Comments
No comments yet. You can be the first!
Most popular documents in this category





Content extract
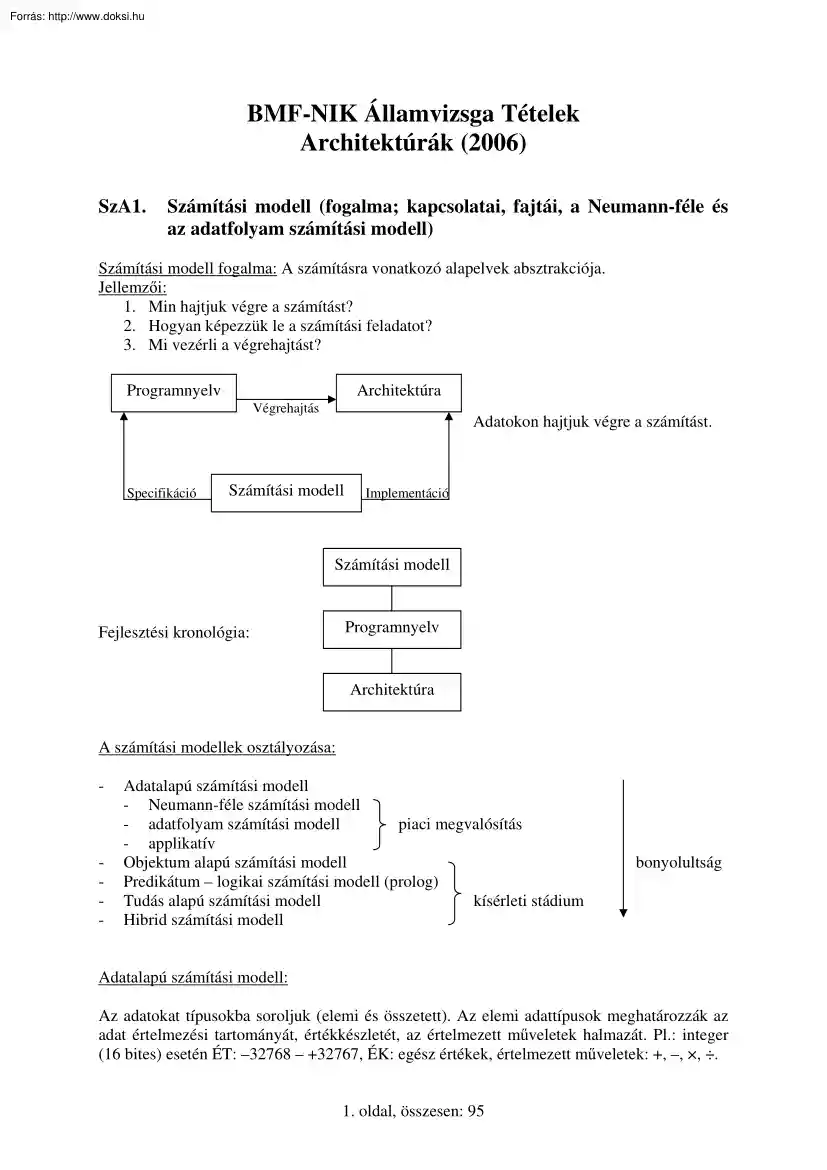
BMF-NIK Államvizsga Tételek Architektúrák (2006) SzA1. Számítási modell (fogalma; kapcsolatai, fajtái, a Neumann-féle és az adatfolyam számítási modell) Számítási modell fogalma: A számításra vonatkozó alapelvek absztrakciója. Jellemzői: 1. Min hajtjuk végre a számítást? 2. Hogyan képezzük le a számítási feladatot? 3. Mi vezérli a végrehajtást? Programnyelv Architektúra Végrehajtás Specifikáció Adatokon hajtjuk végre a számítást. Számítási modell Implementáció Számítási modell Fejlesztési kronológia: Programnyelv Architektúra A számítási modellek osztályozása: - - Adatalapú számítási modell - Neumann-féle számítási modell - adatfolyam számítási modell piaci megvalósítás - applikatív Objektum alapú számítási modell Predikátum – logikai számítási modell (prolog) Tudás alapú számítási modell kísérleti stádium Hibrid számítási modell bonyolultság Adatalapú számítási modell:
Az adatokat típusokba soroljuk (elemi és összetett). Az elemi adattípusok meghatározzák az adat értelmezési tartományát, értékkészletét, az értelmezett műveletek halmazát. Pl: integer (16 bites) esetén ÉT: –32768 – +32767, ÉK: egész értékek, értelmezett műveletek: +, –, ×, ÷. 1. oldal, összesen: 95 Neumann-féle számítási modell: 1. Min hajtjuk végre a számítást: - Adatokon. - Az adatokat a változók képviselik. Deklarált változók - Az architektúra biztosítja, hogy a változók korlátlan számban változtathassák értékeiket. 2. Hogyan képezzük le a számítási feladatot: - Adatmanipuláló utasítások sorozatával. Deklarált változó Adatmanipuláló programutasítás adatmanipuláció 3. Mi vezérli a végrehajtást: - Az adatmanipuláló utasítások implicit szekvenciája - Az explicit vezérlést átadó utasítás. Vezérlés-átadás Utasítások PC Nem számolja, csak egyesével tudja növelni magát. Az adat
elejét tudja értelmezni move utasításként Programnyelvek: Imperatív (parancs) nyelvek, pl.: Pascal, C, Basic, Fortran Architektúra: Neumann-féle architektúra. Adatfolyam számítási modell: 1. Min hajtjuk végre a számítást: Adatokon 2. Hogyan képezzük le a számítási feladatot: - A bemenő adatok halmazának értelmezésével és, - Adatfolyam gráffal: a) Csomópontok: műveletvégzők. b) Élek: input/output lehetőségek, ahol az adat áramlik. 2. oldal, összesen: 95 Pl.: Z=(X+Y)×(X–Y) X Y + – × bemenő adatok halmaza - párhuzamos műveletvégzés időmegtakarítást eredményez (33%) a Neumann-féle szekvenciálisan dolgozott Z 3. Mi vezérli a végrehajtást: Adat Stréber modell: 1. Még nincs operandus 2. Az egyik operandus megjelent 3. Összes operandus megérkezése Műveletvégzés 4. Megjelenik az eredmény Az utolsó operandus megjelenése indítja el a műveletet. Lehet akárhány operandus, akár több száz is. Programnyelv: Sisal.
Architektúra: The Manchester Dataflow Machine Neumann-féle számítási modell 1. Közös memória (adat + program) 1. Változó 2. Adatmanipuláló utasításokkal 3. Implicit szekvencia 3. Explicit vezérlésátadás @ Adatfolyam számítási modell Műveletvégzőben „tárolhatóak” az adatok Egyszeri értékadás (a bejött adat elveszik) Adatfolyam gráffal Adatvezérelt Nincs PC, nincs vezérlési szekvencia A Pentium processzorokban a CISC magban van adatfolyam. SzA2. Az adattér (fogalma; a memória-tér; a regisztertér és fejlődése: egyszerű, adattípusonként különböző, többszörös regisztertér) A processzor által manipulálható tér. Adattér Memóriatér Regisztertér Nagyobb Lassúbb Olcsóbb Processzoron kívül (külön lapkán) Közös az I/O térrel Kisebb Gyorsabb Drágább Processzoron belül Mindig önálló Memóriatér: - A legfontosabb jellemzője a tárolási kapacitása. Címtér: a) Modell címtere: címsín szélessége
határozza meg b) Implementáció címtere: pénztárca 3. oldal, összesen: 95 - A valós memóriatér fejlődése: a) 40-es évek: néhány száz szó. b) 1950 IAS: 10 bites címsín, 210=1024 szó. c) 1964 IBM 360: 16 Mbyte. - Virtuális tár a) 1960-ban jelent meg az ötlete s az IBM 370-es gépcsalád vitte sikerre. b) Alap jellemzői: 1. kétféle címet értelmezünk: a. valós cím (ezt látja a processzor) b. virtuális cím (programozó) Virtuális tér Nagyobb Lassúbb Háttértárolón helyezkedik el Programozó látja Várakozik a program Valós címtér Kisebb Gyorsabb Alaplaphoz illesztve, félvezető lapkán Processzor látja Itt fut a program 2. Létezik egy olyan, a programozó számára transzparens mechanizmus, mely: a. Az éppen futó program számára szükséges program- és adatrészeket behozza a virtuális tárból a valós tárba, illetve b. Az éppen futó program számára nem szükséges program- és adatrészeket kiviszi a valós tárból a
virtuális tárba. 3. Létezik egy olyan, a felhasználó számára transzparens mechanizmus, mely a programozó által használt virtuális címeket a végrehajtási (execution) fázisban lefordítja valós címekké. transzparens 2. pont Valós címek Virtuális címek mechanizmus 3. pont Az Intel processzorok valós és virtuális memóriájának fejlődése: Típus Megjelenés Valós memória Virtuális memória éve (Mbyte) 8086 1978 1 20 bit 80286 1982 16 1 Gbyte 24 bit 80386 1985 4096 64 Tbyte 32 bit Regisztertér: Osztályozása: - egyszerű - adattípusonként különböző - többszörös 4. oldal, összesen: 95 Egyszerű regisztertér: Egyszerű regisztertér 40-es évek 50-es évek 60-as évek egyetlen akkumulátor egyetlen akkumulátor általános célú regisz+ dedikált regiszter terkészlet Verem regiszterek + - Egyetlen akkumulátor Hátránya: 1. Szűk keresztmetszet 2. Két eredmény esetén csak az egyiket tudta tárolni (pl: osztásnál a hányados
és a maradék) - Egyetlen akkumulátor + dedikált regiszter Előnye: A hányados regiszter bevezetése felgyorsította az osztást. Hátránya: Igen drágán valósították meg, mégis gyakran kihasználatlan volt. - Általános célú regiszterkészlet Előnye: 1. Minden regiszter kihasználtsága javul 2. Új programozói stílus: a regiszter operandusú műveletek számának maximalizálása. - Verem regiszterek Hátránya: Szűk keresztmetszet, mivel csak a verem tetejét látjuk. Előnye: Gyors. Adattípusonként különböző regiszterkészlet: Megjelenésének oka a lebegőpontos feldolgozás gyorsítása. karakterisztika (8) mantissza előjele (1) mantissza (23) 1964 IBM 360 Általános célú regiszterkészlet, feladata: fixpontos, karakteres, logikai feldolgozás. Lebegőpontos regiszterkészlet, feladata: lebegőpontos műveleti feldolgozás. 5. oldal, összesen: 95 1998 Pentium III általános célú regiszterkészlet Megjelenés éve: 1964 1985 1990 1998
MMX2 (Katmai) Egy utasítással több műveletvégzést ér el. A vektorgrafikánál fontos 12 bites, 3D filmeket ez tette lehetővé. lebegőpontos regiszterkészlet Típus IBM 360 Intel 80386 IBM RISC 6000 Pentium III Általános célú regiszterkészlet 16x32 8x32 32x32 8x32 Lebegőpontos regiszterkészlet 4x64 8x80 32x64 8x80 Katmai (MMX2) 8x128 Többszörös regiszterkészlet: Háttérismeretek: - kontextus: a) regiszterek aktuális értékei b) az állapottér (flag, PC) - Megszakításkor a futó program kontextusát le kell menteni annak érdekében, hogy a megszakítás feldolgozása után azt visszatöltve a program futása folytatódhasson. - Többfeladatos és többfelhasználós környezetben igen sok megszakítás lép fel. A kontextus memóriába való mentése lassú gyorsítás többszörös regiszterkészlet révén Fajtái: 1. Több, egymástól független regiszterkészlet, pl: 1964 – Sigma7 - Paraméterátadásos eljáráshívásoknál a paraméterátadás
csak memórián keresztül történhet, így nem gyorsít. - Ideális egymástól független megszakításoknál, pl.: I/O megszakítások 6. oldal, összesen: 95 INS regiszterek száma 2. Átfedő regiszterkészlet, pl: 1980 RISC I - A hívóeljárás OUTS része fizikailag megegyezik a meghívott eljárás INS részével nincs paraméterátadás - Regiszterek száma merev viszonylag üres regiszterkészlet esetén is előfordulhat túlcsordulás. - A túlcsordult paraméterek mentése a memórián keresztül történik lassú. - Konkrét regiszter számok: (ins/locals/outs) RISC I: 6/10/6 SPARC: 8/8/8 Locals OUTS INS Locals OUTS INS Locals OUTS regiszterkészletek száma - Regiszterkészletek száma: túlcsordulás (%) 2 - 4 A mérési eredmények azt mutatták, hogy 8 db regiszterkészlet esetén már csak 2% körüli a túlcsordulás. 6 8 regiszterkészletek száma A programozás módszertana sem ajánl nyolcnál több egymásba ágyazott eljárást, mivel az
ennél több már nehezen tekinthető át. 3. Stack-cache, pl: 1982 C-Machine - a stack verem szervezését és - a regiszterek közvetlen címzési lehetőségét egyesíti. Működése: itt is van átfedő rész az INS és OUTS-nál - A compiler minden eljáráshoz hozzárendel egy változó hosszúságú aktiválási rekordot (regiszterkészlet). - A SP lehetővé teszi az aktiválási rekordok közvetlen elérését. aktuális - A SP és a relatív távolság megadásával aktiválási rekord bármely adat közvetlenül elérhető a stackaktuális cache-ben. stack pointer - Az aktiválási rekordok számának csak a (SP) stack cache fizikai mérete szabhat határt. SzA3. - előző SP A szekvenciális utasítás-végrehajtás menete (az aritmetikai utasítások és a feltétlen vezérlés-átadási utasítás végrehajtásának sémája) Egy gépi kódú utasítás általános formátuma: MK Címrész - előző aktiválási rekord MK : műveleti kód, mit csináljon a
processzor Címrész : mivel tegye mindezt Az utasítás-feldolgozás nagyvonalú folyamatábrája: Megszakítás igen megszakítás feldolgozása következik nem I. utasítás lehívás (fetch) II. utasítás végrehajtás (execution) 7. oldal, összesen: 95 MAR: Memory Address Register – memória-címregiszter (egyirányú). PC: Program Counter. MDR: Memory Data Register – memória-adatregiszter (kétirányú). IR: Instruction Register – utasításregiszter. DEC: Decoder. ALU: Arithmetical Logical Unit – műveletvégző (utasítást is képes továbbítani). AC: Accumulator – általános célú regiszterkészlet. - Egy hagyományos szekvenciális feldolgozást végző processzor részei: Operatív tár adatsín címsín processzor MAR MDR Vezérlő egység PC ALU IR AC DEC I. Utasítás lehívás A PC tartalmazza a következő végrehajtandó utasítás címét. MAR ← PC MDR ← (MAR) – nem a címét jutatja el, hanem a tartalmát. IR ← MDR – itt
már az IR-ben adat van. PC ← PC + 1 – következő feldolgozandó utasításra mutat, a +1 egységre utal, 2, 4 byte lehet. Ez a folyamat minden utasítás esetén megegyezik. II. Utasítás végrehajtás - Betöltés (load): DEC ← IR MAR←DEC műveleti kód IR címrész MDR ← (MAR) AC ← MDR 8. oldal, összesen: 95 címrész - - Aritmetikai-logikai utasítások: DEC ← IR MAR ← DECcímrész MDR ← (MAR) AC ← AC + MDR vagy AC ← AC – MDR vagy AC ← AC és MDR értelmezi, hogy mi van a címrészben a másik tag elmentése műveletvégzés Kiírás (store): DEC ← IR MAR ← DECcímrész MDR ← AC (MAR) ← MDR – meghatározott helyre történő visszaírás. - feltétlen vezérlésátadás (ne a soron következő utasítást végezze, hanem amit mi megadunk): DEC ← IR PC ← DECcímrész SzA4. Az állapottér és az állapotműveletek (az állapottér összetevői; az állapotműveletek) Állapottér a felhasználó számára látható a
felhasználó számára transzparens virtuális memória PC állapotjelzők CC állapot-indikátorok CC - Condition Code - 2 bites négy érték felvétele - IBM 360 állapot-indikátorok (flag): megszakítások verem . egyéb, a felhasználó számára látható állapotformáció adattípusonként különböző állapot-indikátorok nyomkövetés (debug) indexelés - minden helyiérték saját jelentéssel bír, pl. negatív, nulla, túlcsordulás adattípusonként különböző állapot-indikátorok: - minden regiszterkészlet típushoz hozzárendelnek külön állapot-indikátor készletet, pl. az általános célú processzorhoz tartozó flag-eken kívül a lebegőpontos proceszszorhoz is hozzárendelnek külön flag-készletet - a lebegőpontos flag-készlet eseményei pl. alul-, túlcsordulás, denormalizált szám, 0 9. oldal, összesen: 95 Megszakításoknál (fejlődés íve): - 1973 IBM 370-es gépcsaládnál bevezetik a PSW-t (Program Status Word):
megszakításoknál a PSW-t mentik el. Kontextus: a) A regiszterek aktuális értékei és b) Az állapottér aktuális értékei (PC, flag) Megszakításnál a kontextust mentik. Állapotműveletek PC Inkrementálás (növelés) Felülírás SzA5. Flag Set (beállítás) Save (mentés) Load (visszatöltés) Clear (törlés) Reset (kezdeti értékek visszaállítása) Az utasítás- és operandus típusok (utasítás- és operandus típusok; szabályos architektúrák) Az utasítások fajtái (típusai): op – operandus s – source (forrás) d – destination (cél) @ - tetszőleges művelet 4 címes utasítás opd:=ops1@ops2, op4 MK Opd ops1 ops2 op4 Az op4 a következő utasításra mutat, csak néha van nagy ugrás. Neumann szerint PC és címregiszter legyen az op4 helyett Hátránya: - memóriapazarló - adatrögzítési hibák lehetősége nő - nehézkes a program karbantartása 3 címes utasítás opd:=ops1@ops2; Az eredmény helyének explicit deklarálása. Előnye: -
Az aktuális utasítás eredményének mentésével párhuzamosan betölthetjük a következő utasítás bemenő operandusait. 10. oldal, összesen: 95 Hátránya: - Neumann szerint: Az aktuális művelet eredménye tipikusan a következő művelet egyik bemeneti operandusa. Pl.: RISC számítógépek (processzorok) 2 címes utasítás ops1:=ops1@ops2; a mai gyakorlat általában ops2:=ops1@ops2; Pl.: ADD[100],[102]; [memóriacímek] Előnye: - Memória- vagy regisztertakarékosabb, kiküszöböli a Neumann által említett hátrányt. Hátránya: - Az a forrásoperandus, ahol az eredmény képződik értékét veszti, ha később szükségünk van rá, a művelet előtt ki kell menteni. Pl.: IBM 360/370, Intel processzorok 1 címes utasítás - Az egyik forrásoperandust betöltjük az AC-ba: LOAD[100] - Az AC aktuális tartalmához hozzáadjuk az utasításban szereplő operandust: ADD[102] - Végül az AC tartalmát kimentjük az operatív tárba: STORE[100] Előnye: -
Rövidebb utasítások. Hátránya: - Több utasítást kell használnunk. Pl.: 1951 IAS (Neumann gépe), csak az 50-es 60-as években készült ilyen processzor 0 címes utasítás Fajtái: - NOP (no operation). - Veremműveletek (csak a verem tetejét látja): POP, PUSH. - A műveleti kód tartalmazza az operandust, pl.: CLEAD (a D flag törlése) Napjaink trendje: - CISC: - kétcímes - az első helyen képződik az eredmény - tipikusan csak a második cím lehet memóriacím - RISC: - aritmetikai-logikai utasítások esetén háromcímes utasítások - mindhárom regisztercím Operandus-típusok: Operandus-típusok akkumulátor (a) memória (m) regiszter (r) verem (stack - s) 11. oldal, összesen: 95 immediate (i) immediate: magában a programban adunk értéket a változónak a gyakorlatban ez bemenő operandus Architektúrák szabályos akkumulátor a-r aar memória a-m ara kombinált(pl. a+m) - a mai CISC processzorok 2 címes regiszter 3 címes 2 címes
aam ama m1m1m2 m2m1m2 m1m2m3 r1r1r2 verem 3 címes r2r1r2 SSS r1r2r3 Akkumulátor: Előny: Gyors, rövid címrész. Hátrány: Szűk keresztmetszet. Napjainkban nem aktuális. Regiszter: Előny: Gyors, rövid címrész. A mai RISC számítógépek mindegyike. Memória: Előny: Nagy címtér. Hátrány: Hosszú címrész, hosszú utasítások, lassú. Napjainkban nem aktuális. Verem: Előny: Gyors, rövid címrész (0 hosszúságú). Hátrány: Szűk keresztmetszet. Pl.: HP3000, VT1005, Napjainkban nem aktuális SzA6. Az aritmetikai egységek felépítése I. (az n-bites soros és párhuzamos összeadó, valamint az előrejelzett átvitellel felépített n-bites összeadó) n-bites soros összeadó Megjelenésének oka az, hogy az összeadandók tipikusan n bit hosszúságú regiszterekben helyezkednek el. n fokozatosan növekszik (ma: 32/64) Jellemzői: - A két operandus léptetőregiszterben (shift) helyezkedik el. - Az eredmény az A operandus helyén képződik. 12.
oldal, összesen: 95 - A kimenő átvitelt tárolóba vagy késleltetőbe helyezzük, hogy a következő bitpároshoz (összeadáshoz) megfelelő időben érkezzen. - A Cin csak az első bithelyiérték összeadásakor aktív. Értékelése: - Ha az egybites teljes összeadó műveleti ideje t, akkor az n-bites összeadási ideje: T=n×t. Gyorsítás: - t: A lehető leggyorsabb kialakítást alkalmazzuk. - N: Az egybites teljes összeadók számát megtöbbszörözzük n-bites párhuzamos öszszeadóra. n-bites párhuzamos összeadó 4 bites párhuzamos összeadó tesztelése: I. eset: A 0101 Cin=0; T=t B +1010 1111 II. eset: A 0101 B +1010 1. lépés 2. lépés 3. lépés 4. lépés Cin=1; T=n×t 1110 1100 1000 0000 C0=1 C1=1 C2=1 Cout=1 Értékelés: - Igen komoly beruházás árán (egy darab helyett n db egybites teljes összeadó) csupán hullámzó teljesítményt értünk el. Az ok: meg kell várni az átvitel terjedését Az átvitel előrejelzéses összeadó (Carry
Look-Ahead – CLA) Cout=A×B+(A+B) ×Cin A×B G (Generate) A+B P (Propagate) Az egyes bithelyiértékeken keletkező átvitel függ - a bemenő operandusoktól és - a kívülről beérkező átviteltől, melyek előre ismertek, de nem függ az előző bithelyiértékeken keletkező átviteltől. Az egyes bithelyiértékeken keletkező átvitel: Ci=Gi+Pi×Ci-1 C0=G0+P0×Cin C1=G1+P1×C0=G1+P1×G0+P1×P0×Cin C2=G2+P2×C1=G2+P2×G1+P2×P1×G0+P2×P1×P0×Cin C3=G3+P3×C2=G3+P3×G2+P3×P2×G1+P3×P2×P1×G0+P3×P2×P1×P0×Cin Értékelése: ÉS kapuk sorozata: 1 fokozat 13. oldal, összesen: 95 Összekapcsolásuk egy vagy kapuval: 1 fokozat P és G meghatározásához egy vagy és egy és kapu kell:+1 fokozat 3 fokozat Amennyiben egy fokozat végrehajtási ideje d, akkor egy bithelyiérték átviteli idejének meghatározása: T=3d Megvalósítási alternatívák: 1. Katalógus áramkör egybites teljes összeadók + CLA 2. Az egybites teljes összeadókat helyettesítjük a P
és a G meghatározásához szükséges kapukkal (vagy valamint és kapuk) A vagy kapu bemeneteinek száma technológiai korlátba ütközik, ezért max. 8 bithelyiértékre alakítható ki a CLA. 3. 32 bites megoldás: A CLA-k között az átvitel sorosan terjed 4. A CLA-khoz is hozzárendelünk egy CLA-t 14. oldal, összesen: 95 SzA7. Az aritmetikai egységek felépítése II. (a fixpontos szorzás algoritmusai és gyorsítási lehetőségek) Hagyományos szorzás: 13×123 39 26 13 1599 Algoritmizált változat: 13×123 0000 felveszünk egy gyűjtőt, amit nullázunk 39 0039 260 10-zel szorozzuk 0299 1300 100-zal szorozzuk 1599 10/100-zal való szorzás helyett léptetés: 13×123 0000 Konklúzió (decimális számoknál): Az összeadási ciklus annyiszor fut le, 39 0039 ahány helyiértékből áll a szorzó. 26 0299 13 1599 A bináris szorzás sajátosságai: - A bináris szám hossza Példa Decimális szám Bináris szám helyiértékeinek száma helyiértékeinek
száma 9 1 4 99 2 7 999 3 10 - Konklúzió: A bináris szám hosszabb, mint a decimális, ezért a ciklus többször fut le. A szorzat hossza A decimális helyiértékek száma Általánosítva A 1 2 2 m B 1 1 2 n Xmax 2 3 4 m+n Példa: 9×9 99×9 99×99 A szorzó és a szorzandó egy-egy regiszterben helyezkedik el, ezért az eredmény két regiszterben képződik. 15. oldal, összesen: 95 Példa: Legyen egy regiszterünk három helyiértékű, a szorzat kisebb helyiértékei keletkeznek a szorzó helyén: 0 0 1 1 9 9 5 2 1 9 9 3 2 1 9 eredmény A bináris szorzás gyorsítása: - Bitcsoportokkal való szorzás: A szorzó helyiértékeit nem egyesével, hanem csoportokban kezeljük, így a csoportokat léptethetjük, ami gyorsabb. Pl.: kettes csoportokban: 00 – kettőt léptetünk balra. 01 – a gyűjtőhöz hozzáadjuk a szorzandó egyszeresét és kettőt léptetünk balra. 10 – a gyűjtőhöz hozzáadjuk a szorzandó kétszeresét és kettőt léptetünk balra.
11 – a gyűjtőhöz hozzáadjuk a szorzandó háromszorosát és kettőt léptetünk balra. Példa: Segédszámítás: 7×9 = 0111×10|01 a szorzandó kétszerese: 0111 0000 A: összeadással 0111 0111 1110 0111 1110 B: léptetéssel 01111110 111111B = 63D - Booth féle algoritmus: - Bináris számok esetén az összeadási ciklus annyiszor fut le, ahány egyes van a szorzóban (nulla esetén csak léptetünk). A szorzóban lévő egyesek számának csökkentése a cél. Példa: 62-vel kell szorozni: 62=111110B 5 db összeadás. Helyette: ×64=100000B 1 db összeadás ×2=000010B 1 db összeadás – 1 db kivonás Összesen 3 db művelet, 40%-os időmegtakarítás, pl.: mai processzorok mindegyike. 16. oldal, összesen: 95 SzA8. Az aritmetikai egységek felépítése III. (a fixpontos osztás algoritmusai; a fixpontos multimédia (a raszteres képfeldolgozás és a hangfeldolgozás) probléma-felvetése és megoldása) Osztás X=A/B Hagyományos osztás: 150/48 150 I
–48 102 II 3,1 –48 54 III –48 60 I –48 120 I –48 72 II Konklúzió: Minden kivonás előtt komparálunk (összehasonlítunk), ezért lassú. Visszatérés a nullán át csak az előjel flag-et vizsgálva: 150 –48 102 I –48 54 II –48 6 III –48 –42 kiírja a gyűjtőt (3,) +48 hozzáadja a maradékhoz az osztót (–42+48) 60 tízszerezi (6×10=60) és folytatja –48 12 –48 –36 kiírja a gyűjtőt (,1) +48 Itt minden kivonás automatikus (nincs komparálás, ami lassú). Mivel nem kell minden kivonás előtt komparálni, csak a gyors előjel flag vizsgálatot végezzük, a két felesleges művelet (hozzáadás +48 és szorzás) ellenére gyorsabb. 17. oldal, összesen: 95 Visszatérés nélküli osztás: 11/6 11 I –6 5 10. lépés –6 –10 9. lépés +6 –4 8. lépés +6 +20 I –6 14 II –6 8 III –6 2 10. lépés –6 –40 9. lépés 1,8 kiírja a gyűjtőt szorozza 10-zel Fixpontos multimédia feldolgozás A probléma felvetése: A,
Hangfeldolgozás: - analóg jel digitális jelfeldolgozásához digitalizálni kell analóg digitális (A-D) konverter Amplitúdó vagy felbontás: - A leképezendő hanghullám minimális és maximális értékhez hozzárendeljük az értelmezési tartományunk minimális és maximális értéket. - 8 bit 256 pontos felbontás - 16 bit 65536 pontos felbontás (a mai gyakorlat) Mintavétel: - Példán keresztül: Egy 50kHz-es mintavétel azt jelenti, hogy másodpercenként 50000 mintát veszünk az adott hullámból (minden egyes mintánál az amplitúdó értékét tároljuk el). 18. oldal, összesen: 95 - Mai példák: Alkalmazás a) Telefon b) Audio CD c) DVD d) DVD (minőségi) kHz 8 44 48 96 Egy másodperc hanganyag tárolási igénye audio CD, 16 bites felbontás, sztereó esetén: - 44000 minta×2 byte felbontás×2 a sztereó miatt = 176000 byte/sec ~ 170 kbyte/sec - Percenként: 60×170 ~ 10Mbyte/min Feladat: Nagy tömegű fixpontos adat - tárolása -
továbbítása - feldolgozása B, Pixeles képfeldolgozás: - A fénykép és a festmények analóg formátumúak, hiszen a fények, árnyékok és színek folyamatos átvitelével írhatók le. A képeket digitalizálnunk kell. Felbontás: - A képeket képpontokra (pixel) bontjuk. Minél sűrűbb a rácsszerkezet, annál jobb minőségű képet kapunk a digitalizálás során Minél kisebb egy pixel, annál jobb a leképezés Pl: 800×600; 1280×1024 Pixelek vagy képpontok: - Minden szín leírható három szín összetételeként, tehát minden pixelhez három darab színkódot kellene hozzárendelni, de helyette ezeket egyetlen vektorrá kódolták. Pl.: 000 0, 001 1, 010 2 A pixelek lehetséges értékei: - 1 bit: fekete-fehér, sötét-világos - 1 byte: 256 féle színt írhatunk le - 2 byte: 65536 féle szín (high-color) - 3 byte: 224 féle szín (true-color) (az emberi szem ennyit nem tud megkülönböztetni, azért jó a sok szín, mert a számítógép ezt is tudja
értelmezni) - 4 byte: a negyedik byte az úgynevezett alfa csatorna, az effektek jelzésére szolgál (pl.: átlátszóság mértéke) Egy kép tárolásához szükséges memóriaterület: egy byte 800×600 480000 byte 1280×1024 1,3 Mbyte két byte 960000 byte 2.6 Mbyte A képfeldolgozás feladata: Nagy tömegű fixpontos adat tárolása, továbbítása, feldolgozása. 19. oldal, összesen: 95 Megoldás: - Tárolás, továbbítás hatékony tömörítéssel. Feldolgozás: - Probléma: a 3 perces számot 3 perc alatt le kell tudni játszani - Hagyományos feldolgozás: pl.: 2 kép összeadása a 800×600-as felbontás mellett 1. Az 1 kép 1 byte-ját betöltjük az AC-ba 2. A 2 kép 1 byte-ját hozzáadjuk az AC-hoz, az eredmény az AC-ban keletkezik 3. Az AC tartalmát lementjük az eredmény memóriaterületre Ez a ciklus 480000-szor fut le. (minden bájtra) - Megoldás SIMD módszerrel (single instruction, multiple data): Több adattal ugyanazt az utasítást hajtja
végre, ~ 8-szoros gyorsítást eredményez, 60000-szer fut le a ciklus. A + + + + + + + + +B = = = = = = = = X - 8 db A gyakorlatban kétféle megoldás: - multimédia segédprocesszor - az általános célú processzorba beleintegrálják a multimédia feldolgozó egységét. - Az Intel MMX kiterjeszés: a) 1997-ben jelent meg b) Matrix Math Extension (Multimedia Extention) c) Logikai architektúra: 1. Pakolt adattípusok bevezetése a. Ezek mindegyike 64 bites, ami megegyezik a processzor belső sínjének szélességével. b. Fajtái: pakolt byte: 8 db 8 bites = 64 bit, pakolt félszó: 4 db 16 bites = 64 bit, pakolt szó: 2 db 32 bites = 64 bit. 2. Új utasítások bevezetése A négy aritmetikai művelet (+,–,×,÷) és a logikai műveletek mindhárom új adattípushoz. d) Fizikai architektúra: 1. Az Intel nem akart új regisztereket bevezetni az új adattípusokhoz, hanem a 80 bites lebegőpontos regisztereket használja a 64 bites pakolt adattípusok feldolgozására. 2.
