséget igényel, és a felszabaduló helyet más, a teljesítményt tovább növelő funkciók telepítésére lehet használni. Kutatni kezdték az alkalmazási programokat, hogy mely utasításokat használják tipikusan, milyen gyakran kerülnek végrehajtásra és milyen CPU-erőforrásokra van szükség azok
támogatására. Ezek a tanulmányok kimutatták, hogy a nagy regiszterkészlet növeli a teljesítményt, továbbá, hogy bizonyos utasítás-osztályokat a nagyobb teljesítmény érdekében optimalizálni kell. Tehát a gondolatmenet lényege: • • • • • • az utasításkészlet 75%-át elhagyták, s ezek ráadásul pont a bonyolultabb utasítások voltak ezáltal igen jelentősen (akár a tizedére is) csökkenthették a lapkán a vezérlőrész által igényelt területet s a felszabadult helyet regiszterekkel töltötték fel. E munkák eredményeképpen született meg a RISC I típusú gép 1980-ban, mely valóban egyetlen chip-en egy nagyteljesítményű processzort jelentett. Logikai architektúra A Stanford University kutatócsoportja John Hennessy vezetésével 1981-ben a MIPS nevű gép tervezésével kapcsolatosan a számítógép és a fordítóprogram (compiler) viszonyát kezdte vizsgálni. A kutatásuk témája az optimalizáló compiler tervezése és
megvalósítása, az egyciklusos utasításkészlet. Ezen úttörő kutatásoknak az eredménye a Neumann-architektúrájú számítógépek egy új típusa tervezési filozófiájának megalapozása volt. A csökkentett utasítás-készletű számítógép-tervezés olyan számítógépeket eredményezett, amelyek az azonos technológiával készített számítógépeknél gyorsabban hajtották végre az utasításokat. További RISC gépek: IBM RT, HP Spectrum, AMD 29000, Sparc, MC88000, Intel i860 és i960, IBM RISC/6000. 3.54 RISC gépek logikai architektúrája Az egyszerű utasítások érveit alapvetően program-végrehajtási statisztikákkal húzták alá. 3.541 Egyszerű utasítások Ezeknek gyors a végrehajtásuk, tipikusan utasításonként egy ciklusidő alatt. 3.542 Fix hosszúságú utasítások Fix hosszúságú utasítások, ez gyorsítja az utasítás-fetchelést. 3.543 Kevesebb utasítás-formátum A nagy számú utasítás-formátum azt jelenti, hogy az adott
bitmezőt - más mezőktől, mint például az opcode mezőtől függően - különféleképpen interpretáljuk. Ennek következtében az utasítás dekódolás tovább tart, mivel több kapu-késleltetést jelent. Ez megnövelheti a processzor ciklus-idejét és az utasítás-dekódoláshoz több hardvert igényel. A RISC utasítások csupán néhány különböző formátummal rendelkeznek, ami gyorsítja az utasítás-dekódolási műveletet. 3.544 Load-store architektúra - A RISC gépek többsége load-store architektúrával rendelkezik. Ez azt jelenti, hogy a load és a store utasítás biztosítja az adatátvitelt a CPU regiszterek és az operatív tár között. Valamennyi adatmanipulációs utasítás korlátozott, hogy az operandusok vagy csak a CPU regiszterben lehetnek, vagy pedig az utasítás szónak kell tartalmaznia. - Csupán néhány bit szükséges az adatot tartalmazó regiszter megnevezéséhez. Sok gép számára előnyös a három-operandusos utasítás
használata, mely lehetővé teszi egyetlen utasításban a következő feladat megoldását: Ri [Rj] + [Rk] Az ilyen jellegű utasítás különösen előnyös optimalizáló compiler használatához. Ezek nagyobb teljesítményűek, mint a két operandusú párjuk, mivel a végrehajtásukhoz nem igényelnek több óraciklust. - többszörös regiszter-készlet, átfedő regiszterek. Az adatfeldolgozást végző utasításoknak rrr típusúaknak kell lenni. Ez biztosítja a legrövidebb operandusfetchelési időt Nagy számú regisztert kell tudni használni, hogy minél több aktiválási rekordot lehessen bennük tartani. Csak a LOAD/STORE utasítások biztosítják az operatív tárral a kapcsolatot A memória-hozzáférést optimalizálni kell. 3.545 A kis konstansok és kis displacement, mint immediate adat A 32-bites fix hosszúságú utasítások - mint amit több RISC architektúra is használ - viszonylag nagyobb konstansokat is magában foglalhatják, mint immediate
mezőt. Pl a MIPS gép 8 bites immediate értékeket enged meg, ami lehetővé teszi, hogy az összes konstansok a 95%-át immediate értékként specifikáljuk. Hasonló érv érvényesül a displacement mező vonatkozásában is; az esetek többségét a 8-16 bit lefedi. 3.546 Kevés adattípus A műveletek száma csökkentésének egyik útja, hogy csökkentjük azadattípusok számát. Feltehetjük a kérdést, hogy vajon van-e igény valamennyi integer adattípusra. A char és a logikai változók 8-bites formátumot használnak. Mivel az adatmanipuláló műveletek 32-bites regisztert használnak, ezért vizsgáljuk meg a 8-bites operandus kezelését a load/store műveleteken keresztül. A 32-bites regisztereknél - optimalizáló compiler-t használva lehetséges a a load-store szám csökkentése, megengedve négy darab 8-bites integerrel kapcsolatos load-store műveletet szimultán módon, azaz egyidejűleg. A többi esetben egy 8-bites load művelet helyettesíthető egy
32bites load művelettel, amit egy bájt kiemelése (extract) követ; a 8-bites store helyettesíthető egy 32-bites loaddal, egy bájt beszúrásával és egy 32-bites store művelettel Ez azt jelenti, hogy a bájtos load-store műveletek lassabban (egy helyett 2-3 ciklus) kerülnek végrehajtásra, mint a szavas műveletek, mivel ezek végső soron emulálva valósulnak meg. A statisztika pedig azt mutatja, hogy a load/store műveleteknek mindössze 5% használ 8-bites operandust. Tehát a hiányzó 8-bites adattípusok feldolgozása csekély időveszteséget okozva emulálhatók. 3.547 Egyszerű címzési módok Ez teszi lehetővé a gyors címszámítást. Egy utasítás komplexitását az operandusok specifikálására használt címzési módok is meghatározzák. Komplex címzési módnak hívjuk azokat, amelyek egyetlen ciklus alatt nem határozhatók meg, mivel több összeadást és/vagy további szó-kiterjesztést igényelnek. Egy Motorola 68020 statisztikából kiderült,
hogy a forrásoperandusok 16, a rendeltetési operandusoknak pedig a 19%-a komplex A load és a store utasításokban használt címzési módok pedig úgy korlátozottak, hogy csak egyetlen memóriahozzáférést igényelhetnek. Azok a címzési módok, amelyek több, CPU-n belüli belső műveletet igényelnek, szintén ki vannak küszöbölve. Például a RISC gépeknél nincs meg az autoinkrementálási címzési mód, mivel ez általában egy további óraciklust igényel, hogy inkrementáljuk a regiszter tartalmát. Még fontosabb, hogy az autoinkrementálási módot ritkán használják a compiler-ek. 3.548 Kevés utasítás 3.549 A feltételes ugró utasítások A 32-bites utasítás-hossz miatt lehetőség van arra, hogy az összehasonlító és ugró-utasítást egyetlen utasításban valósítsuk meg. Ez azt jelenti, hogy egyetlen ciklus alatt végrehajthatókká válnak Hennessy szerint az ugróutasítások 99%-át megelőzi egy összehasonlítási vagy tesztelési
művelet. 3.5410 Eljárás-hívások A fontosságuk miatt részletekbe menően tanulmányozták az eljárás-hívásokat. Megállapították, hogy a hívott eljárásoknak mindössze az 1%-a használt hatnál több paramétert, s csupán a 6%-uk rendelkezett több, mint 6 lokális paraméterrel. Ezek a számok alátámasztják azt az elképzelést, hogy az eljárások aktiválási rekordjai nem hosszúak. Az eljárások másik jellemzője az egymásba-ágyazottságuk. Megállapították, hogy az bizonyos mértékig korlátozott, igen ritka az, amikor több egymásba ágyazott eljárás nagyobb mélységet ér el. Továbbá, miután elértünk bizonyos egymásba ágyazottsági mélységet, a mélység már csekély mértékben változik, azaz az eljárások kb. hasonló mélységűek Ez természetes következménye annak, ahogy a programokat strukturáljuk Ezek az argumentumok támogatják azt az ötletet, hogy a paramétereket és az eljárásokban deklarált lokális változókat
regiszterekben tároljuk, úgy, hogy az aktiválási rekordok egy részét regiszterekben tartsuk. Ezért született a RISC I-nél a többszörös regiszterkészlet átfedő változata. 3.55 A RISC gépek fizikai architektúrája Több gyorsítási mechanizmust tekintenek a RISC architektúrák vonatkozásában "szabványosnak", ezeket összegezzük az alábbiakban: 3.551 Vezérlőegység A CPU - mint fizikai architektúrában majd vesszük - a következő részekből áll: ALU, regiszterek, belső sín és kapcsolók s az egészet a vezérlőegység által generált jelek vezérlik. A vezérlőegység által elfoglalt terület a gépi utasítások számától és összetettségétől függ. A bonyolult, többlépéses utasítások sok helyet igényelnek a control memory-ben. Huzalozott vezérlés esetén pedig összetett logikai áramkörre van szükség Egy kevés számú, egyszerű utasítással rendelkező mikroprocesszor esetén a vezérlőegység kevés helyet igényel.
A megtakarított helyet pedig más eszközökre használhatjuk, például nagy számú regisztert vagy cache memóriát telepíthetünk rá. A futószalag technika a legáltalánosabb módja a az utasítás-feldolgozó egység gyorsításának. A nem RISC, nagy teljesítményű gépekben is alkalmazzák ezt a technikát, de a RISC gépek legtöbbjére ez jellemző. Az utasítások egyszerűségének következtében viszont a RISC futószalagok kevesebb lépcsőt tartalmaznak, mint a CISC processzoroké. 3.552 ALU Lebegőpontos aritmetika A lebegőpontos műveleteket intenzíven használja egy sor számítógép-alkalmazás, mint például a tudományos számítások, a digitális jelfeldolgozás és a grafika. Sok számítógép rendelkezik speciális eszközökkel, hogy felgyorsítsák a lebegőpontos műveleteket, s ez alól a RISC gépek sem kivételek. A RISC gépek többsége a lebegőpontos műveletekhez speciális utasításokkal rendelkezik és olyan hardverrel, mely ezeket a
műveleteket nagy sebességgel végrehajtja. A lebegőpontos műveletek egy összetett, többlépéses utasítás-sorozat végrehajtását jelentik, hogy kezeljük a mantisszát és az exponenst és gondoskodjunk az olyan feladatokról, mint az azonos kitevőre hozás vagy a normalizálás. Az ilyen utasításoknak a számítógép utasítás-készletébe való beiktatása a RISC tervezési filozófiától idegennek tűnik. De ez nincs így Valójában a lebegőpontos aritmetika egy kiváló példa a RISC megközelítés üzletpolitikájára. Egy adott utasítást akkor iktatnak be az utasítás-készletbe, amennyiben az egy jobb általános teljesíményhez vezet. Ebben a megközelítésben a kulcs-szempont az, hogy mennyire gyakran használják az adott utasítást egy tipikus alkalmazásban. S mivel a lebegőpontos műveleteket gyakran használják, ezért a lebegőpontos számítások gyorsítására szolgáló utasítások beiktatása jogos. Egy fontos szempont a futószalag CPU
utasításkészletében, hogy az utasítások többségének kb. hasonló végrehajtási idejűnek kell lennie. A többlépcsős végrehajtás miatt a lebegőpontos műveletek vonatkozásában nehéz megszervezni, hogy azok integer párjának megfelelő idő alatt kerüljenek végrehajtásra. Emiatt e két utasítás-típus nem integrálható egyetlen futószalag struktúrába. Ezért a lebegőpontos hardver általában egy önálló processzort képez, melynek megvan a saját futószalag szervezése. Általában ezt lebegő pontos segédprocesszornak hívják. A lebegőpontos segédprocesszort elhelyezhetik ugyanazon a morzsán, mint a CPU-t, de megvalósítható önálló morzsán is, amelyet a megfelelő sínnel csatlakoztatunk a CPU-hoz. Ez különösen akkor hasznos, amikor a hardver lehetővé teszi mind az integer, mind pedig a lebegőpontos aritmetikai egység számára a párhuzamos működést, a szoftver vezérlése alatt. Ilyen esetben a hardvernek elegendő
információt kell tárolnia az egyes egységekben folyó számítási folyamat előrehaladásáról, hogy biztosítsa a helyes számítást, amikor egy megszakítás vagy más jellegű kivételes esemény fellép. 3.553 Regiszterek Általában megállapíthatjuk, hogy jótékony hatást gyakorol a számítógép teljesítményére, ha nagy számú CPU regiszterrel rendelkezik, mivel ez csökkenti a a gyakori adatátvitel szükségességét a CPU és az operatív tár között. A modern compiler-ek sokféle algoritmust használnak, hogy az adott gépen elérhető regisztereket maximálisan kihasználják, mivel a regiszterekben tárolt változókon végzett adatműveletek kevesebb időt igényelnek. A többször használt adatoperandust csak egyetlen egyszer szükséges betölteni a regiszterbe, mivel a regiszter a feladat folyamán dedikáltan szolgálhat az adott operandus tárolására. Egyébként, ha a regiszterek száma kicsi, az operandust mindannyiszor be kell töltenünk az
operatív tárból, ahányszor csak szükségünk van rá. Más szavakkal, kis számú regiszter az adott feladat megoldásához szükséges load és store utasítások számának növeléséhez vezet. S a futószalagos CPU esetén a load és a store utasítások lelassítják a műveleteket Tehát előnyös, ha a load és a store műveletek számát csökkentjük több regiszter biztosításával. Ugyanakkor a nagy számú regiszter csupán egy szükségtelen üres hely, amennyiben a compiler nem használja azt ki hatékonyan. A RISC gépek többsége legalább 32 regiszterrel rendelkezik, de vannak 128 regiszteresek is 3.554 Memória Jelenleg a legtöbb számítógép a Neumann koncepciót követi, mely szerint az utasítások és az adatok keverve, ugyanazt a memóriát használják. Nyilvánvaló, hogy az egy memória-ciklus alatt átvitt utasítások és adatok mennyiségét az elérhető memória sávszélesség korlátozza. Amennyiben ez a sávszélesség nem elegendő, akkor a
processzor nem tud a maximális sebességével működni. A memória-sávszélesség növelésének egy lehetséges módja, hogy két különálló memóriát vezetünk be: egyet az utasítások, egyet pedig az adatok számára. Ez két memória-elérési útvonalat eredményez, ami a párhuzamosság egyik formája. Az ilyen architektúrát Harvard architektúrának nevezzük. A Harvard architektúra alapkövetelménye, hogy a program ne változtassa meg önmagát. Ez nem túl nagy követelmény, mivel a program ön-módosítást rossz gyakorlatnak tartják A legtöbb RISC implementáció Harvard architektúrát használ, hogy független elérési utat biztosítson az utasításokhoz és az adatokhoz, s ezáltal megduplázza a memória sávszélességet. Mivel a rövid ciklusidő és minden ciklusban egy utasítás végrehajtása a cél, az operatív memória nem tudja támogatni az igényelt sávszélességet, így cache memória használata a követelmény. A Harvard architektúra
lehet a CPU-cache interfésznél, így tehát két cache memória van, annak ellenére, hogy az egyetlen operatív tárban találhatók mind az utasítások, mind pedig az adatok; Utasítás cache Közös adat- és program memória CPU Adat cache Harvard architektúra - az operatív tárnál, akkor elkülönült utasítás- és adat-memória van. Utasításmemória CPU Adatmemória Harvard architektúra 3.555 Cache memory Egy nevezetes funkcionális blokk, amit egy RISC gépben megtalálhatunk, az a cache memória. Bár a cache memória hasznos bármely számítógépben, ennek a szerepe a RISC gépekben különösen fontos. A hosszú memóriahozzáférési idő vagy hosszú CPU óraciklus használatát, vagy pedig minden egyes memóriahozzáféréshez több, mint egy óraciklus használatát igényli. Összefoglalás Míg kezdetben a RISC esetében a fő hangsúly az utasításkészlet csökkentése eredményezte kisebb vezérlőrészen, s a lapkán így felszabaduló
helynek a regiszterekkel való feltöltésén volt, napjainkban a feldolgozás-átszervezésével tudtak igen nagy teljesítmény-növekedést elérni (futószalag, szuperskalár architektúra, stb.), ezért a RISC-előny hangsúlya áttevődött a fix utasításhosszra (egyszerű az utasításlehívás), • • az egyciklusos utasításokra (egyszerű a feldolgozás szervezés), • • a load-store architektúrára (rrr utasításformátum). • • 3.56 A RISC/CISC ellentmondás A RISC filozófia bevezetése rengeteg vitát eredményezett az érdemeiről. - - - A kulcskérdések egyike a teljesítmény, mivel a RISC processzorokat úgy tartják, hogy túlszárnyalják a CISC-eket. S valóban, a mérések alapján Assembly nyelvnél 30-50%-kal, magas szintű programnyelvnél, mint pl. a C, 2-3szor gyorsabb A következő szám a relatív kódméret. Mint várható, a RISC kód terjedelmesebb, mert az utasítások egyszerűbbek, azaz azonos funkcióhoz több gépi kódú
utasításra van szükség: 40-50% statikus kódnövekedés: ennyivel több a gépi kódú utasítások száma; 10-30% dinamikus kódnövekedés: ennyivel nő a ténylegesen felhasznált bájtok száma (a CISC gépnek az átlagos utasítás-hossza nagyobb: ha a RISC 1 hosszú, a CISC 1,1-1,4). A megvalósítás vonatkozásában több kedvező tény szól a RISC mellett: Jellemző Az elemek száma Szabályossági faktor A vezérlési rész a teljes lapka %-ban A tervezési idő hónapban RISC I 44K 25 6 19 MC-68000 68K 12 50 30 Z8000 17,5 K 50 53 30 Az elemek száma: a lapka komplexitását jellemzi. Szabályossági faktor: a manuálisan tervezett elemek (tranzisztorok, stb.) és a könyvtárból vett, szabvány elemek száma. az egyszerűségénél fogva a RISC megközelítés nem igényel sok manuálisan tervezett elemet Ez egyrészt munkaerő és idő-megtakarítást jelent, másrészt pedig csökkenti a hibalehetőséget is. A vezérlési rész a teljes lapka %-ban: az
egyszerű utasítások kevesebb vezérlést igényelnek. A tervezési idő hónapban: A rövid tervezési idő igen fontos, különösen a konkurencia-harcban. Egy termék élettartamát a technológiai szintje határozza meg. Amennyiben az új technológia időtartamát három évnek vesszük, a RISC megközelítés élettartama 30-19=11 hónappal, azaz lényegében egy évvel hosszabb, mint egy CISC termék. A RISC filozófia fő hozzájárulásának a RISC I processzor nagy regiszter-készletét tartják, különösen pedig a többszörös, átfedő regiszterkészletet. Az valójában vitatható, hogy ez valójában a RISC jellemzője-e Az a RISC javára szolgál, hogy a vezérlési rész csökkentése lehetővé tette, hogy a lapkán olyan nagy regiszter állomány jöhessen létre, amilyen a VAX-11 vagy az MC68000 esetében lehetetlen. Hitchcock (1985) többszörös, átfedő regiszterkészlettel látta el a VAX-11-et és az MC68000-at, továbbá szimulálta a RISC I processzort
egyetlen regiszter-készlettel. A konklúziója szerint a többszörös, átfedő regiszterkészlet teljesítménye független az architektúrától. CISC Egyre inkább konvergálnak RISC 1978 1980 napjaink RISC oldalról vizsgálva: elkezd növekedni a RISC-processzorban implementált műveletek száma. pl lebegőpontos műveletek CISC oldalról: a miniatürizálás eredményeképpen csökken a vezérlőrész mérete s így növelni tudják a regiszter-teret Harvard memória alkalmazása pl. a Pentium processzorokban (külön adat és külön utasítás-cache) a korszerű szuperskalár CISC processzorok megvalósítása során egyre gyakoribb, hogy szuperskalár RISC magot használ. Ilyen Például az Nx586, a K5 és a Pentium Pro 4.33 A CPU-teljesítmény mértékegységei Több népszerű számítógép-teljesítmény mértékegység létezik. 4.331 MIPS Million instructions per second A MIPS vonatkozásában jó, hogy egyszerű megérteni a fogalmat, főképpen a
felhasználó által is, és a gyorsabb gépek nagyobb MIPS-szel rendelkeznek, ami megfelel a szándéknak. A problémák viszont a következők: a MIPS függ az utasításkészlettől, ezért nehezen vethetők össze a különböző utasításkészletű gépek; a MIPS ugyanazon a gépen is más programnál más értékű; s a legfontosabb: a MIPS a teljesítménnyel fordított arányban is változhat. Erre a klasszikus példa az opcionális lebegőpontos processzorral rendelkező gép. Mivel a lebegőpontos műveletek lebegőpontos utasításonként több óraciklust igényelnek, mint a fixpontos utasítások, ezért a lebegőpontos programok a lebegőpontos szoftver-rutinok helyett az opcionális lebegőpontos hardvert használva rövidebb idő alatt futnak le, de alacsonyabb MIPS értéket érnek el. A szoftver lebegőpontos feldolgozás egyszerűbb utasításokat hajt végre, mely magasabb MIPS értéket eredményez, de annyival több utasítást kell végrehajtania, hogy a teljes
végrehajtási idő hosszabb lesz. Fajtái: 1) Eredeti (native) MIPS Erről beszéltünk korábban. 2) Csúcs (peak) MIPS Ez az alapértelmezés: a processzor hány milliót tud megcsinálni a leggyorsabb műveletéből (ilyen például a NOP), tehát nem csinál semmit. Végső soron csalás, a processzor semmilyen számítást nem végez 3) EDM MIPS, Dhrystone MIPS Speciális célú tesztprogramokat futtatunk. 4. Relatív MIPS IBM 370/158-on futó kis program futási ideje volt az első ezt sikerre a VAX 11/780-on futó program vitte, melyet 1 80-as évek végétől VUP (VAX Unit of Performance)-nak hívtak később a legelterjedtebb a PC-XT teljesítményét egységként kezelő programok, pl. a Checkit is használja, s ennél a következő eredményeket kaptam: Típus 386, 25 MHz 486, 66 MHz Pentium 133 MHz CPU 18,89 85,49 341,94 MATH 18,50 1730,29 5974,74 A második sor utolsó oszlopában lévő szám azt mutatja, hogy ennek a sebessége 1730,29-szorosa a PC-XTjének.