Egy évre rá az MMX műveletvégzőket 2-re növelték, így a ciklusok száma 30000-re csökkent 20. oldal, összesen: 95 SzA9. Az aritmetikai egységek felépítése IV. (a lebegőpontos algebrai műveletek és megvalósításuk A lebegőpontos multimédia (vektoros képfeldolgozás) probléma-felvetése és megoldása) Lebegőpontos műveletek Összeadás: X=A+B A=mArka B=mBrkb Példa: 0,9×103 +0,95×104 0,09×104 +0,95×104 1,04×104 0,104×105 Közös kitevőre kell hozni, a mantisszában a törtpontot ciklikusan léptetetem jobbra/balra. Mantissza vizsgálata, majd szükség esetén normalizálása. Bonyolultabb, mint a fixpontos Algoritmus: 1. A kitevők megvizsgálása: csak azonos kitevőjű számok mantisszái adhatók össze 2. Amennyiben a kitevő eltérő, akkor a kisebb kitevőjű szám mantisszájában a törtpontot jobbra léptetjük és a kitevőt inkrementáljuk. Ez a ciklus addig fut, míg a kitevők meg nem egyeznek. 3. Összeadjuk a
közös kitevővel rendelkező számok mantisszáit 4. Szükség esetén normalizálunk Szorzás: X=A×B=mA×mBrka+kb Algoritmus: A mantisszákat összeszorozzuk, a karakterisztikákat pedig összeadjuk. Osztás: X=A/B=mA/mBrka-kb Algoritmus: A mantisszákat elosztjuk, a karakterisztikákat pedig kivonjuk egymásból. Megvalósítás: Univerzális műveletvégző - az ALU parciálásával (részekre bontásával) karakterisztika mantissza fixpontos ALU Ez egy kicsit bonyolultabb vezérléssel megoldható. - Szervezési módosítással a) Mind a mantisszát, mind a karakterisztikát külön-külön regiszterekben helyezzük el. b) Egymás után elvégezzük a mantissza és a karakterisztika műveleteket. c) Az eredményt pedig az egyik regiszterben összevonjuk. 21. oldal, összesen: 95 Dedikált műveletvégző adatsín Karakterisztika egység Mantissza egység visszacsatolás Vezérlő vezérlés Következtetések: - Míg a mantissza egységnek ismernie kell a szorzást
és osztást is, a karakterisztika egységnek elegendő az összeadást és a kivonást ismernie. - Párhuzamosan lehet végezni a karakterisztika és a mantissza műveleteket. - A szűk keresztmetszetet a mantissza egység jelenti (a szorzás, osztás miatt), mivel a karakterisztika egység az összeadást és kivonást gyorsan el tudja végezni. A gyorsítást a mantissza egységnél kell végezni. Lebegőpontos, vektorgrafikus multimédia műveletek: - Az egyenesekkel és görbékkel határolt objektumok geometriai jellemzőikkel leírhatók. Elegendő a geometriai jellemzők tárolása. Például: a) Egyenes esetén: Két pontjának koordinátáit. b) Kör: A középpont koordinátáját és a sugár hosszát. Jellemzők: - 2D: - Egy kép igen sok objektumra (sokszögre, háromszögre) bontható egy átlagos kép objektumainak száma ~20000. - Miután a számítógép a geometriai jellemzők alapján meghatározza a ~20000 objektumot, a színek valósághűbb átmenete
érdekében egy úgynevezett textúrát alkalmaz. A megoldandó feladat: - Viszonylag kevés lebegőpontos adaton - sok műveletet hajtunk végre. - 3D: - - Egy harmadik dimenzió kerül hozzáadásra. a) Biztosítani kell a párhuzamosoknak a végtelenben való találkozását. b) Az atmoszférikus sajátosságok is megvalósításra kerülnek, azaz a közelebb lévő tárgyak élesebbek, a távolabbiak kékesebbek és elmosódottabbak. Sok 3D film készül, ahol minimum 15 képet kell vetíteni másodpercenként annak érdekében, hogy folyamatosnak láthassuk. Pl.: képenként 20000 objektummal számolva 20000×15=300000 obj/sec feldolgozási sebesség szükséges 22. oldal, összesen: 95 A megoldandó feladat: - Viszonylag kevés lebegőpontos adaton - sok műveletet kell végrehajtanunk - adott időegység alatt. Megoldás az Intel processzoroknál: - 1998: MMX2, azaz a KNI (Katmai New Instruction) - a megoldás: a SIMD elv (Single Instruction Multiple Data) - 1985 óta
először új regisztereket vezetett be az Intel: 8 db 128 bites regisztert. - Formátumok: a) 4 db 1-szeres pontosságú vagy b) 2 db 2-szeres pontosságú számon hajt végre egy időben műveletet: - + + + + = = = = 70 db új utasítást vezettek be. 100%-osan megfelel az IEEE 754-es szabványának. Megszakítás esetén az új regisztereket is menteni kell, ezt először a Win98 operációs rendszer végzi. A lebegőpontos műveletvégzés jelentősége: - A tudományos és multimédia számításokhoz szükséges. - A miniatürizálás és a fajlagos árcsökkenés eredményeként a jelenleg kereskedelmi forgalomban lévő processzorok mindegyike hardver úton megvalósítja. SzA10. A vezérlőegység (az áramköri vezérlőegység és a mikrovezérlő jellemzőinek szembeállítása Az áramköri vezérlőegység megvalósítása és működése) - - Centralizált vagy szekvenciális vezérlés: a) Huzalozott vezérlés. 1. 1947: első elektronikus számítógép
b) Mikroprogramozott vezérlés. 1. 1954: Wilkes 2. 1963: CDC6600 Decentralizált vagy párhuzamos vezérlés: a) Szuperskalár. 1. 1966: IBM 360/91 b) Futószalag. 23. oldal, összesen: 95 Huzalozott vagy áramköri vezérlés Hátrányai: - Az ember számára nehézen áttekinthető. - Nehézkesen módosítható. Előnye: - Gyors. Tervezése: - igazságtábla - logikai függvények - azonos átalakítások a következő célfüggvényekkel: a) az elemek számának minimalizálása b) a végrehajtási idő minimalizálása - megvalósítás Megvalósítás: Elv: - Egy forrásregiszterből módosító áramkörökön keresztül egy célregiszterbe juttatjuk az adatot. Regiszterek: - Memória regiszterek (MDR, MAR). - ALU regiszterei (AC, általános célú regiszterkészlet). - I/O regiszterek (vezérlőkártyán). - Vezérlőrész regiszterei (utasítás regiszter, PC). 24. oldal, összesen: 95 Módosító áramkörök: - Összeadó - Invertáló - Inkrementáló -
Léptető Működése: - A forrásregiszter kimenetét rákapuzzuk a módosító áramkör bemenetére. - Előírjuk a módosító áramkör számára, hogy most éppen milyen módosítást hajtson végre. (Pl: léptetés, összeadás) - A módosító áramkör kimenetét rákapuzzuk a célregiszter bemenetére. A mai processzorokban tipikusan több száz olyan vezérlési pont van, amit vezérelni kell. Mikroprogramozott vezérlés 1954: Maurice Wilkes (University of Cambridge). Cél: - Ember számára áttekinthetővé tenni a vezérlést. a) Mikroutasítások, melyek meghatározott vezérlővonalat, vagy -vonalakat aktiválnak. b) A gépi kódú utasítások végrehajtása mikroutasítások sorozatával érhető el. c) A hagyományos (Neumann-elvű) számítógépet tekinthetjük egy makroszámítógépnek, ezen belül helyezkedik el egy mikroszámítógép mikroutasítássokkal, mikroprogrammal. - A vezérlést rugalmassá, könnyen módosíthatóvá alakítani. a) A
mikroprogramot tároló Control Memory-ban cserélhetjük, változtatjuk magát a mikroprogramot. Huzalozott kontra mikroprogramozott vezérlés: sebesség gyors áttekinthetőség ember számára nehezen áttekinthető módosíthatóság merev, nehézkesen módosítható mindig lassabb ember számára áttekinthető rugalmas SzA11. Félvezető tárak (jellemzőik; csoportosításuk) Csoportosításuk: Félvezető memória-típusok írható-olvasható RAM DRAM (operatív tár) főképpen csak olvasható - CMOS (setup) SRAM (gyorsító tár) csak olvasható ROM (BIOS) 25. oldal, összesen: 95 A számítógépen belül a legelterjedtebb a RAM (Random Access Memory). Szó szerinti fordításban ez közvetlen elérésű tárat jelent, azonban ez a táblázatban szereplő valamennyi tárra vonatkozóan igaz, tehát nem egy egyedi jellemzőt tartalmazó elnevezés. Így inkább szabad fordításban írható-olvasható tárnak nevezhetjük. Ennek kétféle gyártási
technológiája van A megengedett Az adaA memóOlvasási írási Jelleg tok élet- Írási idő Törölhetőség ria típusa idő ciklusok tartama száma írható60-100 programból, DRAM 4-32 ms 60-100 ns végtelen olvasható ns bájt szinten az áramprogramból, írhatóforrás SRAM 10-25 ns 10-25 ns végtelen blokkolvasható kikapszinten csolásáig csak olcsak nem lehetROM végtelen különböző 100 ns vasható egyszer séges csak olcsak nem lePROM végtelen órák 100 ns vasható egyszer hetséges főképpen ultraviola pár máEPROM csak ol- végtelen 100 ns sokszor fénnyel, lapsodperc vasható ka-szinten főképpen kb. 1 mákorlátoEEPROM programból, csak ol- végtelen sodperc/ 100 ns zott bájt szinten vasható bájt számban főképpen korláto- programból, Flash csak ol- végtelen n. a 100 ns zott blokk szinvasható számban ten a tápfőképpen elem CMOS csak ol- által törn. a n. a sokszor programból vasható ténő táplálásig A fontosabb félvezető
memória-típusok és tulajdonságaik A DRAM a Dynamic RAM, azaz a dinamikus RAM jelenti az alkalmazás során a nagyobb tárolási kapacitást. Fizikailag bitenként egy kondenzátort alkalmaznak benne, melynek feltöltött állapota jelenti az 1-et, és az ellenkező állapota pedig a 0-t Sajnos a kondenzátor jellemző fizikai tulajdonsága, hogy az alkalmazott szigetelő tökéletlensége miatt idővel elveszíti töltését. Annak érdekében, hogy az adatvesztést megakadályozzuk, a tartalmát rendszeresen újra kell írni, azaz frissíteni kell. Ez a felhasználó számára teljesen észrevétlenül történik, az alkalmazott memória jellemzőitől függően 4-30 msec-onként A DRAM viszonylag könnyen és olcsón gyártható, kis energia-fogyasztású, de például a processzorhoz képest viszonylag lassú. Hátránya, hogy a tápáram kikapcsolásával elveszíti tartalmát. A gyakorlatban ezt a memóriatípust alkalmazzák operatív memóriaként 26. oldal, összesen: 95
Fast Page Mode DRAM 1, Cím-folytonos olvasás: egyszerre több bitet olvasunk a mátrixból, így a RAS jelet elég csak egyszer kiadni. (6+4+4+4 ns) Nibble Mode FPM DRAM: 4 rekeszes RAM 1. az első olvasásnál rákerülnek a címek, a RAS és a vezérlőjel 2. a címek növelése az IC-n belül történik, nincs külső címzés Mindez a CAShez szinkronizálva; (6+4+4+4 ciklus) Ez akkor előny, ha a CPU 4 bájtos egységekben hívja le az adatot OPT-ból, és folyamatosan tudja fogadni az adatokat. Extended Data Out DRAM = EDORAM +1 kimenet bevezetése (tároló) a nCAS visszabillenésének tárolására. A kimeneti adat érzékelését ehhez kötik: előbb indulhat a kiolvasás (egy ciklus megspórolása). 6+3+3+3ciklus – Output Enable nOE // nX = X negáltja Burst Extended Data Out DRAM = BEDO RAM Nincs szükség az oszlop vezérlőjelre, a címeket az IC-n belül generálja. Saját címszámlálóval és belső pipeline-nal rendelkezik A bemenetén már
megjelenik az új adat, amikor a kimenetére kerül az előző adat. (6+2+2+2ciklus) Synchronous DRAM = SDRAM Az olvasás a CPU vezérlőjeléhez van szinkronizálva, nem pedig a CAS-RAS-hoz. 5+1+1+1 ciklus. 1 SDRAM lapra 4db Bank (4*8 bit) Rambus DRAM • teljesen új architektúra, több egymástól független memóriamodult tartalmaz • rendkívül nagy belső cache-tárja van (1M-hoz 2K cache), • NINCS nRAS, nCAS helyette 1 lépésben kapja meg a címet • blokkos az adatátvitel; blokk: 8db 256 bájt terjedelmű, adatszélesség: 8bit • gyors blokkmozgatás, speciális illesztő-áramkör szükséges (rambus) • nagyon drága, mert az eltérő technológia miatt más gyártósort igényel DDR SDRAM SDRAM esetén a művelet a felfutó élre van szinkronizálva, míg a DDR SDRAM esetén a lefutóra is. • A belső memória lapokra van bontva: az egyik rekeszben adatforgalom, a másikba beolvasás. • Nagyon gyors belső órajelgenerátor és pipeline. •
Kompatibilis a jelenlegi gyártási technikával. • PC 2100: 2100 Mb/s / 266MHz / 7,5ns • PC 2700: 2700 Mb/s / 333MHz / 6ns • PC 3200: 3200 Mb/s / 400MHz / 5ns Összefoglalva: DRAM [ns] [Mb/s] 60 100 FPM EDO Aszinkron burst 40 25 200 266 BEDO SDRAM RDRAM DDR szinkron 15 532 15/10/7,5 1600 4/3,3 7,5/6/5 Az SRAM a Static RAM, azaz a statikus RAM jelenti a gyakorlatban a kicsi, de gyors memóriát. Ezt hagyományos flip-flop alkalmazásával készítik, így frissítést nem igényel (innen ered a neve is), s a tartalmát egészen addig megőrzi, amíg a tápáramforrás be van kapcsolva. A DRAM-hoz képest a gyártása nehezebb, az ára magasabb, s több áramot is fogyaszt. Ez utób27 oldal, összesen: 95 bi esetben nem annyira a magasabb fogyasztás jelent hátrányt, hanem inkább az, hogy nagyobb energia alakul át hőenergiává, aminek elvezetéséről gondoskodni kell. A sebessége viszont már közelebb áll a processzor sebességéhez. Ezért a
számítógépen belül ezt a memória-típust alkalmazzák gyorsítótárként A főképpen csak olvasható memóriák közé sorolható CMOS memóriát alkalmazzuk a PC-nk egyedivé alakítására, a beállítási (setup) adatok (a külső tárolók indítási sorrendje, a külső tárolók jellemzői, a memória mérete stb.) tárolására A CMOS memória a számítógépben lévő elemmel táplálva alacsony feszültségszinten, igen csekély fogyasztás mellett a számítógép kikapcsolása után is képes a benne tárolt adatok megőrzésére, s üzemi feszültségszinten pedig azok módosítására is. A CMOS lapka az adattároló egységen túlmenően tartalmaz egy órát is, mely az elem táplálásával a számítógép kikapcsolása után is képes követni az idő múlását. A csak olvasható memóriából (ROM) töltődnek be az első programok, így az egyes részegységek működőképességét letesztelő programok valamint az alapvető beviteli-kiviteli műveletek
(BIOS) programjai, s így bekapcsolásakor e memória-típus segítségével éled fel a számítógép. SzA12. A megszakítási rendszer (fogalma; megszakítási okok; a megszakítás folyamata; az egy- és a többszintű megszakítási rendszer) A számítógépnek rugalmasan reagálnia kell a külvilág eseményeire. Erre a célra szolgál a számítógép megszakítási rendszere. A megszakítás bekövetkezésekor az éppen futó programról vezérlés ideiglenesen átadódik egy másik program számára, amely kiszolgálja a bekövetkezett eseményt A megszakítást kiszolgáló program lefutása után pedig a megszakított program végrehajtása a következő utasításától kezdve folytatódik Váratlan esemény aszinkron (teljesen reprodukálhatatlan) várható pl. DMA szinkron (bármikor reprodukálható, a program minden futásakor ugyanott következik be) nem várható pl. hardver hiba paritás hiba, áramkimaradás A megszakítások okai vagy forrásai: 1.
Géphibák: - Az egyes eszközök valamilyen hibajavító kód segítségével ismerik fel a hibákat - A CPU regiszterei - Operatív tár - Adatátvitel - Energiaellátás hibái - Klimatizáció 2. I/O források: a perifériák megszakítás-kérő jelzései (CPU dobozon belül) 3. Külső források másik számítógép 4. Programozói források 28. oldal, összesen: 95 Utasítások végrehajtásakor keletkező megszakítások: Hiba, nem kért, váratlan (arch. specifikusak) o Memóriavédelem megsértése (saját részéről túlmutat) o Tárkapacitás túlcímzés (tényleges) o Címzési előírások megsértése o Aritmetikai és logikai műveletek miatti megszakítás (kivételek:tömbindextúlcímzés, 0-val való osztás, overflow) Szándékos o Rendszerhívások (pl. az Intel CPU-k overflow flag-je jelzi, ha túlcsordulás lépett fel. Az INTO utasítással egy megszakítás kérhető: korrekció) Megszakítás-kiszolgálás 1. egy egység aktiválja az INTR
bemenetet 2. a CPU elfogadja ezt az INT kérést, ha megszakítható állapotban van megfelelő a prioritás nagysága a beérkezett megszakítás nincs maszkolva (letiltva) A 3 felt. teljesülése esetén INT elfogadva 3. minden utasítás-töréspontban a vezérlőegység megvizsgálja, hogy van-e megszakítás Észleli, hogy van megszakítás. Az INTACK vezérlővonal aktiválásával jelzi a megszakítási kérés elfogadását, mire a megszakítást kérő deaktiválja az INTR vonalat 4. CPU elmenti a verembe az aktuális állapot információkat (PC, flag) automatikusan 5. a megszakított program adatterének mentése (regiszterkészlet) 6. a megszakítást igénylő azonosítása (ha egy INT-hez több egység is tartozik) 7. megszakítás kiszolgálása 8. az adattér visszaállítása 9. A CPU a kiszolgálás végeztével visszaküld egy nyugtát az egységnek, az pedig deaktiválja a jelet A megszakítás kiszolgálása után a megszakított program
folytatódik, vagy nem (reset). Mindegyik INT-hez tarozik egy bit: a CPU ezeket vizsgálja, amikor fogadóképes. A megszakítást kérő azonosítása A legegyszerűbb lehetőség a megszakítások egyenkénti kiszolgálása, azok beérkezési sorrendjében. Hátránya, hogy a megszakítások kiszolgálása közben érkező megszakítást nem tudja kiszolgálni, így a halaszthatatlan kérelmek elveszhetnek. 1. Lekérdezéses (polling): Valamilyen sorrendben lekérdezzük az egységeket Hardveres úton: daisy chain Szoftveres úton: az operációs rendszer 2. Vektoros: A megszakítást kérő eszköz a kiszolgáló rutin kezdőcímét határozza meg a megszakítási vezérlő és a processzor számára Több megszakítási vonal esetén minden eszköz saját megszakítást kérő vezetékkel rendelkezik, így a kérelem helye egyértelműen megállapítható. 29. oldal, összesen: 95 Megszakítási rendszerek szintek szerint Egyszintű: Nincs lehetőség a kiszolgáló
rutin felfüggesztésére egy újabb megszakítási kérelem által. A kiválasztó logika a kiszolgálás közben érkezett megszakítások közül a legmagasabb prioritású engedélyezett megszakítás-kérést engedélyezi Az 1-es forrás szerinti kérés feldolgozása hosszabb ideig is eltarthat, viszont az 0-ás forrás megszakítás-kérése esetleg nem tűrhet ekkora halasztást. 1 INT 0 2 normál felh.-i szint t 1 2 0 0 2 Többszintű: keresi a pillanatnyi CPU-szintnél magasabb prioritás-szintű engedélyezett megszakítás-kéréseket. Kiválasztja a legalacsonyabb prioritás-szintűt PSW-csere esetén ez oly módon zajlik le, hogy a megszakított szint PSW-je Old PSW-ként tárolódik, a másik rekesz tartalma pedig New PSW-ként betöltődik a programállapot-regiszterbe. Az elfogadott megszakítás-kérés nyugtázódik Ha nem talál az utolsó szintnél magasabb prioritású engedélyezett kérést, akkor megengedi a legutolsó New PSW-ben megjelölt utasítás
végrehajtását. 0 0 1 2 3 1 1 2 1 2 0 t 2 Kompromisszum: az előző kettő ötvözése, azaz szinteket rendelnek a megszakítások egy-egy csoportjához 0 1 2 3 0/a 1/a Szinten belül egyszintű, szintek között többszintű 1/a 2/a 1/a 0/a 2/a 2/b 2/b t 2/a 2/b 30. oldal, összesen: 95 SzA13. A külső sínrendszer (fogalma; jellemzői; csoportosítása, a sínfoglalás (bus arbitration) módjai; az adatátvitel és felügyelete (szinkron, aszinkron)) Fogalma: - Műszaki: Olyan vezetékköteg, melynek minden egyes erén vagy csak a logikai 0-nak megfelelő 0 Volt, vagy csak a logikai 1-nek megfelelő +12, +5, +3.3, +28 Volt jelenhet meg - Funkcionális: Olyan vezetékköteg, mely lehetővé teszi egyszerre n bit továbbítását a forrástól a célig. Ebben a kontextusban a sín fogalmába beleértjük a sín forgalmát vezérlő intelligenciát is Jellemzői: - A vezetékek száma. - Napjainkban tipikusan megosztott eszköz: a) Minden vezeték egy
időpillanatban 1 bitnyi információt továbbíthat b) Mindig csak egyetlen adó lehet, vevőoldalon lehet több eszköz is. - Regiszter tulajdonsággal rendelkezik. Értelmezett: r1r0 úgy történik, hogy: databusr0 r1databus Csoportosítás: - Átvitel iránya szerint: a) Szimplex: egyirányú. b) Duplex: egy időben egyirányú; kétirányú. c) Full-duplex: egy időben kétirányú (két vezeték van). d) Pl.: Egyirányú: órajel, reset, cím Kétirányú: adat - Az átvitel jellege szerint: a) Dedikált sín: 1. Jellemzői: Minden egységet minden egységgel összekötünk. Egysínes: (n×(n–1)) /2 sín. U3 U4 Kétsínes: n×(n–1) sín. 2. Előnyei: a. Gyors: minden egység minden egységgel párhuzamosan kommunikálhat b. Megbízhatóság: amennyiben biztosított az infrastruktúra, akkor pl. az U1-U2 közötti szakadás esetén a két egység továbbra is kommunikálhat U3 vagy U4 egységen keresztül. 3. Hátrányai: a. Drága b. Újabb egységek
csatlakoztatása bonyolult c. Újabb csatlakozási felületek kialakítása bonyolult d. Újabb csatlakozási felületek kialakítása technológiai nehézséget jelent. U1 31. oldal, összesen: 95 U2 b) Közös (shared) sín: 1. Jellemzője: Minden egység egyetlen közös sínen keresztül kommunikálhat U1 U2 Un 2. Előnyei: a. Olcsóbb (nem sokkal) közös sín b. A szabványos csatlakozási felületek miatt könnyű az újabb egységek csatlakoztatása. 3. Hátrányai: a. Lassúbb, mivel egyidejűleg csak egyetlen adó lehet a sínen, a többinek várnia kell a sín felszabadulására. b. Érzékeny a közös sínrendszer meghibásodására c. A közös sínrendszer vezérlése bonyolult (nem olcsó) Funkcionális csoportosítás: a) Címsín: 1. Feladata: Az egységek (pl: hálókártya) illetve egységrészek (pl: memóriacím) azonosítása 2. Fejlődése az Intel esetében: 20 bit v. v 4 bit v. v 20 bit 80386 20 bit vezérlő vezetékek 80286 8088 - v. v 4 bit
v. v 8 bit v. v 20 bitnél 1MB-ot tudunk megcímezni, 24 bitnél már 16MB-ot, 32 bitnél 4GB-ot. Napjainkban is 32 bit a címzési lehetőség 3. A kompatibilitás megtartása nem eredményezett tiszta tervet b) Adatsín: 1. Feladata: Adatok továbbítása 2. Fejlődése: a. 8088 – 8 vezetékes volt b. 80286 – 16 vezetékes volt c. 80386– 32 vezetékes 3. A kompatibilitás megtartása nem eredményezett tiszta tervet c) Közös adat- és címvezeték: 1. Akkor alkalmazzák, amikor: a. vezetéket kívánnak megtakarítani, vagy b. a csatlakozó lábak számát szeretnék csökkenteni 2. Külön vezérlővezetékkel kell jelezni, hogy mi van az adott pillanatban a sínen (cím vagy adat). 3. Akkor érdemes alkalmazni, ha blokkos átvitelt használunk A blokk kezdőcíme átvitele után a többi cím inkrementálással megállapítható. 4. Időbeli multiplexelés elvén alapul 5. Pl: PCI 32. oldal, összesen: 95 d) Vezérlővezetékek (sín): 1. Számuk tipikusan 10-15 db 2.