Nyilvánvaló, hogy ez a hatalmas (százszoros!) növekmény a beépített lebegőpontos aritmetikának köszönhető. 4.331 MFLOPS Million FLoating-point Operations Per Second Nyilvánvaló, hogy a MFLOPS sebesség függ mind a géptől, mind pedig a programtól. Mivel e mértékegység szándéka a lebegőpontos műveletek mérése, ezért ez nem alkalmazható ezen a körön kívül. Egy extrém példa: a compiler 0-közeli MFLOPS értékkel rendelkezik, akkor érdektelen, hogy az architektúra milyen gyors, mivel a compiler ritkán használ lebegőpontos műveletet. Ez a mértékegység kevésbé érintetlen, mint a MIPS. Műveleteken alapul, s nem pedig utasításokon s a célja a különféle gépek elfogulásmentes összehasonlítása. Az az eredeti elképzelés, hogy ugyanaz a program különböző gépeken futva különféle számú utasítást hajt végre ugyan, de azért ugyanolyan számú lebegőpontos műveletet végez el. Sajnálatos módon a MFLOPS az
utasítás-készlettől mégsem függetleníthető, mivel a lebegőpontos utasításkészlet a különféle gépek között nem konzisztens. Például míg a Cray-2-nek nincs lebegőpontos osztása, addig a Motorola 68882 rendelkezik osztással, négyzetgyökvonással, sinus és cosinus művelettel. A másik probléma, hogy a MFLOPS sebesség nem csupán az integer és lebegőpontos műveletek keverési arányával változik, hanem a gyors és lassú lebegőpontos műveletek arányával is. Például egy 100%-ig lebegőpontos összeadást tartalmazó program gyorsabb lesz, mint egy 100%-ig csak lebegőpontos osztást tartalmazó program. Mindkét probléma megoldása, hogy a forrásprogram tartalmazzon egy stabil számú lebegőpontos műveletet és azt osszuk el a végrehajtási idővel. A Livermore Loops benchmark szerzői a programonkénti normalizált lebegőpontos műveletek számát számítják, a forráskódban éppen megtalált műveleteknek megfelelően: Valós FP művelet
ADD, SUB, COMPARE, MULT DIVIDE, SQRT EXP, SIN,. Normalizált FP művelet 1 4 8 Például egy olyan utasítássorozat, amely tartalmaz egy ADD, egy DIVIDE és egy SIN műveletet, az 13 normalizált lebegőpontos műveletként jön számításba. Így a natív MFLOPS nem egyezik meg a normalizált MFLOPS értékkel. - Pentium/1 - Pentium processzor Lefelé 100% kompatibilitás. Szuperskalár architektúra (több utasítás végrehajtása 1 órajel ciklus alatt). Beépített lebegőpontos egység. Külön kód- és adat cache (8+8 KB) Write-Back megvalósítás. Cache kezelés a MESI protokoll szerint. 64 bit-es adatbusz. Multiprocesszor vezérlő. Két beépített utasítás pipeline (U és V) függetlenül működik. 2 integer utasítás/s Programág előrejelzés. A MOV és néhány ALU utasítás huzalozott (nem mikroprogramozott) megvalósítású. A 4KB-os lapok helyett 4MB-os lapok is választhatók. 64 bit 32 bit Kód-cache 32 bit Utasításelőrejelzés 256 bit
Prefetch Pufferek 256 bit 64 bit 64 bit-es busz interfész 64 bit 256 bit Integer egység ALU ALU 32 bit 64 bit 32 bit Regiszter készlet 32 bit 64 bit Pipeline-olt FPU 32 bit Adat-cache Hardver szorzás Hardver összeadás Hardver osztás A pentium processzor blokkvázlata Agárdi-Hadi: Pentium - Pentium/2 - Regiszterek Általános regiszterek: EAX, EBX, ECX, EDX, EBP, ESP, ESI, EDI 32 bit-esek Szegmens regiszterek: CS, DS, SS, ES, FS, GS 16 bitesek (egyszerre 6 szegmens érhető el) Állapotregiszterek: EFLAGS, EIP (32 bit-esek) Vezérlő regiszterek: CR0, CR1, CR2, CR3, CR4 (általában csak az operációs rendszer módosíthatja) Nyomkövető regiszterek: DR0 - DR7 Adat-töréspontok és utasítás-töréspontok létesíthetők a kód megváltoztatása nélkül CPU üzemmódok Valós üzemmód (8086) Az új regiszterek elérhetők (FS, GS is) Bizonyos utasítások (pl. amelyek a deszkriptorokat kezelik) kivételt idéznek elő. Védett (protected) üzemmód
Valódi védett mód 8086-os virtuális mód Reset Valós mód Reset PE=0 PE=1 Védett mód Megszakítás, kivétel Rendszer menedzselő mód Taszkváltás, IRET Virtuális 8086 mód Üzemmód állapotok közötti átmenetek - Pentium/3 - A védett üzemmód működése Az architektúra rendszerszintű lehetőségei: memóriaszervezés védelem multitaszking kivételek és megszakítások ki- és beviteli műveletek (I/O) inicializálás és üzemmód váltás lebegőpontos egység (FPU) menedzsmentje hibaelhárítás és nyomkövetés cache szervezés Memóriaszervező regiszterek Rendszer címző regiszterek 47 32 bit lineáris báziscím 16 15 0 GDTR IDTR Rendszer szegmens regiszterek TR 15 0 Szelektor LDTR Szelektor Deszkriptor regiszterek (automatikusan töltődnek) 32 bit lineáris báziscím 32 bit szegmens határ Jellemzők Memóriakezelő regiszterek A szegmentált memóriaszervezéshez szükséges adatstruktúrák
helyét 4 regiszter határozza meg. Ezek speciális utasításokkal tölthetők fel (általában csak az operációs rendszer teheti meg). Global Descriptor Table Register (GDTR) Local Descriptor Table Register (LDTR) Interrupt Descriptor Table Register (IDTR) Task register (TR) A GDT fizikai címét, és határát tartalmazza Az LDT fizikai címét, határát és attribútumokat tartalmaz. A szelektor egy GDT-beli deszkriptorra mutat. Így taszkonként lehet külön LDT-t használni. A megszakítás deszkriptor táblázat fizikai címét, és határát tartalmazza. Az éppen végrehajtott taszk báziscímét, határát és szegmens szelektorát tárolja. A szelektor egy GDT-beli taszk állapotszegmens (TSS) deszkriptorra mutat. - Pentium/4 - Védett üzemmódú memóriaszervezés Szegmentálás Sík modell. Eltörli a szegmentálást Minden szegmenst a teljes fizikai címtartományra képez le Minden deszkriptor báziscíme 0, a szegmenshatár 4GB Védett sík
modell. Ua, mint a sík modell, csak a szegmenshatár a fizikai memória méretére van beállítva Multiszegmens modell. A szegmentálás teljes körűen működik Minden program saját szegmensdeszkriptor táblázattal és szegmensekkel rendelkezik A szegmensek lehetnek kizárólagosan egy-egy programhoz rendelve, vagy megosztozhatnak rajtuk más programokkal. Szegmenshatár ellenőrzés működik Egy-egy program egyszerre 6 szegmens lát (6 szegmensregiszter). Más szegmensek a szegmensregiszterek átírása révén érhetők el Lapozás A lineáris címtartomány egy 32 bit-s címmel leírható tároló terület. Ez szimulálható valamennyi fizikai RAM-mal és diszk területtel. A diszk terület a teljes logikai címtartományt lefedi, amelynek bizonyos blokkjai jelen vannak a fizikai memóriában A memória és a diszk között fix méretű (4KB) blokkokban történik az adatcsere Ha egy logikai címre hivatkozunk, két eset lehet: a logikai cím fizikai címre
fordítható (a címet tartalmazó blokk a memóriában van). A logikai címet tartalmazó blokk nincs a fizikai memóriában, ezért kivétel keletkezik (page fault). A kivételkezelő mechanizmus lapcserét hajt végre Ezután a kivételt okozó utasítás ismételten végrehajtódik Szegmentálás és lapozás együtt Több lapot átfogó szegmensek Több szegmenst átfogó lapok Nem illeszkedő lap- és szegmenshatárok Illeszkedő lap- és szegmenshatárok Szegmensenként egy laptáblázat - Pentium/5 - Szegmensfordítás Globális Deszkriptor Táblázat Lokális Deszkriptor Táblázat TI=0 TI=1 Szegmens szelektor TI Szelektor Határ Báziscím Határ Báziscím GDTR A deszkriptor tábla kiválasztása (TI-bit) 15 Logikai cím 0 31 Szelektor 0 Offszet Deszkriptor tábla + Szegmens deszkriptor 31 0 Lineáris cím Szegmens fordítás Szegmensregiszterek LDTR - Pentium/6 - Látható rész Láthatatlan rész Szelektor
Báziscím, határ, stb. CS SS DS ES FS GS Szegmens regiszterek Minden memóriahivatkozáshoz egy szegmens regiszter van hozzárendelve. A szegmens regisztereknek van egy látható és egy láthatatlan része. A látható rész programutasításokkal feltölthető (pl MOV), a láthatatlan részt a processzor tölti fel A szegmens regiszterek látható része kétféleképpen kaphat értéket: Közvetlen betöltő utasítások: MOV, POP, LCS, LDS, LES, LSS, LGS, LFS Közvetett betöltő utasítások: CALL, JMP távoli (far) változatai. Ha a szegmensszelektor új értéket kap (látható rész), a szelektor láthatatlan része a deszkriptor táblázatból kiolvasott résszel lesz feltöltve (cache-ként működik). A deszkriptor kiemelése a táblából a címszámítás sebességét hivatott növelni. Szegmensszelektorok Összetevői: Index (13 bit) 8192 deszkriptor közül választ. Táblázat mutató (TI) Kijelöli a GDT-t vagy az LDT-t. Igényelt
privilegizálási szint (RPL) A privilegizálási védelem része. Szegmens deszkriptorok Meghatározzák a szegmensek helyét méretét - Pentium/7 - vezérlő és állapot információit A fordítóprogramok, szerkesztők, betöltők vagy az operációs rendszer állítja elő. Mezői: Báziscím A szegmens kezdete. Felbontás (granularity) Szegmenshatár egysége: byte vagy 4KB. Szegmenshatár (limit) A processzor határellenőrzésre használja. Deszkriptor típusa Lehet: rendszer-, kód- vagy adatszegmens. D/B bit Szegmenstípus Meghatározza a hozzáférés típusát, a szegmens növekedési irányát, stb. Deszkriptor privilégiumszintje (DPL) A védelmet szolgálja. Ennek értékétől függ a szegmens elérhetősége más szegmensekből (lásd később részletesebben) Szegmens jelenléte Jelzi, hogy a szegmens a memóriában van-e. Lapfordítás 31 Lineáris cím 0 Lapcímtár Laptábla Offszet
Lapcímtár Lapcímtár bejegyzés Lapkeret Laptáblázat Laptáblázat bejegyzés Fizikai cím Lapfordítás - Pentium/8 - Védelmi mechanizmusok A taszkok védelmét kell biztosítani. A védelem szegmensekre és lapokra is alkalmazható. Szegmens szintű védelem Minden memóriahivatkozáskor elvégzi a processzor: 1. Szegmens típus 2. Határ (limit) 3. A privilégiumokat érintő megszorítások 4. Az eljárások bemenőpontjait érintő megszorítások 5. Az utasításkészletet érintő megszorítások ellenőrzését. Az ellenőrzés a címfordítással párhuzamosan történik. Bármely szabálytalanság kivételt eredményez. Az ellenőrzés a deszkriptor adatai alapján történik. 1. Szegmens típus ellenőrzés A szegmens típusai: Felhasználói kódszegmens (Olvasható-e?) Felhasználói adatszegmens (Írható/olvasható?) Rendszerszegmens (taszkok, kivételek és megszakítások szervezésére) Kapudeszkriptorok Bizonyos szegmensregiszterek
csak meghatározott deszkriptorokra mutathatnak! 2. Határ (limit) ellenőrzés A hivatkozott cím benne van-e a megadott tartományban? 3. A privilégiumokat érintő megszorítások A processzor 4 privilégium szinttel dolgozik. (0 - 3) A 0-szint jelenti a legprivilegizáltabb szintet! A szintek: 0 Operációs rendszer 1 Perifériakezelő programok 2 Eszközmeghajtók 3 Felhasználói programok Egy program csak a saját privilégium szintjén lévő programokat hívhat! Egy program csak a saját vagy annál alacsonyabb privilégium szinten (nagyob szintszám!) levő adatokat érhet el! - Pentium/9 - A szintek megléte, a hívások és adathivatkozások korlátozása a szintek között a programok és adatok védelmét hivatott biztosítani. Legkevésbé privilegizált szint 3 2 Legprivilegizáltabb szint Adatok Programok Legális elérés Illegális elérés 1 0 Kernel Alkalmazói szint Privilegizálási szintek Privilegizálási szintek a következő adatstruktúrákban
jelennek meg: Aktuális szint (Current Privilege Level = CPL) A CS regiszter alsó 2 bit-je jelöli. Deszkriptor Privilégium szintje (DPL) A deszkriptorban van elhelyezve. A szükséges privilégium szint (RPL) A szegmensszelektor alsó 2 bit-je. Az adathozzáférések korlátozása A hozzáférés engedélyezésének kiértékelésében részt vesz: a CPL, a kijelölt adatszegmens regiszter RPL-je és az adatszegmens deszkriptorának DPL-je Hozzáférés engedélyezve, ha DPL >= Max(CPL, RPL) (pl. CPL= 1, RPL=1, DPL=3 esetben az adatszegmens elérhető) Vezérlésátadások korlátozása - Pentium/10 - Vezérlésátadás: JMP, CALL, RET, INT, IRET utasításokkal vagy kivétel és megszakítás előfordulásakor lehetséges. A JMP és a CALL "far" (távoli) változatai másik kódszegmensre vonatkoznak. Két eset lehetséges: a) Az operandus egy másik végrehajtható szegmens deszkriptorát választja ki. b) Az operandus egy call-kapu
deszkriptorát választja ki (lásd a következő bekezdést a kapudeszkriptorokról) a) eset A vezérlésátadás engedélyezésének kiértékelésében részt vesz: a CPL, a cél-kódszegmens deszkriptorának DPL-je Vezérlésátadás engedélyezve, ha DPL = CPL Gyakran szükség lehet vezérlésátadásra magasabb privilegizálási szintre. Pl egy felhasználói program az operációs rendszer valamely szolgáltatását kívánja igénybe venni. Ez normál kódszegmensre közvetlenül nem lehetséges, csak az ún. kapudeszkriptorok segítségével Kapudeszkriptorok Eltérő privilegizálási szintek közötti vezérlésátadásra használhatók. A kapudeszkriptor szerkezete eltér a többi deszkriptorétól 3 2 1 0 Kapun keresztüli hívások Kapuk Programok Legális elérés Illegális elérés - Pentium/11 - Négy féle kapudeszkriptor létezik: Call kapu Trap kapu Megszakítás kapu Taszk kapu A Call kapu funkciói: Megjelöli egy eljárás
belépési pontját Meghatározza az eljárás hívásához szükséges privilegizálási szinteket A CALL vagy JMP utasítás végrehajtásakor a processzor felismeri, hogy a célszegmens egy kapudeszkriptorra mutat. A call kapu a GDT-ben és az LDT-ben is előfordulhat, de az IDTben nem A kapu-ban lévő szelektor egy kódszegmens deszkriptorát jelöli ki. A kódszegmens deszkriptorának bázisa és a kapu deszkriptor ofszetje együtt a kódszegmens egy eljárásának belépési pontját határozzák meg. Az utasításban lévő logikai cím nincs felhasználva Szelektor Szegmensen belüli ofszet (nem használt) Cél cím Deszkriptor táblázat Ofszet + Szelektor Bázis DPL Számláló DPL Kapu deszkriptor Kódszegmens deszkriptor Eljárás belépési pontja A call kapu működési mechanizmusa A call kapun keresztüli vezérlésátadás engedélyezésének kiértékelésében részt vesz: a CPL, a szegmens szelektor RPL-je, a kapu deszkriptor DPL-je,
a cél-kódszegmens deszkriptorának DPL-je Vezérlésátadás engedélyezve, ha JMP utasítás CALL utasítás Max(CPL, RPL) <= kapu DPL-je, és Cél kódszegmens DPL-je = CPL Max(CPL, RPL) <= kapu DPL-je, és Cél kódszegmens DPL-je <= CPL - Pentium/12 - Veremváltás Egy privilegizáltabb szintre történő eljárás híváskor az alábbiak játszódnak le: a CPL megváltozik, a vezérlés átadódik, a hívott eljárás számára új verem jön létre, amelybe bemásolódik a hívó program verméből a kapudeszkriptor "számláló" mezőjével megadott számú duplaszó. Az új veremre azért van szükség, hogy a hívott (privilegizáltabb) eljárás számára biztosan elegendő hely álljon rendelkezésre. Visszatéréskor a verem tartalma visszamásolódik a régi verembe. Minden futó taszk rendelkezik egy taszk állapot szegmenssel (Task State Segment = TSS), amelyet a TTS deszkriptora jelöl ki a memóriában. A TSS tartalmát az
alábbi ábra mutatja 31 16 15 0 0 0 0 I/O bittérkép TSS határ 0 Back link ESP 0 SS0 ESP 1 SS1 ESP 2 SS2 CR3 EIP EFLAG-ek EAX ECX EDX EBX ESP EBP ESI EDI 0 ES 0 CS 0 SS 0 DS 0 FS 0 GS 0 LDTR T 0 Rendszerfüggő Cím offszet 0 4 8 12 16 . . . Taszk állapotszegmens A TTS-t a taszkok közötti váltáskor használja fel az operációs rendszer a félbe hagyott taszk állapotának elmentésére, ill. a folytatott taszk állapotának visszaállítására - Pentium/13 - Az éppen futó taszk állapot szegmensét a TR processzor-regiszter jelöli ki. Egy privilegizáltabb szintre történő eljárás híváskor az új veremszegmens kijelölésekor szintén a TSS játszik szerepet, ugyanis az ebben megadott ESPx és SSx értékek adják meg az adott privilégiumszinthez tartozó veremszegmenseket. Minden privilégiumszinthez külön veremszegmens tartozik. A 3. privilégiumszinthez nincs veremmutató a TSS-ben, mivel egy 3 szintbeli eljárást nem hívhat meg egy kevésbé
privilegizált program (ugyanis ilyen nem létezik). A taszkok közötti váltást később mutatjuk be. Az operációs rendszer számára lefoglalt utasítások A védelmi mechanizmust vagy a processzor teljesítményét érintő utasításokat csak megbízható eljárások használhatják. Ezek csoportjai: Privilegizált utasítások, amelyeket a rendszer vezérlésére használnak Érzékeny (sensitive) utasítások az I/O-val kapcsolatosak A privilegizált utasítások csak a CPL=0 szinten hajthatók végre. Az I/O-val kapcsolatos, ún. érzékeny utasításokat is védelem alatt kell használni, de 0-tól eltérő privilegizálási szinten is végre kell tudni hajtani Lapszintű védelem A védelem lapokra is vonatkozik. Minden memóriahivatkozáskor a processzor megvizsgálja, hogy eleget tesz-e a védelmi feltételeknek. A védelem megsértése kivételt eredményez. A lapszintű ellenőrzések: A címezhető tartományt érintő ellenőrzések
Típusellenőrzés A lapszintű védelem által használt paramétereket a laptáblázatok tárolják: A címezhető tartományt érintő ellenőrzések Két privilegizálási szint van: Felügyelő szint (U/S=0) (operációs rendszer, eszközmeghajtók, kezelőprogramok) Felhasználói szint (U/S=1) (alkalmazások) A szegmentálásnál használt privilegizálási szintek a lapozásnál használt privilegizálási szinteknek vannak megfeleltetve: CPL = 0, 1, 2 megfelel a felügyelő szintnek. CPL = 3 megfelel a felhasználói szintnek. - Pentium/14 - Típusellenőrzés Kétféle típusú lap van: Csak olvasható (R/W = 0) Írható/olvasható (R/W = 1) A szegmens- és lapvédelem együtt is használható. A védelem bármilyen megsértése kivételt generál. Multitaszking A processzor hardveresen támogatja a többtaszkos működést. A taszk vagy éppen fut, vagy arra vár, hogy fusson. Egy taszkot egy megszakítás, egy kivétel, egy ugrás vagy egy call
utasítás hív meg. Két különböző taszkokra vonatkozó deszkriptor létezik a deszkriptortáblázatban: Taszk állapotszegmens deszkriptor (TSS deszkriptor) Taszk kapu A taszkkapcsolás olyan, mint egy eljáráshívás, csak több processzor-állapotinformáció lesz eltárolva. A futó taszk teljes állapota elmentődik, és az új taszk korábban elmentett állapotinformációi lesznek visszatöltve. Taszkkapcsoláskor nem kerül semmi a verembe A taszkok nem újraindíthatók (nem reentráns) A multitaszkot támogató adatstruktúrák: taszk állapotszegmens (TSS) taszk állapotszegmens deszkriptor taszkregiszter (TR) taszk kapudeszkriptor A taszk állapotszegmens (TSS) tartalma az előző ábrán látható. Taszkkapcsolás A processzor a következő esetekben adja át a vezérlést egy másik taszknak: JMP vagy CALL utasítás egy TSS deszkriptorra JMP vagy CALL utasítás egy taszk kapura Megszakítás vagy kivétel keletkezik, amely az
IDT-ben lévő taszk kapura mutat IRET utasítás végrehajtása (miközben az NT flag magas) Lehetőség van taszkok visszafelé láncolására (linking). Ez esetben egy taszk visszaadhatja a vezérlést az őt hívó taszknak. További taszkszervező lehetőségek: A megszakítások és kivételek kezelése taszkkapcsolással. Minden taszk kapcsoláskor lehetőség van új LDT-re váltani. Ez egy további védelmi lehetőség, ugyanis ezzel a módszerrel lehet meggátolni, hogy az azonos privilégium szinten - Pentium/15 - lévő programok egymást megzavarják. Az alábbi ábra azt az esetet mutatja, amikor csak a GDT-használjuk, LDT-t nem. A 3 szinten futó programok elérhetik egymás adatterületét A rákövetkező ábra a taszkonként külön-külön LDT-vel bíró megoldást mutatja, ahol a 3. szinten futó programok nem zavarhatják egymást, hiszen nem láthatják egymás LDT-jét. 0 DPL = 0 Program 1 DPL = 0 X taszk 2 DPL = 0 X címterület Adat
X taszk . . . 100 DPL = 3 101 DPL = 3 Program 102 DPL = 3 Y taszk 103 DPL = 3 . . . Adat Y címterület Y taszk Operációs rendszer GDT használatával Y címterület X címterület DPL = 3 DPL = 3 X kód Y kód DPL = 3 DPL = 3 Y adat X adat LDT X DPL = 0 LDT Y DPL = 0 DPL = 0 DPL = 0 GDT Operációs rendszer GDT és LDT használatával - Pentium/16 - Az utasítások felépítése Opkód ModR/M SIB Offszet Adat 1,2 0,1 0,1 0,1,2,4 0,1,2,4 Hossz: Prefixek: Hossz: Utasítás prefix Cím méret prefix Operandus méret prefix Szegmens felülíró prefix 0,1 0,1 0,1 0,1 Utasítás formátum 7 6 5 Mod 4 3 2 Reg/Opkód 1 0 R/M ModR/M byte 7 6 SS 5 4 3 2 INDEX 1 Bázis SIB (Skála Index Bázis) byte ModR/M és SIB byte-ok formátuma 0 byte byte - Pentium/17 - A ModR/M és SIB byte-ok meghatározzák az indexelés típusát vagy regiszterszámot, a felhasználandó regisztert vagy az utasítás
kiválasztásához szükséges többletinformációt, a bázis, index és skálával kapcsolatos információt ModR/M byte Mod: 8 regisztert és 24 indexelési módot határoz meg (az R/M-mel kiegészítve) Reg: Regisztert jelöl, vagy az op. kódot egészíti ki R/M: Regisztert, vagy címzési módot jelöl SIB byte (Skála + Index + Bázis) A SIB byte jelenlétét a ModR/M mező egyes kódjai jelzik. SS: skálatényezőt jelöl (az index regiszter 0, 2, 4 vagy 8-al való szorzása) Index: Indexregisztert választ (EAX, EXC, EDX, EBX, -, EBP, ESI, EDI) Bázis: A bázisregiszter választ Prefixek 1. 2. 3. 4. Utasításprefixek: REP, REPE/REPZ, REPNE/REPNZ, LOCK Szegmensfelülíró prefixek: CS, SS, DS, ES, FS, GS Operandusméret felülíró prefix Címméret felülíró prefix Mindegyik csoportból csak 1 szerepelhet! A prefixek sorrendje közömbös. - Pentium/18 - A regiszterkészlet Általános regiszterek 31 16 15 8 7 16 bit 32 bit 0 AH AL AX EAX DH DL DX
EDX CH CL CX ECX BH BL BX EBX BP EBP SI ESI DI EDI SP ESP Szegmensregiszterek CS SS DS ES FS GS Státusz és vezérlő sregiszterek EFLAGS EIP Az alkalmazások számára elérhető regiszterkészlet - Pentium/19 - I/O műveletek Az I/O műveletek a portokon keresztül valósulnak meg. A portok a perifériavezérlőkben lévő regiszterek. Az I/O portok lehetnek: beviteli, kiviteli és kétirányú portok. A portokat adatátvitelre vagy vezérlésre használják. Egy-egy perifériavezérlő általában mindkét fajta porttal rendelkezik. A portok használatának módját az architektúra határozza meg. A portok címzése A processzor az I/O portok kezelését az alábbi módszerekkel teszi lehetővé: 1. Önálló I/O címtartomány használatával A portokhoz I/O processzor-utasításokkal lehet hozzáférni 2. Memóriára leképzett (memory mapped) I/O segítségével A portok memória címként jelennek meg. A processzor mindkét megoldást
lehetővé teszi. Az önálló címtartományt speciális utasítások és hardver védelmi mechanizmus támogatja. A memóriára leképzett I/O memóriakezelő utasításokkal használható, a védelmet a szegmentálás és a lapvédelem biztosítja. A kétféle működés között a rendszer tervezői választanak. A processzor egyetlen kivezetésének (M/IO#) állapota dönti el, hogy egy elindított buszciklus memória, vagy I/O címtartományra vonatkozik. Önálló I/O címtartomány A port címe megadható: byte konstanssal 8, 16 és 32 bit-es portok jelölhetők ki a 0 - 255 címtartományban DX regiszterrel 8, 16 és 32 bit-es portok jelölhetők ki a 0 - 65535 címtartományban Az IN, OUT utasítások adatokat visznek át a port és egy regiszter között. Az INS, OUTS utasítások adatfűzéreket mozgatnak a memória és az I/O címtartomány között. Memóriára leképzett (memory mapped) I/O címtartomány A portok memóriakezelő utasításokkal (pl. MOV)
érhetők el - Pentium/20 - A perifériák vezérlő- és állapotregiszterei az AND, OR, TEST utasításokkal manipulálhatók. A portok elérésére a processzor összes címzési módja felhasználható, ténylegesen úgy kezelhetők, mintha fizikai memóriában lennének. Az adatok cache-elését a portok címtartományára tiltani kell! A védett üzemmódú I/O műveletek A processzor védett üzemmódjában az I/O is védelem alatt áll. Az I/O utasítások védelme: Az EFLAGS regiszter IOPL mezője ellenőrzi az I/O utasítások végrehajtásának engedélyezését vagy tiltását. A TSS szegmens I/O engedélyező bit-térképe ellenőrzi az egyes taszkok számára az egyes portokhoz való hozzáférést. A memóriára leképzett I/O portok védelme: Szegmens és/vagy Lapvédelemmel Az I/O privilégium szintek Az IN, OUT, INS, OUTS, CLI, STI utasítások csak akkor hajthatók végre, ha CPL <= IOPL. Ezzel az I/O műveletek kiadása 0-ás vagy 1-es
privilégium szinthez köthető, vagyis input/output csak az operációs rendszeren keresztül végezhető. Virtuális 8086-os üzemmódban az I/O bittérkép tovább korlátozza az I/O portok elérését. Az EFLAGS regiszter IOPL mezője és az I(nterrupt) flag is csak 0-s privilégiummal változtathatók meg. Az Intel 8086 processzor címsín cím AU + fizikai cím IP puffer +1 buszvezérlõ + adat puffer adatsín 6 Byte regtár ALU BU FLAGS EU mP EC IU dekódoló IR 3 utasítás BU = Bus Unit (Busz vezérlõ egység) IU = Instruction Unit (Utasítás dekódoló egység) EU = Execution Unit (Utasítás végrehajtó egység) AU = Address Unit (Cím kiszámító egység) I8086/80286-os processzor felépítése Az I8086/I80286 processzor részegységei Bus Unit Instruction Unit Execution Unit Address Unit Busz vezérlő egység: Processzor - memória és Processzor - I/O kapcsolat megteremtése Szabad busz ciklus alatt előkészíti a következő
utasítást. Utasítás előkészítő egység Az előkészített utasítást dekódolja ( 3 utasítást dekódol és sorbaállít). Végrehajtó egység A dekódolt utasításban előírt műveletet hajtja végre az (Execution Control) műveleti vezérlő irányítása alatt. Az IR-ben tárolt műveleti kód alapján elindítja a ROM-ban tárolt mikroprogramot. Címkiszámító egység Operandus címeket állít elő a BU számára. Az utasítás végrehajtás lépései 1. Utasítás előkészítés, lehívás (fetch): (IP) -> IR 2. Utasításszmláló regiszter tartalmának növelése: IP + 1 -> IP 3. Műveleti kód (Opcode) értelmezése, dekódolása és az operandus címének meghatározása 4. A művelethez szükséges adatok előkészítése 5. Végrehajtás (execution): a kijelölt művelet végrehajtása Vezérlésátadás esetén: új cím -> IP 6. Eredmény elhelyezése -2- Általános regiszterek 8 8 16 16 16 AX : Akkumulátor regiszter IP: utasítás
számláló (Instruction pointer) BX: Bázis regiszter FLAGS: Jelzõ és vezérlõ biteket tartalmazó regiszter CX: Számláló regiszter DX: Adat regiszter MSW: Gépi állapot szó (Machine status word) SI: Forrás index regiszter DI: Cél index regiszter SP: Verem (stack) mutató CS: Kód szegmens regiszter BP: Bázis mutató DS: Adat szegmens regiszter SS: Verem(stack) szegmens regiszter ES: Extra szegmens regiszter -3- -4- Utasítás formák (I8086, I80286) Utasítások hossza: 1-9 Byte Címek száma: 1 vagy 2 (az egyik cím mindig regisztert címez) Utasítások szerkezete Prefix Opcode Mode Offset Data 0-1 0-2 0-2 0-1 0-2 0-2 I 8086 processzor 0-3 1 I 80286 processzor 0-3 1 6 1 1 2 3 3 Opcode D W MOD REG R/M D = 0 az eredmény byte helye a MOD/RM által meghatározott D = 1 az eredmény helye a regiszter W = 0 az operandus 1 byte-os W = 1 az operandus 2 byte-os -5- A MODE byte tartalma REG 16 bites W=1 8 bites W=0 000 AX AL
001 CX CL 010 DX DL 011 BX BL 100 SP AH 101 BP CH 110 SI DH 111 DI BH -6- Címzési módok Indexelt bázis címzés (eltolással vagy anélkül) W=0 W=1 MOD R/M 00 01 10 11 000 m[BX+SI] m[BX+SI+d8] m[BX+SI+d16] AX vagy AL 001 m[BX+DI] m[BX+DI+d8] m[BX+DI+d16] CX vagy CL 010 m[BP+SI] m[BP+SI+d8] m[BP+SI+d16] DX vagy DL 011 m[BP+DI] m[BP+DI+d8] m[BP+DI+d16] BX vagy BL 100 m[SI] m[SI+d8] m[SI+d16] SP vagy AH 101 m[DI] m[DI+d8] m[DI+d16] BP vagy CH 110 direkt címzés m[BP+d8] m[BP+d16] SI vagy DH 111 m[BX] m[BX+d8] m[BX+d16] DI vagy BH Közvetlen címzés Közvetett regiszter címzés Regiszter címzés Közvetlen indexelt címzés Relatív báziscímzés -7- Memória fizikai címének kiszámítása valós mûködési módban Tároló Szegmens regiszter CS Szegmens kezdet cím 16 bit Relatív cím 0000 4 bit Relatív cím 20 bit Szegmens kezdet 20 bit Fizikai cím Az utasítások csoportosítása
Aritmetikai és logikai uatasítások: Fixpontos +,-,(*,/) Lebegőpontos +,-,(*,/) Ősszehasonlítás Léptetés, forgatás Logikai műveletek Bit vizsgálat (I80386) Bit beállítás (I80386) ADD, ADC, SUB, INC, DEC, MUL, IMUL, DIV, IDIV CMP SHL, SHR, SAR, ROR, ROL, RCR, RCL AND, OR, XOR, NOT, NEG BSF, BSR BT, BTS, BTR, BTC -8- IDIV előjeles Léptetõ és forgató utasítások C 0 Léptetés balra SHL C 0 Logikai léptetés jobbra SHR C Aritmetikai léptetés jobbra SAR RCR C Jobbra forgatás ROR C Balra forgatás ROL RCL Adatátviteli uatasítások: Töltő (Load) Tároló (Store) Mozgató Reg <- Mem/Reg Reg -> Mem Mem -> Mem MOV MOV MOVS MOV op1, op2 XCHG op1, op2 PUSH regiszter tartalma -> Verem POP regiszter tartalma <- Verem LDS Mem -> regiszter, szegmens regiszter LES -“- LEA Mem offset -> Reg LDS DI, 32 POINTER a memóriában lévő címet tölti be LEA BX, TABLE LEA BX, TABLE[SI] (indexelt) -9- Verem (stack) kezelés SP mindig
az utolsó felhasznált byte-ra mutat PUSH AX: SP <-- SP - 2 SP (SP) <-- AX AH AL POP AX: AX <-- (SP) SP <-- SP+ 2 SS a verem teteje 1. 0. SS = Stack szegmens regiszter String kezelő utasítások MOVS CMPS STOS SCAS LODS [DS:SI] -> [ES:DI], DI++, SI++ [DS:SI] CMP [ES:DI], DI++, SI++ [ES:DI] <- AL (AX), DI++ AL (AX) CPM [ES:DI], DI++ AL (AX) <- [DS:SI], SI++ A fenti string kezelő utasítások közül a MOVS, STOS és a LODS a REP (ismétlés) prefix-el is használható és jelentése: - 10 - While CX<>0 string művelet CX CX -1 End While REP, REPE, REPZ: While CX<>0 string művelet CX CX -1 If ZF = 0 ciklus befejezése End While (REPNE, REPNZ: If ZF<>0 ciklus bef.) Beviteli/Kiviteli utasítások IN AL/AX, cím OUT cím, AL/AX INS, OUTS 8 vagy 16 bites I/O blokkos átvitel (80386) Vezérlés átadó utasítások Eljárás hívó (Subroutin) utasítások CALL, RET, RET n Ugró utasítások: feltételes és feltétel
nélküli (JMP) Előjelet figyelembe veszi = JE <> JNE > JG >= JGE < JL <= JLE Előjelet nem veszi figyelembe JE JNE JA JAE JB JBE - 11 - Egyéb ugró utasítások: JNO, JPO JNP, JP JPE, JPO JS, JNS JZ, JNZ JC, JNC JCXZ LOOP Overflow Parity Even, Odd parity Sign Zero Carry ugrik, ha CX =0 ugrik, ha CX <>0 Az offset 1 byte (az ugrás távolsága -128 --- +127) Speciális utasítások: NOP No operation HLT Stop STI Set Interrupt (megszakítás engedélyezve) CLI Clear Interrupt (megszakítás nincs engedélyezve) WAIT várakozó állapot, amíg külső megszakítás nem érkezik (koproc.) Feltételes ugrások összefoglalása Mnemonik Jelentés Ellenőrzött Flag-ek JB/JNAE Jump if below CF = 1 Jump if not above or equal to JAE/JNB Jump if above or equal to CF = 0 Jump if not below JBE/JNA Jump if below or equal to CF = 1 or ZF = 1 Jump if not above JA/JNBE Jump if above CF = 0 and ZF = 0 Jump if not below or equal to JE/JZ Jump if equal
to ZF = 1 JNE/JNZ Jump if not equal to ZF = 0 JL/JNGE Jump if less than SF # OF Jump if not greater than or equal to JGE/JNL Jump if greater than or equal to Jump if not less than - 12 - SF = OF JLE/JNG Jump if less than or equal to ZF = 1 or SF # OF Jump if not greater than JG/JNLE Jump if greater than ZF = 0 or SF = OF Jump if not less than or equal to JP/JPE Jump if parity PF = 1 Jump if parity even JNP/JPO Jump if no parity PF = 0 Jump if parity odd JS Jump if sign SF = 1 JNS Jump if not sign SF = 0 JC Jump if carry CF = 1 JNC Jump if not carry CF = 0 JO Jump if overflow OF = 1 JNO Jump if not overflow OF = 0 - 13 - Az assembly program elkészítésének lépései 1. Forrásprogram (ASM) elkészítése szövegszerkesztővel 2.Tárgykód (OBJ) generálása az assembler fordítóprogrammal (TASM) 3. Futtatható program (EXE) létrehozása tárgykód szerkesztővel (TLINK) 4. Tesztelés (Turbo Debugger) TASM .ASM .OBJ EXE TLINK
Szoftver és hardver kapcsolat Alkalmazói program DOS hívás Int 21 és más interrupt-on keresztül DOS BIOS funkciók hívása interrupt-on keresztül BIOS IBM PC hardver: Display adapter, billentyûzet, nyomtató, diszk - 14 - Hardver működtetése I/O portokon és memórián keresztül
esetén az adatok elérési ideje 8 - 10-szerese a cache tár elérési idejének. Az átlagos elérési idő 95%-os találati arány esetén kb. 50%-kal nagyobb a cache elérési idejénél A cache tárak jellemzői, típusai Visszakeresés a keresett adat címe alapján történik. A címet (vagy annak egy része), amelynek alapján a visszakeresés történik "tag"-nek nevezik. A címen és az adaton kívül a cache az az adatok állapotára vonatkozó, a vezérlést segítő és a helyettesítési eljárást segítő adatokat is tartalmaz. Vezérlő bit-ek: V (Validity bit), érvényességi bit Az adat a megadott címhez tartozik, és helyes. A cache tár törlésekor (flush) az összes V-bit 0-ra vált. D (Dirty bit) A blokk egy része módosult. Nem lehet a helyére új blokkot betölteni, amíg ki nem írjuk a főtárba. C (Coherence bit) A 'V' és 'D' bit-tel együtt a főtár tartalma és a cache blokkjai közötti
egyezőség biztosítását segíti. SV (Supervisor bit) Jelzi, hogy a blokk felhasználói- vagy rendszeradat. A hozzáférési védelmet segíti. - Cache-tárak/3 PID (process identifier bits) Jelzik a blokk valamely feladathoz tartozását. Megakadályozzák az illetéktelen felhasználásokat. Használata esetén, nem kell a cache-t kiüríteni taszk váltáskor Helyettesítési bit-ek (replacement bits) A blokkok cseréjéhez nyújtanak információt. A visszakeresés módja szerint: Teljesen asszociatív cache A blokk bármely sorban lehet: rugalmas, hatékony, de költséges a sok öszszehasonlító áramkör miatt. Közvetlen leképzésű cache A blokk csak egyetlen sorban lehet. merev, a "tag" rövidebb Olcsó, mert nem kell asszociatív memória, de a találati arány alacsonyabb. Csoport asszociatív cache A fenti két megoldás között helyezkedik el, elég hatékony, és nem túl költséges. Tartalmának karbantartása A