Fajtái: a. Adatátvitel vezérlése: 1. R/W – read/write: a processzor nézőpontjából mutatja az átvitel irányát. 2. B/W – byte/word: hány bitet kell párhuzamosan átvinni. 3. A/D – address/data: a közös vezetékeken cím vagy adat van-e. 4. AS – address strobe: a címet felhelyeztük a sínre. 5. DS – data strobe: az adatot felhelyeztük a sínre. 6. M/U – memory/unit: a címvezetéken memóriacím van-e vagy egységcím. 7. RDY – ready: kész. b. A megszakítások vezérlése: A megszakítások kérése és engedélyezése. c. A sínhasználattal kapcsolatos vezérlővezetékek: A sínhasználat kérése, engedélyezése, a sínfoglaltság jelzése. d. Egyéb: 1. CLCK – órajel 2. Reset – kezdeti értékek visszaállítása Az összekapcsolt területek alapján: M1 CPU - Mn bővítősín Sínvezérlő rendszersín I/O1 I/On a) Rendszersín: 1. A rendszersín tipikusan gyorsabb, mint a bővítősín 2. A rendszersín nehezen
szabványosítható, mivel CPU közeli sajátosságok kihasználásával teljesítménye növelhető 3. Elnevezések: a. Rendszersín: A rendszer adatforgalom itt zajlik b. Memóriasín: Memóriablokkok összekapcsolása c. Processzorsín: 1. A winchesteren tárolt adatokat a DMA vezérlő segítségével közvetlenül a memóriába visszük 2. A processzor pedig a másodszintű gyorsítótárból dolgozik b) Bővítősín: 1. Feladata: az I/O egységek csatlakoztatása a processzor-memória kettőshöz 33. oldal, összesen: 95 2. Fejlődése: a. Kábelekkel egyedi módon csatlakoztatták a perifériákat b. DEC első gépei sín-orientáltak voltak Aljzatokat alakítottak ki tesztkészülékek csatlakoztatására. Megoldásaikat szerzői jogi védelem alá helyezték. c. 1976: az Altair tervezője kialakította az S-100-as bővítősín architektúrát, mely 100 db érintkező felületet biztosított Ezt az IEEE szabványként fogadta el. d. 1981: IBM PC 3. Elnevezések: a.
bővítősín b. I/O sín c. helyi sín A sínrendszer működése Megosztott sínrendszer esetén két fázisból áll: - A sínfoglalás (bus arbitration) – ha két vagy több egység szeretne master lenni, akkor sínütemezésre van szükség, hogy a káoszt elkerüljük - A sínhasználat (bus timing) – maga az adatátvitel folyamata Sínfoglalás: Soros sínfoglalás: - Hardver lekérdezéses (daisy chain – gyermekláncfű). Előnyei: a) Kevés vezetéket igényel (olcsó) b) Elvben végtelen számú egységet tudunk csatlakoztatni Hátrányai: c) A prioritás hardveres úton szabályozott (merev) d) Az előrébb álló egységek elnyomhatják a hátrébb állókat e) Érzékeny a bus grant vonal meghibásodására Működése: Amikor az ütemező egy sínkérést észlel, használati engedélyt ad ki oly módon, hogy beállítja a sínhasználat engedélyezése jelet. Ez sorban keresztülfut az összes egységen Amikor az ütemezőhöz fizikailag legközelebbi eszköz
meglátja az engedélyezést, ellenőrzi, hogy ő adta-e ki a kérést. Ha igen, akkor átveszi a sínt, és nem továbbítja az engedélyt a következő eszköznek. Az egységek távolsága egyben a prioritásukat is meghatározza. 34. oldal, összesen: 95 - Szoftver lekérdezéses (software polling). Előnyei: a) A prioritás szoftveres úton szabályozott (rugalmas) b) Kevésbé érzékeny a bus grant vonal meghibásodására Hátrányai: c) több vezérlővonal (drága) d) A csatlakoztatható egységek számát a bus grant vonalak száma korlátozza, példánkban maximum 23=8 db Párhuzamos sínfoglaltság: a) Előnye: gyors b) Hátránya: még több vezérlővonalat igényel (még drágább), pl.: PCI Rejtett sínfoglalás: - Előfeltétele: két, egymástól független hardver vezérelje a sínfoglalást és az adatátvitelt - Amíg az aktuális adatátvitel folyik, az alatt lehetőség van az adatsín következő használójának kiválasztására Adatátvitel (bus
timing) Szinkron adatátvitel - Fogalma: Az adatátvitel mind az adó, mind a vevő számára előre ismert időintervallumban történik - Óra-ütemadó: a) Mind az adó, mind a vevő közös forrásból kapja az órajelet (akkor alkalmazzák, ha kicsi a távolság az adó, és a vevő között) 35. oldal, összesen: 95 b) Mind az adónak, mind a vevőnek saját, de azonos frekvenciával járó óra-ütemadója van. Ezek időben elcsúszhatnak egymástól, ezért egy szinkronjel segítségével hangolják össze a működésüket Értékelése: - Előnye: olcsó, egyszerű a megvalósítása - Hátrány: Az előre ismert idő intervallum hosszát mindig a leglassúbb egység határozza meg ez visszafogja a gyors egységeket (ez kiküszöbölhető többszintű sínrendszer alkalmazásával, ahol átviteli-sebesség függő tartományonként csoportosítják az egységeket) A Bővítősínek fajtái: - Átviteli sebesség szerint (szinkron meghajtású sínek): a)
Kompatibilitási vagy hagyományos sín (~ 5MB/s) b) Helyi sín, pl.: PCI (lehet 132 vagy 264 MB/s) c) AGP 1x (500 MB/s) - Tervezési szempontok szerint: a) Platformfüggő, pl.: ISA, EISA b) Platformfüggetlen, pl.: USB, SCSI, PCI Aszinkron adatátvitel - Fogalma: Az előző elemi művelet befejeződése egyben jelzés a következő elemi művelet kezdetére. - Egyvezetékes (egy vezérlővezeték) a) Adó oldali vezérlés: Először az adat az adatsínre kerül, majd késleltetést alkalmazunk. Hátránya: Az adónak nincs visszacsatolása arról, hogy a vevő valóban elolvasta-e az adatsínre helyezett adatot Lehet, hogy a vevő ki van kapcsolva (Jobbra az alsó ábrán: Data; Data ready) b) Vevő oldali vezérlés: Ez biztonságosabb átvitelt jelent, mert a vevő az átvitel igénylésének pillanatában aktív, de továbbra sincs visszacsatolás az adat célba érkezéséről. (Jobbra az alsó ábrán: Data; Data request) 36. oldal, összesen: 95 - Kétvezetékes
átvitel (handshaking - kézfogás) a) Adó oldali vezérlés: az alsó ábrán Data, Data Ready, Data Acknowledge b) Vevő oldali vezérlés: az alsó ábrán Data, Data Request, Data Ready 37. oldal, összesen: 95 SzA14. A processzor részvételével zajló I/O rendszer (a programozott I/O, a különálló I/O címtér és az I/O port; a memóriában leképezett I/O címtér; működése (feltétlen és feltételes)) I/O Rendszer Programozott I/O DMA A processzor közreműködésével Címzés A processzor működése nélkül Működés Fogalma, jellemzői Működése Különálló I/O címtér blokkos feltételes cikluslopásos feltétlen Programozott I/O Fogalma: minden egyes I/O művelethez a processzornak egy-egy utasítást kell végrehajtania Fajtái címtér szerint: Különálló I/O címtér. - Elve: A processzor két különálló címteret lát. - Jellemzői: a) A címsín szolgál: 1. az operatív tár, 2. és az I/O egység címzésére b) Létezik
olyan vezérlővonal (memória / I/O) mely megmutatja, hogy az adott időpillanatban a címsínen memória vagy I/O cím található c) mivel két különálló címtérről van szó, ugyanaz a cím szerepelhet memóriacímként és I/O címként is. d) Pl.: Intel esetében az eszköz 16 biten címezhető meg (65536 féle I/O cím). 38. oldal, összesen: 95 e) azon regisztereket, amelyeken keresztül a processzor a perifériákkal kommunikálhat, I/O portnak nevezzük, amely fizikailag a vezérlőkártyán helyezkedik el - Az I/O Port regiszterei: a) Parancs (command) regiszter, amelybe a processzor írhatja a kívánságait a perifériákhoz b) Adat (data) regiszter 1. Data input regiszter: ebből olvassa a processzor a perifériától kapott adatokat 2. Data output regiszter: ebbe írja a processzor a periféria számára küldött adatokat c) Állapot (Status) regiszter: innen olvassa a processzor a periféria üzeneteit d) Az input, output regisztereket a mai gyakorlatban
összevonják: parancs állapot regiszter, adat input-output regiszter. e) Napjainkban az I/O porton belül több regiszter is található, pl.: 1. I/O egység működőképességét jelző regiszter 2. I/O egység típusát, konfigurációs jellemzőit tároló regiszter (plug & play) 3. a nagyobb teljesítményű, összetettebb I/O egységeknél több parancs-, adat-, és állapotregiszter lehetséges A különálló I/O címtér megvalósítása: - Következmény: a) Különálló utasítások szolgálnak a memória-műveletekre (pl.: load/store), és b) Különálló utasítások szolgálnak az I/O műveletekre. Pl: Intel esetében 1. inX: a processzor olvassa be az X című I/O port adatregiszterét az AC-ba outX: a processzor beírja az AC tartalmát az X című I/O port adatregiszterébe - Értékelés: a) Előnyei: egyszerű, olcsó a megvalósítása b) Hátránya: a processzor részt vesz az I/O műveletekben szűk keresztmetszet c) az AC szűk keresztmetszetet
jelent nagy tömegű I/O számára 39. oldal, összesen: 95 d) Pl.: Hálókártya (ISA), amely az IBM PC-nél különálló IO címtérrel rendelkezik e) Minden mai piacon lévő processzorban megtalálható A Memóriára leképzett I/O (Memory mapped I/O) Elve: Ezt látja a processzor Processzor Ezt az I/O egység látja Jellemzői: - A megosztás: a processzor memóriakezelő utasítással (load-store) éri el azt a közös memóriaterületet, amit a periféria is kezelhet Ebben az esetben az I/O egység használhatja a rendszersínt nagyobb az átviteli sebesség Megvalósítása: Értékelése: - Jóval gyorsabb, mint a különálló I/O címtér (előny) Minden I/O esetén a processzornak egy utasítást végre kell hajtania (hátrány) Pl.: Az IBM PC-nél a képernyőkezelés Működése: Feltétlen átvitel: - A vevő mindig vételre kész állapotban van - Nem ellenőrizzük az átvitel sikerességét - Nincs szinkronizálás a vevő és az adó között. - Pl.:
LED Feltételes átvitel: - Lekérdezés (wait for flag) a) A processzor beírja a kívánságát az I/O port parancsregiszterébe b) A processzor kiolvassa az I/O egység állapotregiszterének tartalmát c) Amennyiben nem „ready”, akkor vissza a (b) pontra d) Amennyiben „ready”, akkor kiolvassa az I/O egység adott adatregiszterének tartalmát, majd beírja azt az akkumulátorba (AC) Értékelése: A processzor - I/O egység közti sebességkülönbség miatt a proceszszor akár több milliószor olvassa be feleslegesen az állapotregiszter tartalmát 40. oldal, összesen: 95 - Megszakításos: a) A processzor beírja a kívánságát az I/O egység parancsregiszterébe, majd elkezd mást csinálni b) Amikor az I/O egység begyűjtötte a perifériától a szükséges adatot az adatregiszterben: 1. Beállítja az állapot regiszter „ready” bitjét, és 2. Megszakításkérést küld a processzor felé c) A processzor a következő utasítás-töréspontban
elkezdheti a megszakításkérés feldolgozását 1. Beolvassa az I/O egység állapotregiszterét 2. ha ott a „ready” bit be van állítva, akkor egy ennek megfelelő megszakítás-feldolgozó programot indít el; ez kiolvassa az I/O port adatregiszterét és tartalmát átviszi az AC-ba SzA15. A közvetlen memória-hozzáférés (DMA) (fogalma; megvalósítása; működése: blokkos és cikluslopásos üzemmód) Fogalma: nagy tömegű adat gyors periféria alkalmazásával történő átvitele, a processzor közreműködése nélkül Elve: Megvalósítása: DC – decrementer I/O AR – I/O Address Register I/O DR – I/O Data Register 41. oldal, összesen: 95 Működése: - a DMA vezérlő „felprogramozása”: programozott I/O-val átvisszük a processzorból a DMA vezérlőbe az átvitelt leíró alapinformációkat: a) A DC-be beírjuk az átviendő adategységek számát b) Az I/O AR-be beírjuk az átviendő memóriablokk kezdőcímét c) Az adatátviteli egysége
(byte, félszó, szó) d) Az átvitel irányát e) A résztvevő periféria címét, és a DMA vezérlő címét f) Az átvitel módját blokkos vagy cikluslopásos módon - Blokkos vagy (burst) üzemmód (pl.: Winchester esetén memóriacíminkrementálás) a) Mihelyt a DMA vezérlő előkészítette az első átviendő adatelemet az I/O DR-ben, akkor egy DMA request jelzést küld a processzornak. Ezzel kéri a rendszersín használati jogát! b) A processzor DMA acknowledge jelzéssel lemond a rendszersín használati jogáról c) A DMA vezérlő beírja az I/O DR tartalmát az I/O AR által kijelölt memóriacímre, majd a DC értékét csökkenti, az I/O AR értékét növeli d) Ez a ciklus addig fut, míg a DC értéke nullára nem csökken - Cikluslopásos (cycle stealing) átvitel Értékelése: Míg az utasítás-töréspontban a megszakítás feldolgozással a processzorra további munka várhat, addig a DMA töréspontban a DMA vezérlő a processzor helyet dolgozhat.
SzA16. Hagyományos számítógépek felépítése, működése (felépítési vázlat, működés) Korlátaink – jellemzők: - minden utasítás két byte hosszú (256 lehetséges cím): MK címrész 1 byte 1 byte - két egységből áll - Processzor - Memória 42. oldal, összesen: 95 - utasításkészlet: - Összeadó: - ADD 100 AC:=AC+100. ADD [100] AC:=AC+Memo[100] //ez egy memóriahely Inkrementálás AC:=AC+1. Nullázás AC:=0; Betöltés a regbe LOAD [100] AC:=Memo[100]. Kiírás a memóriába STORE [100] Memo[100]:=AC. Feltétlen ugrás JMP 120 PC:=120; o Vezérlőrész PC Memória PC tartalma: 100 LOAD[200] 102 ADD[201] 104 STORE[202] 106 JUMP 120 ALU Címsín MAR A MUX IR MDR DEC Adatsín AC Processzor //azért kettesével növekszik mert 2 byte az utasításhossz I. Utasítás-lehívás (fetch) A PC mindig a következő végrehajtandó utasítás címét tartalmazza. Az utasítás lehívás minden utasítás esetén megegyezik. MAR PC MDR
(MAR) IR MDR PC PC+1 II. Utasítás-végrehajtás (execution) - adatbehívás (load) DEC IR MAR DEC címrész IR MDR PC PC+1 - aritmetikai-logikai utasítás, pl. összeadás DEC IR MAR DEC címrész MDR (MAR) AC AC + MDR vagy AC AC – MDR vagy 43. oldal, összesen: 95 AC AC AC * MDR vagy AC / MDR - adattárolás (store) DEC MAR MDR (MAR) IR DEC címrész AC MDR - a feltételes ugrás DEC PC IR DEC címrész SzA17. Számítógép architektúrák osztályozása (Flynn-féle, illetve korszerű osztályozás) Flynn féle csoportosítás a hatvanas évekből: o Értelmezett fogalmak: SI – Single Instruction Stream: egyetlen vezérlő egyetlen utasításfolyamot bocsát ki MI – Multiple Instruction Stream: a vezérlő több, egymástól elkülönülö folyamatot bocsát ki SD – Single Data Stream: A műveletvégző egyetlen adatfolyamot hajt végre, dolgoz fel. MD – Multiple Data Stream: A
műveletvégzők több adatfolyamot dolgoz fel. o A fogalmak kombinációi: Az architektúrák: SISD: szekvenciális architektúra SIMD: multiple 3D feldolgozás MISD MIMD o Értékelése: Hátránya, hogy nem mutatja Sem a párhuzamosság forrását (adat) Sem pedig a szintjét (szál/utasítás) 44. oldal, összesen: 95 Párhuzamos architektúrák korszerű csoportosítása Adatpárhuzamos Funkcionálisan párhuzamos Vektorprocesszorok Asszociatív és neurális processzorok SIMD Szisztolikus architketúrák Utasításszinten párhuzamos architektúrák Futószalag Szálszinten párhuzamos VLIW (Very Long Instruction Word) Folyamatszinten párhuzamos Szuperskalár Utasításszinten párhuzamos architektúrák (Instruction Level Parallelism – ILP) Az ILP architektúrák fő fejlődési útja Neumann-féle szekFutószalagos venciális architektúra (pipeline) processzo1950 rok 1985 Soros kibocsátás, soros végrehajtás Soros kibocsátás,
párhuzamos végrehajtás Szekvenciális feldolgozás Időbeli párhuzamosság Egyetlen processzorban egyetlen, nem futószalagos végrehajtó egység Futószalagos processzor, több, nem futószalagos végrehajtó egységgel Szuperskalár processzorok 1990 Szuperskalár processzorok MM/3D kiegészítéssel 1994 Párhuzamos kibocsá- Párhuzamos kibocsátás, párhuzamos vég- tás, párhuzamos végrehajtás rehajtás, utasításokon belüli párhuzamosság (SIMD) Időbeli párhuzamos- Időbeli párhuzamosság, kibocsátásbeli ság, kibocsátásbeli párhuzamosság párhuzamosság, utasításon belüli párhuzamosság Több futószalagos MM/3D kiegészítésvégrehajtó egységet sel rendelkező szutartalmazó VLIW és perskalár processzorok szuperskalár processzorok 1. 1950 Neumann-féle szekvenciális architektúra: soros kibocsátás és végrehajtás 45. oldal, összesen: 95 2. 1985: Futószalag processzorok: Időbeli párhuzamosság Megvalósítási technikái: -
Futószalag (időbeli párhuzamosság) - A Többszörözés (térbeli párhuzamosság) A végrehajtó egység szakosodott, pl.: fixpontos / lebegőpontos A futószalag processzorok teljesítményét: - hatékony memória alrendszerrel (gyorsító tárak), és - hatékony ugrás előre jelzéssel juttatták el az ezen az úton elérhető teljesítmény határáig 3. 1990: Kibocsátásbeli párhuzamosság – szuperskalár processzorok - A futószalagos végrehajtó egységeket többszörözték, tehát az időbeli párhuzamossághoz hozzáadódott a térbeli párhuzamosság - Előzmények: o Mivel a többszörözött futószalagelvű végrehajtóegységek óraciklusonként egynél több utasítást is képesek lettek végrehajtani, a soros kibocsátás szűk keresztmetszetet eredményezett. Ennek feloldására vezették be a párhuzamos kibocsátást - Fejlődési irányok: o Statikus ütemezésű VLIW processzorok (egyszerűbb) o Dinamikus ütemezésű szuperskalár processzorok
(bonyolultabb) A szuperskalárok fejlődése - Első generációs szuperskalárok: o Közvetlen (nem pufferelt) utasítás-kibocsátás o Elágazásbecslés o Korszerű memória alrendszer - Második generációs szuperskalárok: o Pufferelt (közvetett) utasítás kibocsátás o Regiszter-átnevezés Ezzel az általános célú programok vonatkozásában kimerültek az ILP processzorokban rejlő teljesítménynövelési lehetőségek (ILP). 4. 1995: Utasításbeli párhuzamosság jellemzi: MM/3D kiterjesztés - A SIMD elv alkalmazásával gyorsul a vektorgrafikus műveletvégzés 46. oldal, összesen: 95 SzA18. Adatfüggőségek (fogalma, főbb fajtái, teljesítmény-korlátozó hatása) Az adatfüggőségek fogalma: Ha egy program két egymást követő utasítása ugyanazt a regiszter-, vagy memória operandust használja, kivéve, ha a közös operandus mindkét utasításban forrás operandus. Az adatfüggőség nyilvánvaló esete az, hogy a soron következő utasítás az
előző utasítás eredményt használja forrás operandusként Amíg egy processzor az utasításokat sorosan hajtja végre, az adatfüggőségek nem okoznak gondot Más a helyzet, ha az utasításokat a processzor párhuzamosan dolgozza fel, mint ILP végrehajtásnál Ilyenkor az adatfüggőségek észrevétele és megfelelő kezelése a processzor elsődleges feladatává válik Az adatfüggőségek főbb fajtái: Adatfüggőség Jellege szerint Soros utasításSzekvenciákon Valós függőség (RAW) Helye szerint Ciklusban Regiszter Memória Álfüggőség WAR WAW RAW-függőség (írást követő olvasási függőség, true dependence). Valamely utasítás forrásoperandusza felhasználja a másik utasítás eredményét i1: load r1, a // r1 <=(a) i2: add r2,r1,r1 // r2 <=(r1)+(r1) Az i2 utasítás az r1 regisztert, mint forrást használja. Így az i2 utasítás mindaddig nem hajtható végre helyesen, míg az i1 utasítás nem hajtódik végre és eredménye nem
áll rendelkezésre Ezért i2 utasítás RAW-függőségben van az i1 utasítástól. A RAW függőségek fajtái Behívási függőség: a kívánt operandust előbb be kell olvasni (r1-be) ahhoz, hogy i2 végrehatható legyen. i1: load r1, a // r1<=(a) i2: add r2,r1,r1 // r2<=(r1)+(r1) Műveleti függőség: ha a keresett operandust a megelőző utasítás aritmetikai, logikai stb. műveletek eredményeként állítja elő i1: mul r1, r4, r5 // r1<=(r4)*(r5) i2: add r2, r1, r1 // r2<=(r1)+(r1) WAR-függőség (olvasást követő írásfüggőség, anti dependence) Valamely utasítás célregisztere megegyezik az előző utasítás forrásregiszterével i1: mul r1, r2, r3 //r1<=(r2)*(r3) i2: add r2, r4, r5 //r2<=(r4)+(r5) 47. oldal, összesen: 95 Ebben az esetben, az i2 utasítás az r2 regiszterbe ír, míg az i1 utasítás r2 tartalmát forrásoperandusként használja. Ha bármely okból i2 előbb hajtódik végre, mint i1, akkor r2 tartalmát i2 korábban
írná át, mint ahogy azt i1 olvasná, és ez nyilvánvalóan hibát eredményezne. WAW-függőség (írást követő írásfüggőség, output dependence) Valamely utasítás célregisztere megegyezik az előző utasítás célregiszterével i1: mul r1,r2,r3 // r1<=(r2)*(r3) i2: add r1,r4,r5 // r1<=(r4)+(r5) A ciklusbeli adatfüggőség: Ciklusokban megjelenő függőségek. Akkor van, ha a ciklusmag valamely utasítása olyan értékre hivatkoznak, amely valamely előző ciklus eredménye Fontos probléma, mivel a futásidőt döntően a ciklusok összideje adja ki (80/20-as szabály) Kezelésük a compiler feladata Pl. do i=2, n x(i)=a(i)*x(i-1)+b enddo Elsőrendű ciklusok Ha a ciklus az őt közvetlenül megelőző ciklus eredményét használja fel. Általános formája: X(i) = a(i) * X(i-1) + b(i) Teljesítmény-korlátozó hatása - valódi adatfüggőség (RAW): ki kell várni, amíg a szükséges adat elkészül. Nem lehet kiküszöbölni - hamis adatfüggőség (WAR,
WAW): csak az ugyanarra a tároló helyre hivatkozás miatti függőség, regiszter átnevezéssel megszüntethető. Valódi adatfüggőség esetén,a teljesítménycsökkenés nem kiküszöbölhető, de csökkenthető, részlegesen feloldható utasítás várakoztatással és eredmény előreküldéssel. SzA19. Regiszter adatokra vonatkozó ál- és valódi adatfüggőségek teljesítmény korlátozó hatásának csökkentése, illetve kiküszöbölése (utasítás várakoztatás, regiszter átnevezés, eredmények előreküldése, három- operandusú utasítások elve) Utasítás várakoztatás: Az utasítás várakoztatás célja az utasítások között fellépő függőségek hatására létrejövő kibocsátási blokkolások megszüntetése. Ezt úgy éri el, hogy a VP felé függőségek vizsgálata nélkül kibocsátja (issue) a dekódolt utasításokat, majd ezek után végez függőség vizsgálatot, a VP-ben lévő utasítások között. A nem függő utasításokat
kiküldi (dispatch) a VE felé Regiszter átnevezés: Az álfüggőségek megszüntethetők, például regiszter operandusok esetén regiszterátnevezéssel. Regiszterátnevezéskor az i2 utasítás célregiszterének nevét kell egy jelenleg nem használt másik névre változtatni: i1: i2: mul r1, r2, r3 => add r2, r4, r5 => i1: mul r1, r2, r3 i2: add r36, r4, r5 48. oldal, összesen: 95 // r1 <= (r2)*(r3) // r36 <= (r4)+(r5) Az álfüggőségek jelentős mértékben akadályozzák az ILP processzorok teljesítőképességének kihasználását. Ezért ezeket vagy a fordítóprogram statikusan, vagy az ILP-processzorok dinamikusan megszüntetik (Pl: részleges RISC 6000, teljes ES/9000) Megvalósítás: minden célregisztert átneveznek, átnevezéseket követni kell források átnevezése, átnevezési tábla, átnevezések érvényességét kezelni kell., r22 tartalmát vmikor be kell írni r1-be. Eredmények előreküldése (result bypassing): Célja a RAW
időbeli negatív hatásainak csökkentése. Elve: a végrehajtó egység által szolgáltatott eredményt nemcsak a regisztertárba vezetik vissza, hanem minden olyan VE bemenetére is, amely ezt az eredményt forrás operandusként felhasználja: add sub r1, r2, r3 r4, r5, r1 // r1<=(r2)+(r3) // r4<=(r5)-(r1) Megvalósítás: FX Hármoperanduszú utasítások elve Bevezették az úgynevezett i=a*b+c szemantikájú utasításokat és ezt nevezték el 3 operandusu utasításnak több különböző néven pl. multiple add Lényege 3 operanduszal végez egyszerre műveletet és két művelet egyidejű végrehajtását szolgálja. Ezeknél az utasításoknál a párhuzamosság mértéke 2 Alkalmazása dedikált célokra hasznos az-az tudományos műszaki számítások Általános programoknál a gyorsítás mértéke elhanyagolható Mivel a 2 operandusú utasítások átnevezése 3 operandusú utasításokhoz vezet, ezért ehhez egy belső utasításformátum konverzió is
szükséges. Cél: regiszterátnevezés megvalósítása (Pl.:ES/9000) SzA20. Vezérlésfüggőségek és teljesítmény korlátozó hatásuk csökkentése (vezérlésfüggőségek fogalma, teljesítmény korlátozó hatása és annak csökkentése, a feltétlen vezérlésátadás, a statikus és dinamikus elágazásbecslés, valamint a spekulatív elágazás-kezelés elve) Vezérlőfüggőség fogalma: Elágazáskor a processzor (ugrás esetén) nem az elágazás utasítás utáni utasítást olvassa be, dekódolja, stb. hanem az ugrás címén találhatót Ehhez feltétlen ugrásnál is címet kell számítani, feltételes ugrás esetén pedig feltétel vizsgálatot is kell végezni Mindez időbe telik és addig az egységek nem tudnak dolgozni (úgynevezett buborék keletkezik). Tehát itt is függ a feldolgozás az előző (elágazás) utasítástól. Feltétlen elágazás – késleltetett ugrás: 49. oldal, összesen: 95 Probléma: MUL JMP címke ADD címke SHL Mivel a JMP
hatására feltétlen ugrás következik be, az ADD utasítás nem hajtódik végre. Nem az ADD hanem az SHL a következő (a JMP utáni) utasítás: - feleslegesen hívjuk le az ADD utasítást, sőt - veszélyeztetjük a regiszter-tartalmakat Kezelése: - utasításrés (buborék) segítségével - Kétfokozatú futószalag: 1 utasításrés - Négyfokozatú futószalag: 3 utasításrés. - n fokozatú futószalag: n-1 utasításrés (a futószalag miatt kell az n-1-edik eredmény a végeredményhez) - Statikusan történik, a compiler által o Egyszerű compiler: minden feltétlen ugrás után beszúr egy NOP-ot (kétfokozatú futószalag esetén) Értékelés: bár felesleges műveletet végzünk (egy ciklus), de már nem veszélyeztetjük a regiszter-tartalmat o Optimalizáló compiler: A compiler a JMP utasítás előtt adatmanipuláló utasításokkal kísérli meg feltölteni az utasításrést Pl.: JMP címke MUL ADD címke SHL Amennyiben az utasításrés
mérete 1 akkor a feltöltés valószínűsége 85%, ha nagyobb, akkor az esély csökken Ezt a megoldást korai RISC processzorok alkalmazták Ezzel megszűnt a ciklus-veszteség is! Elágazások gyakorisága általános célú programokban 20-30%, tudományosoknál 5-10%. Feltételes elágazások gyakorisága általános célú programoknál 20%, tudományosnál 5-10%. Általános célú programok esetén a legtöbb vizsgálat meglepően alacsony gyorsítási lehetőséget mutat, 1.2 – 30 értékek között, 2 körüli átlagértékkel Tudományos programoknál a párhuzamos végrehajtásával elérhető gyorsítás mértéke valamivel nagyobb, 12 – 17 közötti tartományokba esik, 2-4 közötti átlagértékkel Ezeknek az eredményeknek az az oka, hogy a vezérlésfüggőségek erőteljesen behatárolták az utasítások párhuzamos végrehajtását. A feltételes elágazások alapblokkokra tagolják a programot, és a párhuzamosítás alapblokkonként
külön-külön történik (alapblokk-ütemezés). Mivel az alapblokkok viszonylag rövidek (az ütemezéshez csak kisszámú utasítás áll rendelkezésre), az adódó gyorsítás mértéke is alacsony marad. 50. oldal, összesen: 95 Többirányú elágazás: egy feltételes elágazás esetén mindkét lehetséges útvonalat egyidejűleg követik a feltétel kiértékeléséig, majd a feltétel kiértékelése után a helytelennek bizonyult útvonalat elvetik, és a helyes útvonalon folytatják a program végrehajtását. Spekulatív elágazáskezeléssel: A processzor minden függő feltételes elágazás esetén becslést végez a feltétel kimenetéről és az utasítások feldolgozását e becslésnek megfelelően vagy a soros vagy az elágazási ágon folytatja. A feltétel kiértékelése után a processzor ellenőrzi a becslést. Ha a becslés helyes volt érvényesíti a feltételes elágazást követően végrehajtott utasításokat és folytatja a feldolgozást Ha a
becslés hibás volt a feltételesen végrehajtott utasításokat törli és a végrehajtást a helyes ágon folytatja A statikus módszer: a becslést a processzor a tárgykód valamely jellemzőjéből származtatja pl. műveleti kódból az elágazás irányából, vagy a fordító program által adott ajánlásból A dinamikus módszer: az elágazás történetén alapul 1 bites eljárás: a processzor elágazásonként 1 bittel írja le az elágazás történetét. Ez jelzi hogy az elágazás a legutolsó végrehajtáskor bekövetkezet –e vagy sem. 80/20-as szabály Ha az előző ugrás teljesült, akkor a következő is fog. 2 bites eljárás: ha az egyes elágazások leírásához több bit áll rendelkezésre hosszabb lesz az elágazás-történet és így a becslés várhatóan pontosabb lesz. A processzor 2 biten (telített számláló) 4 állapotú véges automata ként tartja nyilván a múltat: 1. 2. 3. 4. 5. 00: határozott soros folytatás (ugrás esetén 01,
nem ugráskor 00 az új állapot) 01: gyenge soros folytatás (ugrás esetén 10, nem ugráskor 00 az új állapot) 10: gyenge elágazás (ugrás esetén 11, nem ugráskor 01 az új állapot) 11: határozott elágazás (ugrás esetén 11, nem ugráskor 10 az új állapot) Alapállapot az 11. SzA21. Szekvenciális konzisztencia (az utasítás-feldolgozás és a kivételkezelés soros konzisztenciája, a precíz megszakítás-kezelés) Szekvenciális konzisztencia Utasításfeldolgozás Szekvenciális konzisztenciája Kivételkezelés Szekvenciális konzisztenciája Utasítás-végrehajtás Memória-hozzáférés Szekvenciális konzisztenciája Konzisztenciája Memória-konzisztencia Processzor-konzisztencia 51. oldal, összesen: 95 Kivétel-konzisztencia Processzor-konzisztencia Probléma: MUL ADD JZ (JMP ZERO) Ha nem figyelünk, akkor a MUL értékére reagál! - Soros feldolgozás esetén, amennyiben az ADD eredménye nulla, akkor ugrik. - Párhuzamos feldolgozás esetén
várhatóan a MUL utasítás fejeződik be később, tehát biztosítani kell, hogy az ugrás továbbra is az ADD utasítás nulla eredménye esetén történjen Kivételek konzisztenciája Gyenge konzisztencia Erős konzisztencia Pontatlan megszakítás-kezelés Pontos megszakítás-kezelés Pontatlan megszakításkezelés: Probléma: MUL ADD JZ - - Párhuzamos feldolgozás esetén várhatóan az ADD utasítás fejeződik be hamarabb, és lehet, hogy pl. túlcsordulással – amennyiben ezt a processzor elfogadja, akkor az állapottere elveszti korrektséget, ami csak kiegészítő eljárásokkal lehet helyreállítani Ennek oka, hogy a korábbi MUL utasítás még definiálatlan s így felborulhat a kivételkezelés soros konzisztenciája Pl.: Power1 (1990) és Power 2 (1993) – csak a lebegőpontos utasításoknál Az Alpha processzorok viszont minden utasításnál Pontos megszakításkezelés - A processzor kizárólag az eredeti utasítás szekvenciának megfelelő