tartalom betöltése az igény felmerülésekor (demand fetching) előkészítéssel (prefetch) Aktualizálás azonnali átírás (write through) visszaírás (write back) Helyettesítési eljárások véletlenszerű csere FIFO-elv (First-In-First-Out) Legkevésbé használt elemek cseréje (LRU) Adategyezőség biztosítása A főtár és a cache tartalmának egyezőségét biztosítani kell! A főtár és a cache tartalma több okból is eltérhet: a processzor a cache-ben módosít, majd csak később aktualizálja a tárat (writeback módszer) a főtár tartalmát egy másik egység módosítja (lapváltás, I/O DMA-val) több processzor is használja a tárat több cache is van a rendszerben - Cache-tárak/4 (a) Visszaírási módszerek A közvetlen átírás (write-through) módszer problémamentes. A cache módosításával együtt a főtár is aktualizálva lesz A visszaírási (write-back) módszer problémát okozhat,
ha a tárat más egység is használja (DMA). (b) A cache tár strukturális elhelyezkedése az adatáramlási útvonalon 1. Címfordítás szempontjából A virtuális tárkezeléshez kapcsolódik. Processzor - Tárolókezelő (MMU) - Cache tár - Főtár elrendezés A cache tár fizikai címeket kap. Egyértelmű megfeleltetés van a cache tár címei és a főtár között. A cache használata lassulhat. Processzor - Cache tár - Tárolókezelő (MMU) - Főtár elrendezés A cache virtuális címekkel dolgozik, így a cache működése gyors. Különböző folyamatokhoz tartozó virtuális címeket ugyanahhoz a fizikai címhez rendelheti az MMU (szinonimák). Ezt a problémát külön áramkörökkel (TLB, ITB ) kezelik. 2. I/O átvitelek szempontjából Az I/O átvitel közvetlenül a főtárba/-ból Figyelő rendszert (snoop logic) alkalmaznak, amely minden címet ellenőriz a cache-ben, amelyhez tartozó adat a sínen áthalad. Ha a főtár tartalma változik,
és az adat a cache-ben is megtalálható, a figyelő logika a cache tartalmát érvényteleníti (V-bit), vagy aktualizálja a cache-t. A főtárból olvasáskor, ha az adat a cache-ben is megtalálható, a cache-ből szolgálja ki az adatot. Az I/O átvitel a cache-en keresztül (I/O through cache) Nincs adat-egyezőségi probléma. A cache forgalma megnő A cache-hez többszörös hozzáférést kell biztosítani MESI protokoll Több processzoros rendszerekben még nehezebb az adategyezőség biztosítása (különösen, ha több cache is van). Elterjedt a MESI protokoll használata. A MESI elnevezés a cache blokkjai aktuális állapotainak: Modified, Exclusive, Shared, Invalid kezdőbetűiből tevődik össze. - Cache-tárak/5 - SHR Lehetséges állapotok: SHW I S RMS RH SHR M E S I modified exclusive shared invalid WH SHW WM SHR RME Állapotátmenetek: SHW RH M WH E RH WH RH read-hit WH write-hit RMS read-miss, shared RME read-miss, exclusive WM
write-miss SHR snoop-hit on a read SHW snoop-hit on a write /read with intent to modify MESI protokoll állapotdiagramja Cserny: RISC processzorok A cache blokkok állapotai az alábbi 4 állapot valamelyikében lehetnek: Módosított (modified) A cache blokkja a főtárhoz képest módosítva lett, és ez az egyetlen érvényes adatblokk. Kizárólagos (exclusive) A cache blokk a főtárral egyezik, érvényes, és más cache-ben nem fordul elő a blokk. Megosztott (shared) A cache blokk a főtárral egyezik, érvényes, de legalább még egy cache-ben megtalálható a blokk. Érvénytelen (invalid) A cache blokk érvénytelen adatot tartalmaz. Az egyes állapotok közötti átmenetet kiválthatja olvasás/írás a cache-ből/-be a figyelő logika - Futószalagos és szisztolikus architektúrák/1 Futószalagos és szisztolikus adatpárhuzamos architektúrák Mindkét architektúrára jellemző, hogy egy nagy adatkészlet elemein képes
hatékonyan elvégezni ugyanazokat a számításokat anélkül, hogy a vezérlésen változtatni kellene. Az egymás utáni eredmények olyan ütemben keletkeznek, amilyen ütemben a bemeneti adatok eljuthatnak a rendszerhez. Futószalagos architektúrák Legfontosabb alkalmazása a képfeldolgozás. Az alkalmazás legfontosabb jellemzői: azonos műveleteket kell elvégezni egy hosszú adatfolyamon a számítások eredménye minden pontban csak korlátozott számú szomszédos képpont függvénye Az ábra elvi megoldást mutat arra, hogyan lehet a fenti két jellemzőt kiaknázni a képfeldolgozás teljesítményének növelésére. Bemenő adatok Léptetőregiszter Léptetőregiszter Kimenő adatok Adatpárhuzamos futószalag Sima: Korszerű számítógép architektúrák A képpontokból alkotott adatáram léptetőregiszteren keresztül éri el a tárolóelemeket, amelyekből aztán a feldolgozóelem a szomszédossági követelményeknek megfelelő adatokat
közvetlenül felhasználhatja. A léptetőregiszterek annyi tárolóelemből állnak, ahány képpont alkotja a feldolgozandó kép sorait. A párhuzamosságot itt az jelenti, hogy a feldolgozóelem egyszerre képes fogadni a környezetében lévő adatokat, - és a processzor bonyolultságától függően - az eredmény kialakításában párhuzamosan működhetnek feldolgozóelemek. - Futószalagos és szisztolikus architektúrák/2 Pl. ha a szomszédos képpontok szürkeségi szintjeinek átlagát kell kiszámítani, párhuzamosan négy összeadó áramkör működhet az adatpárok összeadásakor. Nyolc több-bites bemenet Összeadó Összeadó Összeadó Összeadó Osztó Összeadó Összeadó Összeadó Kimenet Processzorművelet: átlagolás Sima: Korszerű számítógép architektúrák A futószalagról kikerülő eredmény azonnal a második, hasonló futószalag bemeneti léptetőregiszterébe kerülhet. A párhuzamosság alacsony fokú, a feldolgozandó
környezet méretétől függ. Ez elérheti a 25x25 kiterjedést is A feldolgozóelem bonyolultsága az egyes rendszerekben nagyon különböző lehet. A feldolgozandó környezet méretének változtatása a regisztertár átkonfigurálását teszi szükségessé. Ugyanez szükségessé teszi a processzor párhuzamosan működő feldolgozóelemeinek átkonfigurálását is. A párhuzamos futószalag elven működő számítógépek speciális alkalmazásokban akár több nagyságrenddel felülmúlhatják egy munkaállomás teljesítményét. - Futószalagos és szisztolikus architektúrák/3 Szisztolikus architektúrák Ebben a rendszerben a bevitt adatokat keresztülpumpálják egy műveletvégző rendszeren, az eredmény általában egy hosszú adatsor. A "szisztolikus" elnevezés a szív hasonló pumpáló mozgásának analógiájából született. A működési elvet egy mátrixszorzás példáján követhetjük. i n j m i Egy sor X Egy oszlop A j B m = n
Cmn Az eredmény egy eleme C Mátrixok szorzása Sima: Korszerű számítógép architektúrák Két négyzetes mátrix szorzásának eredménye egy ugyanolyan méretű négyzetes mátrix, mint a szorzó és a szorzandó mátrixok mérete. A szisztolikus elv alkalmazása: Az eredménymátrix minden elemének kiszámításakor azonos műveleteket kell elvégezni. A mátrix adott oszlopában (vagy sorában) az eredmények kiszámításához a bemenő mátrix adott oszlopának (vagy sorának) minden elemére szükség van. A szükséges adatok könnyen bevihetők sorosan oszloponként vagy soronként a rendszerbe. A sok részeredmény (egy sor- és egy oszlopelem szorzata) párhuzamosan számítható. - Futószalagos és szisztolikus architektúrák/4 A fenti jellemzők alapján készíthető szisztolikus rendszer főbb paraméterei: A műveletvégző egységek egy négyzetben helyezkednek el, amelynek mérete megegyezik az összeszorzandó mátrixok
méretével. Minden műveletvégző elem egy szorzó, egy összeadó és egy tárolóegységből áll. A tömb minden eleme ugyanazokat a meghatározott műveleteket végzi. Minden elem csak a legközelebbi szomszédjához kapcsolódik, és a kapcsolat csak egyirányú. A rendszert egyetlen vezérlő órajel vezérli, amely a műveleteket szinkronizálja. A bemeneti adatok a tömb két oldaláról érkeznek, egyenesen haladnak végig Az eredménymátrix a tömb másik oldalán távozik. 1. Bemenő adat Adatelemek Feldolgozóelemek Késleltetőelemek Eredmény Szisztolikus mátrixszorzás rendszerkapcsolása Sima: Korszerű számítógép architektúrák A két mátrix sorai ill. oszlopai balról és felülről érkeznek a rendszerbe A mátrixok egymás utáni sorait ill. oszlopait azonban késleltetni kell, ugyanis a tömb közbülső feldolgozóelemei a sor- és oszlopadatokat a tőlük balra, ill a felettük lévő feldolgozóelemtől kapják
Ilyen módon az első ütemidőben csak az F1,1 feldolgozóegység fog működni és elvégzi az első részletszorzat és részösszeg kiszámítását. A második ütemidőben már az F1,2 és az F2,1 feldolgozóegység is működésbe lép, hiszen balról és fentről megérkeznek a számításhoz szükséges adatok. Minden ütemidőben több egység lép működésbe mindaddig, amíg a legelső egység be nem fejezi az utolsó részletszorzat és összeg kiszámítását. Ezután minden ütemidőben egyre több műveletvégző egység áll le. - Futószalagos és szisztolikus architektúrák/5 - Működő cella Nem működő cella Műveletek végrehajtása a szisztolikus tömbben Sima: Korszerű számítógép architektúrák A műveletvégző egység az alábbi ábrán látható. Fentről Balról Szorzó Tároló Jobbra Összeadó Alulra Szisztolikus mátrixszorzás műveletvágző egysége Sima: Korszerű számítógép architektúrák - VLIW architektúrák/1
- Hosszú utasításszavú architektúrák Very Long Instruction Word (VLIW) Az utasításszintű párhuzamosságot hasznosítja. Több párhuzamosan működő végrehajtóegységgel rendelkezik. A fixpontos és a lebegőpontos adatokhoz használhat közös vagy külön regisztertárat. Mindét megoldásra van példa. A VLIW és a szuperskalár processzorok közötti fő különbség az utasításaik felépítésében és az ütemezés módjában van. A VLIW processzorok utasításai minden végrehajtóegységhez külön-külön vezérlőmezőt tartalmaznak. Gyorsítótár/ memó -ria F Egyetlen több műveletes utasítás VE VE Gyorsítótár/ memó -ria F Többszörös utasítás VE VE VE VE Regisztertár Regisztertár VLIW megoldás D utasítás/vezérlés adat D dekódoló egység F: utasítás lehívó egység VE: végrehajtó egység Szuperskalár megoldás A szuperskalár és VLIW processzorok közötti főbb különbségek Sima: Korszerű
számítógép architektúrák - VLIW architektúrák/2 Az utasítások hossza függ: a végrehajtóegységek számától és az egyes végrehajtóegységek vezérléséhez szükséges mezők hosszától Hagyományos VLIW (széles utasításszavú) architektúrák 5-30 végrehajtóegység 16-32 bites vezérlőszó végrehajtó-egységenként (100-1024 bit) Pl.: Trace 28/200 gép 28 utasítást képes végrehajtani ciklusonként, szóhosszúsága 1024 bit A túl hosszú utasításszó hátrányai: Nem lehet minden ciklusban kihasználni az összes vezérlőmezőt, ezért a programok nagy tárigényűek. Nagy memória sávszélességet igényel. Assembly szinten manuálisan nem programozható (sok végrehajtóegységet kellene egyszerre figyelembe venni) Pl. a Trace számítógépre fordított FORTRAN programok háromszor hosszabbak egy VAX gépre fordított programnál. Keskeny VLIW architektúrák 2-3 utasításmezőt tartalmaznak. (Pl.: Az Intel-HP IA-64
architektúra 3 műveleti mezőt tartalmaz) Utasításszavúk 100 bit-nél rövidebb. A VLIW processzorok statikus ütemezése A függőségek észrevétele és kezelése teljes egészében a fordítóprogramra hárul. A statikus ütemezése előnye, hogy a processzor egyszerűbbé válik (nem szükséges az adatfüggőségek észrevétele, az utasításvárakoztatás, a regiszterátnevezés a soros konzisztencia biztosítása). A processzor kevesebb áramköri elemet tartalmaz Az alacsonyabb bonyolultság miatt nagyobb órajelfrekvencia valósítható meg. A statikus ütemezése hátránya, hogy sokkal bonyolultabb fordítóprogramot igényel. A fordítóprogramnak ismernie kell a processzor és a memória minden jellemzőjét, amely az utasítások ütemezéséhez szükséges. Ismernie kell a végrehajtóegységek számát, típusát, késleltetési és ismétlési értékeiket, a gyorsítótár késleltetési idejét, stb. Tehát a fordítóprogramnak technológiafüggő
paramétereket is figyelembe kell vennie. Egy processzorcsalád különböző tagjaihoz általában nem használható ugyanaz a fordítóprogram, vagyis a VLIW fordítók tecnológiafüggőek. Ez az egyik legnagyobb korlátjuk. A technológiaérzékenységhez tartozik a gyorsítótár találati hibáinak problémája. - VLIW architektúrák/3 Az adatok behívásakor lényeges eltérés van az adatok rendelkezésre állásának idejében cache találat és cache hiba esetén. A fordítóprogramnak az adatfüggőségek vizsgálatakor a legroszszabb esetet kell figyelembe vennie, ami jelentősen ronthatja a teljesítményt A VLIW architektúra a szuperskalár architektúrával van versenyben. A VLIW architektúra jövőjét az határozza meg, hogy a csökkentett bonyolultságból származó előnyöket ki tudja-e használni a nagyobb teljesítmény eléréséhez. A technológia fejlődésével a szuperskalár processzorok teljesítménye is növekszik. A szuperskalár processzorok
végrehajtási párhuzamossága is eléri azt a határt, amelyet a programokban lévő párhuzamosság mértéke még indokol Ez általános célú programok esetén 6-8, műszaki-tudományos programoknál 10-20 Néhány mai szuperskalár processzor is rendelkezik többműveletes utasításokkal (HP PA, Power, PowwrPC). Egyetlen utasításban megadható egy lebegőpontos szorzás és összeadás Tehát ezek a processzorok bizonyos esetben VLIW processzorként viselkednek. Kevés VLIW architektúrájú gép jelent meg kereskedelmi forgalomban. A Trace 200 család 3 modellje (1980-as évek végén jelent meg): Trace 7/200, 14/200 és 28/200. A magasabb sorszámú modellek a 7/200-as modellek összekapcsolásával készültek Összehasonlító teljesítményadatok: Típus Trace 7/200 Trace 14/200 DEC 8700 Cray XMP Ciklusidő [ns] 130 130 45 8 Linpack teljesítmény (MFLOPS) 6 10 0,97 24 A Trace gépek jelentősen felülmúlják a drágább DEC gép teljesítményét, és
összemérhető a Cray XMP szuperszámítógép teljesítményével. A Trace család gépei UNIX 4.3 BSD operációs rendszert használtak Műszaki-tudományos feladatokhoz használták Fortran programnyelven. A Multiflow cég fejlesztette. - Vektorarchitektúrák/1 - Vektorarchitektúrák Az adatpárhuzamos megoldások legsikeresebb megvalósítása a vektoros szuperszámítógépek. Legsikeresebben a nagy teljesítményt igénylő tudományos számításoknál alkalmazzák őket. Nagy teljesítményük a vektorozott felépítésnek és a modern technológiának köszönhető. Gyártóik: Cray, Convex A vektorizálás főbb komponensei: Nagyfokú adatpárhuzamosság, amelynek forrása a szószervezés A szóhosszt hatékonyabban használják ki, mint más rendszerek. A szavak nagyobbak is lehetnek, mint a soros számítógépeké A szószervezés a gép teljes architektúrájára jellemző (memóriaszervezés, kommunikációs csatornák). Az adatszavak elhelyezése
vektorokban A vektorok az adatszavak százait tömörítheti, és ezeket a vezérlésfolyam egyedi adatként kezeli. Ez elérheti a 64KB-ot is Egy-egy utasítás ideális esetben ennyi adatelemen végez műveleteket. Ez előnyös azáltal, hogy egyetlen utasításlehívással sok adaton lehet elvégezni a kijelölt műveletet, és a vektorok összefüggő memóriaterületeken helyezkednek el, amelyeknek a betöltését is hatékonyan lehet elvégezni. A futószalagos feldolgozás mikro- és makroszinten Az egyes elemi műveleteknél, és több műveleti elem esetén is alkalmazzák a futószalagot. Az adat be- és kivitelnél, az adatvektorok kezelésénél szintén alkalmazzák a futószalag elvet A műveleti elemek párhuzamosítása A vektorok párhuzamos árama is feldolgozható, például több lebegőpontos összeadó, szorzó és több egész típusú műveleti egység működtetésével. A fenti négy technika egyenkénti alkalmazása kb. 10-10-szeres gyorsítást
jelent, együttesen mintegy 1 000-10 000 -szeres gyorsítás érhető el. A hatékony működtetés feltétele a megfelelő alkalmazások kiválasztása, és az adatok megfelelő formátumú összeállítása. Az utóbbi feladatban nagy szerepe van a párhuzamos fordítóprogramoknak Az ilyen számítógépek teljesítménye 1-10 GFlop. A vektorszámítógépek a legbonyolultabb rendszerek az adatpárhuzamos gépek között. Szóhossz A szóhosszt a számábrázoláshoz igazítják (pl. 64 és 32 bites szabványos IEEE lebegőpontos számábrázolás). A fixpontos számábrázolási formákat is úgy alakítják ki, hogy az a szóhosszúsághoz jól illeszkedjék. - Vektorarchitektúrák/2 - Vektorizálás A művelet végrehajtásának fázisai: 1. Az első cím kiszámítása 2. Az első adat betöltése t1 3. A második cím kiszámítása 4. A második adat betöltése t2 5. Az eredmény kiszámítása 6. Az eredmény címének kiszámítása t3 7. Az eredmény
tárolása Nem vektorizált számítási mód Egy eredmény számítási ideje: N eredmény számítási ideje: t1 + t2 + t3 N (t1 + t2 + t3) Vektorizált számítási mód N eredmény számítási ideje: (t1 + N t2 + t3) A cím kiszámítása és az adatok előkészítése, majd az eredmények visszatárolása jelentős időt vesz igénybe. A vektorizálással a cím kiszámítására csak egyszer van szükség, hiszen az adatokat egy összefüggő címtartományról vesszük elő Az adatlehívás is vektoronként történik A művelet végrehajtásának fázisai még a futószalag technikának is alá van vetve. A hatékonyság attól függ, hogy mennyire eredményesen lehet az adatokat vektorizálni, és hogy a vektorizálás a teljes folyamat lelassulása nélkül elvégezhető-e. A futtatás előtt gyakran az adatok átrendezése szükséges. Futószalagos adatkezelés A soros processzoroknál megismert futószalag technikát alkalmazzák. Nagyon fontos, hogy a futószalag
szemcsézettsége optimális legyen, a futószalag fázisainak végrehajtási ideje azonos legyen. - Vektorarchitektúrák/3 - Párhuzamos számítási folyamatok Funkciópárhuzamos, adatpárhuzamos vagy a kettőt egyesítő megoldást alkalmaznak a tervezők. A funkcionális párhuzamosság itt azt jelenti, hogy külön végrehajtóegység van a fixpontos és a lebegőpontos számításokhoz, amelyek párhuzamosan működtethetők. Ennek kihasználásához az alkalmazásokban lennie kell olyan számítási egységeknek, amelyek hasznosíthatók Az adatpárhuzamosság úgy valósítható meg, hogy minden típusú végrehajtóegységből több is készül, amelyek párhuzamosan működnek. Ezek kihasználásához az adatok sorozatát, amelyeken azonos típusú műveleteket kell elvégezni, darabokra kell bontani, és a rendelkezésre álló egységekkel elvégeztetni. Számítások Egyes egység FX Többszörös egység FX LP 2 4 LP + 2 4 + Párhuzamos számítások
Sima: Korszerű számítógép architektúrák A Cray család 1976-ban jelent meg az első Cray szuperszámítógép. A technológia folyamatosan fejlődött és a párhuzamosság egyre növekedett. A Cray család 4 generációjának teljesítménye: Rendszer Központi Órajel [MHz] egység Cray-1 X-MP Y-MP C90 1 4 8 16 80 105 166 240 Lebegőpontos eredmények órajelenként 2 2 2 4 Mozgatott MFlop ráta szavak óraje- [Adatszó/órajel] lenként 1 80 3 840 3 2667 6 15360 - Vektorarchitektúrák/4 - Fő jellemzőjük a vektoros feldolgozás, egy-egy programlépés adatelemek csoportján indít el műveletet. Vektorregisztereket alkalmaznak, amelyekben a beolvasott adatvektorokat átmenetileg tárolják. Ezáltal a processzoron belüli műveletvégzés és a memória közötti adatmozgás függetlenné válik A futószalagot az utasítások feldolgozása és az aritmetikai egységek esetében egyaránt alkalmazzák. A memóriához többszörös hozzáférést alkalmaznak,
amellyel jelentősen megnő a memóriaigényes alkalmazások végrehajtási sebessége. A Cray90 rendszer felépítése 2, 4, 8 vagy 16 processzort tartalmazhat. C916 főbb jellemzői: 16 processzor van. A 8GB nagysebességű memória egyformán hozzáférhető minden processzor számára. A maximálisan 256 ki/bemeneti csatorna 13,6 GB/s sávszélességet biztosít a perifériák és a hálózat eléréséhez. Összeköttetés a nagymértékben párhuzamos Cray T3D-hez. Opcionális szilárdtest tárolók, amelyek 32 GB kapacitásúak, 14,6 GB/s sávszélességgel. Egyidejű skaláris és vektoros feldolgozás. Minden processzornak két független műveleti szegmense van. A vektoros feldolgozás az iteratív műveletek teljesítménye miatt jóval gyorsabban szolgáltat eredményt, mint a hagyományos skalár feldolgozás, míg a skalár műveletek kiegészítik a vektoros alkalmazásokat olyan esetben, amikor a probléma nem adaptálható vektoros
technikára. Memóriaszervezés A központi memóriát az összes CPU használhatja, és mindegyik a teljes címtartományt elérheti. Minden CPU 4 dupla szélességű porttal csatlakozik a memóriához. Többszörös adatátvitel folyhat a memória és a CPU-k között. Az elrendezés hierarchikus: 8 független szekció Szekciónként 8 alegység Minden alegységben 2 feldolgozócsoport Minden csoportban 8 feldolgozóegység (összesen 1024 feldolgozóegység) - Vektorarchitektúrák/5 - Közös regiszterek és valós órajel 0. CPU 2. CPU . . . 1. CPU Központi memória 8 rész, 64 alegység, 1024 feldolgozóegység, 1024 Mszó 14. CPU 3. CPU . . . 15. CPU Ki/bemeneti alrendszer A processzorok és a memória közti adatforgalom Sima: Korszerű számítógép architektúrák Minden CPU-nak független összeköttetési útvonala van minden szekcióhoz, amellyel 128 64bites memóriaművelet végezhető órajelenként. A programkód és az adatok ugyanabban
a memóriában vannak. Minden szó 80-bites (64 adatbit + 16 bit a hibafelismerésre és javításra). A memóriát a processzorok és a ki/bemeneti alrendszer közösen használják. A processzor felépítése A processzorok egyforma felépítésűek. A processzorok műveleti regiszterekből, funkcionális egységekből, és egy utasításvezérlő hálózatból áll. A műveleti regiszterek és a funkcionális egységek 3-féle feldolgozásban szerepelhetnek: cím, skalár és vektor A címfeldolgozás a belső információk (címek, indexek), a vektorok hosszának és a léptetések számának vezérlésénél használatos. Ezt 2 fixpontos ALU látja el A skaláris feldolgozás egyedi számokon, számpárokon végez aritmetikai műveleteket. 5 funkcionális egység kizárólag skaláris feldolgozást végez, 3 lebegőpontos egység megosztva végzi a vektorműveleteket. A skalár és vektorműveletek párhuzamosan is végrehajthatók a lebegőpontos műveletek
kivételével. A vektoros funkcionális egységek két vektor vagy egy vektor és egy skalár között végez műveleteket. Az eredmények a vektor-regiszterekbe kerülnek 2 lebegőpontos funkcionális egység van A vektorműveletekben az egyik a páros, a másik a páratlan elemeken végez műveleteket - Vektorarchitektúrák/6 - Vektorműveletek A vektor lehet egy 1 dimenziós tömb, vagy egy 2 dimenziós tömb sora, oszlopa vagy átlója. A hosszú vektorok 128 elemű egységekben (vagy maradék formájában) vesznek részt a vektorműveletekben. A vektorok tördelését a fordítóprogramok végzik A műveletek két elempáron hajtódnak végre egyszerre. A vektor elemeinek feldolgozását az elemszámláló regiszter ütemezi. A vektorizálás önmagában mintegy 10-szeresére növeli a sebességet. A vektorregiszterek és a központi memória közti adatmozgás blokkonként történik. A memóriaművelethez meg kell adni az első szó címét, a növekményt vagy
csökkenést, és a vektor hosszát. Az adatmozgás sebessége 2 szó/órajel sebességű. Gyártástechnológia A technológia emittercsatolt (ECL) logikára épül. Az integráltság foka: Rendszer Cray-1 X-MP Y-MP C90 1000 kapu/lapka 2 16 2 500 10 000 Szoftver A hardverben rejlő párhuzamosság csak a megfelelő felhasználói programokkal használható ki. Operációs rendszer: UNICOS (UNIX System V alapokon). Interaktív, helyi kötegelt és távoli kötegelt feldolgozást támogat. Számos, - a Cray által készített - függvény kiegészítést tartalmaz a teljesítmény növelésére. Egy-egy program több processzoron futhat: Önelosztó megoldás Automatikusan szétosztja a párhuzamos Fortran vagy C program kódot a proceszszorok között, ezzel a párhuzamosságot a ciklusok szintjén valósítja meg. Ehhez nincs szükség programozói beavatkozásra. Ciklusszintű megoldás (micro-tasking) A DO ciklusok szintjén valósítja meg a párhuzamosságot a
Fortran vagy C programokban. A program kódot nem kell módosítani, a programozó mindössze direktívákat épít be, amelyekkel jelzi a párhuzamosságot A szinkronizálás egyszerű, mivel a kicsi kódrészek eredményesen partícionálhatók. Makro-szintű megoldás Alprogramok szintjén teszi lehetővé a kód több processzoron történő végrehajtását. A programozó egy szubrutinkészlet segítségével szinkronizálja az alprogramokat a Fortran, C vagy Ada programokban. - SIMD architektúrák/1 - SIMD architektúrák A kereskedelmileg is sikeres architektúrák egyike a SIMD-rendszer (a vektorszuperszámítógépek és a MIMD-rendszerek a másik kettő). A sikerhez az alábbi tényezők járultak hozzá: a koncepció egyszerűsége és a jó programozhatóság a szerkezet szabályossága a méret és a teljesítmény egyszerű skálázhatósága számos olyan területen való közvetlen felhasználhatósága, ahol szükség van a párhuzamosságra a
megfelelő teljesítmény eléréséhez A SIMD rendszerek legfontosabb elvei (Steven Unger): Az elemek egy kétdimenziós tömbben helyezkednek el, és mindegyik a négy legközelebbi szomszédjához kapcsolódik Minden processzor párhuzamosan ugyanazt a műveletet hajtja végre. Minden processzornak van saját belső memóriája. A processzorok programozhatók, és különböző feladatok elvégzésére alkalmasak. Az adatok gyorsan haladnak át a tömbön. Kell egy központi számítógép, ami az utasítások forrása és egy külön rendszer az adatbevitelre, az eredmények megjelenítésére és tárolására. Processzortömb Tömbvezérlő Központiszámítógép Adatillesztő Adat ki/be Háttértároló A SIMD-rendszer jellemző felépítése Sima: Korszerű számítógép architektúrák - SIMD architektúrák/2 - Néhány kereskedelmi megvalósítás: DAP (Distributed Array Processor) 1976, ICL. 32x32 elemű processzortömb. MPP
(Massively Paralell Processor) 1983, Goodyear Corp. 128x128 elemű processzortömb. Bitsoros elemekkel és közeli összeköttetésekkel dolgozott. Connection Machine 1985 Bonyolult hiperkocka hálózat Thinking Machine Inc. gyártotta MasPar 1990 Egy bitesnél bonyolultabb feldolgozóelemekkel rendelkezett. A távoli összeköttetéseket többszintű crossbar kapcsolókkal oldotta meg. Az IBM, Cray, DEC, nCUBE is gyártanak SIMD elven működő számítógépeket. A gépek tervezésénél eldöntendő kérdések: a feldolgozóelemek bonyolultsága (processzor alap-adattípusa, utasításkészlet bonyolultsága, memória nagysága) az egyes elemek lokális autonómiájának meghatározása az elemek összeköttetésének módja a feldolgozóelemek száma, az összeköttetések elrendezése a tartalék egységek elosztása a megvalósítás technológiája A szemcsézettség Meghatározza a viszonyt a feldolgozóelemek száma és az adatkészlet
párhuzamossága között. Finom szemcsézettségű rendszerek: Minden feldolgozóelemhez csak kevés számú adatelem tartozik Durva szemcsézettségű rendszerek: Minden feldolgozóelemhez sok adatelem tartozik Az ideális az 1:1-es megfeleltetés lenne, de a jellemző alkalmazásokban ez a technológia mai fejlettségi fokán még nem megvalósítható. - SIMD architektúrák/3 Másik probléma a különböző alkalmazásokban használt adatkészletek eltérő mérete. Nehéz rugalmasan bővíthető SIMD rendszereket készíteni. Az adatelemenként elvégzendő számítások bonyolultsága hatással van a feldolgozóelemek típusára és bonyolultságára. Ez pedig technológiai és gazdaságossági szempontból hatással van a maximálisan elérhető párhuzamosságra. A megoldások általában a két végletet célozzák meg: Finom szemcsézettség egyszerű feldolgozóelemekkel Durva szemcsézettség bonyolult feldolgozóelemekkel Összeköttetési módok
Kívánatos lenne: ha bármelyik processzor bármelyik másik processzorral egységnyi idő alatt tudna kommunikálni. ha a kommunikációs események párhuzamosan mehetnének végbe. ha a kiindulás és a cél előre meghatározható lenne. ha a rendszer bizonyos redundanciával rendelkezne a hibás elemek és összeköttetések helyettesítése céljából. A fenti szempontoknak eleget tevő hálózat kiválasztása a legnehezebb döntés. A megismert összeköttetési módok alkalmazhatók: SIMD-összeköttetés Közeli szomszédok Fa Piramis Hiperkocka Jellemzők Nagy átmérő, nagy sávszélesség Kis átmérő és sávszélesség Kis átmérő, bonyolult programozás Kis átmérő és nagy sávszélesség A processzorok bonyolultsága Ez határozza meg a rendszer felhasználhatóságát. Az alkalmazás jellege is meghatározza, hogy milyen műveletekre van szükség: Tudományos kutatás: lebegőpontos műveletek Képfeldolgozás: logikai műveletek Az
áramkörök precizitása Ugyanaz a műveleti pontosság elérhető különböző precizitású processzorokkal. Gyakran egybites feldolgozóelemeket használnak, mert ez rugalmasan felhasználható különböző pontosságú számításokhoz. Például a képfeldolgozásban különböző pontosságú adatelemekkel dolgoznak, és ez leghatékonyabban egybites feldolgozóelemekkel valósítható meg. Az egybites feldolgozóelemek lényegesen egyszerűbbek és nagyobb méretű tömbök alakíthatók ki, és az összeköttetések is egyszerűbben megvalósíthatók. - SIMD architektúrák/4 - Finom szemcsézettségű SIMD-architektúrák Legfontosabb jellemzőik: A feldolgozóelemek minimális bonyolultsággal és a lehető legkisebb autonómiával rendelkeznek. A processzorok maximális számát gazdaságossági megfontolások határozzák meg. A programozási modell feltételezi, hogy a feldolgozóelemek száma megegyezik az adatelemek számával. Az
összeköttetés modellje: 4 pontú közeliszomszédos. A szokásos programozási nyelv soros, párhuzamos adatokra vonatkozó kiegészítésekkel. Az újabb rendszerek néhány ponton eltérnek a fenti modelltől: A feldolgozóelemek bonyolultsága nő: vagy több-bites alapon működnek, vagy kiegészülnek speciális aritmetikai elemekkel. A szokásos rács mellett további összeköttetések is léteznek: hiperkocka, crossbar. A helyi memória mérete növekszik. Az MPP finom szemcsézettségű rendszere Massively Paralell Processor Kimenet Kapcsoló Vezérlő VAX 11/780 128x128-as processzortömb Osztott memória Kapcsoló Bemenet Az MPP-rendszer Sima: Korszerű számítógép architektúrák A feldolgozóelemek 128x128-as négyzetrácsban helyezkednek el. Az MPP a NASA számára készült, és főleg képfeldolgozásra használják. A 88 tömbkártya mindegyike 24 processzorlapkát (192 processzorral) támogat a hozzátartozó memóriával együtt.
Tokonként 8 processzor Tömbönként négy tartalék processzoroszlop van elhelyezve, amely a hibatűrést biztosítja. - SIMD architektúrák/5 A feldolgozóelemek a közeliszomszédokkal vannak összekapcsolva. Az adatok bevitelét és kivitelét különválasztották, és ún. lépcsős memóriaszervezést valósítottak meg, amely könnyű átalakítást tesz lehetővé a bit-formátum és az egész adattípus között. A tömböt egy VAX 11/780-as számítógép és egy önálló tömbvezérlő vezérli. Programozási nyelv: párhuzamos Fortran és párhuzamos Pascal. A szabványos nyelvet kiegészítették az adattömb adattípussal, és egy előfeldolgozás során az adattömbre vonatkozó műveleteket olyan szubrutin-hívással helyettesítik, amely a vezérlő kifejezést a megfelelő interfészhez irányítja. A műveletvégző egységek: Minden adatcsatorna, regiszter és funkcionális egység 1 bites. Önálló összeadóval, tömbléptetővel és
logikai műveletvégző egységgel rendelkezik, amelyek párhuzamosan működnek. A szomszédoktól érkező bemeneti adatok multiplexeren keresztül érkeznek. Egyetlen kimeneti adat van, amely a szomszédokhoz kerül. Egy különálló regiszterbit (S) kapcsolódik a többi processzor megfelelő elemeihez, és ezzel egy olyan bemeneti/kimeneti léptető regiszter jön létre, amely önállóan képes működni a processzor többi elemétől. Ezzel átfedhető a számítás és az adattovábbítás. A helyi memóriát egy másik berendezés szolgáltatja. Összeadó Léptetőregiszter B P A C Logika adat ki S adat be MUX Külső memória Szomszédokhoz Szomszédoktól Az MPP-processzor elemei Sima: Korszerű számítógép architektúrák - SIMD architektúrák/6 Az MPP áramkör teljesítménye Művelet Adat bevitel/kivitel Összeadás Szorzás Közeli szomszéd Helyi 3x3 átlag Körbejárás (3x3) Tömb mozgatása 1 képponttal Pontosság 1 bites 16 bites 32 bites
lebegőpontos 16 bites egész 32 bites lebegőpontos 1 bites 8 bites 8 bites 8 bites Idő[µs] 0,1 2,5 33 10 60 1,5 12,4 9,5 1,7 Blokkok száma 1 25 330 100 600 15 124 95 17 Példa az alkalmazásra Képek szegmentálása Feladata a képeket olyan összefüggő részekre osztani, amelyek képpontjai bizonyos szempontból összetartoznak. Az alkalmazott szempont (feltétel) lehet például a szürkeségi szint, a textúra, az alak. A leggyakoribb felosztási módszer, hogy a kép minden (előre megadott) kis területére megvizsgálják a feltételt, és azokat a részeket összekapcsolják, amelyek között az eltérés egy küszöbszint alatt van. A módszer több iteráció során jut el a megoldáshoz. A párhuzamosan elvégezhető művelet a területek közötti hasonlóság vagy eltérés számítása a megadott feltétel alapján. 3.5 A RISC gépek Reduced Instruction Set Computer - csökkentett utasítás készletű gép Ezeket megelőzték a Complex Instruction Set
Computer - bonyolult utasítás készletű gépek 3.51 A CISC gépek fejlődése A számítástechnika kezdeti szakaszában az operatív tár rendkívül drága erőforrás volt. Ez adta az alapját annak a gondolkodásmódnak, hogy a legjobb architektúra az, amely - a memóriabeli helyfoglalást tekintve - a legrövidebb programot eredményezi. Más, az architektúra minőségét mérő tényezők voltak az utasításonkénti bitek száma vagy a program-végrehajtás során befetchelt program- és adatbitek száma. A mikroprogramozás bevezetése után gyorsították az utasításoknak a memóriából történő fetchelését, ami javította a végrehajtás hatékonyságát. Mivel egyre több funkciót hajtottak végre mikrokóddal, annak mérete növekedett. Mivel már akkora volt, hogy nem lehetett hibamentes, ezért írható memóriába tették (WCM Writable Control Memory) Ez lehetővé tette, hogy a mikrokódot a használt programnyelvhez vagy alkalmazáshoz lehessen adaptálni.