sorrendben fogadja el a megszakításkéréseket - Ehhez általában átrendező-puffert használ, így a processzor csak akkor fogadja el a megszakításkérést, amikor az adott utasítást kiírjuk az átrendező-pufferből. Pl: Az Intel processzorcsalád, és a mai processzorok 52. oldal, összesen: 95 SzA22. Az utasítások időben párhuzamos feldolgozásának alapvető lehetőségei (prefetching, átlapolt utasítás végrehajtás, futószalag elvű feldolgozás, ebből adódó szűk keresztmetszetek (memória sávszélesség és elágazások) feloldása) Futószalagos feldolgozás: - Előfeltételei (két fokozatot figyelembe véve): o Két egymástól teljesen független hardver egységet kell kialakítani o Mindkét egység feldolgozási ideje megegyezik o Az egyik egység kimenete lesz a másik bemenete Időbeli párhuzamosság (átlapolás) Következtetés: Kellően nagy számú utasítás esetén, két hardveregység használva, elvben megduplázódik a feldolgozás
sebessége - El Bontsuk négy részre az utasítás-feldolgozási ciklust: F Fetch D-S/O Decoding – Source Operand E Execution W/B Write Back Ekkor elvben megnégyszereződik az utasítás-feldolgozás sebessége, de a teljesítmény növekedését a függőségek mérséklik! - Előlehívás: Az előző utasítás visszaírási fázisát és az aktuális utasítás lehívási fázisát párhuzamosítjuk o maximum egy óraciklus nyerhetünk, amit a függőségek mérsékelnek o Példa: A hatvanas évek nagyszámítógépeinek egy része A 8086-os mikroprocesszor - Csak a végrehajtás fázisban (futószalag-elvű kialakítás): o Példa: Nagyszámítógépek: a 60-as évek vektorprocesszoros gépei Mikroszámítógépek: ez a fázis kimaradt 53. oldal, összesen: 95 - A teljes utasítás-feldolgozási fázisban o Maximum óraciklusonként tudunk feldolgozni egy utasítás, amit a függőségek mérsékelnek o Példa: Nagyszámítógépek (1960)
Mikroszámítógépek: 80286 A futószalagos feldolgozás következményei - Memóriakezelés: o A memória lassabb, mint a processzor. Hagyományos, szekvenciális elvű 4 ciklusú utasítás: Négyfokozatú futószalag esetén: Míg a hagyományos szekvenciális feldolgozásnál – a példánk esetében – csak minden negyedik óraciklusban kell utasítást lehívni, addig 4 fokozatú futószalagnál már maximum óraciklusonként, amit a függőségek csökkenthetnek. o A memória-alrendszert gyorsításokkal egészítették ki o A gyorsítótárak a 80-as évek második felében terjedtek el robbanásszerűen, a futószalagos feldolgozás terjedésével párhuzamosan - Vezérlés-függőségek: o Az okozott teljesítmény-redukció mértéke: Feltétlen vezérlésátadás esetén az ugrási rés (buborék) mérete N-1, ahol N a futószalag fokozatainak száma Feltételes vezérlésátadás esetén ehhez hozzájön a feltétel kiértékelés, az ugrási cím
számítása és a bonyolultabb dekódolás is o A teljesítmény-csökkenés mérséklése: A korai gépekben hardver-kiegészítéssel lehetővé tették, hogy a dekódolás végére előálljon az ugrási cím A korai RISC gépekben késleltetett ugrást alkalmaztak A CISC gépek esetén megjelent: A fix előrejelzés: A következő végrehajtandó utasítás mindig az ugrási címen helyezkedik el Az ugrási cím előáll a dekódolási szakasz végére, majd folytatják az utasítások lehívását az ugrási címet követően A feltételes vezérlés-átadásokban a feltételek kiértékelése az execution szakasz végén következett be: 54. oldal, összesen: 95 o Az előrejelzés helyes volt s folytatódott az utasítások feldolgozása az elkezdett irányba o Hibás volt, ekkor az elkezdett utasításokat eldobták és elkezdték a feldolgozást a helyes irányba. Pl: 80486 Feloldatlan feltételes vezérlési függőség: amikor a feltétel
nagy késleltetésű (látenciájú) (szorzás, osztás) utasításra vonatkozik, ami nem hajtódik végre a feltételes vezérlésátadási utasítás execution szakaszának végére ezért blokkolódik a feldolgozás. Pl.: a=x/y if a=1 (várnia kell az előzőre) SzA23. A futószalag (pipeline) elvű utasítás-végrehajtás, futószalag processzorok (a futószalag elve; jellemzői; logikai és fizikai futószalagok kiváltott szűk keresztmetszetek és feloldásuk) Futószalag (pipeline) => Gyakorlati vonatkozás: T – egy termék elkészülésének időtartalma. t – egy egység mennyi ideig van egy munkaállomáson Egyszerre n db készül! (t időközön- ként egy termék) n – futószalagon lévő egységek száma A futószalagos feldolgozás jellemzői 1. A fokozatok száma: A függőségek miatt sok utasítást kell eldobni! - Pl.: 1980, RISC I. – kétfokozatú, 1982, RISC II – háromfokozatú, napjainkban 15 – 20 fokozat 2. Újrafeldolgozás
Újrafeldolgozás nélkül: Újrafeldolgozással, pl.: szorzás, osztás esetén igen hosszú lenne, ha a részeredményeket műveletenként kimentenénk a regiszterekbe Helyette a részeredményeket az E fokozat végéről visszavezetjük az E fokozat bemenetére. (elemi műveletek sorozata) 3. Operandus-előrehozás 55. oldal, összesen: 95 4. Szinkron – aszinkron: napjainkban szinkron az elterjedt A futószalag logikai felépítése 1. szint: A futószalagok funkcionális meghatározása pl.: 2. szint: az egyes fokozatok által végrehajtandó elemi műveletek pl.: Fetch MAR ← PC MDR ← (MAR) IR ← (MDR) PC ← PC+1 A futószalagok fizikai felépítése - általános fizikai felépítés 1960-80 90-es évek (itt jelenik meg a többszörözés): 56. oldal, összesen: 95 - fizikai megvalósítás: o Univerzális futószalag: minden logikai futószalagot egyetlen fizikai futószalagon valósítunk meg, Pl.: RISC I o Master futószalag (Pentium I.): Két futószalag
közül: Az egyik minden utasítás végrehajtására alkalmas, A másik csak az egyszerűbb utasítások végrehajtására képes o Dedikált futószalag, pl.: ProwerPC 604 FX összetett: szorzás, osztás. Képes az újrafeldolgozásra Soros konzisztencia (CO): A konzisztencia biztosítja, hogy az utasítások az eredeti sorrendjüknek megfelelően kerüljenek kiírásra. CISC – RISC futószalagok: A CISC futószalagok jellemzően hosszabbak: - A címszámító fokozat illetve, - A gyorsítótár-elérés miatt SzA24. Szuperskalár processzorok megjelenése (az ötlet megjelenése, kísérleti és a kezdeti kereskedelmi rendszerek áttekintése, elterjedésük) A szuperskalár kibocsátás ötletét TJADEN és FLYNN már 1970-ben publikálta, de az elv pontosabb megfogalmazására csak jóval később, a ’80-as években került sor (TORN, 1982, ACOSTA és mások, 1986). A szuperskalár elnevezés egy IBM technical report-ban látott napvilágot 1987-ben (Super-Scalar
kísérlet), az elnevezés feltehetőleg a korabeli fejlesztésekkel (America, RS/6000) kapcsolatban született. Az IBM hatalmas előnyt és tapasztalatot szerzett azzal, hogy 1982-ben a Cheetah projektet, majd 1985-ben az America projektet útjára indította. A Cheetah szolgált az America alapjául, melyből később az RS/6000 nőtte ki magát (1990), melyet később Power 1-re keresztelték át. A DEC szintén fontos szerepet játszott a szuperskalár fejlesztések területén Multititan elnevezésű szuperskalár projektje révén, melynek fejlesztési munkái 1985-87 között folytak. Az azóta ismertté vált Alpha sorozat azonban nem ebből született, hanem egy későbbi, teljesen új, 1988-as RISCy VAX kódnevű projektből. Említést érdemel még két további fejlesztés 1988-89 környékén, a Stanford University és a japán Kyushu University projektjei. 57. oldal, összesen: 95 Projektek: The designation "superscalar" Cheetah project IBM America
project (4) Multititan (2) DEC Stanford U. MATCH (2) Kyushu U. SIMP (4) 1982 1987 1983 1988 1989 TORCH (2) DSNS (4) 1990 1991 A szuperskalár CISC-processzorok csak jelentős késéssel jelentek meg a piacon. Ennek oka a RISC-ekhez képest nagyobb bonyolultságban rejlik, mely két okra vezethető vissza. Először is, a RISC-ekkel szemben, a CISC-processzoroknak változó hosszúságú utasításokat kell dekódolnia. Másodszor, a memória architektúrájú CISC-processzorok csak sokkal nagyobb ráfordítással valósíthatók meg, mint a behívó/tároló (LOAD/STORE) architektúrájú RISCprocesszorok Megjelenésük a kereskedelmi rendszerekben: RISC processors Intel 960 960KA/KB M 88000 MC 88100 960CA (3) MC 88110 (2) HP PA PA 7000 PA7100 (2) SPARC MicroSparc SuperSparc (3) R 4000 MIPS R R 8000 (4) 29040 29000 sup (4) Am 29000 Power1(4) RS/6000 IBM Power 21064(2) DEC PPC 601 (3) PPC 603 (3) PowerPC 88 89 90 91 92 93 94 95 CISC
processors i486 Intel x86 Pentium(2) M 68040 M 68000 M 68060 (2) Gmicro/100p Gmicro Gmicro500(2) AMD K5 K5 (4) CYRIX M1 M1 (2) Denotes superscalar processors. 58. oldal, összesen: 95 A szuperskalárok megjelenése két csoportra bontható: Az egyik út a már meglévő (skalár) RISC-processzorcsaládok átkonvertálása volt szuperskalár családokká szuperskalár modellek bevezetésével. Pl: Intel 960, MC88000 és Sun Sparc processzorcsaládok. A másik út, eleve szuperskalár feldolgozást feltételező, új architektúrájú processzorcsaládok kifejlesztését jelentette. Pl: IBM RS/6000 (Power 1), a DEC Aplha proceszszorai, vagy a Power PC processzorcsalád SzA25. Első generációs (keskeny) szuperskalár processzorok áttekintése(közvetlen kibocsátás, végrehajtási modelljük, kibocsátási szűk keresztmetszetük) Jellemzői: - Közvetlen (nem pufferelt) utasítás-kibocsátás. - Statikus elágazásbecslés: o A programkód jellemzői
alapján történik az írás becslése o Pontosabb, mint a fix előrejelzés - A memória-alrendszer kétszintű gyorsítótárat tartalmaz: o L1: A processzorlapkán helyezkedik el Külön adat- és utasítás-gyorsítótár egyportos o L2: Külön lapkákon helyezkedik el Közös gyorsítótár az adatok és az utasítások számára A processzorsínre csatlakozik Közvetlen utasítás-kibocsátás: Megvalósítása: Utasítás-puffer Működési alternatívák: - Az utasítások sorrendiségének tekintetében o Sorrendben történő kibocsátás: a függő utasítások blokkolják az utasításkibocsátást 59. oldal, összesen: 95 o Sorrenden kívül történő kibocsátás: a függő utasítások nem blokkolják az utasítás-kibocsátást - Az utasítás-ablak feltöltése: o Az utasításokat egyenként pótoljuk o Az utasítások ablak teljes kiürülése után az egészet pótoljuk Tipikus példa az első generációs szuperskalárra: -
Sorrendben történő utasítás kibocsátás - Az utasítás-ablak teljes kiürülése után a teljes feltöltése - Az utasítás-ablak 3 db utasítást tartalma - Jelölés: Az i-edik ciklusban egyetlen utasítás tudunk kibocsátani, mert az i2 blokkolja a további utasítás kibocsátást. Az i+1 ciklusban időközben feloldódott az i2 függősége, ezért kibocsátható mind az i2, mind pedig az i3. Az utasítás-ablak ezáltal teljesen kiürül Az i+2 cikusban teljesen feltöltjük az utasítás-ablakot, és két független utasítást tudunk kibocsátani. Az első generációs szuperskalár RISC processzor működési modellje - Az utasítás feldolgozási rendszert alrendszerekre tudjuk bontani, és ezeket külön vizsgálhatjuk - Értelmezhetjük a rendszer átbocsátó-képességét (rátáját, szélességét) 60. oldal, összesen: 95 - A teljes utasítás-feldolgozási rendszer átbocsátási rátáját a legszűkebb keresztmetszetű alrendszer átbocsátási
rátája határozza meg Az egyes alkalmazások utasítás-mixe sajátos és távol áll az utasítás feldolgozásának szempontjából ideális utasítás-mixtől minden alkalmazásnak más az átbocsátási rátája Kibocsátási szűk keresztmetszet Kezeljük a: o Behívási függőségeket gyorsítótárakkal o A vezérlés-függőségeket statikus elágazás-becsléssel Az adatfüggőségek (a valódi és álfüggőségek) okoznak főképpen teljesítménycsökkenést o A tipikus példákból láthatjuk, hogy a 3 utasítás-szélességű ablakból nem mindig sikerül kibocsátani 3 utasítást, a függőségek miatt o A gyakorlatban: RISC esetén 2-3, CISC esetén 2 utasítás feldolgozása történik óraciklusonként o Tehát az első generációs szuperskalárokat keskeny szuperskalároknak nevezzük Jellemző megvalósítások: - Viszonylag általános célú 2 db futószalag (Pentium I) - 2-4 db dedikált futószalag (Alpha 21064) SzA26. Második generációs
(széles) szuperskalár processzorok áttekintése(a kibocsátási szűk keresztmetszet kiküszöbölése: dimnamikus utasítás-ütemezés és regiszter-átnevezés, végrehajtási modelljük, értékelésük) Jellemzői: - Dinamikus utasítás-ütemezés - Regiszter-átnevezés Dinamikus utasítás-ütemezés (részei): - Pufferelt utasítás-kibocsátás - Sorrenden kívüli utasítás-végrehajtás 61. oldal, összesen: 95 Megvalósítása: Működés: - Kibocsátási puffereket alakítottak ki - A kibocsátás során nem történik semmiféle függőség-ellenőrzés (adat, vezérlés, erőforrásfüggőséget sem) - A várakoztató-állomásokban addig tartózkodnak az utasítások, amíg függetlenné nem válnak - Minden óraciklusban ellenőrzésre kerül a várakoztató állomásokban levő összes utasítás függőség szempontjából, és az összes független utasítás kiküldésre kerül, mégpedig sorrenden kívül. - Az utasításablak több tucat utasítást
tartalmaz rendkívül kiszélesedett, azaz eltűnt a kibocsátási szűk keresztmetszet Regiszter-átnevezés: - Lényege: minden eredmény-regiszter átnevezésre kerül. Kezeli ennek következményeit is: o Amennyiben később forrásregiszterként hivatkozunk rá, akkor az átnevezési regisztert fogja használni o Amikor egy utasítás-feldolgozás a befejeződött, akkor átmásolja az átnevezési regiszter tartalmát az architekturális regisztertárba, és felszabadítja az átnevezés regisztert. o Hibás elágazásbecslés esetén az átnevezési regiszterek alapján történik a visszajátszás; kezeli a kivételeket is. - A második generációs szuperskalároknál jelent meg, pl.: PowerPC 603 (1993), PentiumPro (1995), Alpha 21264 (1998) 62. oldal, összesen: 95 A második generációs szuperskalár RISC gépek végrehajtási modellje Működése: - Az első rész feladata az utasításablak feltöltése - A forrás-operandusok lehívása architektúrától
függően lehet: o kibocsátáshoz kötött vagy o kiküldéshez kötött - A kiküldés során a független utasításokat sorrenden kívül tölti ki - A végrehajtás során az átnevezési regiszterekbe kerülnek az eredmények - Visszaíráskor az eredmények az utasítások eredeti sorrendjében másolódnak át az átnevezési regiszterekből az architekturális regiszterekbe Sávszélesség: - Kibocsátás ráta: 4 utasítás / ciklus - Kiküldési ráta: 5-8 utasítás / ciklus - Végrehajtási ráta: még magasabb Oka: - Bizonyos végrehajtó egységek nem képesek minden ciklusban utasítást fogadni (a bonyolultabb utasítások miatt) - Az utasítás-mix az egyes alkalmazásoknál nem egyezik meg a végrehajtható egységek eloszlásával CISC gépek: - A CISC processzorok belsejében RISC magot alakítottak ki - A CISC utasítások lefordítják RISC utasításokká - Egy CISC utasításból átlagosan 1,2-1,5 RISC utasítás keletkezik. Mivel a bonyolult CISC
utasításokat elhagyták, ezért ezeket valahogy helyettesíteni kell. Pl: for ciklus esetén (bonyolult utasítás): egy if, egy inkrementálás, egy goto és egy ciklus vége utasítás szükséges. - Óraciklusonként ~3 CISC utasítás kerül lehívásra, tehát 3 x (1,2-1,5), azaz ~4 db RISC utasítás kerül kibocsátásra 63. oldal, összesen: 95 Adatfolyam modell: - Mivel a függőségeket kezeljük csak műveleti és a behívási függőség feloldását kell kivárni - Mihelyt a bemenő operandusok rendelkezésre állnak, a kiküldés elvben bekövetkezhet (erőforrás-függőség lehetséges), s a végrehajtó egység azonnal működésbe lép (adatmeghajtott elv) SzA27. Harmadik generációs szuperskalár processzorok: az utasításon belüli párhuzamos végrehajtás áttekintése (három-operandusú utasítások, SIMD-utasítások, VLIW-architektúrák) Utasításon belüli párhuzamosság Duál-műveletes utasítások SIMD Multimédia (fixpontos) VLIW 3D
(lebegőpontos) A logikai architektúra kiterjesztése Teljesen új logikai architektúra Duál műveletes utasítások: - Fogalma: egyetlen utasításban kettő darab művelet - Pl.: X=a*b+c (A szorzatok eredményét c-ben felgyűjtjük) LOAD/OP (Betöltés után azonnal elvégzi a műveletet is) - A 70-es években jelentek meg - Numerikus feldolgozásoknál használják, de az általános célúaknál nem jellemző SIMD: - Fogalma: egyetlen utasításban ugyanazon művelet több operanduson van értelmezve - Fajtái: Fixpontos: ~ 2-8-szoros gyorsítás Lebegőpontos: 2-4-szeres gyorsítás - Ez képezi a processzorok fejlődésének fő irányvonalát: ~ 1994-től - Sajátosságai: o A logikai architektúra módosítást igényel o Az L2 gyorsítótár felkerül a processzor lapkájára o A rendszer-architektúra is módosul: megjelenik az AGP (Accelerated Graphics Port) VLIW: - Fogalma: egyetlen utasításokban sok műveletet írunk elő - Korai VLIW-ek: o Igen hosszú
utasítások, pl.: a TRACE VLIW processzor esetén: 256-1024 bites utasítások 7-28 műveletet tartalmaz o A statikus ütemezés során a compiler gondoskodik a függőségek feloldásáról 64. oldal, összesen: 95 o A compiler szoros kapcsolatban áll a fizikai architektúrával, pl.: ismernie kell a végrehajtó egységek számát, azok késleltetését, a behívási késleltetést, stb. o A 80-as évek első felében papíron, második felében a piacon is megjelentek (pl.: TRACE) o Gyorsan leállt a forgalmazásuk, mivel a compiler túlságosan kötődött a fizikai architektúrához - Mai VLIW-ek: o A compilerek fejlődtek, ezért a 90-es évek végén újra megjelentek o Szerverek piaca: INTEL Itanium: 6 db végrehajtó egységgel rendelkezik A szuperskalárok 4 db / ciklus feldolgozási rátáját kívánják a 6 db végrehajtó egységgel túlszárnyalni o Hordozható gépek piaca: a Transmeta cég processzorai: A statikus ütemezés egyszerűbb
processzort eredményez kisebb áramfogyasztás (2W DVD-lejátszás közben!) Fajtái: 4 db végrehajtó egységgel 8 db végrehajtó egységgel 65. oldal, összesen: 95 Számítógép architektúrák záróvizsga-kérdések 2 SzA28. 2 és 3 generációs szuperskalár processzorok tervezési tere (a tervezési tér főbb komponensei) Szuperskalár processzorok tervezési tere Utasítás lehívás Dekódolás Utasítás kibocsátás Utasítás végrehajtás Szekvenciális konzisztencia megőrzése Kivételkezelés 1. Utasítás lehívás: feladata a következő utasítás címének átadása az utasítás cache-nek 2. Dekódolás: minden órajelben több utasítást bocsát ki egyszerre, ezért párhuzamos dekódolásra van szükség 3. Szuperskalár utasítás kibocsátás: Magasabb utasítás kibocsátási ráta nagyobb teljesítményt eredményez, de egyben erősíti a vezérlési és adatfüggőségek teljesítmény-visszafogó hatását is. Ennek
mérséklésére különböző kiküldési politikákat (dispatch policy) alkalmaznak, mint például shelving, regiszter átnevezés, spekulatív elágazás kezelés. 4. Párhuzamos végrehajtás: a szuperskalár feldolgozás alapfeltétele 5. Szekvenciális konzisztencia biztosítása: az utasítások párhuzamosan hajtódnak végre, de szekvenciális logika szerint 6. Kivételkezelés: A szekvenciális konzisztenciát a kivételkezelésnél is biztosítani kell Dekódolás: 1) Elődekódolás a) Van b) Nincs Utasítás kibocsátás: 1) Kibocsátási politika a) Kibocsátási mód Direkt Pufferelt b) Kibocsátás sorrendje Sorrendi Sorrenden kívüli c) Kibocsátás illesztése Fix ablakos Csúszó ablakos d) Függőségek kezelése Vezérlés függőségek 66. oldal, összesen: 95 • Spekulatív • Nem spekulatív Ál-adatfüggőségek • Van regiszter át nevezés • Nincs regiszter át nevezése 2) Kibocsátási ráta SzA29.
Utasításlehívás (főbb feladatok, a címképzés általános sémája, az ugrási cím meghatározása, a BTIC és a BTAC eljárás elve, példák) Főbb feladatok: Elődekódolás azaz elágazás becslés Elágazási címszámítása Feladata a következő utasítás címének átadása az utasítás cache-nek (I$). Ez skalár processzoroknál, amelyek nem tartalmaznak elágazásbecslést a PC-vel történik, IPC (Initial PC) vagy BTA (Branch Target Address) segítségével. Mivel csak egy utasítást hív le, ez nem jelent gondot. A szuperskalár processzorok 4 utasítás/ciklus lehívását végzik, ha nem lenne elágazásbecslés, akkor az jelentős teljesítménycsökkenéshez vezetne A szuperskalárok IFA-t (Instruction Fetch Address) használnak, IIFA (Initial IFA) vagy BTA segítségével a címmeghatározáshoz. A BTA-t elágazásbecsléssel (branch prediction) határozzák meg A címképzés általános sémája Szuperskalár elágazásbecsléssel: 67. oldal,
összesen: 95 Az ugrásí cím meghatározása: Az elágazási ág elérésének módszerei Kiszámítási lehívási módszer BTAC BTIC A köv. lehívási címre mutató index Kiszámítási lehívási módszer elve: Elágazás észlelésekor a processzor előbb kiszámítja az elágazási címet (BTA) majd a soros ágon következő utasítás címét felülírja vele. Így a kiszámított elágazási cím lesz a következő utasítás címe (IFA). A következő ciklusban a processzor behívja az utasítás gyorsítótárból az elágazási címen lévő célutasítást (BTI). Pl 486, Power1, PowerPC 601 Elágazási címpuffer BTAC: BA 1000 BA 1000 BTA 9879 A BTAC a legutoljára végrehajtott elágazási utasítások címeit (BTA) és a vonatkozó elágazási címeket (BA) tartalmazza. Ha az aktuális utasítás behívási cím (IFA) egy elágazási utasítás címe (BA) és ehhez bejegyzés található a BTAC-ben akkor a proc. miközben az utasítás gyorsító tárból
beolvassa az elágazási utasítást a BTAC-ből egyidejűleg az elágazási címet is kiolvassa A következő ciklusban a proc ezt a címet használja az elágazási célutasítás eléréséhez Pl. Pentium, PA8000, PowerPC 604, 620 Célutasítás puffer BTIC: BA BTI1 címx ut1 BTI2 ut2 BTI3 ut3 BTI4 ut4 BA A BTIC módszer elve abban az esetben ha a BTIC-ben az elágazási ág folytatásának címe (BTA+) is el van tárolva. A BTIC az utolsó teljesült elágazások címeit, a hozzájuk tartozó célutasításokat, valamint a folytatási címeket tárolja. Amikor az aktuális utasítás behívási címhez tartozik egy bejegyzés aBTIC-ben akkor a proc. A következő utasítást a BTIC-ből és nem az utasítás gyorsítóárból hívja le majd dekódolja. Egyúttal a proc a BTIC-ből kiolvassa az elágazási ág soron következő utasításának címét (BTA+) is. A következő utasítást a proc erről a címről hívja le. Pl Hitachi Gmicro/200 A BTIC módszer elve abban az
esetben ha a BTIC-ben az elágazási ág folytatási címét a proc. számítja ki. A BTIC az utolsó teljesült elágazások címeit (BA), és a hozzájuk tartozó elágazási ágak első két utasítását tárolja (BTI, ill BTI+1) Ha az aktuális utasításlehívási címhez (IFA) a BTIC-ben tartozik bejegyzés akkor a processzor a következő két utasítást nem az utasítás gyorsítótárból hanem a BTIC-ből hívja le. Az elágazási ág soron következő utasítás behívási címét (BTA+) a proc az elágazási címből számítja ki annak inkrementálásával Pl Am 29000, MC88110 68. oldal, összesen: 95 SzA30. Dekódolás (alkalmazott eljárások áttekintése, párhuzamos hagyományos dekódolók, elődekódolás, a trace cache használata, példák) Dekódolási lehetőségek: Hagyományos dekódolók, Elődekódolók (prefetching): L2-ből hozzák be az utasítást 2G AMD Trace cache: eltárolja a dekódolt utasítást Mivel a szuperskalár
processzorokat jellemzően több utasítás kibocsátása jellemzi, ezért a párhuzamos dekódolás itt egy komplexebb feladat, mint az egyszerű skalár processzorokban. Magasabb kibocsátási ráták esetén túlzottan megnőhet a dekódolási ciklus hossza vagy ez a dekódolás továbbfejlesztése nélkül oda vezethet, hogy egy dekódolási ciklus helyett a processzornak két vagy több ciklusra lesz szüksége. Skalár processzoroknak ciklusonként csak egyetlen utasítást kell dekódolnia, ezen felül ellenőriznie kell, hogy a kibocsátandó utasítás függ-e a végrehajtás alatt állóktól és így kibocsátható-e. A szuperskalár processzor ennél összetettebb Minden ciklusban több, általában négy utasítást kell egy időben dekódolni, ezen felül meg kell vizsgálnia, hogy a kibocsátás alatt álló utasítások függenek-e a jelenleg végrehajtás alatt állóktól, illetve, hogy van-e függőség a következő ciklusban kibocsátásra váró utasítások
között. Mivel a szuperskalár processzorban több végrehajtó egység is van, ezért ezek a függőség vizsgálatok sokkal több összehasonlítást jelentenek, mint a skalárokban. Összességében tehát a kibocsátási ráta növelésével nő a dekódolás komplexitása Ez nyilván a teljesítményben mutatkozik meg Hagyományos: A hagyományos dekódolás egy egyszerű párhuzamos dekódolás. Ezt az első generációs RISC-ek és a későbbi CISC processzorok használják. A második generációs CISC proceszszorokban többnyire egy RISC magot valósítottak meg Ilyenkor a dekódolás során a CPU előtt egy CISC-RISC konverziót végez, melynek során egy CISC utasítást RISC utasítások sorára bontja. Pentium Pro-ban 16 bájt töltödik fel a dekóderekben Ezekből az 1 elfogad bármilyen CISC utasítást, ami maximum három RISC utasítással dekódolható. A másodikharmadik, egyszerű dekóder viszont csak egy RISC utasítással dekódolható CISC-eket fogad el (pl
load vagy egy regiszter operáció). Akkor van tehát hármas feltöltés, ha az utasítás legfeljebb három RISC utasítással dekódolható és rögtön utána két olyan utasítás jön, melyek egy-egy RISC utasításokkal dekódolhatóak. Ez nagyon ritkán fordul elő A komplexebb utasításokhoz egy mikor-utasítás ROM tartozik, mely ciklusonként három utasítást bocsát ki Ezek felváltva dolgoznak, vagyis vagy a három alapdekóder működik vagy a mikro-utasítás ROM. Az AMD K6 processzorának egy nagyon hasonló dekódere van. Ebben a három alapdekóder mellett egy ún. vektor dekóderrel találkozunk, mely gyakorlatilag megegyezik a Pentium Pro mikro-utasítás ROM-jával. Az Athlon (K7) abban különbözik az előzőektől, hogy a három alapdekóder teljesen egyenrangú: 69. oldal, összesen: 95 A dekódolás után a kibocsátáshoz egy visszaalakítást végez. Ennek során összeláncolják az egy CISC utasításhoz tartozó RISC utasításokat, és csak
együtt engedik őket kibocsátani (ROB). Elődekódolás A növekvő kibocsátás hatásának csökkentésére a szuperskalár processzorokban bevezették az elődekódolás folyamatát. Az utasítás cache feltöltésekor az L2 cache (vagy ennek híján a memória) és az utasítás cache közé egy hardware egység kerül, mely utasításokhoz RISCeknél 4-7, CISC-eknél 2-5 bitet fűz hozzá. Egyszerre 128 bit jön le az L2 cache-ből Ez tehát még a feltöltéskor történik, így nem jelent időkritikus műveletet. Az elődekódolás megjelenése jellemzően 1995-re tehető, vagyis a második generációs rendszereknél, mivel itt nőt meg a kibocsátási ráta, itt vált szükségessé ennek a technikának a bevezetése. Ez nem sokkal az első generációs rendszerek megjelenése után jött, 2-3 évvel ezek bevezetése után. Rohamos elterjedésük elsősorban annak köszönhető, hogy az ilyen technikákkal kapcsolatos tervek hamar kikerülnek a titok köréből, így
többnyire egyszerre tudnak kijönni a gyártók az új megoldásokkal. A többlet bitekre jellemző, hogy elsősorban CISC rendszereknél terjedtek el és az idő előrehaladtával csökkentek (pl K8-ban már csak 2 bit). Trace cache: Jellemzően az Intel P4-ben, vagyis egy harmadik generációs CISC rendszerben jelent meg. Lényege az a felismerés, hogy az utasítások kb. 80%-át a ciklusok végrehajtása jelenti, így azonos utasítások folyamatos lehívásával és dekódolásával felesleges műveleteket végzünk. Ötlet: a dekódolt utasításokat tárolni kell, s a ciklusok végrehajtását a tároltak lehívásával gyorsítani. SzA31. Az elődekódolás megvalósítása (szükségessége, elve, szükséges többletbitek száma, felhasználása, példák) Szükségessége: A skalár processzoroknak ciklusonként csak 1 utasítást kell dekódolnia. Ezen felül ellenőriznie kell azt is, hogy a kibocsátandó utasítás függ-e a végrehajtás alatt állóktól, és így
kibocsátható-e Ezzel szemben a szuperskalár processzor feladata sokkal összetettebb 70. oldal, összesen: 95 Minden ciklusban általában több, pl 4 utasítást kell egy időben dekódolni. Ezen felül kétféle függőségvizsgálatot is el kell végezni, egyrészt meg kell vizsgálni, hogy a kibocsátásra váró utasítások függetlenek-e a jelenleg végrehajtás alatt állóktól, illetve, hogy vannak-e függőségek a következő ciklusban kibocsátásra váró utasítások között. Mivel a szuperskalár proceszszorokban általában több VE van, mint a skalár-ban, a végrehajtás alatt álló utasítások száma is általában sokkal nagyobb, mint a skalár-nál. Ez azt jelenti, hogy a függőségvizsgálatok során jóval több összehasonlításra van szükség Elve: Cél: idő csökkentése, órajel frekvencia növelése. A dekódolási feladatok egy részét a processzor már aközben végrehajtja, mikor az utasításokat a másodszintű L2 cache-ből vagy a