A funkciók mikrokód formájában való megvalósításának másik oka az volt, hogy ezeket a funkciókat könnyebb volt öszehangolni a támogató fordítóprogramokkal. Amennyiben egy magasszintű programnyelv elemet (statement) egyetlen gépi nyelvű utasítássá fordítható, akkor a compiler-ek írása egyszerűbbnek tűnik. Továbbá, amennyiben a gépi nyelv tartalmaz olyan utasításokat, amelyek közeli kapcsolatban állnak a magasszintű programnyelv elemeivel, akkor összezárul az a szemantikai rés (gap), amely a magasszintű programnyelv és a gépi nyelv között van. Példaképen néhány utasítás, amelyet a VAX-11 gépi nyelvéhez adtak a magasszintű programnyelvek jobb támogatása érdekében: az INDEX, a CASE és a CALL utasítás vagy a MC68020-éhoz a CHK utasítás. A fentről lefelé történő kompatibilitás igénye arra kényszeríti a számítógép gyártókat, hogy állandóan növeljék az utasítás-készletüket az újabb és hatékonyabb
modelljeikben. Az utasításkészlet ilyen gazdagítása párhuzamosan folyt a címzési módok számának a hasonlóan gyors növekedésével. Például, míg a MC68000 12, MC68020 már 18 címzési móddal rendelkezett A kódsűrűségi mutató és a sok utasítás szükségesé tette, hogy változó hosszúságú utasítás-formátumokat használjanak. Így az utasítások opcodja és operandus-specifikáló mezője változó hosszúságú A VAX-11-nél például nem lehet megmondani, hogy hol kezdődik a következő utasítás specifikáló mezője, amíg az előző utasítás specifikáló mezőjét nem dekódoltuk. A különféle utasítás-hosszak azt eredményezhetik, hogy az utasítások tetszőleges bájtokon, sőt bizonyos architektúráknál tetszőleges biteken kezdődjenek, ami bizony nem eredményez hatékony utasítás-fetchelést, sem pedig hatékony adatátvitelt. A már korábban bevezetett utasításokat nem lehet elhagyni, hiszen ezeket alkalmazták a
felhasználói programokban és ez szoftver-inkompatibilitáshoz vezetne. Tehát az egyes processzorok utasításkészlete - a szoftver-kompatibilitási kényszer miatt - állandóan csak növekedhet. Nézzünk meg néhány ismert CISC architektúrát: Jellemző Bevezetési év Az utasítások száma A Control Memory mérete: Kbájt Utasítás-hossz (bit) IBM 370/168 1973 208 420 16-48 VAX 11/780 1978 303 480 16-456 iAPX-432 1982 222 64 6-321 3.52 1980: RISC fizikai és logikai architektúra kialakulása Fizikai architektúra Az University of California, Berkeley (UCB) kutatócsoportja a 70-es évek végén azon dolgozott, hogy egyetlen chip-en kialakítson egy nagyteljesítményű processzort, ezért a tervezés során mindent igyekeztek egyszerűsíteni. Több éves program-elemzés eredményeképpen megállapították, hogy a CISC gépek utasításainak mintegy 25%a használja a gépidő 95%-át (s ráadásul ezek pont a legegyszerűbb utasítások voltak). Ez impliciten
magában hordozza, hogy a hardver által támogatott utasításoknak a 75%-át szinte egyáltalán nem használják. S a ritkán használatos utasítások a bonyolultabb utasítások közé tartoztak. Természetesen felmerült a logikus kérdés: Miért kell elpazarolni az értékes lapka-területet ritkán használt utasítások számára? A modern számítógép CPU áramköreinek többsége az utasítás-dekódolást és a végrehajtásuk vezérlését végzi. A mikroprogramozott CISC számítógépeknél is az áramkörök több, mint a fele a vezérlési célra szolgál. Az UCB kutatók észrevették, hogy a kis utasítás-készlet kisebb vezérlő-áramkör mennyiséget igényel, és a felszabaduló helyet más, a teljesítményt tovább növelő funkciók telepítésére lehet használni. Kutatni kezdték az alkalmazási programokat, hogy mely utasításokat használják tipikusan, milyen gyakran kerülnek végrehajtásra és milyen CPU-erőforrásokra van szükség azok
támogatására. Ezek a tanulmányok kimutatták, hogy a nagy regiszterkészlet növeli a teljesítményt, továbbá, hogy bizonyos utasítás-osztályokat a nagyobb teljesítmény érdekében optimalizálni kell. Tehát a gondolatmenet lényege: • • • • • • az utasításkészlet 75%-át elhagyták, s ezek ráadásul pont a bonyolultabb utasítások voltak ezáltal igen jelentősen (akár a tizedére is) csökkenthették a lapkán a vezérlőrész által igényelt területet s a felszabadult helyet regiszterekkel töltötték fel. E munkák eredményeképpen született meg a RISC I típusú gép 1980-ban, mely valóban egyetlen chip-en egy nagyteljesítményű processzort jelentett. Logikai architektúra A Stanford University kutatócsoportja John Hennessy vezetésével 1981-ben a MIPS nevű gép tervezésével kapcsolatosan a számítógép és a fordítóprogram (compiler) viszonyát kezdte vizsgálni. A kutatásuk témája az optimalizáló compiler tervezése és
megvalósítása, az egyciklusos utasításkészlet. Ezen úttörő kutatásoknak az eredménye a Neumann-architektúrájú számítógépek egy új típusa tervezési filozófiájának megalapozása volt. A csökkentett utasítás-készletű számítógép-tervezés olyan számítógépeket eredményezett, amelyek az azonos technológiával készített számítógépeknél gyorsabban hajtották végre az utasításokat. További RISC gépek: IBM RT, HP Spectrum, AMD 29000, Sparc, MC88000, Intel i860 és i960, IBM RISC/6000. 3.54 RISC gépek logikai architektúrája Az egyszerű utasítások érveit alapvetően program-végrehajtási statisztikákkal húzták alá. 3.541 Egyszerű utasítások Ezeknek gyors a végrehajtásuk, tipikusan utasításonként egy ciklusidő alatt. 3.542 Fix hosszúságú utasítások Fix hosszúságú utasítások, ez gyorsítja az utasítás-fetchelést. 3.543 Kevesebb utasítás-formátum A nagy számú utasítás-formátum azt jelenti, hogy az adott
bitmezőt - más mezőktől, mint például az opcode mezőtől függően - különféleképpen interpretáljuk. Ennek következtében az utasítás dekódolás tovább tart, mivel több kapu-késleltetést jelent. Ez megnövelheti a processzor ciklus-idejét és az utasítás-dekódoláshoz több hardvert igényel. A RISC utasítások csupán néhány különböző formátummal rendelkeznek, ami gyorsítja az utasítás-dekódolási műveletet. 3.544 Load-store architektúra - A RISC gépek többsége load-store architektúrával rendelkezik. Ez azt jelenti, hogy a load és a store utasítás biztosítja az adatátvitelt a CPU regiszterek és az operatív tár között. Valamennyi adatmanipulációs utasítás korlátozott, hogy az operandusok vagy csak a CPU regiszterben lehetnek, vagy pedig az utasítás szónak kell tartalmaznia. - Csupán néhány bit szükséges az adatot tartalmazó regiszter megnevezéséhez. Sok gép számára előnyös a három-operandusos utasítás
használata, mely lehetővé teszi egyetlen utasításban a következő feladat megoldását: Ri [Rj] + [Rk] Az ilyen jellegű utasítás különösen előnyös optimalizáló compiler használatához. Ezek nagyobb teljesítményűek, mint a két operandusú párjuk, mivel a végrehajtásukhoz nem igényelnek több óraciklust. - többszörös regiszter-készlet, átfedő regiszterek. Az adatfeldolgozást végző utasításoknak rrr típusúaknak kell lenni. Ez biztosítja a legrövidebb operandusfetchelési időt Nagy számú regisztert kell tudni használni, hogy minél több aktiválási rekordot lehessen bennük tartani. Csak a LOAD/STORE utasítások biztosítják az operatív tárral a kapcsolatot A memória-hozzáférést optimalizálni kell. 3.545 A kis konstansok és kis displacement, mint immediate adat A 32-bites fix hosszúságú utasítások - mint amit több RISC architektúra is használ - viszonylag nagyobb konstansokat is magában foglalhatják, mint immediate
mezőt. Pl a MIPS gép 8 bites immediate értékeket enged meg, ami lehetővé teszi, hogy az összes konstansok a 95%-át immediate értékként specifikáljuk. Hasonló érv érvényesül a displacement mező vonatkozásában is; az esetek többségét a 8-16 bit lefedi. 3.546 Kevés adattípus A műveletek száma csökkentésének egyik útja, hogy csökkentjük azadattípusok számát. Feltehetjük a kérdést, hogy vajon van-e igény valamennyi integer adattípusra. A char és a logikai változók 8-bites formátumot használnak. Mivel az adatmanipuláló műveletek 32-bites regisztert használnak, ezért vizsgáljuk meg a 8-bites operandus kezelését a load/store műveleteken keresztül. A 32-bites regisztereknél - optimalizáló compiler-t használva lehetséges a a load-store szám csökkentése, megengedve négy darab 8-bites integerrel kapcsolatos load-store műveletet szimultán módon, azaz egyidejűleg. A többi esetben egy 8-bites load művelet helyettesíthető egy
32bites load művelettel, amit egy bájt kiemelése (extract) követ; a 8-bites store helyettesíthető egy 32-bites loaddal, egy bájt beszúrásával és egy 32-bites store művelettel Ez azt jelenti, hogy a bájtos load-store műveletek lassabban (egy helyett 2-3 ciklus) kerülnek végrehajtásra, mint a szavas műveletek, mivel ezek végső soron emulálva valósulnak meg. A statisztika pedig azt mutatja, hogy a load/store műveleteknek mindössze 5% használ 8-bites operandust. Tehát a hiányzó 8-bites adattípusok feldolgozása csekély időveszteséget okozva emulálhatók. 3.547 Egyszerű címzési módok Ez teszi lehetővé a gyors címszámítást. Egy utasítás komplexitását az operandusok specifikálására használt címzési módok is meghatározzák. Komplex címzési módnak hívjuk azokat, amelyek egyetlen ciklus alatt nem határozhatók meg, mivel több összeadást és/vagy további szó-kiterjesztést igényelnek. Egy Motorola 68020 statisztikából kiderült,
hogy a forrásoperandusok 16, a rendeltetési operandusoknak pedig a 19%-a komplex A load és a store utasításokban használt címzési módok pedig úgy korlátozottak, hogy csak egyetlen memóriahozzáférést igényelhetnek. Azok a címzési módok, amelyek több, CPU-n belüli belső műveletet igényelnek, szintén ki vannak küszöbölve. Például a RISC gépeknél nincs meg az autoinkrementálási címzési mód, mivel ez általában egy további óraciklust igényel, hogy inkrementáljuk a regiszter tartalmát. Még fontosabb, hogy az autoinkrementálási módot ritkán használják a compiler-ek. 3.548 Kevés utasítás 3.549 A feltételes ugró utasítások A 32-bites utasítás-hossz miatt lehetőség van arra, hogy az összehasonlító és ugró-utasítást egyetlen utasításban valósítsuk meg. Ez azt jelenti, hogy egyetlen ciklus alatt végrehajthatókká válnak Hennessy szerint az ugróutasítások 99%-át megelőzi egy összehasonlítási vagy tesztelési
művelet. 3.5410 Eljárás-hívások A fontosságuk miatt részletekbe menően tanulmányozták az eljárás-hívásokat. Megállapították, hogy a hívott eljárásoknak mindössze az 1%-a használt hatnál több paramétert, s csupán a 6%-uk rendelkezett több, mint 6 lokális paraméterrel. Ezek a számok alátámasztják azt az elképzelést, hogy az eljárások aktiválási rekordjai nem hosszúak. Az eljárások másik jellemzője az egymásba-ágyazottságuk. Megállapították, hogy az bizonyos mértékig korlátozott, igen ritka az, amikor több egymásba ágyazott eljárás nagyobb mélységet ér el. Továbbá, miután elértünk bizonyos egymásba ágyazottsági mélységet, a mélység már csekély mértékben változik, azaz az eljárások kb. hasonló mélységűek Ez természetes következménye annak, ahogy a programokat strukturáljuk Ezek az argumentumok támogatják azt az ötletet, hogy a paramétereket és az eljárásokban deklarált lokális változókat
regiszterekben tároljuk, úgy, hogy az aktiválási rekordok egy részét regiszterekben tartsuk. Ezért született a RISC I-nél a többszörös regiszterkészlet átfedő változata. 3.55 A RISC gépek fizikai architektúrája Több gyorsítási mechanizmust tekintenek a RISC architektúrák vonatkozásában "szabványosnak", ezeket összegezzük az alábbiakban: 3.551 Vezérlőegység A CPU - mint fizikai architektúrában majd vesszük - a következő részekből áll: ALU, regiszterek, belső sín és kapcsolók s az egészet a vezérlőegység által generált jelek vezérlik. A vezérlőegység által elfoglalt terület a gépi utasítások számától és összetettségétől függ. A bonyolult, többlépéses utasítások sok helyet igényelnek a control memory-ben. Huzalozott vezérlés esetén pedig összetett logikai áramkörre van szükség Egy kevés számú, egyszerű utasítással rendelkező mikroprocesszor esetén a vezérlőegység kevés helyet igényel.
A megtakarított helyet pedig más eszközökre használhatjuk, például nagy számú regisztert vagy cache memóriát telepíthetünk rá. A futószalag technika a legáltalánosabb módja a az utasítás-feldolgozó egység gyorsításának. A nem RISC, nagy teljesítményű gépekben is alkalmazzák ezt a technikát, de a RISC gépek legtöbbjére ez jellemző. Az utasítások egyszerűségének következtében viszont a RISC futószalagok kevesebb lépcsőt tartalmaznak, mint a CISC processzoroké. 3.552 ALU Lebegőpontos aritmetika A lebegőpontos műveleteket intenzíven használja egy sor számítógép-alkalmazás, mint például a tudományos számítások, a digitális jelfeldolgozás és a grafika. Sok számítógép rendelkezik speciális eszközökkel, hogy felgyorsítsák a lebegőpontos műveleteket, s ez alól a RISC gépek sem kivételek. A RISC gépek többsége a lebegőpontos műveletekhez speciális utasításokkal rendelkezik és olyan hardverrel, mely ezeket a
műveleteket nagy sebességgel végrehajtja. A lebegőpontos műveletek egy összetett, többlépéses utasítás-sorozat végrehajtását jelentik, hogy kezeljük a mantisszát és az exponenst és gondoskodjunk az olyan feladatokról, mint az azonos kitevőre hozás vagy a normalizálás. Az ilyen utasításoknak a számítógép utasítás-készletébe való beiktatása a RISC tervezési filozófiától idegennek tűnik. De ez nincs így Valójában a lebegőpontos aritmetika egy kiváló példa a RISC megközelítés üzletpolitikájára. Egy adott utasítást akkor iktatnak be az utasítás-készletbe, amennyiben az egy jobb általános teljesíményhez vezet. Ebben a megközelítésben a kulcs-szempont az, hogy mennyire gyakran használják az adott utasítást egy tipikus alkalmazásban. S mivel a lebegőpontos műveleteket gyakran használják, ezért a lebegőpontos számítások gyorsítására szolgáló utasítások beiktatása jogos. Egy fontos szempont a futószalag CPU
utasításkészletében, hogy az utasítások többségének kb. hasonló végrehajtási idejűnek kell lennie. A többlépcsős végrehajtás miatt a lebegőpontos műveletek vonatkozásában nehéz megszervezni, hogy azok integer párjának megfelelő idő alatt kerüljenek végrehajtásra. Emiatt e két utasítás-típus nem integrálható egyetlen futószalag struktúrába. Ezért a lebegőpontos hardver általában egy önálló processzort képez, melynek megvan a saját futószalag szervezése. Általában ezt lebegő pontos segédprocesszornak hívják. A lebegőpontos segédprocesszort elhelyezhetik ugyanazon a morzsán, mint a CPU-t, de megvalósítható önálló morzsán is, amelyet a megfelelő sínnel csatlakoztatunk a CPU-hoz. Ez különösen akkor hasznos, amikor a hardver lehetővé teszi mind az integer, mind pedig a lebegőpontos aritmetikai egység számára a párhuzamos működést, a szoftver vezérlése alatt. Ilyen esetben a hardvernek elegendő
információt kell tárolnia az egyes egységekben folyó számítási folyamat előrehaladásáról, hogy biztosítsa a helyes számítást, amikor egy megszakítás vagy más jellegű kivételes esemény fellép. 3.553 Regiszterek Általában megállapíthatjuk, hogy jótékony hatást gyakorol a számítógép teljesítményére, ha nagy számú CPU regiszterrel rendelkezik, mivel ez csökkenti a a gyakori adatátvitel szükségességét a CPU és az operatív tár között. A modern compiler-ek sokféle algoritmust használnak, hogy az adott gépen elérhető regisztereket maximálisan kihasználják, mivel a regiszterekben tárolt változókon végzett adatműveletek kevesebb időt igényelnek. A többször használt adatoperandust csak egyetlen egyszer szükséges betölteni a regiszterbe, mivel a regiszter a feladat folyamán dedikáltan szolgálhat az adott operandus tárolására. Egyébként, ha a regiszterek száma kicsi, az operandust mindannyiszor be kell töltenünk az
operatív tárból, ahányszor csak szükségünk van rá. Más szavakkal, kis számú regiszter az adott feladat megoldásához szükséges load és store utasítások számának növeléséhez vezet. S a futószalagos CPU esetén a load és a store utasítások lelassítják a műveleteket Tehát előnyös, ha a load és a store műveletek számát csökkentjük több regiszter biztosításával. Ugyanakkor a nagy számú regiszter csupán egy szükségtelen üres hely, amennyiben a compiler nem használja azt ki hatékonyan. A RISC gépek többsége legalább 32 regiszterrel rendelkezik, de vannak 128 regiszteresek is 3.554 Memória Jelenleg a legtöbb számítógép a Neumann koncepciót követi, mely szerint az utasítások és az adatok keverve, ugyanazt a memóriát használják. Nyilvánvaló, hogy az egy memória-ciklus alatt átvitt utasítások és adatok mennyiségét az elérhető memória sávszélesség korlátozza. Amennyiben ez a sávszélesség nem elegendő, akkor a
processzor nem tud a maximális sebességével működni. A memória-sávszélesség növelésének egy lehetséges módja, hogy két különálló memóriát vezetünk be: egyet az utasítások, egyet pedig az adatok számára. Ez két memória-elérési útvonalat eredményez, ami a párhuzamosság egyik formája. Az ilyen architektúrát Harvard architektúrának nevezzük. A Harvard architektúra alapkövetelménye, hogy a program ne változtassa meg önmagát. Ez nem túl nagy követelmény, mivel a program ön-módosítást rossz gyakorlatnak tartják A legtöbb RISC implementáció Harvard architektúrát használ, hogy független elérési utat biztosítson az utasításokhoz és az adatokhoz, s ezáltal megduplázza a memória sávszélességet. Mivel a rövid ciklusidő és minden ciklusban egy utasítás végrehajtása a cél, az operatív memória nem tudja támogatni az igényelt sávszélességet, így cache memória használata a követelmény. A Harvard architektúra
lehet a CPU-cache interfésznél, így tehát két cache memória van, annak ellenére, hogy az egyetlen operatív tárban találhatók mind az utasítások, mind pedig az adatok; Utasítás cache Közös adat- és program memória CPU Adat cache Harvard architektúra - az operatív tárnál, akkor elkülönült utasítás- és adat-memória van. Utasításmemória CPU Adatmemória Harvard architektúra 3.555 Cache memory Egy nevezetes funkcionális blokk, amit egy RISC gépben megtalálhatunk, az a cache memória. Bár a cache memória hasznos bármely számítógépben, ennek a szerepe a RISC gépekben különösen fontos. A hosszú memóriahozzáférési idő vagy hosszú CPU óraciklus használatát, vagy pedig minden egyes memóriahozzáféréshez több, mint egy óraciklus használatát igényli. Összefoglalás Míg kezdetben a RISC esetében a fő hangsúly az utasításkészlet csökkentése eredményezte kisebb vezérlőrészen, s a lapkán így felszabaduló
helynek a regiszterekkel való feltöltésén volt, napjainkban a feldolgozás-átszervezésével tudtak igen nagy teljesítmény-növekedést elérni (futószalag, szuperskalár architektúra, stb.), ezért a RISC-előny hangsúlya áttevődött a fix utasításhosszra (egyszerű az utasításlehívás), • • az egyciklusos utasításokra (egyszerű a feldolgozás szervezés), • • a load-store architektúrára (rrr utasításformátum). • • 3.56 A RISC/CISC ellentmondás A RISC filozófia bevezetése rengeteg vitát eredményezett az érdemeiről. - - - A kulcskérdések egyike a teljesítmény, mivel a RISC processzorokat úgy tartják, hogy túlszárnyalják a CISC-eket. S valóban, a mérések alapján Assembly nyelvnél 30-50%-kal, magas szintű programnyelvnél, mint pl. a C, 2-3szor gyorsabb A következő szám a relatív kódméret. Mint várható, a RISC kód terjedelmesebb, mert az utasítások egyszerűbbek, azaz azonos funkcióhoz több gépi kódú
utasításra van szükség: 40-50% statikus kódnövekedés: ennyivel több a gépi kódú utasítások száma; 10-30% dinamikus kódnövekedés: ennyivel nő a ténylegesen felhasznált bájtok száma (a CISC gépnek az átlagos utasítás-hossza nagyobb: ha a RISC 1 hosszú, a CISC 1,1-1,4). A megvalósítás vonatkozásában több kedvező tény szól a RISC mellett: Jellemző Az elemek száma Szabályossági faktor A vezérlési rész a teljes lapka %-ban A tervezési idő hónapban RISC I 44K 25 6 19 MC-68000 68K 12 50 30 Z8000 17,5 K 50 53 30 Az elemek száma: a lapka komplexitását jellemzi. Szabályossági faktor: a manuálisan tervezett elemek (tranzisztorok, stb.) és a könyvtárból vett, szabvány elemek száma. az egyszerűségénél fogva a RISC megközelítés nem igényel sok manuálisan tervezett elemet Ez egyrészt munkaerő és idő-megtakarítást jelent, másrészt pedig csökkenti a hibalehetőséget is. A vezérlési rész a teljes lapka %-ban: az
egyszerű utasítások kevesebb vezérlést igényelnek. A tervezési idő hónapban: A rövid tervezési idő igen fontos, különösen a konkurencia-harcban. Egy termék élettartamát a technológiai szintje határozza meg. Amennyiben az új technológia időtartamát három évnek vesszük, a RISC megközelítés élettartama 30-19=11 hónappal, azaz lényegében egy évvel hosszabb, mint egy CISC termék. A RISC filozófia fő hozzájárulásának a RISC I processzor nagy regiszter-készletét tartják, különösen pedig a többszörös, átfedő regiszterkészletet. Az valójában vitatható, hogy ez valójában a RISC jellemzője-e Az a RISC javára szolgál, hogy a vezérlési rész csökkentése lehetővé tette, hogy a lapkán olyan nagy regiszter állomány jöhessen létre, amilyen a VAX-11 vagy az MC68000 esetében lehetetlen. Hitchcock (1985) többszörös, átfedő regiszterkészlettel látta el a VAX-11-et és az MC68000-at, továbbá szimulálta a RISC I processzort
egyetlen regiszter-készlettel. A konklúziója szerint a többszörös, átfedő regiszterkészlet teljesítménye független az architektúrától. CISC Egyre inkább konvergálnak RISC 1978 1980 napjaink RISC oldalról vizsgálva: elkezd növekedni a RISC-processzorban implementált műveletek száma. pl lebegőpontos műveletek CISC oldalról: a miniatürizálás eredményeképpen csökken a vezérlőrész mérete s így növelni tudják a regiszter-teret Harvard memória alkalmazása pl. a Pentium processzorokban (külön adat és külön utasítás-cache) a korszerű szuperskalár CISC processzorok megvalósítása során egyre gyakoribb, hogy szuperskalár RISC magot használ. Ilyen Például az Nx586, a K5 és a Pentium Pro 4.33 A CPU-teljesítmény mértékegységei Több népszerű számítógép-teljesítmény mértékegység létezik. 4.331 MIPS Million instructions per second A MIPS vonatkozásában jó, hogy egyszerű megérteni a fogalmat, főképpen a
felhasználó által is, és a gyorsabb gépek nagyobb MIPS-szel rendelkeznek, ami megfelel a szándéknak. A problémák viszont a következők: a MIPS függ az utasításkészlettől, ezért nehezen vethetők össze a különböző utasításkészletű gépek; a MIPS ugyanazon a gépen is más programnál más értékű; s a legfontosabb: a MIPS a teljesítménnyel fordított arányban is változhat. Erre a klasszikus példa az opcionális lebegőpontos processzorral rendelkező gép. Mivel a lebegőpontos műveletek lebegőpontos utasításonként több óraciklust igényelnek, mint a fixpontos utasítások, ezért a lebegőpontos programok a lebegőpontos szoftver-rutinok helyett az opcionális lebegőpontos hardvert használva rövidebb idő alatt futnak le, de alacsonyabb MIPS értéket érnek el. A szoftver lebegőpontos feldolgozás egyszerűbb utasításokat hajt végre, mely magasabb MIPS értéket eredményez, de annyival több utasítást kell végrehajtania, hogy a teljes
végrehajtási idő hosszabb lesz. Fajtái: 1) Eredeti (native) MIPS Erről beszéltünk korábban. 2) Csúcs (peak) MIPS Ez az alapértelmezés: a processzor hány milliót tud megcsinálni a leggyorsabb műveletéből (ilyen például a NOP), tehát nem csinál semmit. Végső soron csalás, a processzor semmilyen számítást nem végez 3) EDM MIPS, Dhrystone MIPS Speciális célú tesztprogramokat futtatunk. 4. Relatív MIPS IBM 370/158-on futó kis program futási ideje volt az első ezt sikerre a VAX 11/780-on futó program vitte, melyet 1 80-as évek végétől VUP (VAX Unit of Performance)-nak hívtak később a legelterjedtebb a PC-XT teljesítményét egységként kezelő programok, pl. a Checkit is használja, s ennél a következő eredményeket kaptam: Típus 386, 25 MHz 486, 66 MHz Pentium 133 MHz CPU 18,89 85,49 341,94 MATH 18,50 1730,29 5974,74 A második sor utolsó oszlopában lévő szám azt mutatja, hogy ennek a sebessége 1730,29-szorosa a PC-XTjének.