memóriából az utasítás, L1 cache-be írja. Szükséges többletbitek száma és felhasználása: Az elődekódoláshoz használt bitek száma RISC processzorok esetében általában 4-7 bit, melyek a következő jellegű információkat hordoznak: • • • melyik feldolgozó egységhez kell tenni = az utasítás milyen osztályba tartozik (milyen típusú) végrehajtáshoz szükséges erőforrások típusa elágazás detektálás, néha BTA kiszámítása A CISC processzorok esetében további többletinformációkat is tartalmazhatnak, például egy utasítás hol kezdődik és hol végződik. Az AMD K5 processzora pl minden byte-hoz 5 bitet fűz (+60%!). Példák: Először 1995-ben jelentek meg elődekódolást használó szuperskalár processzorok: PA-7200 (1995), PA-8000 (1996), PowerPC 620 (1995), R10000 (1995), UltraSparc (1995), AMD K5 (1995). Gyakorlatilag azonnal elterjedt Az egyes meghatározó processzorcsaládok legújabb tagjai rendszerint már használják,
viszont néhány nagyon elterjedt processzor ugyanakkor nem használ elődekódolást, pl. Pentium Pro, PII, PIII 71. oldal, összesen: 95 SzA32. Utasítás várakoztatás I (célja, elve, függőség vizsgálat tartalma, tervezési terének áttekintése) Utasítás várakoztatás célja és elve: Az utasítás várakoztatás célja az utasítások között fellépő függőségek hatására létrejövő kibocsátási blokkolások megszüntetése. Ezt úgy éri el, hogy a várakoztató állomások felé függőségek vizsgálata nélkül kibocsátja (issue) a dekódolt utasításokat, majd ezek után végez függőség vizsgálatot, a várakoztató állomásban lévő utasítások között A független utasításokat kiküldi (dispatch) a végrehajtó egység felé. Függőség vizsgálat tartalma: (Spekulatív elágazás kezelés és regiszter átnevezést feltételezve.) A spekulatív elágazás kezelés megszűnteti a feloldatlan vezérlésfüggőségek következtében
fellépő kibocsátási blokkolódásokat, míg az átnevezéssel az ál-adat függőségek, azaz a WAR és WAW függőségek és a miattuk előálló kibocsátási blokkolódások küszöbölhetőek ki. Így az utasítások kiküldése során függőségvizsgálat már csak a RAW adatfüggőségek vizsgálatára korlátozódik. Tervezési tere: Várakoztatás A várakoztatás hatóköre A várakoztató pufferek megvalósítása Operandusz lehívási politikák Az utasítás kiküldés módja Várakozatás hatóköre: • Néhány utasításra terjed ki a várakoztatás • Minden utasításra terjed ki a várakoztatás Várakoztató pufferek megvalósítása: Várakoztató pufferek megvalósítása A várakoztató pufferek típusa A várakoztató pufferek kapacitása Csak várakoztató állomás Egyedi VÁ Csoportos VÁ Ki és bemeneti kapuk száma Kombinált pufferek várakoztatásra utasítás átrendezésre és regiszter átnevezésre is szolgál Központi VÁ
Operandus lehívási politikák: Kibocsátáshoz kötött operandus lehívás: az operandusokat a processzor az utasítások kibocsátása alatt hívja be. Ebben az esetben a várakoztató pufferek a forrásoperandusok értékeit tárolják 72. oldal, összesen: 95 Kiküldéshez kötött operandus lehívás: az operandusokat a processzor az utasítások kiküldése alatt hívja be. Ebben az esetben a várakoztató pufferek a forrásregiszterek azonosítóit tárolják. Utasítás kiküldés módja: Utasítások kiküldési módja Kiküldési politika Kiküldési sorrend Kiküldési ráta Üres várakoztató állomás kezelése Döntési szabály Kiválasztási szabály Az operandusok rendelkezésre állása megállapításának módja Sorrendben történő Részben sorrenden Sorrenden kívüli kívüli kiküldés kiküldés kiküldés SzA33. Utasítás várakoztatás II (utasítás várakoztató pufferek megvalósítási alternatívái, operandus lehívási
politikák, értékelésük) Utasítás várakoztató pufferek megvalósításai: Várakoztató pufferek megvalósítása A várakoztató pufferek típusa A várakoztató pufferek kapacitása Csak várakoztató állomás Egyedi VÁ Csoportos VÁ Ki és bemeneti kapuk száma Kombinált pufferek várakoztatásra utasítás átrendezésre és regiszter átnevezésre is szolgál Központi VÁ Várakozó állomás (Csak várakoztató pufferek): Egyedi: minden egyes végrehajtó egységnek saját puffere van Példa: AMD K5, PowerPC 620 (ábra – 7.102) Ráfordítás: nagy Teljesítmény: az egyik pufferből a másikba nem lehet utasításokat áttenni Kapacitás: 2-4 hely Csoport: az azonos típusú (pl. FX) VE-ek egy közös pufferből táplálkoznak Ehhez nyilván nagyobb pufferre van szükség. Ez a tendencia Példa: Pentium 4, Athlon, Opteron, R10000 (ábra – 7.100): két buszon keresztül történik az utasítások kiküldése. Az egyik a
fixpontoshoz, a másik a FP és gyökvonáshoz Az FP osztás 20-40 ciklusig tart. Ez egy buszról táplálva, nem hoz érdemi 73. oldal, összesen: 95 teljesítménycsökkenést, mivel a FP utasítások aránya 10% még a műszaki programokban is. Teljesítmény: bármelyik VE-be kerülhetnek a várakozó utasítások Kapacitás: 8-20 Központi: Minden VE egyetlen pufferből táplálkozik, ezért nagy kapacitásúra van szükség. Példa: Pentium Pro, P2, P3 (ábra 7.105) Pentium Pro: egy 20 elemű központi állomás szolgálja ki mind a 10 VE-t. Egy buszon keresztül lassú egységeket látnak el: +/ FP/*. Ráfordítás: a pufferméret csökkenthető az egyedihez képest. Nagyobb ráfordítású, de nem gyorsabb, mint a csoport típusú. Teljesítmény: az FP VE nem tudja végrehajtani az FX-et, és fordítva Kapacitás: 20 fölött Kombinált pufferek: A várakoztatáson kívül egyéb funkciókat is ellát: o Várakoztató és átnevező o
Várakoztató és átrendező o Várakoztató, átrendező és átnevező Operandusz lehívási politikák: Kibocsátáshoz kötött operandus lehívás: Azt jelenti, hogy a processzor az operandusokat az utasítások kibocsátásakor hívja le, vagyis akkor, amikor azok a dekódolás után bekerülnek a várakoztató pufferekbe. Ilyenkor ezek a forrás operandusok értékeit tárolják elsősorban. A processzor a kibocsátás során a forrás operandusok regisztereinek azonosítóját a regisztertárba továbbítja a hivatkozott operandusok behívása céljából. A várakozó állomásba bekerül a dekódolt műveleti kód, a célregiszterek azonosítói, valamint a behívott operandus értékek. A behívás során a processzornak ellenőriznie kell, hogy a hivatkozott regiszter értékek rendelkezésre állnak-e Ha nem, akkor az azt jelenti, hogy egy már végrehajtás alatt álló utasítás célregisztere a hivatkozott forrásregiszter, vagyis a két utasítás között RAW
adatfüggőség van (ahogy már korábban említettem, regiszterátnevezés és spekulatív elágazás kezelés mellett a processzornak a várakoztató pufferekben csupán a RAW függőségeket kell vizsgálnia). Az operandusok rendelkezésre állásának eldöntéséhez érvényességi biteket alkalmaznak (scoreboarding) Ennek során a regisztertárban minden regiszterhez egy további bitet rendelünk, mely érvényességi bitként funkcionál (V bit – valid bit). Egy utasítás kibocsátása során annak célregiszterének érvényességi bitjét a processzor mindig 0-ba állítja mindaddig, amíg az utasítás végrehajtása be nem fejeződik és az eredmény vissza nem íródik a regisztertárba. A várakozó állomásokban is elhelyeznek a forrásoperandusok mellé egy-egy ilyen érvényességi bitet Amikor a processzor lehívja a forrás operandusok értékeit, ellenőrzi, hogy a hozzájuk tartozó érvényességi bit a regisztertárban be van-e állítva. Ha igen, akkor a
kiolvasott értéket beteszi a pufferben a megfelelő helyre és 1-es ír az operandus mellé érvényességi bitnek. Amennyiben nincs beállítva ez a bit, akkor a hivatkozott forrásregiszter azonosítóját írja be a pufferbe és mellette 0-s érvényességi bittel jelzi, hogy az adott érték egy regiszter azonosító és nem az operandus értéke Miután a vezérlőegység elvégezte a rá bízott műveletet, az előállított eredménnyel frissíteni kell mind a regisztertárat, mind a várakoztató puffereket. Ekkor a célregiszter azonosítóját, mint asszociatív címet felhasználva előbb kikeresi a regisztertár megfelelő helyét, majd a várakoztató pufferekben is frissíti azon forrás regiszter értékeket, ahol az érvényességi bit 0 és 74. oldal, összesen: 95 mellette a regiszter azonosító a most előállított eredmény célregiszter azonosítójával egyezik meg. Itt fontos megjegyezni, hogy a várakoztató pufferek frissítése globális művelet,
vagyis minden olyan várakoztató pufferbe továbbítani kell az eredményt, amelyben a létrehozott eredményre várakozó utasítások lehetnek. I-buffer D e c o d e /I s s u e So ur c e r e g. n um b e r s Issue R e g . f ile O p c o d e s, d e st in a t io n r e g . n u m b e r s So ur c e 1 o p e r a n ds So ur c e 2 o p e r a n ds R S R S RS E U E U E U Kiküldéshez kötött operandus lehívás: Azt jelenti, hogy a processzor a várakoztató pufferekbe a kibocsátás során csak a forrás regiszterek azonosítóit teszi be és a konkrét értékeket csak akkor hívja le, amikor az utasításokat a vezérlőegység felé kiküldi. Kiküldés során fordul tehát csak a regisztertárhoz, így csak a regisztertárban szükséges érvényességi biteket eltárolni. Amennyiben mindkét forrás operandus érvényességi bitje 1 a regisztertárban, úgy az adott utasítás kiküldhető Amennyiben bármelyik is 0, függőség lépett fel, így az utasítás nem küldhető ki
Ennek a megvalósításnak a másik következménye, hogy az eredmény előállásakor nincs szükség a várakoztató pufferek aktualizálására sem. I-buffer Deco de/Issue In st ruct io n s Disp at ch RS RS RS So urce regist er n um bers Op. co des, dest inat io n reg. n um bers Reg. file So urce 1 o p eran ds So urce 2 o p eran ds EU EU EU Értékelésük: - A kiküldéshez kötött kibocsátás előnyösebb az időkritikus dekódolás/kibocsátási fázis szempontjából, mivel nem tartalmaz regiszterolvasást - A kiküldéshez kötött lehívás esetén a VP-ek sokkal kisebb méretűek lehetnek, mivel a regiszterazonosítók lényegesen kevesebb helyet igényelnek 75. oldal, összesen: 95 - A hivatkozott forrásoperandusok rendelkezésre állásának ellenőrzése tekintetében a kibocsátáshoz kötött előnyösebb, mivel a VP-ben lévő érvényességi bitek értékeinek ellenőrzése sokkal egyszerűbb feladat, - A kimenő kapuk számát tekintve bonyolultabb
az összehasonlítás, általában a kiküldéshez kötött operandus behívási politika igényel kevesebb olvasási kaput SzA34. Utasítás kiküldés I (tervezési tere, kiküldési szabály (dispatch rule) értelmezése, kiküldési sorrend alternatívái, trendje, példák) Tervezése tere: Utasítások kiküldési módja Kiküldési politika Kiküldési sorrend Kiküldési ráta Üres várakoztató állomás kezelése Döntési szabály Kiválasztási szabály Az operandusok rendelkezésre állása megállapításának módja Sorrendben történő Részben sorrenden Sorrenden kívüli kívüli kiküldés kiküldés kiküldés Kiküldési politika: milyen módon válasszuk ki az utasítást a végrehajtáshoz, és hogyan kezelje a kiküldési blokkolást. Kiküldési ráta: definiálja az egy ciklusban a várakozó pufferekből kiküldhető utasítások számát Operandusok rendelkezésre állásának megállapítási módja: az utasítások kiküldhetők-e járulékos
késés nélkül vagy sem. Üres várakoztató puffer kezelése: el kell döntenünk, hogy egy üres várakozó állomás elkerülhető-e Kiküldési szabályok értelmezése: Kiválasztási szabály. Ez határozza meg, hogy a várakoztató pufferekben tárolt utasítások mikor minősülnek végrehajthatónak. Amennyiben a processzor fejlett utasítás-kibocsátást alkalmaz (regiszterátnevezés + spekulatív elágazás-kezelés) ennek eldöntése arra a vizsgálatra korlátozódik, hogy az utasítás forrásoperandusai rendelkezésre állnak-e. Döntési szabályra akkor van szükség, ha a továbbíthatónál több alkalmas utasítás áll rendelkezésre. Általánosságban elmondhatjuk, hogy ahány szabad vezérlőegységhez kapcsolódik egy várakoztató puffer, annyi végrehajtható utasítás előállítása jelent optimális működést ciklusonként, hiszen ekkor biztosítható az, hogy minden ciklusban, minden vezérlőegység valamilyen hasznos munkát végezzen. Ha ennél
több végrehajtható utasítás szerepel a pufferben, akkor dönt a döntési szabály. A legtöbb processzor ilyenkor egy nagyon egyszerű döntést hoz: a „legidősebb” utasítást küldi ki. Kiküldési sorrend alternatívái: A kiküldési sorrend szabja meg azt, hogy egy nem végrehajtható utasítás megakadályozza-e a sorban következő végrehajtható utasítás vagy utasítások kiküldését. 76. oldal, összesen: 95 Ha sorrendben (in-order) küldi ki az utasításokat, egy nem végrehajtható utasítás a pufferben meggátolja a soron következő utasítást vagy utasításokat a kiküldésben, vagyis blokkolódás jön létre. Ez nyilván csökkenti a teljesítményt, ugyanakkor csökkenti a komplexitást is, mivel elegendő csupán a várakoztató puffer utolsó elemét leellenőrizni. Ha részben sorrenden kívül (partially out-of-order) küldi ki az utasítást, akkor kismértékű teljesítménynövekedés érhető el. Ez jelentheti azt is, hogy a sorrenden
kívüli kiküldést csak bizonyos típusú vezérlőegységeknél alkalmazza, de azt is jelentheti, hogy csak egy nem kiküldhető utasítást tud átlépni. Például a Power2 csak a lebegőpontos utasításokat várakoztatja, és kiküldéskor csak egyetlen nem végrehajtható lebegőpontos utasítást tud átlépni. Ha sorrenden kívül (out-of-order) küldi ki az utasításokat, mely a leghatékonyabb eljárás egyike a három közül. Itt egy nem végrehajtható utasítás nem blokkolja a várakoztató pufferben sorban következő végrehajtható utasítások kiküldését A legkorszerűbb processzorok ezt a kiküldési módot alkalmazzák, bár az IBM360/91 is implementálta már. Ennek oka egyszerű: a mai architektúrák többnyire csoportos vagy központi várakoztató puffereket alkalmaznak, melyeknél több vezérlőegységhez egy várakoztató puffer kapcsolódik. Ilyenkor, ha a blokkoló sorrendben kiküldést alkalmazná a processzor, az jelentős
teljesítménycsökkenéshez vezetne. Trendek és példák: Egyértelműen a sorrenden kívüli kiküldés felé mutat. A csoportos vagy központi várakoztató állomást használó processzoroknál ez szinte követelmény, különben rendkívüli teljesítménycsökkenés következne be. Sorrendi kiküldés: IBM Power1, PowerPC 603. Részben sorrendi kiküldés: IBM Power2, PowerPC 604. Sorrenden kívüli kiküldés: Pentium Pro, R10000. SzA35. Utasítás kiküldés II (a kiküldött utasítások multiplicitása, forrás operanduszok meglétének vizsgálati elvei, üres várakoztató pufferek kezelése) Kiküldési ráta: A várakozó puffereknek minden ciklusban el kell tudni látnia minden hozzárendelt EU-t utasítással. Ennek megfelelően: Egyedi várakoztató állomás: csak 1 utasítás kiküldésére képes ciklusonként, csak saját EU-ját kell ellátnia Csoport várakoztató állomás: több utasítás kiküldésére is alkalmasnak kell lennie, de a
kiküldendő utasítás típusától is függ a kiküldési ráta. Egyszerű utasítás (R10000, load/store): esetén 2, bonyolultabb utasítás (R10000 FX, FP, div, mul) azonban csak 1. Központi várakozató állomás: ciklusonként több (P6-nál 5) utasítást is kell tudnia küldeni, de ezek megvalósítása összetettebb Forrás operandoszok meglétének vizsgálati elvei: Közvetlen ellenőrzés (kiküldéshez kötött): nincsenek konkrét állapotbitek, melyek jeleznék az operandusok jelenlétét, így külön meg kell vizsgálni azokat. Az RS-ben csak az opcode-t és a hivatkozott forrás és célregiszterek számát tárolják. A regiszter elérhetőségét egy a register file-ban lévő scoreboard jelzi. Minden regiszternél még egy validity bit Ha egy regisztert valamelyik utasítás használja V bitje 0 Ha eredmény megérkezett és beíródott, akkor V=1 lesz. A regiszterek hozzáférhetőségét ezzel a bittel ellenőrzik Komplex logika, több ezer komparátor.
77. oldal, összesen: 95 Állapotbitek vizsgálata (kibocsátáshoz kötött): az operandusok meglétét külön erre a célra definiált állapotbitek jelzik Az RS-ben az opcode mellett a hivatkozott forrásregiszterek értéke és a hozzáférhetőségüket jelző státusz bitek mellett a célregiszter számát tárolják. V=1 esetén a regiszter tartalma, V=0 esetén csak a hivatkozott regiszter száma van az RS-ben. Decoded instructions Decoded instructions RS1, RS2 , RD OC RS1 RS2 Update R D, set V-bit Reset V-bit of R D RD V Check V-bits of source operands Reservation Station Reg. file Scoreboard bits RS1, RS2, RD Update R D, set V-bit Reset V-bit of R D V Reg. file Associative update of I S1, I S2 with R D1 set Reservation Station Check the status bits (VS1 , V S2) related VS-bits OS1 OC, OS1 , OS2 , R OC OS1 /I S1 VS1 OS2 /I S2VS2 R D OS2 Scoreboard bits OC, OS1, OS2 , RD D EU EU Result, R D Result, R D Üres várakozó pufferek kezelése:
Egyszerű kezelés (straightforward): ha egy utasítás egy üres pufferhez ér, akkor az adott ciklusban beíródik a pufferbe, és csak a következő ciklusban lesz kiküldve, így egy egész ciklust fölöslegesen várakozik a pufferben (Pl.: Nx586) Hatékonyabb megoldás a kikerülés (bypassing): ha az utasítás üres pufferhez érkezik, akkor „kikerüli” azt és még az adott ciklusban kiküldésre kerül, így nincs fölösleges várakoztatás (Pl.: Power PC604) SzA36. Regiszter átnevezés I (statikus, dinamikus átnevezés, a megvalósítás elve és a főbb feladatok utasításvárakoztatást feltételezve, kibocsátáshoz kötött operandusz lehívás esetén) Statikus átnevezés: Statikus átnevezés: Az átnevezésre fordításkor kerül sor, a regisztereket a fordítóprogram nevezi át (korai futószalag-processzorok, szuperskalár processzorok párhuzamosan optimalizáló fordítóprogramjai). Dinamikus átnevezés: Dinamikus átnevezés: Az átnevezésre futási
időben kerül sor, és a processzor végzi el. Ehhez jelentős többlethardverre van szükség, ezért később is jelent meg. Elsőként az IBM valósította meg részlegesen (Power1, Power2), majd az IBM és a Motorola teljes körűen (PowerPC, Power3, MC 88110). Ma már gyakorlatilag minden fejlett processzor alkalmazza 78. oldal, összesen: 95 Regiszter átnevezés megvalósítási elve és főbb feladatai utasítás várakoztatást és kibocsátáshoz kötött operandusz lehívás esetén: Az utasítások kibocsátásakor a processzornak át kell neveznie mind a kibocsátott utasítás célregiszterét, minden a forrásregisztereket, majd be kell olvasnia a forrásregiszterek tartalmát. A célregiszterek átnevezése állandó, mindig megtörténik, forrásregisztert azonban csak akkor kell átnevezni, ha korábban a processzor már átnevezte. Az operandus értéket betöltése során a gyakorlatban a processzor egyszerre fordul a regiszterazonosítóval mind az
architektúrális, mind az átnevező tárhoz. Amelyik eredményt szolgáltat, azt használja fel Ha mindkettő egyszerre küld eredményt, úgy általában az átnevező puffertár adatát használja fel. Az utasítások kiküldésekor a várakozó pufferekben az érvényességi bitek ellenőrzése. Ha az utasítás kiküldhető vagyis végrehajtható, akkor várakozó pufferek a szabad VE-k felé továbbítják. Amikor a végrehajtóegység létrehozta az eredményt, mint a várakozóállomást, mind az átmeneti puffertárat frissítenie kell. Itt az a különbség a várakoztatásnál megismertekhez képest, hogy célregiszternek egy átnevező puffer azonosítót használ, és ezzel címzi a várakozóállomás olyan forrásoperandusok után kutatva, mely a kapott eredményre várnak. Ezt követően frissül az átnevező puffertár tartalma. Az architektúrális regisztertárhoz ilyenkor nem nyúl a processzor, mivel minden célregisztert átnevez, vagyis minden eredményt az
átnevező puffertárba kell írni. Az utolsó feladat (az utasítás befejezésekor) a már nem használatos puffertár elemek visszanyerése. Erre akkor van lehetőség, ha az adott puffere a processzornak már nincs szüksége Ez két esetben lehetséges: ha egy utasítás egy olyan célregiszterre hivatkozik, amelyiket már átneveztek, de még nem zárult le a végrehajtás, a korábbi átnevezésre már nincs szükség, hiszen azt az eredményét felül fogja írni az éppen átnevezés alatt álló utasítás. A másik eset, amikor befejeződik az utasítás végrehajtása, visszaíródik az architektúrális regisztertárba az adat. 79. oldal, összesen: 95 SzA37. Regiszter átnevezés II (a megvalósítás elve és a főbb feladatok utasítás várakoztatást feltételezve, kiküldéshez kötött operandusz lehívás esetén) Regiszter átnevezés megvalósítási elve és főbb feladatai utasítás várakoztatást és kiküldéshez kötött operandusz lehívás esetén:
Az utasítások kibocsátása során a processzornak át kell neveznie a célregisztert, valamint a forrásregiszterek közül azokat, amelyeket már korábban átnevezett. Az operációs kód, a forrás (címei)- és cél regiszterek a VÁ-ba kerülnek. Az utasítások kiküldésekor a processzor elvégzi hivatkozott forrás operandusok érvényességi bitjeinek vizsgálatát a VÁ-ban, majd a végrehajtható utasításokat továbbítja a szabad VEkbe. A hivatkozott forrás operandusok beolvasása vagy az ÁPT-ből (Átnevező puffer tár) vagy az ART-ből (Arch. Regiszter Tár) Amikor előáll az eredmény a végrehajtóegységben, a processzor frissíti az átnevező puffertár tartalmát. Itt nincs szükség a várakozóállomások frissítésére, mivel azok csak azonosítókat és nem adatokat tárolnak A már nem használt pufferek felszabadítása (utasítás befejezésekor) itt kicsit bonyolultabb feladat, mint a kibocsátáshoz kötött esetben. Amikor ugyanis a processzor
visszaírja az architektúrális regisztertárba az eredményt, előfordulhat, hogy a várakozóállomások még tartalmaznak olyan utasítást, amelyek forrásoperandusa az átnevezett regiszterre hivatkozik. En- 80. oldal, összesen: 95 nek megoldására bevezethetünk egy számlálót, amelyet inkrementál a processzor, valahányszor egy forrásoperandus hivatkozik az átnevező pufferre és csökkenti a számláló értékét, amikor ennek az utasításnak a végrehajtása befejeződött. Ha a számláló újra eléri a nulla értéket (vagyis minden olyan utasítás végrehajtása befejeződött, amelynek valamelyik forrásoperandusa hivatkozott a pufferre), akkor a puffer felszabadítható és újra fel lehet használni átnevezésre 81. oldal, összesen: 95 SzA38. Regiszter átnevezés III (tervezési tere, a regiszter átnevezés kiterjedése (scope), átnevező regiszterek megvalósítási alternatívái) Tervezési tere: Regiszterátnevezés Átnevezés hatóköre
részleges Átnevező pufferek megvalósításának módja Átnevezési ráta teljes Átnevező pufferek típusa Összevont architektúrális és átnevező regiszter Regiszterleképzések megvalósítása Önálló átnevező regiszter Átnevező pufferek száma Átnevező pufferek megvalósítása ROB- ban Átnevezések nyilvántartási módja Átnevező pufferek megvalósítása DRIS- ben Nyilvántartás átnevező pufferekben Nyilvántartás leképző táblában A regiszter átnevezés kiterjedése (scope): A szuperskalár processzorok megjelenésekor még nem alkalmazták a regiszterátnevezést. Elterjedésükkor néhány processzorban nevezették a részleges átnevezést. Ilyenkor a folyamat csak egy vagy néhány utasítás típusra korlátozódik. Ilyen volt pl a Power1 (FP behívó) vagy a Power2 (összes FP). Később elterjedt a teljes átnevezés, melynek során valamennyi utasításnál alkalmazzák az átnevezést, mely egy adatregiszter tartalmát
módosítja A trend a teljes átnevezés felé mutat. Átnevezések nyilvántartási módjai: Asszociatív átnevező tábla (rename buffer) -- Nyilvántartás átnevező pufferekben Ez esetben a pufferek három információt tárolnak: a célregiszterek azonosítóját, értékét és bizonyos állapotinformációkat. Amikor egy utasítás célregiszteréhez átnevező puffert kell allokálni, a processzor keres egy szabad bejegyzést, lefoglalja és a célregiszter azonosító mezőbe beírja az architektúrális regiszter sorszámát. Az eredmény a puffer indexe lesz. A mechanizmus sajátossága, hogy egy regiszterhez több puffert is lehet rendelni. Ez akkor fordulhat elő, ha egy utasítás célregisztere megegyezik egy már átnevezett regiszterrel. Indexelt átnevező tábla (mapping table) -- Nyilvántartás leképző táblában Ebben az esetben az aktuális leképzéseket a processzor egy táblában tartja nyilván, mely az architektúrális regiszter
azonosítójával címezhető, és számon tartja az 82. oldal, összesen: 95 egyes architektúrális regiszterekhez hozzárendelt átnevező pufferek indexét. Az átnevezés során a processzor létrehoz ebben a táblában egy bejegyzést. Ekkor a célregiszterhez hozzárendel egy átnevező puffert és a célregiszter számának megfelelő táblasorba beírja ennek indexét Átnevező regiszterek megvalósítási alternatívái: Összevont architektúrális és átnevező regisztertár: (Power 1,2, R10000, P4) Ebben az esetben a processzor egy közös regisztertárat tartalmaz, melyek elemei dinamikusan vagy architektúrális regiszterek vagy átnevező pufferek. Összevont átnevező regiszterek állapot-átmenet diagramja: Külön átnevező regisztertár: (PowerPc 603,604,620) Csak az átnevezésre szolgál. FX-re és FP-re külön RRF és ARF van Önálló átnevező regiszterek állapot-átmenet diagramja: 83. oldal, összesen: 95 Átnevező pufferek
megvalósítása ROB-ban: (AMD K5,K6, PPro,PII,PIII) Párhuzamos végrehajtás esetén mindenképpen szükséges, hogy a processzor az állapotteret a soros konzisztenciának megfelelően módosítsa. Ennek megvalósítására egy átrendező buffert alkalmaznak. Ennek a buffernek minden eleme egy utasítás Ezt hívjuk ROB-nak. A regiszterátnevezést meg lehet valósítani ebben a ROB-ban is. Ilyenkor az utasítás mellé elmentjük annak célregiszterének tartalmát is, így amikor a ROB-ból a soros konzisztencia szerint kikerül az utasítás, meg lesz a proceszszornak az az információ is, hogy mivel módosítsa a regisztertár tartalmát Átnevező pufferek megvalósítása DRIS-ben: (csak elvi megoldás): A kombinált várakoztató pufferben valósítják meg az átnevező puffereket. Ilyenkor a várakoztató állomás tartalmazza a regiszterátnevezéshez szükséges többlet információkat. Átnevezési ráta: A ciklusonként átnevezhető utasítások maximális
számát jelenti. Mivel kibocsátáskor a kibocsátási korlátok elkerülése érdekében a processzornak minden ciklusban képesnek kell lennie minden kibocsátott utasítás átnevezésére, az átnevezési rátának meg kell egyeznie a kibocsátási rátával. SzA39. Regiszter átnevezés IV (a leggyakrabban használt átnevezési eljárások áttekintése) A leggyakrabban használt átnevezési eljárások áttekintése: Összevont architektúrális és átnevező regiszter, nyilvántartás leképző táblában, kiküldéshez kötött operandus lehívás: Power1, Power2, R10000, Pentium4, K7-FP (Athlon) Önálló átnevező regiszter, nyilvántartás átnevező pufferekben, kibocsátáshoz kötött operandus lehívás: PowerPC 603, 604, 620 Átnevező pufferek megvalósítása ROB-ban, nyilvántartás leképző táblában, kiküldéshez kötött operandus lehívás: Pentium Pro, Pentium II, Pentium III Átnevező pufferek megvalósítása ROB-ban, nyilvántartás
átnevező pufferekben, kibocsátáshoz kötött operandus lehívás: AMD K5 Átnevező pufferek megvalósítása ROB-ban, nyilvántartás átnevező pufferekben, kiküldéshez kötött operandus lehívás: AMD K6, K7-FX 84. oldal, összesen: 95 SzA40. Szuperskalár processzorok mikroarchitektúrájának megvalósítási alternatívái (a processzorok főbb megvalósítási alternatíváit meghatározó szempontok, megvalósítási alternatívák áttekintése) A processzorok főbb megvalósítási alternatíváit meghatározó szempontok: A mikroarchitektúra magjának felépítését alapvetően 2 jellemző határozza meg: az utasítás várakoztatás és a regiszterátnevezés megvalósítási módja. Az utasításvárakoztatás tervezési teréből két összetevő maradt, mely szignifikáns a fejlett szuperskalár processzorok mikroarchitektúrájának megvalósítása szempontjából. A VP-ek típusa, és a használt operandus behívási politika A
regiszterátnevezés tervezési teréből egyetlen kvalitatív tervezési szempont veendő figyelembe, ez pedig a választott ÁP-ek típusa. Spekulatív elágazásbecslés módja (van vagy nincs). Szekvenciális konzisztencia megvalósításának módja A megvalósítási alternatívák áttekintése: Shelving Reservation station Individual RS Issue bound Group RS Dispatch bound 2. Nx586 1. 3. Power1 Fig. 10/1 Fig. 10/2 9. PPC603 10. 17. Am 29000 18. Central RS Issue bound Dispatch bound PM1 4. ES-9000 Fig. 10/3 11. Power2 R10000 Alpha 21264 Pentium 4 Athlon (FP) Issue bound 5. 12. Shelving within the ROB Dispatch bound 6. 13. Fig. 10/6 14. Power3 19. supersc. K5 Fig. 10/10 Fig. 10/11 20. Issue bound 7. Fig. 10/5 Fig. 10/4 PPC604 PPC620 Fig. 10/9 Combined buffers Dispatch bound Issue bound Dispatch bound 8. Fig. 10/7 15. Shelving and renaming within the ROB Fig. 10/8 16. PA-8000 PA-8200 PA-8500 21. 22. Athlon (FX) Pentium Pro
Pentium II Pentium III Fig. 10/12 Fig. 10/13 Fig. 10/14 23. 24. Lightning K6 Fig. 10/15 85. oldal, összesen: 95 Fig. 10/16 SzA41. Fontosabb szuperskalár processzorok mikroarchitektúrájának áttekintése (a Pentium Pro, a Pentium 4, a K6, az Athlon (K7) és az Opteron (K8) mikroarchitektúrájának főbb jellemzői) A Pentium Pro mikroarchitektúrájának főbb jellemzői Szuperskalár CISC proci RISC maggal Nincs elődekódolás BTAC a BTA kiszámításához (BTB) Kibocsátási ráta: 3, kiküldési ráta 5 20 bejegyzéses központi várakoztató állomás Sorrenden kívüli kiküldés Kibocsátáshoz kötött operandusz lehívás Soros konzisztenciát ROB biztosítja ROB-ban megvalósított átnevező regiszterek Gyenge memória, erős processzor konzisztencia A Pentium 4 mikroarchitektúrájának főbb jellemzői Elődekódolás mikroarchitektúra szinten, trace cache BTAC a BTA kiszámításához (BTB) 20 fokozatú
futószalag Mikrocode ROM L1 data-cache (8k, 4 utas) L2 data-cache (256 kbyte, 8 utas) Dedikált, csoport várakoztató állomás Sorrenden kívüli kiküldés Kiküldéshez kötött operandusz lehívás Összevont architekturális és átnevező regiszterek Gyenge memória, erős processzor konzisztencia A K6 mikroarchitektúrájának főbb jellemzői Elődekódolás BTIC a BTA kiszámításához Kombinált várakozó állomás Kiküldéshez kötött operandus lehívás Átnevezés és várakoztatás (ROB-ban) Gyenge memória, erős processzor konzisztencia A K7 (Athlon) mikroarchitektúrájának főbb jellemzői Elődekódolás, 3 BTAC a BTA kiszámításához (BTB) Dedikált, csoport várakoztató állomás Sorremden kívüli kiküldés Kiküldéshez kötött operandusz lehívás Összevont architekturális és átnevező regiszterek lebegőpontosnál ROB-ban megvalósított átnevezés fixpontosnál
Makro utasítások kezelése Gyenge memória, erős processzor konzisztencia 86. oldal, összesen: 95 Az Opteron mikroarchitektúrájának főbb jellemzői elődekódolás, predecode cache BTAC a BTA kiszámításához dedikált, csoport várakoztató állomás out-of-order dispatch kiküldéshez kötött operandusz lehívás összevont architekturális és átnevező regiszterek lebegőpontosnál ROB-ban megvalósított átnevezés fixpontosnál gyenge memória, erős processzor konzisztencia SzA42. Többszálas processzorok (megjelenésük szükségessége, megvalósítási alternatívák és értékelésük, példák) Megjelenésük szükségessége: Nem kikerülhető fejlődési fokozat Soros proc (i286(1982)), Futószalagos proc (i386 - i486), szuperskalár (Pentium, Pentium Pro) Az általános célú programokban az utasításszintű párhuzamosság kimerült a: • multimédia támogatással (PII), illetve • a
multimédia + 3D támogatással (PIII, PIV) A dedikált növelés is kimerült A következő lépcsőfokot a hardveresen többszálú architektúrák jelentik Technikák: Egyszálas: egyetlen utasításfolyamban a processzor már kimeríti a rendelkezésre álló párhuzamosságot (párhuzamosan feldolgozható utasítások – utasításfolyam) Többszálas: több szál egyidejű futtatása A processzorok fejlődése (2) (jelen és jövő) Egyszálas technika Többszálas technika Utasításfolyam Több szál Egyetlen utasításfolyamban a processzor már kimeríti a rendelkezésre álló párhuzamosságot (párhuzamosan feldolgozható utasításokat) IBM Power4 (2001) Pentium 4 Prestonia (2002) Pentium 4 Northwood (2002) 3.06 GHz-től Megvalósítási alternatívái: Többmagos egyszálas: egy lapkán két vagy több processzor-maggal A cache-ekben osztoznak, a megvalósítás az egyes rendszerekben eltér Egy mag egy szálat dolgoz fel, közös
cache Értékelés: 87. oldal, összesen: 95 o Többlethardver: 60-70%-kal több o Többletteljesítmény: 50-60% általános célú alkalmazásokban Többszálas egymagos: egyetlen többszálas processzor-maggal SMT, pl. kétszálas mag: ezen belül tesznek különbséget az állapotok között, pl külön regiszterkészlettel Értékelés: Többlethardver: 5%-kal több Többletteljesítmény: erősen alkalmazásfüggő: -10-20%-tól +20%-ig (zavarhatják egymást) Az egyprocesszoros rendszerekben a disszipáció okozza a korlátot. Két mag 200W+, léghűtéssel érdemben nem kezelhető. A többmagos technikához csökkenteni kell a disszipációt. Többszálas több magos: a kettő ötvözése Példák: Többmagos egyszálas IBM Power4: kétmagos UltraSparc IV Sun Niagara: 8 mag, 4 szál,2006-7 (5 futószalag fokozat, egyszerű magok) AMD Opteron Dual Intel két Prescott maggal: Tulsa Többmagos egyszálas HT helyett,
Pentium M-mel. Kétmagos VLIW Itanium: két szálat kezel Egymagos többszálas Intel Hyperthreading, ami megfelel az SMT-nek = Symmetrical MultiThreading A feldolgozás keverve történik, a jelzőbitek kezelik az állapotmódosításokat Szimmetrikus, a kettő között nincs különbség Többmagos többszálas Power5: AS/400 és OS/400 összehozva, a Power5 már mindkét célra alkalmas (konvergencia), kialakult a virtuális technika, logikai particionálás (a hardver erőforrásokat futás közben kezeli). Figyeli a kihasználtságokat, átcsoportosítani is képes. Dinamikus allokáció 88. oldal, összesen: 95 Többszálas processzorok jelene és jövője Egymagos többszálas IBM Sun Többmagos egyszálas Többmagos többszálas Power4 Power5 (2001) dual core (2004) dual core/2T 0.13 /276 mtrs UltraSparc V UltraSparc IV (2006) dual core/2T 0.09 (IH 2004) 2*USIII 0.13 /66 mtrs Opteron AMD (4/05) dual core 0.09 /233
mtrs Athlon 64 X2 (06/05) dual core 0.09 Intel Pentium 4/HT (11/2002) 2T 0.13 /55 mtrs Smithfield (Pentium D) (5/05) dual core 0.09 Pentium EE 840 (4/05) 2T 0.09 /230 mtrs Complexity SzA43. Rendszerarchitektúrák I (fejlődésük főbb állomásai, processzor buszok fejlődése, a frekvencianövelés korlátja és annak feloldása) Rendszerarchitektúrák fejlődésének főbb állomásai: • ISA alapú • PCI alapú o Straightforward o IDE/ATA és USB–vel o AGP, IDE/ATA és USB-vel • Port alapú - ISA a buszvezérlő gondoskodik a memória és a billentyűzet kezeléséről minden kártyákon keresztül valósul meg (ISA based system architectures) - Straight forward PCI-based system architecture A vezérlés kettéválik, északi és déli híd, amelyek a PCI-on keresztül kapcsolódik Északi: L2 és memóriakezelés, itt nagyobb sávszélesség szükséges A perifériák PCI vagy ISA buszra is kialakíthatók, jellemzően 4-5 PCI
slot és 2-3 ISA - PCI-based system a with IDE/ATA and USB ports A déli híd a vinyók kezelését, két csatorna, négy eszköz, és néhány usb-s rendszer Megmarad az ISA, de a a sebessége miatt a PCI dominál - PCI-based system a with AGP, IDE/ATA and USB ports ISA a háttérbe szorul (1 vagy semennyi) - Ports-based Szinte minden portokon keresztül kapcsolódik a rendszerhez, az ISA nem 89. oldal, összesen: 95 tartozék, csak egy hídon keresztül csatlakoztatható (opcionális) A PCI is elvesztette jelentőségét, mivel minden a déli hídhoz kötődik Super IO: keyb, ms, fd, sp, pp, ir AC ’97 FPM-EDO-SD RAM - Soros buszokat és portokat használó rendszerarchitektúra Az FSB (Front Side Bus) 64bites, megjelennek a 0-1 átmenetek, az északi híd bemenetén megjelenik egy SKEW, ami a futási idők eltéréseit jelenti. Azért van eltérés, mert az egyes biteknek eltérő távolságot kell megtenniük a híd és a proci között
Korlátozza a teljesítményt A kapacitív terhelés sem azonos: különböző meredekségű a felfutás. A buszkorlátot 3-4Ghz környékén érték el HT: soros buszok, annyi van belőle, amennyi kell. 1 bit = 2 Gbit sávszél 2GHz mellett. RS-242 USB, ATA SATA, SCSI SAS, PCI PCI X, AGP 16 bit PCI Express AMD FSB HyperTransport, az Intel is megjelenik majd a soros busszal Processzor buszának szélesség bitben (Address/Data bus): 8086 (20-16) 8088 (20-8) 80286 (24-16) 80386 (32-32) 80486 (32-32) Pentium (32-64) Pentium Pro – P4 (36-64+8) Processzor FSB frekvencia: P(60) PII(100) PIII(133) P4(400,533,800,1066 MHz) Az fc gyorsabban növekedett, mint az FSB. Tapasztalat: FSB/fc > ~0,2 kell lennie, hogy ne okozzon szűk keresztmetszetet Jelenlegi technológia mellett 4GHz-nél elérték az FSB max. határát Tovább nem növelhető a frekvencia, az eltérő futási idők és az eltérő meredekségű felfutás miatt. Megoldás: Soros buszra váltás. AMD: Hyper
Transport bus 90. oldal, összesen: 95 SzA44. Rendszerarchitektúrák II (az elmúlt évek busz innovációinak áttekintése, a GbE, SCSI vezérlők és a grafika csatolása) Gigabit Ethernet: o Déli hídhoz PCI-on keresztül o Déli híd (ICH) PCI-E x1 keresztül, 1 esetleg több o Északi híd (MCH): Megosztják a PCI-E x8-at, ebből egy x4 a PCI-X hídra megy, amihez GbE c. kapcsolódhat o Bridge nélkül közvetlenül kapcsolódhat a 2 db GbE c. az északi hídhoz P4 P4 GbE MCH GbE c. PCI PCI-X CSA GbE MCH GbE c. PCI-X ICH 82540EM 845xx E75011 E7205 82541GI 875P 915xx 925X E7210 P4 HI 2.0 MCH brigde MCH HI 1.5 ICH GbE c. P4 P4 HI 1.5 HI 1.5 GbE P4 HI 1.5 ICH PCI-X GbE GbE c. ICH (6300ESB) Examples 82541PI 4 82547EI 848P 865xx 4 875P 4 82547GI 875P E7210 5 82545EM E7500/7501/7505 82546EB (D) E7500/7501/7505 82541GI E7320/7525 (w/6300ESB) 2 82541PI E7320/7525 (w/6300ESB) 3 82541GB E7320/7525 (w/6300ESB) 3 E7221
E7520(w/ICH5R) All categories Early DP servers/workstations Mainstream desktops Advanced DP servers/workstations (Furthermore the E7210) 1 Ususally in companion with a MbE controller such as the 82550PM or the 82551QM. 2 The 82541GI is used either in 32-bit/33MHz or 32-bit/66 MHz mode. The 82541PI and the 8254GB is used in the 32-bit/33 MHz mode. 4 Most of the enlisted motherboards provide either a MbE controller attached to the LAN 10/100 interface or a GbE controller attached to the CSA interface. 5 Ususally in companion with a MbE controller such as the 82551QM. 3 P4 P4 PCI-X MCH GbE GbE c. PCI-X bridge P4 x4 P4 GbE PCI E. x8 GbE c. MCH x4 DMI P4 x4 PCI E. x8 x4 MCH HI 1.5 HI 1.5 PCI E. x1 GbE c. GbE c. GbE c. ICH ICH ICH (ICH6/ ICH6R) (ICH5R) (ICH5/ 6300ESB) Examples 82570EI 1 2 (88E8050 ) 3 (BCM5721 ) 915GV 925X 82546GB (D) E7520/E7525 (w/ICH5R) E7221 Advanced single processor motherboards Advanced DP servers/workstations 1 Used to date
(2/05) in Commel's FS-979 motherboards. From Marvell 3 From Broadcom 2 91. oldal, összesen: 95 82571EB E7320 E7520 E7525 Advanced DP servers/workstations Small Computer System Interface (SCSI): o Északi hídhoz: PCI-X hídon keresztül, egy majd két csatorna P4 P4 FSB HI 2.0 SCSI c. PCI-X bridge PCI-X (P64H2) P4 P4 FSB PCI E. x8 MCH PCI-X bridge (PXH-V) SCSI c. (E7500/7501) PCI-X x8 P4 MCH (E7320) SCSI c. PCI-X bridge PCI-X (PXH) LSI Logic 53C1020 (Ultra 320, single channel) Adaptec AIC-7902 (Ultra 320, dual channel) LSI Logic 53C1030 (Ultra 320, dual channel) Advanced high-end DP-servers Advanced mid-range DP-servers Early DP-servers Display: o MCH-ból közvetlenül (Északi hídba integrált video vezérlő) o ICH PCI buszon keresztül on-board video vezérlő o MCH AGP, PCI-E buszon keresztül off-board video vezérlő P4 VGA MCH P4 VGA Off-board video c. P4 P4 P4 AGP 4x/8x/ PCI E. x8/x16 ICH MCH ICH MCH VGA On-board video c.
PCI 32 bit/33 MHz ICH (mostly ATI Rage XL) Typical use: Value/mainstream desktops with the letter G in their designation (e.g 845G/GL/GV) Entry level servers based on the E7221 Value/mainstream desktops excluding those with the letters GL or GV in their designation (e.g 845GL/GV) High end desktops/entry level workstations DP-workstations Periféria buszok fejlődése Párhuzamos buszok ideje lejárt, váltás soros buszra. PCI PCI-X ATA SATA SCSI SAS FSB HT soros buszra (AMD) AGP PCI-X 16x USB (alapból soros) 92. oldal, összesen: 95 MCH (E7520) ICH Typical use: Adaptec A16-7899W (Ultra 160, dual channel) Adaptec AIC-7901 (Ultra 320, single channel) Adaptec AIC-7902 (Ultra 320, dual channel) FSB PCI E. x8 ICH ICH P4 Entry level servers based on the E7210 DP-servers SzA45. Alaplapok I (alaplap típusok fejlődésének áttekintése, az AT és a korai ill. fejlett Baby AT alaplapok karakterisztikus jegyei) Alaplapok típusai: • 1981 IBM/PC az eredet • 1984
AT minden kártyákon keresztül valósul meg • 1985 Baby AT: méretcsökkenés, oka: chipkészletek, memórialapkák megjelenése • 1985 Pentium alapú Baby AT: PCI slotok megjelenése • 1987LPX célja keskeny házak megvalósítása, megjelent a Riser Card • 1996 ATX funkcionális javítás • 1997 NLX funkcionális javítás • 1998 microATX • 2000 ATX w/riser • 2004 BTX; microBTX; picoBTX hűtés megoldása AT 8/84 LPX 2 NLX 4 1987 11/96 Baby AT 1 ATX3 ~1985 8/95 ATX w/riser 5 12/99 BTX 7 microBTX 7 microATX 6 1/98 picoBTX 7 9/03 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 00 01 02 03 1 Baby AT: Smaller board size through higher integrated components (chip sets) 2 Non-standardized slimline design with a central mounted riser card allowing 2-3 expansion slots 3 Through better component arrangement reduced cost and EMI emission, integrated AGP (from version 2.02 on) 4 Standardized, improved slimline design with an edge mounted riser
card, integrated AGP 5 Low cost slimline ATX design by using a riser card with 2-3 expansion slots 6 Reduced size low cost ATX design with up to four expansion slots 7 In-line core layout to improve system cooling with scalable board dimensions AT alaplapok karakterisztikus jegyei: • Nem tartalmazott chipkészletet • Rögzített memória az alaplapon (DIPP) • Ezekből következik: nagy méret • 8/16-os ISA billentyűzet (KYB) kivételével minden periféria ezen keresztül kapcsolódik. Korai Baby AT karakterisztikus jegyei: • Megjelenik a chipkészlet • Memória külön lapkán • Ezekből következik: kisebb helyigény • 8/16 bites ISA 93. oldal, összesen: 95 04 05 • • • • CPU: 386 SIMM/30 L2 cache DIPP (alaplapra integrálva) KYB csatlakozó Fejlett Pentium alapú Baby AT alaplapok karakterisztikus jegyei: • Megjelenik a chipkészlet • Memória külön lapkán • Ezekből következik: kisebb helyigény • 16 bites ISA • PCI 32 bites •
CPU: Pentium • SIMM/72 • L2 cache DIPP • KYB, FD, HD on-board vezérlők SzA46. Alaplapok II (a riser card fogalma, célja, alkalmazása, az ATX és a BTX alaplap szabványok) Riser Card: Fogalma: Olyan kártya, melybe több periféria illesztőkártya (ISA, PCI) helyezhető. Az alaplapra merőleges a riser card, így párhuzamosan helyezkednek el a periféria illesztőkártyák az alaplappal. Cél: méretek csökkentése Slim alaplap típusok: LPX, NLX, ATX w/riser ATX alaplap szabvány tulajdonságai: • A CPU-t a tápegység mellé helyezi, így egyszerre hűthető a kettő. • HD és FD csatolók közel helyezkednek el a meghajtókhoz, így is csökkentve az EMI-t (Elektromágneses interferencia) 94. oldal, összesen: 95 • Kétsoros I/O csatlakozók megjelenése Korai ATX alaplapok tulajdonságai: • 1 ISA (egyre kevesebb ISA slotra van szükség) • PCI • AGP • Slot1 (PII/III) • DIMM/168 • Kétsoros I/O csatlakozók Jelenlegi ATX alaplapok
tulajdonságai: • Nincs ISA, PCI-32 • PCI-E 1x, PCI-E 16x • L2 cache a chipen belül van • Socket 478 (P4) • 1 ATA; 4 SATA BTX alaplap szabvány megjelenésének oka: BTX alaplap szabvány megjelenésének legfőbb oka a processzorok magas disszipációja volt. Ennek a problémának a megoldására az alaplapi chipkészletet és a CPU-t egy légáramba helyezték. 95. oldal, összesen: 95
Az adatokat típusokba soroljuk (elemi és összetett). Az elemi adattípusok meghatározzák az adat értelmezési tartományát, értékkészletét, az értelmezett műveletek halmazát. Pl: integer (16 bites) esetén ÉT: –32768 – +32767, ÉK: egész értékek, értelmezett műveletek: +, –, ×, ÷. 1. oldal, összesen: 95 Neumann-féle számítási modell: 1. Min hajtjuk végre a számítást: - Adatokon. - Az adatokat a változók képviselik. Deklarált változók - Az architektúra biztosítja, hogy a változók korlátlan számban változtathassák értékeiket. 2. Hogyan képezzük le a számítási feladatot: - Adatmanipuláló utasítások sorozatával. Deklarált változó Adatmanipuláló programutasítás adatmanipuláció 3. Mi vezérli a végrehajtást: - Az adatmanipuláló utasítások implicit szekvenciája - Az explicit vezérlést átadó utasítás. Vezérlés-átadás Utasítások PC Nem számolja, csak egyesével tudja növelni magát. Az adat
elejét tudja értelmezni move utasításként Programnyelvek: Imperatív (parancs) nyelvek, pl.: Pascal, C, Basic, Fortran Architektúra: Neumann-féle architektúra. Adatfolyam számítási modell: 1. Min hajtjuk végre a számítást: Adatokon 2. Hogyan képezzük le a számítási feladatot: - A bemenő adatok halmazának értelmezésével és, - Adatfolyam gráffal: a) Csomópontok: műveletvégzők. b) Élek: input/output lehetőségek, ahol az adat áramlik. 2. oldal, összesen: 95 Pl.: Z=(X+Y)×(X–Y) X Y + – × bemenő adatok halmaza - párhuzamos műveletvégzés időmegtakarítást eredményez (33%) a Neumann-féle szekvenciálisan dolgozott Z 3. Mi vezérli a végrehajtást: Adat Stréber modell: 1. Még nincs operandus 2. Az egyik operandus megjelent 3. Összes operandus megérkezése Műveletvégzés 4. Megjelenik az eredmény Az utolsó operandus megjelenése indítja el a műveletet. Lehet akárhány operandus, akár több száz is. Programnyelv: Sisal.
Architektúra: The Manchester Dataflow Machine Neumann-féle számítási modell 1. Közös memória (adat + program) 1. Változó 2. Adatmanipuláló utasításokkal 3. Implicit szekvencia 3. Explicit vezérlésátadás @ Adatfolyam számítási modell Műveletvégzőben „tárolhatóak” az adatok Egyszeri értékadás (a bejött adat elveszik) Adatfolyam gráffal Adatvezérelt Nincs PC, nincs vezérlési szekvencia A Pentium processzorokban a CISC magban van adatfolyam. SzA2. Az adattér (fogalma; a memória-tér; a regisztertér és fejlődése: egyszerű, adattípusonként különböző, többszörös regisztertér) A processzor által manipulálható tér. Adattér Memóriatér Regisztertér Nagyobb Lassúbb Olcsóbb Processzoron kívül (külön lapkán) Közös az I/O térrel Kisebb Gyorsabb Drágább Processzoron belül Mindig önálló Memóriatér: - A legfontosabb jellemzője a tárolási kapacitása. Címtér: a) Modell címtere: címsín szélessége
határozza meg b) Implementáció címtere: pénztárca 3. oldal, összesen: 95 - A valós memóriatér fejlődése: a) 40-es évek: néhány száz szó. b) 1950 IAS: 10 bites címsín, 210=1024 szó. c) 1964 IBM 360: 16 Mbyte. - Virtuális tár a) 1960-ban jelent meg az ötlete s az IBM 370-es gépcsalád vitte sikerre. b) Alap jellemzői: 1. kétféle címet értelmezünk: a. valós cím (ezt látja a processzor) b. virtuális cím (programozó) Virtuális tér Nagyobb Lassúbb Háttértárolón helyezkedik el Programozó látja Várakozik a program Valós címtér Kisebb Gyorsabb Alaplaphoz illesztve, félvezető lapkán Processzor látja Itt fut a program 2. Létezik egy olyan, a programozó számára transzparens mechanizmus, mely: a. Az éppen futó program számára szükséges program- és adatrészeket behozza a virtuális tárból a valós tárba, illetve b. Az éppen futó program számára nem szükséges program- és adatrészeket kiviszi a valós tárból a
virtuális tárba. 3. Létezik egy olyan, a felhasználó számára transzparens mechanizmus, mely a programozó által használt virtuális címeket a végrehajtási (execution) fázisban lefordítja valós címekké. transzparens 2. pont Valós címek Virtuális címek mechanizmus 3. pont Az Intel processzorok valós és virtuális memóriájának fejlődése: Típus Megjelenés Valós memória Virtuális memória éve (Mbyte) 8086 1978 1 20 bit 80286 1982 16 1 Gbyte 24 bit 80386 1985 4096 64 Tbyte 32 bit Regisztertér: Osztályozása: - egyszerű - adattípusonként különböző - többszörös 4. oldal, összesen: 95 Egyszerű regisztertér: Egyszerű regisztertér 40-es évek 50-es évek 60-as évek egyetlen akkumulátor egyetlen akkumulátor általános célú regisz+ dedikált regiszter terkészlet Verem regiszterek + - Egyetlen akkumulátor Hátránya: 1. Szűk keresztmetszet 2. Két eredmény esetén csak az egyiket tudta tárolni (pl: osztásnál a hányados
és a maradék) - Egyetlen akkumulátor + dedikált regiszter Előnye: A hányados regiszter bevezetése felgyorsította az osztást. Hátránya: Igen drágán valósították meg, mégis gyakran kihasználatlan volt. - Általános célú regiszterkészlet Előnye: 1. Minden regiszter kihasználtsága javul 2. Új programozói stílus: a regiszter operandusú műveletek számának maximalizálása. - Verem regiszterek Hátránya: Szűk keresztmetszet, mivel csak a verem tetejét látjuk. Előnye: Gyors. Adattípusonként különböző regiszterkészlet: Megjelenésének oka a lebegőpontos feldolgozás gyorsítása. karakterisztika (8) mantissza előjele (1) mantissza (23) 1964 IBM 360 Általános célú regiszterkészlet, feladata: fixpontos, karakteres, logikai feldolgozás. Lebegőpontos regiszterkészlet, feladata: lebegőpontos műveleti feldolgozás. 5. oldal, összesen: 95 1998 Pentium III általános célú regiszterkészlet Megjelenés éve: 1964 1985 1990 1998
MMX2 (Katmai) Egy utasítással több műveletvégzést ér el. A vektorgrafikánál fontos 12 bites, 3D filmeket ez tette lehetővé. lebegőpontos regiszterkészlet Típus IBM 360 Intel 80386 IBM RISC 6000 Pentium III Általános célú regiszterkészlet 16x32 8x32 32x32 8x32 Lebegőpontos regiszterkészlet 4x64 8x80 32x64 8x80 Katmai (MMX2) 8x128 Többszörös regiszterkészlet: Háttérismeretek: - kontextus: a) regiszterek aktuális értékei b) az állapottér (flag, PC) - Megszakításkor a futó program kontextusát le kell menteni annak érdekében, hogy a megszakítás feldolgozása után azt visszatöltve a program futása folytatódhasson. - Többfeladatos és többfelhasználós környezetben igen sok megszakítás lép fel. A kontextus memóriába való mentése lassú gyorsítás többszörös regiszterkészlet révén Fajtái: 1. Több, egymástól független regiszterkészlet, pl: 1964 – Sigma7 - Paraméterátadásos eljáráshívásoknál a paraméterátadás
csak memórián keresztül történhet, így nem gyorsít. - Ideális egymástól független megszakításoknál, pl.: I/O megszakítások 6. oldal, összesen: 95 INS regiszterek száma 2. Átfedő regiszterkészlet, pl: 1980 RISC I - A hívóeljárás OUTS része fizikailag megegyezik a meghívott eljárás INS részével nincs paraméterátadás - Regiszterek száma merev viszonylag üres regiszterkészlet esetén is előfordulhat túlcsordulás. - A túlcsordult paraméterek mentése a memórián keresztül történik lassú. - Konkrét regiszter számok: (ins/locals/outs) RISC I: 6/10/6 SPARC: 8/8/8 Locals OUTS INS Locals OUTS INS Locals OUTS regiszterkészletek száma - Regiszterkészletek száma: túlcsordulás (%) 2 - 4 A mérési eredmények azt mutatták, hogy 8 db regiszterkészlet esetén már csak 2% körüli a túlcsordulás. 6 8 regiszterkészletek száma A programozás módszertana sem ajánl nyolcnál több egymásba ágyazott eljárást, mivel az
ennél több már nehezen tekinthető át. 3. Stack-cache, pl: 1982 C-Machine - a stack verem szervezését és - a regiszterek közvetlen címzési lehetőségét egyesíti. Működése: itt is van átfedő rész az INS és OUTS-nál - A compiler minden eljáráshoz hozzárendel egy változó hosszúságú aktiválási rekordot (regiszterkészlet). - A SP lehetővé teszi az aktiválási rekordok közvetlen elérését. aktuális - A SP és a relatív távolság megadásával aktiválási rekord bármely adat közvetlenül elérhető a stackaktuális cache-ben. stack pointer - Az aktiválási rekordok számának csak a (SP) stack cache fizikai mérete szabhat határt. SzA3. - előző SP A szekvenciális utasítás-végrehajtás menete (az aritmetikai utasítások és a feltétlen vezérlés-átadási utasítás végrehajtásának sémája) Egy gépi kódú utasítás általános formátuma: MK Címrész - előző aktiválási rekord MK : műveleti kód, mit csináljon a
processzor Címrész : mivel tegye mindezt Az utasítás-feldolgozás nagyvonalú folyamatábrája: Megszakítás igen megszakítás feldolgozása következik nem I. utasítás lehívás (fetch) II. utasítás végrehajtás (execution) 7. oldal, összesen: 95 MAR: Memory Address Register – memória-címregiszter (egyirányú). PC: Program Counter. MDR: Memory Data Register – memória-adatregiszter (kétirányú). IR: Instruction Register – utasításregiszter. DEC: Decoder. ALU: Arithmetical Logical Unit – műveletvégző (utasítást is képes továbbítani). AC: Accumulator – általános célú regiszterkészlet. - Egy hagyományos szekvenciális feldolgozást végző processzor részei: Operatív tár adatsín címsín processzor MAR MDR Vezérlő egység PC ALU IR AC DEC I. Utasítás lehívás A PC tartalmazza a következő végrehajtandó utasítás címét. MAR ← PC MDR ← (MAR) – nem a címét jutatja el, hanem a tartalmát. IR ← MDR – itt
már az IR-ben adat van. PC ← PC + 1 – következő feldolgozandó utasításra mutat, a +1 egységre utal, 2, 4 byte lehet. Ez a folyamat minden utasítás esetén megegyezik. II. Utasítás végrehajtás - Betöltés (load): DEC ← IR MAR←DEC műveleti kód IR címrész MDR ← (MAR) AC ← MDR 8. oldal, összesen: 95 címrész - - Aritmetikai-logikai utasítások: DEC ← IR MAR ← DECcímrész MDR ← (MAR) AC ← AC + MDR vagy AC ← AC – MDR vagy AC ← AC és MDR értelmezi, hogy mi van a címrészben a másik tag elmentése műveletvégzés Kiírás (store): DEC ← IR MAR ← DECcímrész MDR ← AC (MAR) ← MDR – meghatározott helyre történő visszaírás. - feltétlen vezérlésátadás (ne a soron következő utasítást végezze, hanem amit mi megadunk): DEC ← IR PC ← DECcímrész SzA4. Az állapottér és az állapotműveletek (az állapottér összetevői; az állapotműveletek) Állapottér a felhasználó számára látható a
felhasználó számára transzparens virtuális memória PC állapotjelzők CC állapot-indikátorok CC - Condition Code - 2 bites négy érték felvétele - IBM 360 állapot-indikátorok (flag): megszakítások verem . egyéb, a felhasználó számára látható állapotformáció adattípusonként különböző állapot-indikátorok nyomkövetés (debug) indexelés - minden helyiérték saját jelentéssel bír, pl. negatív, nulla, túlcsordulás adattípusonként különböző állapot-indikátorok: - minden regiszterkészlet típushoz hozzárendelnek külön állapot-indikátor készletet, pl. az általános célú processzorhoz tartozó flag-eken kívül a lebegőpontos proceszszorhoz is hozzárendelnek külön flag-készletet - a lebegőpontos flag-készlet eseményei pl. alul-, túlcsordulás, denormalizált szám, 0 9. oldal, összesen: 95 Megszakításoknál (fejlődés íve): - 1973 IBM 370-es gépcsaládnál bevezetik a PSW-t (Program Status Word):
megszakításoknál a PSW-t mentik el. Kontextus: a) A regiszterek aktuális értékei és b) Az állapottér aktuális értékei (PC, flag) Megszakításnál a kontextust mentik. Állapotműveletek PC Inkrementálás (növelés) Felülírás SzA5. Flag Set (beállítás) Save (mentés) Load (visszatöltés) Clear (törlés) Reset (kezdeti értékek visszaállítása) Az utasítás- és operandus típusok (utasítás- és operandus típusok; szabályos architektúrák) Az utasítások fajtái (típusai): op – operandus s – source (forrás) d – destination (cél) @ - tetszőleges művelet 4 címes utasítás opd:=ops1@ops2, op4 MK Opd ops1 ops2 op4 Az op4 a következő utasításra mutat, csak néha van nagy ugrás. Neumann szerint PC és címregiszter legyen az op4 helyett Hátránya: - memóriapazarló - adatrögzítési hibák lehetősége nő - nehézkes a program karbantartása 3 címes utasítás opd:=ops1@ops2; Az eredmény helyének explicit deklarálása. Előnye: -
Az aktuális utasítás eredményének mentésével párhuzamosan betölthetjük a következő utasítás bemenő operandusait. 10. oldal, összesen: 95 Hátránya: - Neumann szerint: Az aktuális művelet eredménye tipikusan a következő művelet egyik bemeneti operandusa. Pl.: RISC számítógépek (processzorok) 2 címes utasítás ops1:=ops1@ops2; a mai gyakorlat általában ops2:=ops1@ops2; Pl.: ADD[100],[102]; [memóriacímek] Előnye: - Memória- vagy regisztertakarékosabb, kiküszöböli a Neumann által említett hátrányt. Hátránya: - Az a forrásoperandus, ahol az eredmény képződik értékét veszti, ha később szükségünk van rá, a művelet előtt ki kell menteni. Pl.: IBM 360/370, Intel processzorok 1 címes utasítás - Az egyik forrásoperandust betöltjük az AC-ba: LOAD[100] - Az AC aktuális tartalmához hozzáadjuk az utasításban szereplő operandust: ADD[102] - Végül az AC tartalmát kimentjük az operatív tárba: STORE[100] Előnye: -
Rövidebb utasítások. Hátránya: - Több utasítást kell használnunk. Pl.: 1951 IAS (Neumann gépe), csak az 50-es 60-as években készült ilyen processzor 0 címes utasítás Fajtái: - NOP (no operation). - Veremműveletek (csak a verem tetejét látja): POP, PUSH. - A műveleti kód tartalmazza az operandust, pl.: CLEAD (a D flag törlése) Napjaink trendje: - CISC: - kétcímes - az első helyen képződik az eredmény - tipikusan csak a második cím lehet memóriacím - RISC: - aritmetikai-logikai utasítások esetén háromcímes utasítások - mindhárom regisztercím Operandus-típusok: Operandus-típusok akkumulátor (a) memória (m) regiszter (r) verem (stack - s) 11. oldal, összesen: 95 immediate (i) immediate: magában a programban adunk értéket a változónak a gyakorlatban ez bemenő operandus Architektúrák szabályos akkumulátor a-r aar memória a-m ara kombinált(pl. a+m) - a mai CISC processzorok 2 címes regiszter 3 címes 2 címes
aam ama m1m1m2 m2m1m2 m1m2m3 r1r1r2 verem 3 címes r2r1r2 SSS r1r2r3 Akkumulátor: Előny: Gyors, rövid címrész. Hátrány: Szűk keresztmetszet. Napjainkban nem aktuális. Regiszter: Előny: Gyors, rövid címrész. A mai RISC számítógépek mindegyike. Memória: Előny: Nagy címtér. Hátrány: Hosszú címrész, hosszú utasítások, lassú. Napjainkban nem aktuális. Verem: Előny: Gyors, rövid címrész (0 hosszúságú). Hátrány: Szűk keresztmetszet. Pl.: HP3000, VT1005, Napjainkban nem aktuális SzA6. Az aritmetikai egységek felépítése I. (az n-bites soros és párhuzamos összeadó, valamint az előrejelzett átvitellel felépített n-bites összeadó) n-bites soros összeadó Megjelenésének oka az, hogy az összeadandók tipikusan n bit hosszúságú regiszterekben helyezkednek el. n fokozatosan növekszik (ma: 32/64) Jellemzői: - A két operandus léptetőregiszterben (shift) helyezkedik el. - Az eredmény az A operandus helyén képződik. 12.