Nyilvánvaló, hogy ez a hatalmas (százszoros!) növekmény a beépített lebegőpontos aritmetikának köszönhető. 4.331 MFLOPS Million FLoating-point Operations Per Second Nyilvánvaló, hogy a MFLOPS sebesség függ mind a géptől, mind pedig a programtól. Mivel e mértékegység szándéka a lebegőpontos műveletek mérése, ezért ez nem alkalmazható ezen a körön kívül. Egy extrém példa: a compiler 0-közeli MFLOPS értékkel rendelkezik, akkor érdektelen, hogy az architektúra milyen gyors, mivel a compiler ritkán használ lebegőpontos műveletet. Ez a mértékegység kevésbé érintetlen, mint a MIPS. Műveleteken alapul, s nem pedig utasításokon s a célja a különféle gépek elfogulásmentes összehasonlítása. Az az eredeti elképzelés, hogy ugyanaz a program különböző gépeken futva különféle számú utasítást hajt végre ugyan, de azért ugyanolyan számú lebegőpontos műveletet végez el. Sajnálatos módon a MFLOPS az
utasítás-készlettől mégsem függetleníthető, mivel a lebegőpontos utasításkészlet a különféle gépek között nem konzisztens. Például míg a Cray-2-nek nincs lebegőpontos osztása, addig a Motorola 68882 rendelkezik osztással, négyzetgyökvonással, sinus és cosinus művelettel. A másik probléma, hogy a MFLOPS sebesség nem csupán az integer és lebegőpontos műveletek keverési arányával változik, hanem a gyors és lassú lebegőpontos műveletek arányával is. Például egy 100%-ig lebegőpontos összeadást tartalmazó program gyorsabb lesz, mint egy 100%-ig csak lebegőpontos osztást tartalmazó program. Mindkét probléma megoldása, hogy a forrásprogram tartalmazzon egy stabil számú lebegőpontos műveletet és azt osszuk el a végrehajtási idővel. A Livermore Loops benchmark szerzői a programonkénti normalizált lebegőpontos műveletek számát számítják, a forráskódban éppen megtalált műveleteknek megfelelően: Valós FP művelet
ADD, SUB, COMPARE, MULT DIVIDE, SQRT EXP, SIN,. Normalizált FP művelet 1 4 8 Például egy olyan utasítássorozat, amely tartalmaz egy ADD, egy DIVIDE és egy SIN műveletet, az 13 normalizált lebegőpontos műveletként jön számításba. Így a natív MFLOPS nem egyezik meg a normalizált MFLOPS értékkel. - Pentium/1 - Pentium processzor Lefelé 100% kompatibilitás. Szuperskalár architektúra (több utasítás végrehajtása 1 órajel ciklus alatt). Beépített lebegőpontos egység. Külön kód- és adat cache (8+8 KB) Write-Back megvalósítás. Cache kezelés a MESI protokoll szerint. 64 bit-es adatbusz. Multiprocesszor vezérlő. Két beépített utasítás pipeline (U és V) függetlenül működik. 2 integer utasítás/s Programág előrejelzés. A MOV és néhány ALU utasítás huzalozott (nem mikroprogramozott) megvalósítású. A 4KB-os lapok helyett 4MB-os lapok is választhatók. 64 bit 32 bit Kód-cache 32 bit Utasításelőrejelzés 256 bit
Prefetch Pufferek 256 bit 64 bit 64 bit-es busz interfész 64 bit 256 bit Integer egység ALU ALU 32 bit 64 bit 32 bit Regiszter készlet 32 bit 64 bit Pipeline-olt FPU 32 bit Adat-cache Hardver szorzás Hardver összeadás Hardver osztás A pentium processzor blokkvázlata Agárdi-Hadi: Pentium - Pentium/2 - Regiszterek Általános regiszterek: EAX, EBX, ECX, EDX, EBP, ESP, ESI, EDI 32 bit-esek Szegmens regiszterek: CS, DS, SS, ES, FS, GS 16 bitesek (egyszerre 6 szegmens érhető el) Állapotregiszterek: EFLAGS, EIP (32 bit-esek) Vezérlő regiszterek: CR0, CR1, CR2, CR3, CR4 (általában csak az operációs rendszer módosíthatja) Nyomkövető regiszterek: DR0 - DR7 Adat-töréspontok és utasítás-töréspontok létesíthetők a kód megváltoztatása nélkül CPU üzemmódok Valós üzemmód (8086) Az új regiszterek elérhetők (FS, GS is) Bizonyos utasítások (pl. amelyek a deszkriptorokat kezelik) kivételt idéznek elő. Védett (protected) üzemmód
Valódi védett mód 8086-os virtuális mód Reset Valós mód Reset PE=0 PE=1 Védett mód Megszakítás, kivétel Rendszer menedzselő mód Taszkváltás, IRET Virtuális 8086 mód Üzemmód állapotok közötti átmenetek - Pentium/3 - A védett üzemmód működése Az architektúra rendszerszintű lehetőségei: memóriaszervezés védelem multitaszking kivételek és megszakítások ki- és beviteli műveletek (I/O) inicializálás és üzemmód váltás lebegőpontos egység (FPU) menedzsmentje hibaelhárítás és nyomkövetés cache szervezés Memóriaszervező regiszterek Rendszer címző regiszterek 47 32 bit lineáris báziscím 16 15 0 GDTR IDTR Rendszer szegmens regiszterek TR 15 0 Szelektor LDTR Szelektor Deszkriptor regiszterek (automatikusan töltődnek) 32 bit lineáris báziscím 32 bit szegmens határ Jellemzők Memóriakezelő regiszterek A szegmentált memóriaszervezéshez szükséges adatstruktúrák
helyét 4 regiszter határozza meg. Ezek speciális utasításokkal tölthetők fel (általában csak az operációs rendszer teheti meg). Global Descriptor Table Register (GDTR) Local Descriptor Table Register (LDTR) Interrupt Descriptor Table Register (IDTR) Task register (TR) A GDT fizikai címét, és határát tartalmazza Az LDT fizikai címét, határát és attribútumokat tartalmaz. A szelektor egy GDT-beli deszkriptorra mutat. Így taszkonként lehet külön LDT-t használni. A megszakítás deszkriptor táblázat fizikai címét, és határát tartalmazza. Az éppen végrehajtott taszk báziscímét, határát és szegmens szelektorát tárolja. A szelektor egy GDT-beli taszk állapotszegmens (TSS) deszkriptorra mutat. - Pentium/4 - Védett üzemmódú memóriaszervezés Szegmentálás Sík modell. Eltörli a szegmentálást Minden szegmenst a teljes fizikai címtartományra képez le Minden deszkriptor báziscíme 0, a szegmenshatár 4GB Védett sík
modell. Ua, mint a sík modell, csak a szegmenshatár a fizikai memória méretére van beállítva Multiszegmens modell. A szegmentálás teljes körűen működik Minden program saját szegmensdeszkriptor táblázattal és szegmensekkel rendelkezik A szegmensek lehetnek kizárólagosan egy-egy programhoz rendelve, vagy megosztozhatnak rajtuk más programokkal. Szegmenshatár ellenőrzés működik Egy-egy program egyszerre 6 szegmens lát (6 szegmensregiszter). Más szegmensek a szegmensregiszterek átírása révén érhetők el Lapozás A lineáris címtartomány egy 32 bit-s címmel leírható tároló terület. Ez szimulálható valamennyi fizikai RAM-mal és diszk területtel. A diszk terület a teljes logikai címtartományt lefedi, amelynek bizonyos blokkjai jelen vannak a fizikai memóriában A memória és a diszk között fix méretű (4KB) blokkokban történik az adatcsere Ha egy logikai címre hivatkozunk, két eset lehet: a logikai cím fizikai címre
fordítható (a címet tartalmazó blokk a memóriában van). A logikai címet tartalmazó blokk nincs a fizikai memóriában, ezért kivétel keletkezik (page fault). A kivételkezelő mechanizmus lapcserét hajt végre Ezután a kivételt okozó utasítás ismételten végrehajtódik Szegmentálás és lapozás együtt Több lapot átfogó szegmensek Több szegmenst átfogó lapok Nem illeszkedő lap- és szegmenshatárok Illeszkedő lap- és szegmenshatárok Szegmensenként egy laptáblázat - Pentium/5 - Szegmensfordítás Globális Deszkriptor Táblázat Lokális Deszkriptor Táblázat TI=0 TI=1 Szegmens szelektor TI Szelektor Határ Báziscím Határ Báziscím GDTR A deszkriptor tábla kiválasztása (TI-bit) 15 Logikai cím 0 31 Szelektor 0 Offszet Deszkriptor tábla + Szegmens deszkriptor 31 0 Lineáris cím Szegmens fordítás Szegmensregiszterek LDTR - Pentium/6 - Látható rész Láthatatlan rész Szelektor
Báziscím, határ, stb. CS SS DS ES FS GS Szegmens regiszterek Minden memóriahivatkozáshoz egy szegmens regiszter van hozzárendelve. A szegmens regisztereknek van egy látható és egy láthatatlan része. A látható rész programutasításokkal feltölthető (pl MOV), a láthatatlan részt a processzor tölti fel A szegmens regiszterek látható része kétféleképpen kaphat értéket: Közvetlen betöltő utasítások: MOV, POP, LCS, LDS, LES, LSS, LGS, LFS Közvetett betöltő utasítások: CALL, JMP távoli (far) változatai. Ha a szegmensszelektor új értéket kap (látható rész), a szelektor láthatatlan része a deszkriptor táblázatból kiolvasott résszel lesz feltöltve (cache-ként működik). A deszkriptor kiemelése a táblából a címszámítás sebességét hivatott növelni. Szegmensszelektorok Összetevői: Index (13 bit) 8192 deszkriptor közül választ. Táblázat mutató (TI) Kijelöli a GDT-t vagy az LDT-t. Igényelt
privilegizálási szint (RPL) A privilegizálási védelem része. Szegmens deszkriptorok Meghatározzák a szegmensek helyét méretét - Pentium/7 - vezérlő és állapot információit A fordítóprogramok, szerkesztők, betöltők vagy az operációs rendszer állítja elő. Mezői: Báziscím A szegmens kezdete. Felbontás (granularity) Szegmenshatár egysége: byte vagy 4KB. Szegmenshatár (limit) A processzor határellenőrzésre használja. Deszkriptor típusa Lehet: rendszer-, kód- vagy adatszegmens. D/B bit Szegmenstípus Meghatározza a hozzáférés típusát, a szegmens növekedési irányát, stb. Deszkriptor privilégiumszintje (DPL) A védelmet szolgálja. Ennek értékétől függ a szegmens elérhetősége más szegmensekből (lásd később részletesebben) Szegmens jelenléte Jelzi, hogy a szegmens a memóriában van-e. Lapfordítás 31 Lineáris cím 0 Lapcímtár Laptábla Offszet
Lapcímtár Lapcímtár bejegyzés Lapkeret Laptáblázat Laptáblázat bejegyzés Fizikai cím Lapfordítás - Pentium/8 - Védelmi mechanizmusok A taszkok védelmét kell biztosítani. A védelem szegmensekre és lapokra is alkalmazható. Szegmens szintű védelem Minden memóriahivatkozáskor elvégzi a processzor: 1. Szegmens típus 2. Határ (limit) 3. A privilégiumokat érintő megszorítások 4. Az eljárások bemenőpontjait érintő megszorítások 5. Az utasításkészletet érintő megszorítások ellenőrzését. Az ellenőrzés a címfordítással párhuzamosan történik. Bármely szabálytalanság kivételt eredményez. Az ellenőrzés a deszkriptor adatai alapján történik. 1. Szegmens típus ellenőrzés A szegmens típusai: Felhasználói kódszegmens (Olvasható-e?) Felhasználói adatszegmens (Írható/olvasható?) Rendszerszegmens (taszkok, kivételek és megszakítások szervezésére) Kapudeszkriptorok Bizonyos szegmensregiszterek
csak meghatározott deszkriptorokra mutathatnak! 2. Határ (limit) ellenőrzés A hivatkozott cím benne van-e a megadott tartományban? 3. A privilégiumokat érintő megszorítások A processzor 4 privilégium szinttel dolgozik. (0 - 3) A 0-szint jelenti a legprivilegizáltabb szintet! A szintek: 0 Operációs rendszer 1 Perifériakezelő programok 2 Eszközmeghajtók 3 Felhasználói programok Egy program csak a saját privilégium szintjén lévő programokat hívhat! Egy program csak a saját vagy annál alacsonyabb privilégium szinten (nagyob szintszám!) levő adatokat érhet el! - Pentium/9 - A szintek megléte, a hívások és adathivatkozások korlátozása a szintek között a programok és adatok védelmét hivatott biztosítani. Legkevésbé privilegizált szint 3 2 Legprivilegizáltabb szint Adatok Programok Legális elérés Illegális elérés 1 0 Kernel Alkalmazói szint Privilegizálási szintek Privilegizálási szintek a következő adatstruktúrákban
jelennek meg: Aktuális szint (Current Privilege Level = CPL) A CS regiszter alsó 2 bit-je jelöli. Deszkriptor Privilégium szintje (DPL) A deszkriptorban van elhelyezve. A szükséges privilégium szint (RPL) A szegmensszelektor alsó 2 bit-je. Az adathozzáférések korlátozása A hozzáférés engedélyezésének kiértékelésében részt vesz: a CPL, a kijelölt adatszegmens regiszter RPL-je és az adatszegmens deszkriptorának DPL-je Hozzáférés engedélyezve, ha DPL >= Max(CPL, RPL) (pl. CPL= 1, RPL=1, DPL=3 esetben az adatszegmens elérhető) Vezérlésátadások korlátozása - Pentium/10 - Vezérlésátadás: JMP, CALL, RET, INT, IRET utasításokkal vagy kivétel és megszakítás előfordulásakor lehetséges. A JMP és a CALL "far" (távoli) változatai másik kódszegmensre vonatkoznak. Két eset lehetséges: a) Az operandus egy másik végrehajtható szegmens deszkriptorát választja ki. b) Az operandus egy call-kapu
deszkriptorát választja ki (lásd a következő bekezdést a kapudeszkriptorokról) a) eset A vezérlésátadás engedélyezésének kiértékelésében részt vesz: a CPL, a cél-kódszegmens deszkriptorának DPL-je Vezérlésátadás engedélyezve, ha DPL = CPL Gyakran szükség lehet vezérlésátadásra magasabb privilegizálási szintre. Pl egy felhasználói program az operációs rendszer valamely szolgáltatását kívánja igénybe venni. Ez normál kódszegmensre közvetlenül nem lehetséges, csak az ún. kapudeszkriptorok segítségével Kapudeszkriptorok Eltérő privilegizálási szintek közötti vezérlésátadásra használhatók. A kapudeszkriptor szerkezete eltér a többi deszkriptorétól 3 2 1 0 Kapun keresztüli hívások Kapuk Programok Legális elérés Illegális elérés - Pentium/11 - Négy féle kapudeszkriptor létezik: Call kapu Trap kapu Megszakítás kapu Taszk kapu A Call kapu funkciói: Megjelöli egy eljárás
belépési pontját Meghatározza az eljárás hívásához szükséges privilegizálási szinteket A CALL vagy JMP utasítás végrehajtásakor a processzor felismeri, hogy a célszegmens egy kapudeszkriptorra mutat. A call kapu a GDT-ben és az LDT-ben is előfordulhat, de az IDTben nem A kapu-ban lévő szelektor egy kódszegmens deszkriptorát jelöli ki. A kódszegmens deszkriptorának bázisa és a kapu deszkriptor ofszetje együtt a kódszegmens egy eljárásának belépési pontját határozzák meg. Az utasításban lévő logikai cím nincs felhasználva Szelektor Szegmensen belüli ofszet (nem használt) Cél cím Deszkriptor táblázat Ofszet + Szelektor Bázis DPL Számláló DPL Kapu deszkriptor Kódszegmens deszkriptor Eljárás belépési pontja A call kapu működési mechanizmusa A call kapun keresztüli vezérlésátadás engedélyezésének kiértékelésében részt vesz: a CPL, a szegmens szelektor RPL-je, a kapu deszkriptor DPL-je,
a cél-kódszegmens deszkriptorának DPL-je Vezérlésátadás engedélyezve, ha JMP utasítás CALL utasítás Max(CPL, RPL) <= kapu DPL-je, és Cél kódszegmens DPL-je = CPL Max(CPL, RPL) <= kapu DPL-je, és Cél kódszegmens DPL-je <= CPL - Pentium/12 - Veremváltás Egy privilegizáltabb szintre történő eljárás híváskor az alábbiak játszódnak le: a CPL megváltozik, a vezérlés átadódik, a hívott eljárás számára új verem jön létre, amelybe bemásolódik a hívó program verméből a kapudeszkriptor "számláló" mezőjével megadott számú duplaszó. Az új veremre azért van szükség, hogy a hívott (privilegizáltabb) eljárás számára biztosan elegendő hely álljon rendelkezésre. Visszatéréskor a verem tartalma visszamásolódik a régi verembe. Minden futó taszk rendelkezik egy taszk állapot szegmenssel (Task State Segment = TSS), amelyet a TTS deszkriptora jelöl ki a memóriában. A TSS tartalmát az
alábbi ábra mutatja 31 16 15 0 0 0 0 I/O bittérkép TSS határ 0 Back link ESP 0 SS0 ESP 1 SS1 ESP 2 SS2 CR3 EIP EFLAG-ek EAX ECX EDX EBX ESP EBP ESI EDI 0 ES 0 CS 0 SS 0 DS 0 FS 0 GS 0 LDTR T 0 Rendszerfüggő Cím offszet 0 4 8 12 16 . . . Taszk állapotszegmens A TTS-t a taszkok közötti váltáskor használja fel az operációs rendszer a félbe hagyott taszk állapotának elmentésére, ill. a folytatott taszk állapotának visszaállítására - Pentium/13 - Az éppen futó taszk állapot szegmensét a TR processzor-regiszter jelöli ki. Egy privilegizáltabb szintre történő eljárás híváskor az új veremszegmens kijelölésekor szintén a TSS játszik szerepet, ugyanis az ebben megadott ESPx és SSx értékek adják meg az adott privilégiumszinthez tartozó veremszegmenseket. Minden privilégiumszinthez külön veremszegmens tartozik. A 3. privilégiumszinthez nincs veremmutató a TSS-ben, mivel egy 3 szintbeli eljárást nem hívhat meg egy kevésbé