oldal, összesen: 95 - A kimenő átvitelt tárolóba vagy késleltetőbe helyezzük, hogy a következő bitpároshoz (összeadáshoz) megfelelő időben érkezzen. - A Cin csak az első bithelyiérték összeadásakor aktív. Értékelése: - Ha az egybites teljes összeadó műveleti ideje t, akkor az n-bites összeadási ideje: T=n×t. Gyorsítás: - t: A lehető leggyorsabb kialakítást alkalmazzuk. - N: Az egybites teljes összeadók számát megtöbbszörözzük n-bites párhuzamos öszszeadóra. n-bites párhuzamos összeadó 4 bites párhuzamos összeadó tesztelése: I. eset: A 0101 Cin=0; T=t B +1010 1111 II. eset: A 0101 B +1010 1. lépés 2. lépés 3. lépés 4. lépés Cin=1; T=n×t 1110 1100 1000 0000 C0=1 C1=1 C2=1 Cout=1 Értékelés: - Igen komoly beruházás árán (egy darab helyett n db egybites teljes összeadó) csupán hullámzó teljesítményt értünk el. Az ok: meg kell várni az átvitel terjedését Az átvitel előrejelzéses összeadó (Carry
Look-Ahead – CLA) Cout=A×B+(A+B) ×Cin A×B G (Generate) A+B P (Propagate) Az egyes bithelyiértékeken keletkező átvitel függ - a bemenő operandusoktól és - a kívülről beérkező átviteltől, melyek előre ismertek, de nem függ az előző bithelyiértékeken keletkező átviteltől. Az egyes bithelyiértékeken keletkező átvitel: Ci=Gi+Pi×Ci-1 C0=G0+P0×Cin C1=G1+P1×C0=G1+P1×G0+P1×P0×Cin C2=G2+P2×C1=G2+P2×G1+P2×P1×G0+P2×P1×P0×Cin C3=G3+P3×C2=G3+P3×G2+P3×P2×G1+P3×P2×P1×G0+P3×P2×P1×P0×Cin Értékelése: ÉS kapuk sorozata: 1 fokozat 13. oldal, összesen: 95 Összekapcsolásuk egy vagy kapuval: 1 fokozat P és G meghatározásához egy vagy és egy és kapu kell:+1 fokozat 3 fokozat Amennyiben egy fokozat végrehajtási ideje d, akkor egy bithelyiérték átviteli idejének meghatározása: T=3d Megvalósítási alternatívák: 1. Katalógus áramkör egybites teljes összeadók + CLA 2. Az egybites teljes összeadókat helyettesítjük a P
és a G meghatározásához szükséges kapukkal (vagy valamint és kapuk) A vagy kapu bemeneteinek száma technológiai korlátba ütközik, ezért max. 8 bithelyiértékre alakítható ki a CLA. 3. 32 bites megoldás: A CLA-k között az átvitel sorosan terjed 4. A CLA-khoz is hozzárendelünk egy CLA-t 14. oldal, összesen: 95 SzA7. Az aritmetikai egységek felépítése II. (a fixpontos szorzás algoritmusai és gyorsítási lehetőségek) Hagyományos szorzás: 13×123 39 26 13 1599 Algoritmizált változat: 13×123 0000 felveszünk egy gyűjtőt, amit nullázunk 39 0039 260 10-zel szorozzuk 0299 1300 100-zal szorozzuk 1599 10/100-zal való szorzás helyett léptetés: 13×123 0000 Konklúzió (decimális számoknál): Az összeadási ciklus annyiszor fut le, 39 0039 ahány helyiértékből áll a szorzó. 26 0299 13 1599 A bináris szorzás sajátosságai: - A bináris szám hossza Példa Decimális szám Bináris szám helyiértékeinek száma helyiértékeinek
száma 9 1 4 99 2 7 999 3 10 - Konklúzió: A bináris szám hosszabb, mint a decimális, ezért a ciklus többször fut le. A szorzat hossza A decimális helyiértékek száma Általánosítva A 1 2 2 m B 1 1 2 n Xmax 2 3 4 m+n Példa: 9×9 99×9 99×99 A szorzó és a szorzandó egy-egy regiszterben helyezkedik el, ezért az eredmény két regiszterben képződik. 15. oldal, összesen: 95 Példa: Legyen egy regiszterünk három helyiértékű, a szorzat kisebb helyiértékei keletkeznek a szorzó helyén: 0 0 1 1 9 9 5 2 1 9 9 3 2 1 9 eredmény A bináris szorzás gyorsítása: - Bitcsoportokkal való szorzás: A szorzó helyiértékeit nem egyesével, hanem csoportokban kezeljük, így a csoportokat léptethetjük, ami gyorsabb. Pl.: kettes csoportokban: 00 – kettőt léptetünk balra. 01 – a gyűjtőhöz hozzáadjuk a szorzandó egyszeresét és kettőt léptetünk balra. 10 – a gyűjtőhöz hozzáadjuk a szorzandó kétszeresét és kettőt léptetünk balra.
11 – a gyűjtőhöz hozzáadjuk a szorzandó háromszorosát és kettőt léptetünk balra. Példa: Segédszámítás: 7×9 = 0111×10|01 a szorzandó kétszerese: 0111 0000 A: összeadással 0111 0111 1110 0111 1110 B: léptetéssel 01111110 111111B = 63D - Booth féle algoritmus: - Bináris számok esetén az összeadási ciklus annyiszor fut le, ahány egyes van a szorzóban (nulla esetén csak léptetünk). A szorzóban lévő egyesek számának csökkentése a cél. Példa: 62-vel kell szorozni: 62=111110B 5 db összeadás. Helyette: ×64=100000B 1 db összeadás ×2=000010B 1 db összeadás – 1 db kivonás Összesen 3 db művelet, 40%-os időmegtakarítás, pl.: mai processzorok mindegyike. 16. oldal, összesen: 95 SzA8. Az aritmetikai egységek felépítése III. (a fixpontos osztás algoritmusai; a fixpontos multimédia (a raszteres képfeldolgozás és a hangfeldolgozás) probléma-felvetése és megoldása) Osztás X=A/B Hagyományos osztás: 150/48 150 I
–48 102 II 3,1 –48 54 III –48 60 I –48 120 I –48 72 II Konklúzió: Minden kivonás előtt komparálunk (összehasonlítunk), ezért lassú. Visszatérés a nullán át csak az előjel flag-et vizsgálva: 150 –48 102 I –48 54 II –48 6 III –48 –42 kiírja a gyűjtőt (3,) +48 hozzáadja a maradékhoz az osztót (–42+48) 60 tízszerezi (6×10=60) és folytatja –48 12 –48 –36 kiírja a gyűjtőt (,1) +48 Itt minden kivonás automatikus (nincs komparálás, ami lassú). Mivel nem kell minden kivonás előtt komparálni, csak a gyors előjel flag vizsgálatot végezzük, a két felesleges művelet (hozzáadás +48 és szorzás) ellenére gyorsabb. 17. oldal, összesen: 95 Visszatérés nélküli osztás: 11/6 11 I –6 5 10. lépés –6 –10 9. lépés +6 –4 8. lépés +6 +20 I –6 14 II –6 8 III –6 2 10. lépés –6 –40 9. lépés 1,8 kiírja a gyűjtőt szorozza 10-zel Fixpontos multimédia feldolgozás A probléma felvetése: A,
Hangfeldolgozás: - analóg jel digitális jelfeldolgozásához digitalizálni kell analóg digitális (A-D) konverter Amplitúdó vagy felbontás: - A leképezendő hanghullám minimális és maximális értékhez hozzárendeljük az értelmezési tartományunk minimális és maximális értéket. - 8 bit 256 pontos felbontás - 16 bit 65536 pontos felbontás (a mai gyakorlat) Mintavétel: - Példán keresztül: Egy 50kHz-es mintavétel azt jelenti, hogy másodpercenként 50000 mintát veszünk az adott hullámból (minden egyes mintánál az amplitúdó értékét tároljuk el). 18. oldal, összesen: 95 - Mai példák: Alkalmazás a) Telefon b) Audio CD c) DVD d) DVD (minőségi) kHz 8 44 48 96 Egy másodperc hanganyag tárolási igénye audio CD, 16 bites felbontás, sztereó esetén: - 44000 minta×2 byte felbontás×2 a sztereó miatt = 176000 byte/sec ~ 170 kbyte/sec - Percenként: 60×170 ~ 10Mbyte/min Feladat: Nagy tömegű fixpontos adat - tárolása -
továbbítása - feldolgozása B, Pixeles képfeldolgozás: - A fénykép és a festmények analóg formátumúak, hiszen a fények, árnyékok és színek folyamatos átvitelével írhatók le. A képeket digitalizálnunk kell. Felbontás: - A képeket képpontokra (pixel) bontjuk. Minél sűrűbb a rácsszerkezet, annál jobb minőségű képet kapunk a digitalizálás során Minél kisebb egy pixel, annál jobb a leképezés Pl: 800×600; 1280×1024 Pixelek vagy képpontok: - Minden szín leírható három szín összetételeként, tehát minden pixelhez három darab színkódot kellene hozzárendelni, de helyette ezeket egyetlen vektorrá kódolták. Pl.: 000 0, 001 1, 010 2 A pixelek lehetséges értékei: - 1 bit: fekete-fehér, sötét-világos - 1 byte: 256 féle színt írhatunk le - 2 byte: 65536 féle szín (high-color) - 3 byte: 224 féle szín (true-color) (az emberi szem ennyit nem tud megkülönböztetni, azért jó a sok szín, mert a számítógép ezt is tudja
értelmezni) - 4 byte: a negyedik byte az úgynevezett alfa csatorna, az effektek jelzésére szolgál (pl.: átlátszóság mértéke) Egy kép tárolásához szükséges memóriaterület: egy byte 800×600 480000 byte 1280×1024 1,3 Mbyte két byte 960000 byte 2.6 Mbyte A képfeldolgozás feladata: Nagy tömegű fixpontos adat tárolása, továbbítása, feldolgozása. 19. oldal, összesen: 95 Megoldás: - Tárolás, továbbítás hatékony tömörítéssel. Feldolgozás: - Probléma: a 3 perces számot 3 perc alatt le kell tudni játszani - Hagyományos feldolgozás: pl.: 2 kép összeadása a 800×600-as felbontás mellett 1. Az 1 kép 1 byte-ját betöltjük az AC-ba 2. A 2 kép 1 byte-ját hozzáadjuk az AC-hoz, az eredmény az AC-ban keletkezik 3. Az AC tartalmát lementjük az eredmény memóriaterületre Ez a ciklus 480000-szor fut le. (minden bájtra) - Megoldás SIMD módszerrel (single instruction, multiple data): Több adattal ugyanazt az utasítást hajtja
végre, ~ 8-szoros gyorsítást eredményez, 60000-szer fut le a ciklus. A + + + + + + + + +B = = = = = = = = X - 8 db A gyakorlatban kétféle megoldás: - multimédia segédprocesszor - az általános célú processzorba beleintegrálják a multimédia feldolgozó egységét. - Az Intel MMX kiterjeszés: a) 1997-ben jelent meg b) Matrix Math Extension (Multimedia Extention) c) Logikai architektúra: 1. Pakolt adattípusok bevezetése a. Ezek mindegyike 64 bites, ami megegyezik a processzor belső sínjének szélességével. b. Fajtái: pakolt byte: 8 db 8 bites = 64 bit, pakolt félszó: 4 db 16 bites = 64 bit, pakolt szó: 2 db 32 bites = 64 bit. 2. Új utasítások bevezetése A négy aritmetikai művelet (+,–,×,÷) és a logikai műveletek mindhárom új adattípushoz. d) Fizikai architektúra: 1. Az Intel nem akart új regisztereket bevezetni az új adattípusokhoz, hanem a 80 bites lebegőpontos regisztereket használja a 64 bites pakolt adattípusok feldolgozására. 2.
Egy évre rá az MMX műveletvégzőket 2-re növelték, így a ciklusok száma 30000-re csökkent 20. oldal, összesen: 95 SzA9. Az aritmetikai egységek felépítése IV. (a lebegőpontos algebrai műveletek és megvalósításuk A lebegőpontos multimédia (vektoros képfeldolgozás) probléma-felvetése és megoldása) Lebegőpontos műveletek Összeadás: X=A+B A=mArka B=mBrkb Példa: 0,9×103 +0,95×104 0,09×104 +0,95×104 1,04×104 0,104×105 Közös kitevőre kell hozni, a mantisszában a törtpontot ciklikusan léptetetem jobbra/balra. Mantissza vizsgálata, majd szükség esetén normalizálása. Bonyolultabb, mint a fixpontos Algoritmus: 1. A kitevők megvizsgálása: csak azonos kitevőjű számok mantisszái adhatók össze 2. Amennyiben a kitevő eltérő, akkor a kisebb kitevőjű szám mantisszájában a törtpontot jobbra léptetjük és a kitevőt inkrementáljuk. Ez a ciklus addig fut, míg a kitevők meg nem egyeznek. 3. Összeadjuk a
közös kitevővel rendelkező számok mantisszáit 4. Szükség esetén normalizálunk Szorzás: X=A×B=mA×mBrka+kb Algoritmus: A mantisszákat összeszorozzuk, a karakterisztikákat pedig összeadjuk. Osztás: X=A/B=mA/mBrka-kb Algoritmus: A mantisszákat elosztjuk, a karakterisztikákat pedig kivonjuk egymásból. Megvalósítás: Univerzális műveletvégző - az ALU parciálásával (részekre bontásával) karakterisztika mantissza fixpontos ALU Ez egy kicsit bonyolultabb vezérléssel megoldható. - Szervezési módosítással a) Mind a mantisszát, mind a karakterisztikát külön-külön regiszterekben helyezzük el. b) Egymás után elvégezzük a mantissza és a karakterisztika műveleteket. c) Az eredményt pedig az egyik regiszterben összevonjuk. 21. oldal, összesen: 95 Dedikált műveletvégző adatsín Karakterisztika egység Mantissza egység visszacsatolás Vezérlő vezérlés Következtetések: - Míg a mantissza egységnek ismernie kell a szorzást
és osztást is, a karakterisztika egységnek elegendő az összeadást és a kivonást ismernie. - Párhuzamosan lehet végezni a karakterisztika és a mantissza műveleteket. - A szűk keresztmetszetet a mantissza egység jelenti (a szorzás, osztás miatt), mivel a karakterisztika egység az összeadást és kivonást gyorsan el tudja végezni. A gyorsítást a mantissza egységnél kell végezni. Lebegőpontos, vektorgrafikus multimédia műveletek: - Az egyenesekkel és görbékkel határolt objektumok geometriai jellemzőikkel leírhatók. Elegendő a geometriai jellemzők tárolása. Például: a) Egyenes esetén: Két pontjának koordinátáit. b) Kör: A középpont koordinátáját és a sugár hosszát. Jellemzők: - 2D: - Egy kép igen sok objektumra (sokszögre, háromszögre) bontható egy átlagos kép objektumainak száma ~20000. - Miután a számítógép a geometriai jellemzők alapján meghatározza a ~20000 objektumot, a színek valósághűbb átmenete
érdekében egy úgynevezett textúrát alkalmaz. A megoldandó feladat: - Viszonylag kevés lebegőpontos adaton - sok műveletet hajtunk végre. - 3D: - - Egy harmadik dimenzió kerül hozzáadásra. a) Biztosítani kell a párhuzamosoknak a végtelenben való találkozását. b) Az atmoszférikus sajátosságok is megvalósításra kerülnek, azaz a közelebb lévő tárgyak élesebbek, a távolabbiak kékesebbek és elmosódottabbak. Sok 3D film készül, ahol minimum 15 képet kell vetíteni másodpercenként annak érdekében, hogy folyamatosnak láthassuk. Pl.: képenként 20000 objektummal számolva 20000×15=300000 obj/sec feldolgozási sebesség szükséges 22. oldal, összesen: 95 A megoldandó feladat: - Viszonylag kevés lebegőpontos adaton - sok műveletet kell végrehajtanunk - adott időegység alatt. Megoldás az Intel processzoroknál: - 1998: MMX2, azaz a KNI (Katmai New Instruction) - a megoldás: a SIMD elv (Single Instruction Multiple Data) - 1985 óta
először új regisztereket vezetett be az Intel: 8 db 128 bites regisztert. - Formátumok: a) 4 db 1-szeres pontosságú vagy b) 2 db 2-szeres pontosságú számon hajt végre egy időben műveletet: - + + + + = = = = 70 db új utasítást vezettek be. 100%-osan megfelel az IEEE 754-es szabványának. Megszakítás esetén az új regisztereket is menteni kell, ezt először a Win98 operációs rendszer végzi. A lebegőpontos műveletvégzés jelentősége: - A tudományos és multimédia számításokhoz szükséges. - A miniatürizálás és a fajlagos árcsökkenés eredményeként a jelenleg kereskedelmi forgalomban lévő processzorok mindegyike hardver úton megvalósítja. SzA10. A vezérlőegység (az áramköri vezérlőegység és a mikrovezérlő jellemzőinek szembeállítása Az áramköri vezérlőegység megvalósítása és működése) - - Centralizált vagy szekvenciális vezérlés: a) Huzalozott vezérlés. 1. 1947: első elektronikus számítógép
b) Mikroprogramozott vezérlés. 1. 1954: Wilkes 2. 1963: CDC6600 Decentralizált vagy párhuzamos vezérlés: a) Szuperskalár. 1. 1966: IBM 360/91 b) Futószalag. 23. oldal, összesen: 95 Huzalozott vagy áramköri vezérlés Hátrányai: - Az ember számára nehézen áttekinthető. - Nehézkesen módosítható. Előnye: - Gyors. Tervezése: - igazságtábla - logikai függvények - azonos átalakítások a következő célfüggvényekkel: a) az elemek számának minimalizálása b) a végrehajtási idő minimalizálása - megvalósítás Megvalósítás: Elv: - Egy forrásregiszterből módosító áramkörökön keresztül egy célregiszterbe juttatjuk az adatot. Regiszterek: - Memória regiszterek (MDR, MAR). - ALU regiszterei (AC, általános célú regiszterkészlet). - I/O regiszterek (vezérlőkártyán). - Vezérlőrész regiszterei (utasítás regiszter, PC). 24. oldal, összesen: 95 Módosító áramkörök: - Összeadó - Invertáló - Inkrementáló -
Léptető Működése: - A forrásregiszter kimenetét rákapuzzuk a módosító áramkör bemenetére. - Előírjuk a módosító áramkör számára, hogy most éppen milyen módosítást hajtson végre. (Pl: léptetés, összeadás) - A módosító áramkör kimenetét rákapuzzuk a célregiszter bemenetére. A mai processzorokban tipikusan több száz olyan vezérlési pont van, amit vezérelni kell. Mikroprogramozott vezérlés 1954: Maurice Wilkes (University of Cambridge). Cél: - Ember számára áttekinthetővé tenni a vezérlést. a) Mikroutasítások, melyek meghatározott vezérlővonalat, vagy -vonalakat aktiválnak. b) A gépi kódú utasítások végrehajtása mikroutasítások sorozatával érhető el. c) A hagyományos (Neumann-elvű) számítógépet tekinthetjük egy makroszámítógépnek, ezen belül helyezkedik el egy mikroszámítógép mikroutasítássokkal, mikroprogrammal. - A vezérlést rugalmassá, könnyen módosíthatóvá alakítani. a) A
mikroprogramot tároló Control Memory-ban cserélhetjük, változtatjuk magát a mikroprogramot. Huzalozott kontra mikroprogramozott vezérlés: sebesség gyors áttekinthetőség ember számára nehezen áttekinthető módosíthatóság merev, nehézkesen módosítható mindig lassabb ember számára áttekinthető rugalmas SzA11. Félvezető tárak (jellemzőik; csoportosításuk) Csoportosításuk: Félvezető memória-típusok írható-olvasható RAM DRAM (operatív tár) főképpen csak olvasható - CMOS (setup) SRAM (gyorsító tár) csak olvasható ROM (BIOS) 25. oldal, összesen: 95 A számítógépen belül a legelterjedtebb a RAM (Random Access Memory). Szó szerinti fordításban ez közvetlen elérésű tárat jelent, azonban ez a táblázatban szereplő valamennyi tárra vonatkozóan igaz, tehát nem egy egyedi jellemzőt tartalmazó elnevezés. Így inkább szabad fordításban írható-olvasható tárnak nevezhetjük. Ennek kétféle gyártási
technológiája van A megengedett Az adaA memóOlvasási írási Jelleg tok élet- Írási idő Törölhetőség ria típusa idő ciklusok tartama száma írható60-100 programból, DRAM 4-32 ms 60-100 ns végtelen olvasható ns bájt szinten az áramprogramból, írhatóforrás SRAM 10-25 ns 10-25 ns végtelen blokkolvasható kikapszinten csolásáig csak olcsak nem lehetROM végtelen különböző 100 ns vasható egyszer séges csak olcsak nem lePROM végtelen órák 100 ns vasható egyszer hetséges főképpen ultraviola pár máEPROM csak ol- végtelen 100 ns sokszor fénnyel, lapsodperc vasható ka-szinten főképpen kb. 1 mákorlátoEEPROM programból, csak ol- végtelen sodperc/ 100 ns zott bájt szinten vasható bájt számban főképpen korláto- programból, Flash csak ol- végtelen n. a 100 ns zott blokk szinvasható számban ten a tápfőképpen elem CMOS csak ol- által törn. a n. a sokszor programból vasható ténő táplálásig A fontosabb félvezető
memória-típusok és tulajdonságaik A DRAM a Dynamic RAM, azaz a dinamikus RAM jelenti az alkalmazás során a nagyobb tárolási kapacitást. Fizikailag bitenként egy kondenzátort alkalmaznak benne, melynek feltöltött állapota jelenti az 1-et, és az ellenkező állapota pedig a 0-t Sajnos a kondenzátor jellemző fizikai tulajdonsága, hogy az alkalmazott szigetelő tökéletlensége miatt idővel elveszíti töltését. Annak érdekében, hogy az adatvesztést megakadályozzuk, a tartalmát rendszeresen újra kell írni, azaz frissíteni kell. Ez a felhasználó számára teljesen észrevétlenül történik, az alkalmazott memória jellemzőitől függően 4-30 msec-onként A DRAM viszonylag könnyen és olcsón gyártható, kis energia-fogyasztású, de például a processzorhoz képest viszonylag lassú. Hátránya, hogy a tápáram kikapcsolásával elveszíti tartalmát. A gyakorlatban ezt a memóriatípust alkalmazzák operatív memóriaként 26. oldal, összesen: 95
Fast Page Mode DRAM 1, Cím-folytonos olvasás: egyszerre több bitet olvasunk a mátrixból, így a RAS jelet elég csak egyszer kiadni. (6+4+4+4 ns) Nibble Mode FPM DRAM: 4 rekeszes RAM 1. az első olvasásnál rákerülnek a címek, a RAS és a vezérlőjel 2. a címek növelése az IC-n belül történik, nincs külső címzés Mindez a CAShez szinkronizálva; (6+4+4+4 ciklus) Ez akkor előny, ha a CPU 4 bájtos egységekben hívja le az adatot OPT-ból, és folyamatosan tudja fogadni az adatokat. Extended Data Out DRAM = EDORAM +1 kimenet bevezetése (tároló) a nCAS visszabillenésének tárolására. A kimeneti adat érzékelését ehhez kötik: előbb indulhat a kiolvasás (egy ciklus megspórolása). 6+3+3+3ciklus – Output Enable nOE // nX = X negáltja Burst Extended Data Out DRAM = BEDO RAM Nincs szükség az oszlop vezérlőjelre, a címeket az IC-n belül generálja. Saját címszámlálóval és belső pipeline-nal rendelkezik A bemenetén már
megjelenik az új adat, amikor a kimenetére kerül az előző adat. (6+2+2+2ciklus) Synchronous DRAM = SDRAM Az olvasás a CPU vezérlőjeléhez van szinkronizálva, nem pedig a CAS-RAS-hoz. 5+1+1+1 ciklus. 1 SDRAM lapra 4db Bank (4*8 bit) Rambus DRAM • teljesen új architektúra, több egymástól független memóriamodult tartalmaz • rendkívül nagy belső cache-tárja van (1M-hoz 2K cache), • NINCS nRAS, nCAS helyette 1 lépésben kapja meg a címet • blokkos az adatátvitel; blokk: 8db 256 bájt terjedelmű, adatszélesség: 8bit • gyors blokkmozgatás, speciális illesztő-áramkör szükséges (rambus) • nagyon drága, mert az eltérő technológia miatt más gyártósort igényel DDR SDRAM SDRAM esetén a művelet a felfutó élre van szinkronizálva, míg a DDR SDRAM esetén a lefutóra is. • A belső memória lapokra van bontva: az egyik rekeszben adatforgalom, a másikba beolvasás. • Nagyon gyors belső órajelgenerátor és pipeline. •
Kompatibilis a jelenlegi gyártási technikával. • PC 2100: 2100 Mb/s / 266MHz / 7,5ns • PC 2700: 2700 Mb/s / 333MHz / 6ns • PC 3200: 3200 Mb/s / 400MHz / 5ns Összefoglalva: DRAM [ns] [Mb/s] 60 100 FPM EDO Aszinkron burst 40 25 200 266 BEDO SDRAM RDRAM DDR szinkron 15 532 15/10/7,5 1600 4/3,3 7,5/6/5 Az SRAM a Static RAM, azaz a statikus RAM jelenti a gyakorlatban a kicsi, de gyors memóriát. Ezt hagyományos flip-flop alkalmazásával készítik, így frissítést nem igényel (innen ered a neve is), s a tartalmát egészen addig megőrzi, amíg a tápáramforrás be van kapcsolva. A DRAM-hoz képest a gyártása nehezebb, az ára magasabb, s több áramot is fogyaszt. Ez utób27 oldal, összesen: 95 bi esetben nem annyira a magasabb fogyasztás jelent hátrányt, hanem inkább az, hogy nagyobb energia alakul át hőenergiává, aminek elvezetéséről gondoskodni kell. A sebessége viszont már közelebb áll a processzor sebességéhez. Ezért a
számítógépen belül ezt a memória-típust alkalmazzák gyorsítótárként A főképpen csak olvasható memóriák közé sorolható CMOS memóriát alkalmazzuk a PC-nk egyedivé alakítására, a beállítási (setup) adatok (a külső tárolók indítási sorrendje, a külső tárolók jellemzői, a memória mérete stb.) tárolására A CMOS memória a számítógépben lévő elemmel táplálva alacsony feszültségszinten, igen csekély fogyasztás mellett a számítógép kikapcsolása után is képes a benne tárolt adatok megőrzésére, s üzemi feszültségszinten pedig azok módosítására is. A CMOS lapka az adattároló egységen túlmenően tartalmaz egy órát is, mely az elem táplálásával a számítógép kikapcsolása után is képes követni az idő múlását. A csak olvasható memóriából (ROM) töltődnek be az első programok, így az egyes részegységek működőképességét letesztelő programok valamint az alapvető beviteli-kiviteli műveletek
(BIOS) programjai, s így bekapcsolásakor e memória-típus segítségével éled fel a számítógép. SzA12. A megszakítási rendszer (fogalma; megszakítási okok; a megszakítás folyamata; az egy- és a többszintű megszakítási rendszer) A számítógépnek rugalmasan reagálnia kell a külvilág eseményeire. Erre a célra szolgál a számítógép megszakítási rendszere. A megszakítás bekövetkezésekor az éppen futó programról vezérlés ideiglenesen átadódik egy másik program számára, amely kiszolgálja a bekövetkezett eseményt A megszakítást kiszolgáló program lefutása után pedig a megszakított program végrehajtása a következő utasításától kezdve folytatódik Váratlan esemény aszinkron (teljesen reprodukálhatatlan) várható pl. DMA szinkron (bármikor reprodukálható, a program minden futásakor ugyanott következik be) nem várható pl. hardver hiba paritás hiba, áramkimaradás A megszakítások okai vagy forrásai: 1.