privilegizált program (ugyanis ilyen nem létezik). A taszkok közötti váltást később mutatjuk be. Az operációs rendszer számára lefoglalt utasítások A védelmi mechanizmust vagy a processzor teljesítményét érintő utasításokat csak megbízható eljárások használhatják. Ezek csoportjai: Privilegizált utasítások, amelyeket a rendszer vezérlésére használnak Érzékeny (sensitive) utasítások az I/O-val kapcsolatosak A privilegizált utasítások csak a CPL=0 szinten hajthatók végre. Az I/O-val kapcsolatos, ún. érzékeny utasításokat is védelem alatt kell használni, de 0-tól eltérő privilegizálási szinten is végre kell tudni hajtani Lapszintű védelem A védelem lapokra is vonatkozik. Minden memóriahivatkozáskor a processzor megvizsgálja, hogy eleget tesz-e a védelmi feltételeknek. A védelem megsértése kivételt eredményez. A lapszintű ellenőrzések: A címezhető tartományt érintő ellenőrzések
Típusellenőrzés A lapszintű védelem által használt paramétereket a laptáblázatok tárolják: A címezhető tartományt érintő ellenőrzések Két privilegizálási szint van: Felügyelő szint (U/S=0) (operációs rendszer, eszközmeghajtók, kezelőprogramok) Felhasználói szint (U/S=1) (alkalmazások) A szegmentálásnál használt privilegizálási szintek a lapozásnál használt privilegizálási szinteknek vannak megfeleltetve: CPL = 0, 1, 2 megfelel a felügyelő szintnek. CPL = 3 megfelel a felhasználói szintnek. - Pentium/14 - Típusellenőrzés Kétféle típusú lap van: Csak olvasható (R/W = 0) Írható/olvasható (R/W = 1) A szegmens- és lapvédelem együtt is használható. A védelem bármilyen megsértése kivételt generál. Multitaszking A processzor hardveresen támogatja a többtaszkos működést. A taszk vagy éppen fut, vagy arra vár, hogy fusson. Egy taszkot egy megszakítás, egy kivétel, egy ugrás vagy egy call
utasítás hív meg. Két különböző taszkokra vonatkozó deszkriptor létezik a deszkriptortáblázatban: Taszk állapotszegmens deszkriptor (TSS deszkriptor) Taszk kapu A taszkkapcsolás olyan, mint egy eljáráshívás, csak több processzor-állapotinformáció lesz eltárolva. A futó taszk teljes állapota elmentődik, és az új taszk korábban elmentett állapotinformációi lesznek visszatöltve. Taszkkapcsoláskor nem kerül semmi a verembe A taszkok nem újraindíthatók (nem reentráns) A multitaszkot támogató adatstruktúrák: taszk állapotszegmens (TSS) taszk állapotszegmens deszkriptor taszkregiszter (TR) taszk kapudeszkriptor A taszk állapotszegmens (TSS) tartalma az előző ábrán látható. Taszkkapcsolás A processzor a következő esetekben adja át a vezérlést egy másik taszknak: JMP vagy CALL utasítás egy TSS deszkriptorra JMP vagy CALL utasítás egy taszk kapura Megszakítás vagy kivétel keletkezik, amely az
IDT-ben lévő taszk kapura mutat IRET utasítás végrehajtása (miközben az NT flag magas) Lehetőség van taszkok visszafelé láncolására (linking). Ez esetben egy taszk visszaadhatja a vezérlést az őt hívó taszknak. További taszkszervező lehetőségek: A megszakítások és kivételek kezelése taszkkapcsolással. Minden taszk kapcsoláskor lehetőség van új LDT-re váltani. Ez egy további védelmi lehetőség, ugyanis ezzel a módszerrel lehet meggátolni, hogy az azonos privilégium szinten - Pentium/15 - lévő programok egymást megzavarják. Az alábbi ábra azt az esetet mutatja, amikor csak a GDT-használjuk, LDT-t nem. A 3 szinten futó programok elérhetik egymás adatterületét A rákövetkező ábra a taszkonként külön-külön LDT-vel bíró megoldást mutatja, ahol a 3. szinten futó programok nem zavarhatják egymást, hiszen nem láthatják egymás LDT-jét. 0 DPL = 0 Program 1 DPL = 0 X taszk 2 DPL = 0 X címterület Adat
X taszk . . . 100 DPL = 3 101 DPL = 3 Program 102 DPL = 3 Y taszk 103 DPL = 3 . . . Adat Y címterület Y taszk Operációs rendszer GDT használatával Y címterület X címterület DPL = 3 DPL = 3 X kód Y kód DPL = 3 DPL = 3 Y adat X adat LDT X DPL = 0 LDT Y DPL = 0 DPL = 0 DPL = 0 GDT Operációs rendszer GDT és LDT használatával - Pentium/16 - Az utasítások felépítése Opkód ModR/M SIB Offszet Adat 1,2 0,1 0,1 0,1,2,4 0,1,2,4 Hossz: Prefixek: Hossz: Utasítás prefix Cím méret prefix Operandus méret prefix Szegmens felülíró prefix 0,1 0,1 0,1 0,1 Utasítás formátum 7 6 5 Mod 4 3 2 Reg/Opkód 1 0 R/M ModR/M byte 7 6 SS 5 4 3 2 INDEX 1 Bázis SIB (Skála Index Bázis) byte ModR/M és SIB byte-ok formátuma 0 byte byte - Pentium/17 - A ModR/M és SIB byte-ok meghatározzák az indexelés típusát vagy regiszterszámot, a felhasználandó regisztert vagy az utasítás
kiválasztásához szükséges többletinformációt, a bázis, index és skálával kapcsolatos információt ModR/M byte Mod: 8 regisztert és 24 indexelési módot határoz meg (az R/M-mel kiegészítve) Reg: Regisztert jelöl, vagy az op. kódot egészíti ki R/M: Regisztert, vagy címzési módot jelöl SIB byte (Skála + Index + Bázis) A SIB byte jelenlétét a ModR/M mező egyes kódjai jelzik. SS: skálatényezőt jelöl (az index regiszter 0, 2, 4 vagy 8-al való szorzása) Index: Indexregisztert választ (EAX, EXC, EDX, EBX, -, EBP, ESI, EDI) Bázis: A bázisregiszter választ Prefixek 1. 2. 3. 4. Utasításprefixek: REP, REPE/REPZ, REPNE/REPNZ, LOCK Szegmensfelülíró prefixek: CS, SS, DS, ES, FS, GS Operandusméret felülíró prefix Címméret felülíró prefix Mindegyik csoportból csak 1 szerepelhet! A prefixek sorrendje közömbös. - Pentium/18 - A regiszterkészlet Általános regiszterek 31 16 15 8 7 16 bit 32 bit 0 AH AL AX EAX DH DL DX
EDX CH CL CX ECX BH BL BX EBX BP EBP SI ESI DI EDI SP ESP Szegmensregiszterek CS SS DS ES FS GS Státusz és vezérlő sregiszterek EFLAGS EIP Az alkalmazások számára elérhető regiszterkészlet - Pentium/19 - I/O műveletek Az I/O műveletek a portokon keresztül valósulnak meg. A portok a perifériavezérlőkben lévő regiszterek. Az I/O portok lehetnek: beviteli, kiviteli és kétirányú portok. A portokat adatátvitelre vagy vezérlésre használják. Egy-egy perifériavezérlő általában mindkét fajta porttal rendelkezik. A portok használatának módját az architektúra határozza meg. A portok címzése A processzor az I/O portok kezelését az alábbi módszerekkel teszi lehetővé: 1. Önálló I/O címtartomány használatával A portokhoz I/O processzor-utasításokkal lehet hozzáférni 2. Memóriára leképzett (memory mapped) I/O segítségével A portok memória címként jelennek meg. A processzor mindkét megoldást
lehetővé teszi. Az önálló címtartományt speciális utasítások és hardver védelmi mechanizmus támogatja. A memóriára leképzett I/O memóriakezelő utasításokkal használható, a védelmet a szegmentálás és a lapvédelem biztosítja. A kétféle működés között a rendszer tervezői választanak. A processzor egyetlen kivezetésének (M/IO#) állapota dönti el, hogy egy elindított buszciklus memória, vagy I/O címtartományra vonatkozik. Önálló I/O címtartomány A port címe megadható: byte konstanssal 8, 16 és 32 bit-es portok jelölhetők ki a 0 - 255 címtartományban DX regiszterrel 8, 16 és 32 bit-es portok jelölhetők ki a 0 - 65535 címtartományban Az IN, OUT utasítások adatokat visznek át a port és egy regiszter között. Az INS, OUTS utasítások adatfűzéreket mozgatnak a memória és az I/O címtartomány között. Memóriára leképzett (memory mapped) I/O címtartomány A portok memóriakezelő utasításokkal (pl. MOV)
érhetők el - Pentium/20 - A perifériák vezérlő- és állapotregiszterei az AND, OR, TEST utasításokkal manipulálhatók. A portok elérésére a processzor összes címzési módja felhasználható, ténylegesen úgy kezelhetők, mintha fizikai memóriában lennének. Az adatok cache-elését a portok címtartományára tiltani kell! A védett üzemmódú I/O műveletek A processzor védett üzemmódjában az I/O is védelem alatt áll. Az I/O utasítások védelme: Az EFLAGS regiszter IOPL mezője ellenőrzi az I/O utasítások végrehajtásának engedélyezését vagy tiltását. A TSS szegmens I/O engedélyező bit-térképe ellenőrzi az egyes taszkok számára az egyes portokhoz való hozzáférést. A memóriára leképzett I/O portok védelme: Szegmens és/vagy Lapvédelemmel Az I/O privilégium szintek Az IN, OUT, INS, OUTS, CLI, STI utasítások csak akkor hajthatók végre, ha CPL <= IOPL. Ezzel az I/O műveletek kiadása 0-ás vagy 1-es
privilégium szinthez köthető, vagyis input/output csak az operációs rendszeren keresztül végezhető. Virtuális 8086-os üzemmódban az I/O bittérkép tovább korlátozza az I/O portok elérését. Az EFLAGS regiszter IOPL mezője és az I(nterrupt) flag is csak 0-s privilégiummal változtathatók meg. Az Intel 8086 processzor címsín cím AU + fizikai cím IP puffer +1 buszvezérlõ + adat puffer adatsín 6 Byte regtár ALU BU FLAGS EU mP EC IU dekódoló IR 3 utasítás BU = Bus Unit (Busz vezérlõ egység) IU = Instruction Unit (Utasítás dekódoló egység) EU = Execution Unit (Utasítás végrehajtó egység) AU = Address Unit (Cím kiszámító egység) I8086/80286-os processzor felépítése Az I8086/I80286 processzor részegységei Bus Unit Instruction Unit Execution Unit Address Unit Busz vezérlő egység: Processzor - memória és Processzor - I/O kapcsolat megteremtése Szabad busz ciklus alatt előkészíti a következő
utasítást. Utasítás előkészítő egység Az előkészített utasítást dekódolja ( 3 utasítást dekódol és sorbaállít). Végrehajtó egység A dekódolt utasításban előírt műveletet hajtja végre az (Execution Control) műveleti vezérlő irányítása alatt. Az IR-ben tárolt műveleti kód alapján elindítja a ROM-ban tárolt mikroprogramot. Címkiszámító egység Operandus címeket állít elő a BU számára. Az utasítás végrehajtás lépései 1. Utasítás előkészítés, lehívás (fetch): (IP) -> IR 2. Utasításszmláló regiszter tartalmának növelése: IP + 1 -> IP 3. Műveleti kód (Opcode) értelmezése, dekódolása és az operandus címének meghatározása 4. A művelethez szükséges adatok előkészítése 5. Végrehajtás (execution): a kijelölt művelet végrehajtása Vezérlésátadás esetén: új cím -> IP 6. Eredmény elhelyezése -2- Általános regiszterek 8 8 16 16 16 AX : Akkumulátor regiszter IP: utasítás
számláló (Instruction pointer) BX: Bázis regiszter FLAGS: Jelzõ és vezérlõ biteket tartalmazó regiszter CX: Számláló regiszter DX: Adat regiszter MSW: Gépi állapot szó (Machine status word) SI: Forrás index regiszter DI: Cél index regiszter SP: Verem (stack) mutató CS: Kód szegmens regiszter BP: Bázis mutató DS: Adat szegmens regiszter SS: Verem(stack) szegmens regiszter ES: Extra szegmens regiszter -3- -4- Utasítás formák (I8086, I80286) Utasítások hossza: 1-9 Byte Címek száma: 1 vagy 2 (az egyik cím mindig regisztert címez) Utasítások szerkezete Prefix Opcode Mode Offset Data 0-1 0-2 0-2 0-1 0-2 0-2 I 8086 processzor 0-3 1 I 80286 processzor 0-3 1 6 1 1 2 3 3 Opcode D W MOD REG R/M D = 0 az eredmény byte helye a MOD/RM által meghatározott D = 1 az eredmény helye a regiszter W = 0 az operandus 1 byte-os W = 1 az operandus 2 byte-os -5- A MODE byte tartalma REG 16 bites W=1 8 bites W=0 000 AX AL
001 CX CL 010 DX DL 011 BX BL 100 SP AH 101 BP CH 110 SI DH 111 DI BH -6- Címzési módok Indexelt bázis címzés (eltolással vagy anélkül) W=0 W=1 MOD R/M 00 01 10 11 000 m[BX+SI] m[BX+SI+d8] m[BX+SI+d16] AX vagy AL 001 m[BX+DI] m[BX+DI+d8] m[BX+DI+d16] CX vagy CL 010 m[BP+SI] m[BP+SI+d8] m[BP+SI+d16] DX vagy DL 011 m[BP+DI] m[BP+DI+d8] m[BP+DI+d16] BX vagy BL 100 m[SI] m[SI+d8] m[SI+d16] SP vagy AH 101 m[DI] m[DI+d8] m[DI+d16] BP vagy CH 110 direkt címzés m[BP+d8] m[BP+d16] SI vagy DH 111 m[BX] m[BX+d8] m[BX+d16] DI vagy BH Közvetlen címzés Közvetett regiszter címzés Regiszter címzés Közvetlen indexelt címzés Relatív báziscímzés -7- Memória fizikai címének kiszámítása valós mûködési módban Tároló Szegmens regiszter CS Szegmens kezdet cím 16 bit Relatív cím 0000 4 bit Relatív cím 20 bit Szegmens kezdet 20 bit Fizikai cím Az utasítások csoportosítása
Aritmetikai és logikai uatasítások: Fixpontos +,-,(*,/) Lebegőpontos +,-,(*,/) Ősszehasonlítás Léptetés, forgatás Logikai műveletek Bit vizsgálat (I80386) Bit beállítás (I80386) ADD, ADC, SUB, INC, DEC, MUL, IMUL, DIV, IDIV CMP SHL, SHR, SAR, ROR, ROL, RCR, RCL AND, OR, XOR, NOT, NEG BSF, BSR BT, BTS, BTR, BTC -8- IDIV előjeles Léptetõ és forgató utasítások C 0 Léptetés balra SHL C 0 Logikai léptetés jobbra SHR C Aritmetikai léptetés jobbra SAR RCR C Jobbra forgatás ROR C Balra forgatás ROL RCL Adatátviteli uatasítások: Töltő (Load) Tároló (Store) Mozgató Reg <- Mem/Reg Reg -> Mem Mem -> Mem MOV MOV MOVS MOV op1, op2 XCHG op1, op2 PUSH regiszter tartalma -> Verem POP regiszter tartalma <- Verem LDS Mem -> regiszter, szegmens regiszter LES -“- LEA Mem offset -> Reg LDS DI, 32 POINTER a memóriában lévő címet tölti be LEA BX, TABLE LEA BX, TABLE[SI] (indexelt) -9- Verem (stack) kezelés SP mindig
az utolsó felhasznált byte-ra mutat PUSH AX: SP <-- SP - 2 SP (SP) <-- AX AH AL POP AX: AX <-- (SP) SP <-- SP+ 2 SS a verem teteje 1. 0. SS = Stack szegmens regiszter String kezelő utasítások MOVS CMPS STOS SCAS LODS [DS:SI] -> [ES:DI], DI++, SI++ [DS:SI] CMP [ES:DI], DI++, SI++ [ES:DI] <- AL (AX), DI++ AL (AX) CPM [ES:DI], DI++ AL (AX) <- [DS:SI], SI++ A fenti string kezelő utasítások közül a MOVS, STOS és a LODS a REP (ismétlés) prefix-el is használható és jelentése: - 10 - While CX<>0 string művelet CX CX -1 End While REP, REPE, REPZ: While CX<>0 string művelet CX CX -1 If ZF = 0 ciklus befejezése End While (REPNE, REPNZ: If ZF<>0 ciklus bef.) Beviteli/Kiviteli utasítások IN AL/AX, cím OUT cím, AL/AX INS, OUTS 8 vagy 16 bites I/O blokkos átvitel (80386) Vezérlés átadó utasítások Eljárás hívó (Subroutin) utasítások CALL, RET, RET n Ugró utasítások: feltételes és feltétel
nélküli (JMP) Előjelet figyelembe veszi = JE <> JNE > JG >= JGE < JL <= JLE Előjelet nem veszi figyelembe JE JNE JA JAE JB JBE - 11 - Egyéb ugró utasítások: JNO, JPO JNP, JP JPE, JPO JS, JNS JZ, JNZ JC, JNC JCXZ LOOP Overflow Parity Even, Odd parity Sign Zero Carry ugrik, ha CX =0 ugrik, ha CX <>0 Az offset 1 byte (az ugrás távolsága -128 --- +127) Speciális utasítások: NOP No operation HLT Stop STI Set Interrupt (megszakítás engedélyezve) CLI Clear Interrupt (megszakítás nincs engedélyezve) WAIT várakozó állapot, amíg külső megszakítás nem érkezik (koproc.) Feltételes ugrások összefoglalása Mnemonik Jelentés Ellenőrzött Flag-ek JB/JNAE Jump if below CF = 1 Jump if not above or equal to JAE/JNB Jump if above or equal to CF = 0 Jump if not below JBE/JNA Jump if below or equal to CF = 1 or ZF = 1 Jump if not above JA/JNBE Jump if above CF = 0 and ZF = 0 Jump if not below or equal to JE/JZ Jump if equal
to ZF = 1 JNE/JNZ Jump if not equal to ZF = 0 JL/JNGE Jump if less than SF # OF Jump if not greater than or equal to JGE/JNL Jump if greater than or equal to Jump if not less than - 12 - SF = OF JLE/JNG Jump if less than or equal to ZF = 1 or SF # OF Jump if not greater than JG/JNLE Jump if greater than ZF = 0 or SF = OF Jump if not less than or equal to JP/JPE Jump if parity PF = 1 Jump if parity even JNP/JPO Jump if no parity PF = 0 Jump if parity odd JS Jump if sign SF = 1 JNS Jump if not sign SF = 0 JC Jump if carry CF = 1 JNC Jump if not carry CF = 0 JO Jump if overflow OF = 1 JNO Jump if not overflow OF = 0 - 13 - Az assembly program elkészítésének lépései 1. Forrásprogram (ASM) elkészítése szövegszerkesztővel 2.Tárgykód (OBJ) generálása az assembler fordítóprogrammal (TASM) 3. Futtatható program (EXE) létrehozása tárgykód szerkesztővel (TLINK) 4. Tesztelés (Turbo Debugger) TASM .ASM .OBJ EXE TLINK
Szoftver és hardver kapcsolat Alkalmazói program DOS hívás Int 21 és más interrupt-on keresztül DOS BIOS funkciók hívása interrupt-on keresztül BIOS IBM PC hardver: Display adapter, billentyûzet, nyomtató, diszk - 14 - Hardver működtetése I/O portokon és memórián keresztül
 When reading, most of us just let a story wash over us, getting lost in the world of the book rather than paying attention to the individual elements of the plot or writing. However, in English class, our teachers ask us to look at the mechanics of the writing.
When reading, most of us just let a story wash over us, getting lost in the world of the book rather than paying attention to the individual elements of the plot or writing. However, in English class, our teachers ask us to look at the mechanics of the writing.