Géphibák: - Az egyes eszközök valamilyen hibajavító kód segítségével ismerik fel a hibákat - A CPU regiszterei - Operatív tár - Adatátvitel - Energiaellátás hibái - Klimatizáció 2. I/O források: a perifériák megszakítás-kérő jelzései (CPU dobozon belül) 3. Külső források másik számítógép 4. Programozói források 28. oldal, összesen: 95 Utasítások végrehajtásakor keletkező megszakítások: Hiba, nem kért, váratlan (arch. specifikusak) o Memóriavédelem megsértése (saját részéről túlmutat) o Tárkapacitás túlcímzés (tényleges) o Címzési előírások megsértése o Aritmetikai és logikai műveletek miatti megszakítás (kivételek:tömbindextúlcímzés, 0-val való osztás, overflow) Szándékos o Rendszerhívások (pl. az Intel CPU-k overflow flag-je jelzi, ha túlcsordulás lépett fel. Az INTO utasítással egy megszakítás kérhető: korrekció) Megszakítás-kiszolgálás 1. egy egység aktiválja az INTR
bemenetet 2. a CPU elfogadja ezt az INT kérést, ha megszakítható állapotban van megfelelő a prioritás nagysága a beérkezett megszakítás nincs maszkolva (letiltva) A 3 felt. teljesülése esetén INT elfogadva 3. minden utasítás-töréspontban a vezérlőegység megvizsgálja, hogy van-e megszakítás Észleli, hogy van megszakítás. Az INTACK vezérlővonal aktiválásával jelzi a megszakítási kérés elfogadását, mire a megszakítást kérő deaktiválja az INTR vonalat 4. CPU elmenti a verembe az aktuális állapot információkat (PC, flag) automatikusan 5. a megszakított program adatterének mentése (regiszterkészlet) 6. a megszakítást igénylő azonosítása (ha egy INT-hez több egység is tartozik) 7. megszakítás kiszolgálása 8. az adattér visszaállítása 9. A CPU a kiszolgálás végeztével visszaküld egy nyugtát az egységnek, az pedig deaktiválja a jelet A megszakítás kiszolgálása után a megszakított program
folytatódik, vagy nem (reset). Mindegyik INT-hez tarozik egy bit: a CPU ezeket vizsgálja, amikor fogadóképes. A megszakítást kérő azonosítása A legegyszerűbb lehetőség a megszakítások egyenkénti kiszolgálása, azok beérkezési sorrendjében. Hátránya, hogy a megszakítások kiszolgálása közben érkező megszakítást nem tudja kiszolgálni, így a halaszthatatlan kérelmek elveszhetnek. 1. Lekérdezéses (polling): Valamilyen sorrendben lekérdezzük az egységeket Hardveres úton: daisy chain Szoftveres úton: az operációs rendszer 2. Vektoros: A megszakítást kérő eszköz a kiszolgáló rutin kezdőcímét határozza meg a megszakítási vezérlő és a processzor számára Több megszakítási vonal esetén minden eszköz saját megszakítást kérő vezetékkel rendelkezik, így a kérelem helye egyértelműen megállapítható. 29. oldal, összesen: 95 Megszakítási rendszerek szintek szerint Egyszintű: Nincs lehetőség a kiszolgáló
rutin felfüggesztésére egy újabb megszakítási kérelem által. A kiválasztó logika a kiszolgálás közben érkezett megszakítások közül a legmagasabb prioritású engedélyezett megszakítás-kérést engedélyezi Az 1-es forrás szerinti kérés feldolgozása hosszabb ideig is eltarthat, viszont az 0-ás forrás megszakítás-kérése esetleg nem tűrhet ekkora halasztást. 1 INT 0 2 normál felh.-i szint t 1 2 0 0 2 Többszintű: keresi a pillanatnyi CPU-szintnél magasabb prioritás-szintű engedélyezett megszakítás-kéréseket. Kiválasztja a legalacsonyabb prioritás-szintűt PSW-csere esetén ez oly módon zajlik le, hogy a megszakított szint PSW-je Old PSW-ként tárolódik, a másik rekesz tartalma pedig New PSW-ként betöltődik a programállapot-regiszterbe. Az elfogadott megszakítás-kérés nyugtázódik Ha nem talál az utolsó szintnél magasabb prioritású engedélyezett kérést, akkor megengedi a legutolsó New PSW-ben megjelölt utasítás
végrehajtását. 0 0 1 2 3 1 1 2 1 2 0 t 2 Kompromisszum: az előző kettő ötvözése, azaz szinteket rendelnek a megszakítások egy-egy csoportjához 0 1 2 3 0/a 1/a Szinten belül egyszintű, szintek között többszintű 1/a 2/a 1/a 0/a 2/a 2/b 2/b t 2/a 2/b 30. oldal, összesen: 95 SzA13. A külső sínrendszer (fogalma; jellemzői; csoportosítása, a sínfoglalás (bus arbitration) módjai; az adatátvitel és felügyelete (szinkron, aszinkron)) Fogalma: - Műszaki: Olyan vezetékköteg, melynek minden egyes erén vagy csak a logikai 0-nak megfelelő 0 Volt, vagy csak a logikai 1-nek megfelelő +12, +5, +3.3, +28 Volt jelenhet meg - Funkcionális: Olyan vezetékköteg, mely lehetővé teszi egyszerre n bit továbbítását a forrástól a célig. Ebben a kontextusban a sín fogalmába beleértjük a sín forgalmát vezérlő intelligenciát is Jellemzői: - A vezetékek száma. - Napjainkban tipikusan megosztott eszköz: a) Minden vezeték egy
időpillanatban 1 bitnyi információt továbbíthat b) Mindig csak egyetlen adó lehet, vevőoldalon lehet több eszköz is. - Regiszter tulajdonsággal rendelkezik. Értelmezett: r1r0 úgy történik, hogy: databusr0 r1databus Csoportosítás: - Átvitel iránya szerint: a) Szimplex: egyirányú. b) Duplex: egy időben egyirányú; kétirányú. c) Full-duplex: egy időben kétirányú (két vezeték van). d) Pl.: Egyirányú: órajel, reset, cím Kétirányú: adat - Az átvitel jellege szerint: a) Dedikált sín: 1. Jellemzői: Minden egységet minden egységgel összekötünk. Egysínes: (n×(n–1)) /2 sín. U3 U4 Kétsínes: n×(n–1) sín. 2. Előnyei: a. Gyors: minden egység minden egységgel párhuzamosan kommunikálhat b. Megbízhatóság: amennyiben biztosított az infrastruktúra, akkor pl. az U1-U2 közötti szakadás esetén a két egység továbbra is kommunikálhat U3 vagy U4 egységen keresztül. 3. Hátrányai: a. Drága b. Újabb egységek
csatlakoztatása bonyolult c. Újabb csatlakozási felületek kialakítása bonyolult d. Újabb csatlakozási felületek kialakítása technológiai nehézséget jelent. U1 31. oldal, összesen: 95 U2 b) Közös (shared) sín: 1. Jellemzője: Minden egység egyetlen közös sínen keresztül kommunikálhat U1 U2 Un 2. Előnyei: a. Olcsóbb (nem sokkal) közös sín b. A szabványos csatlakozási felületek miatt könnyű az újabb egységek csatlakoztatása. 3. Hátrányai: a. Lassúbb, mivel egyidejűleg csak egyetlen adó lehet a sínen, a többinek várnia kell a sín felszabadulására. b. Érzékeny a közös sínrendszer meghibásodására c. A közös sínrendszer vezérlése bonyolult (nem olcsó) Funkcionális csoportosítás: a) Címsín: 1. Feladata: Az egységek (pl: hálókártya) illetve egységrészek (pl: memóriacím) azonosítása 2. Fejlődése az Intel esetében: 20 bit v. v 4 bit v. v 20 bit 80386 20 bit vezérlő vezetékek 80286 8088 - v. v 4 bit
v. v 8 bit v. v 20 bitnél 1MB-ot tudunk megcímezni, 24 bitnél már 16MB-ot, 32 bitnél 4GB-ot. Napjainkban is 32 bit a címzési lehetőség 3. A kompatibilitás megtartása nem eredményezett tiszta tervet b) Adatsín: 1. Feladata: Adatok továbbítása 2. Fejlődése: a. 8088 – 8 vezetékes volt b. 80286 – 16 vezetékes volt c. 80386– 32 vezetékes 3. A kompatibilitás megtartása nem eredményezett tiszta tervet c) Közös adat- és címvezeték: 1. Akkor alkalmazzák, amikor: a. vezetéket kívánnak megtakarítani, vagy b. a csatlakozó lábak számát szeretnék csökkenteni 2. Külön vezérlővezetékkel kell jelezni, hogy mi van az adott pillanatban a sínen (cím vagy adat). 3. Akkor érdemes alkalmazni, ha blokkos átvitelt használunk A blokk kezdőcíme átvitele után a többi cím inkrementálással megállapítható. 4. Időbeli multiplexelés elvén alapul 5. Pl: PCI 32. oldal, összesen: 95 d) Vezérlővezetékek (sín): 1. Számuk tipikusan 10-15 db 2.
Fajtái: a. Adatátvitel vezérlése: 1. R/W – read/write: a processzor nézőpontjából mutatja az átvitel irányát. 2. B/W – byte/word: hány bitet kell párhuzamosan átvinni. 3. A/D – address/data: a közös vezetékeken cím vagy adat van-e. 4. AS – address strobe: a címet felhelyeztük a sínre. 5. DS – data strobe: az adatot felhelyeztük a sínre. 6. M/U – memory/unit: a címvezetéken memóriacím van-e vagy egységcím. 7. RDY – ready: kész. b. A megszakítások vezérlése: A megszakítások kérése és engedélyezése. c. A sínhasználattal kapcsolatos vezérlővezetékek: A sínhasználat kérése, engedélyezése, a sínfoglaltság jelzése. d. Egyéb: 1. CLCK – órajel 2. Reset – kezdeti értékek visszaállítása Az összekapcsolt területek alapján: M1 CPU - Mn bővítősín Sínvezérlő rendszersín I/O1 I/On a) Rendszersín: 1. A rendszersín tipikusan gyorsabb, mint a bővítősín 2. A rendszersín nehezen
szabványosítható, mivel CPU közeli sajátosságok kihasználásával teljesítménye növelhető 3. Elnevezések: a. Rendszersín: A rendszer adatforgalom itt zajlik b. Memóriasín: Memóriablokkok összekapcsolása c. Processzorsín: 1. A winchesteren tárolt adatokat a DMA vezérlő segítségével közvetlenül a memóriába visszük 2. A processzor pedig a másodszintű gyorsítótárból dolgozik b) Bővítősín: 1. Feladata: az I/O egységek csatlakoztatása a processzor-memória kettőshöz 33. oldal, összesen: 95 2. Fejlődése: a. Kábelekkel egyedi módon csatlakoztatták a perifériákat b. DEC első gépei sín-orientáltak voltak Aljzatokat alakítottak ki tesztkészülékek csatlakoztatására. Megoldásaikat szerzői jogi védelem alá helyezték. c. 1976: az Altair tervezője kialakította az S-100-as bővítősín architektúrát, mely 100 db érintkező felületet biztosított Ezt az IEEE szabványként fogadta el. d. 1981: IBM PC 3. Elnevezések: a.
bővítősín b. I/O sín c. helyi sín A sínrendszer működése Megosztott sínrendszer esetén két fázisból áll: - A sínfoglalás (bus arbitration) – ha két vagy több egység szeretne master lenni, akkor sínütemezésre van szükség, hogy a káoszt elkerüljük - A sínhasználat (bus timing) – maga az adatátvitel folyamata Sínfoglalás: Soros sínfoglalás: - Hardver lekérdezéses (daisy chain – gyermekláncfű). Előnyei: a) Kevés vezetéket igényel (olcsó) b) Elvben végtelen számú egységet tudunk csatlakoztatni Hátrányai: c) A prioritás hardveres úton szabályozott (merev) d) Az előrébb álló egységek elnyomhatják a hátrébb állókat e) Érzékeny a bus grant vonal meghibásodására Működése: Amikor az ütemező egy sínkérést észlel, használati engedélyt ad ki oly módon, hogy beállítja a sínhasználat engedélyezése jelet. Ez sorban keresztülfut az összes egységen Amikor az ütemezőhöz fizikailag legközelebbi eszköz
meglátja az engedélyezést, ellenőrzi, hogy ő adta-e ki a kérést. Ha igen, akkor átveszi a sínt, és nem továbbítja az engedélyt a következő eszköznek. Az egységek távolsága egyben a prioritásukat is meghatározza. 34. oldal, összesen: 95 - Szoftver lekérdezéses (software polling). Előnyei: a) A prioritás szoftveres úton szabályozott (rugalmas) b) Kevésbé érzékeny a bus grant vonal meghibásodására Hátrányai: c) több vezérlővonal (drága) d) A csatlakoztatható egységek számát a bus grant vonalak száma korlátozza, példánkban maximum 23=8 db Párhuzamos sínfoglaltság: a) Előnye: gyors b) Hátránya: még több vezérlővonalat igényel (még drágább), pl.: PCI Rejtett sínfoglalás: - Előfeltétele: két, egymástól független hardver vezérelje a sínfoglalást és az adatátvitelt - Amíg az aktuális adatátvitel folyik, az alatt lehetőség van az adatsín következő használójának kiválasztására Adatátvitel (bus
timing) Szinkron adatátvitel - Fogalma: Az adatátvitel mind az adó, mind a vevő számára előre ismert időintervallumban történik - Óra-ütemadó: a) Mind az adó, mind a vevő közös forrásból kapja az órajelet (akkor alkalmazzák, ha kicsi a távolság az adó, és a vevő között) 35. oldal, összesen: 95 b) Mind az adónak, mind a vevőnek saját, de azonos frekvenciával járó óra-ütemadója van. Ezek időben elcsúszhatnak egymástól, ezért egy szinkronjel segítségével hangolják össze a működésüket Értékelése: - Előnye: olcsó, egyszerű a megvalósítása - Hátrány: Az előre ismert idő intervallum hosszát mindig a leglassúbb egység határozza meg ez visszafogja a gyors egységeket (ez kiküszöbölhető többszintű sínrendszer alkalmazásával, ahol átviteli-sebesség függő tartományonként csoportosítják az egységeket) A Bővítősínek fajtái: - Átviteli sebesség szerint (szinkron meghajtású sínek): a)
Kompatibilitási vagy hagyományos sín (~ 5MB/s) b) Helyi sín, pl.: PCI (lehet 132 vagy 264 MB/s) c) AGP 1x (500 MB/s) - Tervezési szempontok szerint: a) Platformfüggő, pl.: ISA, EISA b) Platformfüggetlen, pl.: USB, SCSI, PCI Aszinkron adatátvitel - Fogalma: Az előző elemi művelet befejeződése egyben jelzés a következő elemi művelet kezdetére. - Egyvezetékes (egy vezérlővezeték) a) Adó oldali vezérlés: Először az adat az adatsínre kerül, majd késleltetést alkalmazunk. Hátránya: Az adónak nincs visszacsatolása arról, hogy a vevő valóban elolvasta-e az adatsínre helyezett adatot Lehet, hogy a vevő ki van kapcsolva (Jobbra az alsó ábrán: Data; Data ready) b) Vevő oldali vezérlés: Ez biztonságosabb átvitelt jelent, mert a vevő az átvitel igénylésének pillanatában aktív, de továbbra sincs visszacsatolás az adat célba érkezéséről. (Jobbra az alsó ábrán: Data; Data request) 36. oldal, összesen: 95 - Kétvezetékes
átvitel (handshaking - kézfogás) a) Adó oldali vezérlés: az alsó ábrán Data, Data Ready, Data Acknowledge b) Vevő oldali vezérlés: az alsó ábrán Data, Data Request, Data Ready 37. oldal, összesen: 95 SzA14. A processzor részvételével zajló I/O rendszer (a programozott I/O, a különálló I/O címtér és az I/O port; a memóriában leképezett I/O címtér; működése (feltétlen és feltételes)) I/O Rendszer Programozott I/O DMA A processzor közreműködésével Címzés A processzor működése nélkül Működés Fogalma, jellemzői Működése Különálló I/O címtér blokkos feltételes cikluslopásos feltétlen Programozott I/O Fogalma: minden egyes I/O művelethez a processzornak egy-egy utasítást kell végrehajtania Fajtái címtér szerint: Különálló I/O címtér. - Elve: A processzor két különálló címteret lát. - Jellemzői: a) A címsín szolgál: 1. az operatív tár, 2. és az I/O egység címzésére b) Létezik
olyan vezérlővonal (memória / I/O) mely megmutatja, hogy az adott időpillanatban a címsínen memória vagy I/O cím található c) mivel két különálló címtérről van szó, ugyanaz a cím szerepelhet memóriacímként és I/O címként is. d) Pl.: Intel esetében az eszköz 16 biten címezhető meg (65536 féle I/O cím). 38. oldal, összesen: 95 e) azon regisztereket, amelyeken keresztül a processzor a perifériákkal kommunikálhat, I/O portnak nevezzük, amely fizikailag a vezérlőkártyán helyezkedik el - Az I/O Port regiszterei: a) Parancs (command) regiszter, amelybe a processzor írhatja a kívánságait a perifériákhoz b) Adat (data) regiszter 1. Data input regiszter: ebből olvassa a processzor a perifériától kapott adatokat 2. Data output regiszter: ebbe írja a processzor a periféria számára küldött adatokat c) Állapot (Status) regiszter: innen olvassa a processzor a periféria üzeneteit d) Az input, output regisztereket a mai gyakorlatban
összevonják: parancs állapot regiszter, adat input-output regiszter. e) Napjainkban az I/O porton belül több regiszter is található, pl.: 1. I/O egység működőképességét jelző regiszter 2. I/O egység típusát, konfigurációs jellemzőit tároló regiszter (plug & play) 3. a nagyobb teljesítményű, összetettebb I/O egységeknél több parancs-, adat-, és állapotregiszter lehetséges A különálló I/O címtér megvalósítása: - Következmény: a) Különálló utasítások szolgálnak a memória-műveletekre (pl.: load/store), és b) Különálló utasítások szolgálnak az I/O műveletekre. Pl: Intel esetében 1. inX: a processzor olvassa be az X című I/O port adatregiszterét az AC-ba outX: a processzor beírja az AC tartalmát az X című I/O port adatregiszterébe - Értékelés: a) Előnyei: egyszerű, olcsó a megvalósítása b) Hátránya: a processzor részt vesz az I/O műveletekben szűk keresztmetszet c) az AC szűk keresztmetszetet
jelent nagy tömegű I/O számára 39. oldal, összesen: 95 d) Pl.: Hálókártya (ISA), amely az IBM PC-nél különálló IO címtérrel rendelkezik e) Minden mai piacon lévő processzorban megtalálható A Memóriára leképzett I/O (Memory mapped I/O) Elve: Ezt látja a processzor Processzor Ezt az I/O egység látja Jellemzői: - A megosztás: a processzor memóriakezelő utasítással (load-store) éri el azt a közös memóriaterületet, amit a periféria is kezelhet Ebben az esetben az I/O egység használhatja a rendszersínt nagyobb az átviteli sebesség Megvalósítása: Értékelése: - Jóval gyorsabb, mint a különálló I/O címtér (előny) Minden I/O esetén a processzornak egy utasítást végre kell hajtania (hátrány) Pl.: Az IBM PC-nél a képernyőkezelés Működése: Feltétlen átvitel: - A vevő mindig vételre kész állapotban van - Nem ellenőrizzük az átvitel sikerességét - Nincs szinkronizálás a vevő és az adó között. - Pl.:
LED Feltételes átvitel: - Lekérdezés (wait for flag) a) A processzor beírja a kívánságát az I/O port parancsregiszterébe b) A processzor kiolvassa az I/O egység állapotregiszterének tartalmát c) Amennyiben nem „ready”, akkor vissza a (b) pontra d) Amennyiben „ready”, akkor kiolvassa az I/O egység adott adatregiszterének tartalmát, majd beírja azt az akkumulátorba (AC) Értékelése: A processzor - I/O egység közti sebességkülönbség miatt a proceszszor akár több milliószor olvassa be feleslegesen az állapotregiszter tartalmát 40. oldal, összesen: 95 - Megszakításos: a) A processzor beírja a kívánságát az I/O egység parancsregiszterébe, majd elkezd mást csinálni b) Amikor az I/O egység begyűjtötte a perifériától a szükséges adatot az adatregiszterben: 1. Beállítja az állapot regiszter „ready” bitjét, és 2. Megszakításkérést küld a processzor felé c) A processzor a következő utasítás-töréspontban
elkezdheti a megszakításkérés feldolgozását 1. Beolvassa az I/O egység állapotregiszterét 2. ha ott a „ready” bit be van állítva, akkor egy ennek megfelelő megszakítás-feldolgozó programot indít el; ez kiolvassa az I/O port adatregiszterét és tartalmát átviszi az AC-ba SzA15. A közvetlen memória-hozzáférés (DMA) (fogalma; megvalósítása; működése: blokkos és cikluslopásos üzemmód) Fogalma: nagy tömegű adat gyors periféria alkalmazásával történő átvitele, a processzor közreműködése nélkül Elve: Megvalósítása: DC – decrementer I/O AR – I/O Address Register I/O DR – I/O Data Register 41. oldal, összesen: 95 Működése: - a DMA vezérlő „felprogramozása”: programozott I/O-val átvisszük a processzorból a DMA vezérlőbe az átvitelt leíró alapinformációkat: a) A DC-be beírjuk az átviendő adategységek számát b) Az I/O AR-be beírjuk az átviendő memóriablokk kezdőcímét c) Az adatátviteli egysége
(byte, félszó, szó) d) Az átvitel irányát e) A résztvevő periféria címét, és a DMA vezérlő címét f) Az átvitel módját blokkos vagy cikluslopásos módon - Blokkos vagy (burst) üzemmód (pl.: Winchester esetén memóriacíminkrementálás) a) Mihelyt a DMA vezérlő előkészítette az első átviendő adatelemet az I/O DR-ben, akkor egy DMA request jelzést küld a processzornak. Ezzel kéri a rendszersín használati jogát! b) A processzor DMA acknowledge jelzéssel lemond a rendszersín használati jogáról c) A DMA vezérlő beírja az I/O DR tartalmát az I/O AR által kijelölt memóriacímre, majd a DC értékét csökkenti, az I/O AR értékét növeli d) Ez a ciklus addig fut, míg a DC értéke nullára nem csökken - Cikluslopásos (cycle stealing) átvitel Értékelése: Míg az utasítás-töréspontban a megszakítás feldolgozással a processzorra további munka várhat, addig a DMA töréspontban a DMA vezérlő a processzor helyet dolgozhat.
SzA16. Hagyományos számítógépek felépítése, működése (felépítési vázlat, működés) Korlátaink – jellemzők: - minden utasítás két byte hosszú (256 lehetséges cím): MK címrész 1 byte 1 byte - két egységből áll - Processzor - Memória 42. oldal, összesen: 95 - utasításkészlet: - Összeadó: - ADD 100 AC:=AC+100. ADD [100] AC:=AC+Memo[100] //ez egy memóriahely Inkrementálás AC:=AC+1. Nullázás AC:=0; Betöltés a regbe LOAD [100] AC:=Memo[100]. Kiírás a memóriába STORE [100] Memo[100]:=AC. Feltétlen ugrás JMP 120 PC:=120; o Vezérlőrész PC Memória PC tartalma: 100 LOAD[200] 102 ADD[201] 104 STORE[202] 106 JUMP 120 ALU Címsín MAR A MUX IR MDR DEC Adatsín AC Processzor //azért kettesével növekszik mert 2 byte az utasításhossz I. Utasítás-lehívás (fetch) A PC mindig a következő végrehajtandó utasítás címét tartalmazza. Az utasítás lehívás minden utasítás esetén megegyezik. MAR PC MDR
(MAR) IR MDR PC PC+1 II. Utasítás-végrehajtás (execution) - adatbehívás (load) DEC IR MAR DEC címrész IR MDR PC PC+1 - aritmetikai-logikai utasítás, pl. összeadás DEC IR MAR DEC címrész MDR (MAR) AC AC + MDR vagy AC AC – MDR vagy 43. oldal, összesen: 95 AC AC AC * MDR vagy AC / MDR - adattárolás (store) DEC MAR MDR (MAR) IR DEC címrész AC MDR - a feltételes ugrás DEC PC IR DEC címrész SzA17. Számítógép architektúrák osztályozása (Flynn-féle, illetve korszerű osztályozás) Flynn féle csoportosítás a hatvanas évekből: o Értelmezett fogalmak: SI – Single Instruction Stream: egyetlen vezérlő egyetlen utasításfolyamot bocsát ki MI – Multiple Instruction Stream: a vezérlő több, egymástól elkülönülö folyamatot bocsát ki SD – Single Data Stream: A műveletvégző egyetlen adatfolyamot hajt végre, dolgoz fel. MD – Multiple Data Stream: A
műveletvégzők több adatfolyamot dolgoz fel. o A fogalmak kombinációi: Az architektúrák: SISD: szekvenciális architektúra SIMD: multiple 3D feldolgozás MISD MIMD o Értékelése: Hátránya, hogy nem mutatja Sem a párhuzamosság forrását (adat) Sem pedig a szintjét (szál/utasítás) 44. oldal, összesen: 95 Párhuzamos architektúrák korszerű csoportosítása Adatpárhuzamos Funkcionálisan párhuzamos Vektorprocesszorok Asszociatív és neurális processzorok SIMD Szisztolikus architketúrák Utasításszinten párhuzamos architektúrák Futószalag Szálszinten párhuzamos VLIW (Very Long Instruction Word) Folyamatszinten párhuzamos Szuperskalár Utasításszinten párhuzamos architektúrák (Instruction Level Parallelism – ILP) Az ILP architektúrák fő fejlődési útja Neumann-féle szekFutószalagos venciális architektúra (pipeline) processzo1950 rok 1985 Soros kibocsátás, soros végrehajtás Soros kibocsátás,
párhuzamos végrehajtás Szekvenciális feldolgozás Időbeli párhuzamosság Egyetlen processzorban egyetlen, nem futószalagos végrehajtó egység Futószalagos processzor, több, nem futószalagos végrehajtó egységgel Szuperskalár processzorok 1990 Szuperskalár processzorok MM/3D kiegészítéssel 1994 Párhuzamos kibocsá- Párhuzamos kibocsátás, párhuzamos vég- tás, párhuzamos végrehajtás rehajtás, utasításokon belüli párhuzamosság (SIMD) Időbeli párhuzamos- Időbeli párhuzamosság, kibocsátásbeli ság, kibocsátásbeli párhuzamosság párhuzamosság, utasításon belüli párhuzamosság Több futószalagos MM/3D kiegészítésvégrehajtó egységet sel rendelkező szutartalmazó VLIW és perskalár processzorok szuperskalár processzorok 1. 1950 Neumann-féle szekvenciális architektúra: soros kibocsátás és végrehajtás 45. oldal, összesen: 95 2. 1985: Futószalag processzorok: Időbeli párhuzamosság Megvalósítási technikái: -
Futószalag (időbeli párhuzamosság) - A Többszörözés (térbeli párhuzamosság) A végrehajtó egység szakosodott, pl.: fixpontos / lebegőpontos A futószalag processzorok teljesítményét: - hatékony memória alrendszerrel (gyorsító tárak), és - hatékony ugrás előre jelzéssel juttatták el az ezen az úton elérhető teljesítmény határáig 3. 1990: Kibocsátásbeli párhuzamosság – szuperskalár processzorok - A futószalagos végrehajtó egységeket többszörözték, tehát az időbeli párhuzamossághoz hozzáadódott a térbeli párhuzamosság - Előzmények: o Mivel a többszörözött futószalagelvű végrehajtóegységek óraciklusonként egynél több utasítást is képesek lettek végrehajtani, a soros kibocsátás szűk keresztmetszetet eredményezett. Ennek feloldására vezették be a párhuzamos kibocsátást - Fejlődési irányok: o Statikus ütemezésű VLIW processzorok (egyszerűbb) o Dinamikus ütemezésű szuperskalár processzorok
(bonyolultabb) A szuperskalárok fejlődése - Első generációs szuperskalárok: o Közvetlen (nem pufferelt) utasítás-kibocsátás o Elágazásbecslés o Korszerű memória alrendszer - Második generációs szuperskalárok: o Pufferelt (közvetett) utasítás kibocsátás o Regiszter-átnevezés Ezzel az általános célú programok vonatkozásában kimerültek az ILP processzorokban rejlő teljesítménynövelési lehetőségek (ILP). 4. 1995: Utasításbeli párhuzamosság jellemzi: MM/3D kiterjesztés - A SIMD elv alkalmazásával gyorsul a vektorgrafikus műveletvégzés 46. oldal, összesen: 95 SzA18. Adatfüggőségek (fogalma, főbb fajtái, teljesítmény-korlátozó hatása) Az adatfüggőségek fogalma: Ha egy program két egymást követő utasítása ugyanazt a regiszter-, vagy memória operandust használja, kivéve, ha a közös operandus mindkét utasításban forrás operandus. Az adatfüggőség nyilvánvaló esete az, hogy a soron következő utasítás az
előző utasítás eredményt használja forrás operandusként Amíg egy processzor az utasításokat sorosan hajtja végre, az adatfüggőségek nem okoznak gondot Más a helyzet, ha az utasításokat a processzor párhuzamosan dolgozza fel, mint ILP végrehajtásnál Ilyenkor az adatfüggőségek észrevétele és megfelelő kezelése a processzor elsődleges feladatává válik Az adatfüggőségek főbb fajtái: Adatfüggőség Jellege szerint Soros utasításSzekvenciákon Valós függőség (RAW) Helye szerint Ciklusban Regiszter Memória Álfüggőség WAR WAW RAW-függőség (írást követő olvasási függőség, true dependence). Valamely utasítás forrásoperandusza felhasználja a másik utasítás eredményét i1: load r1, a // r1 <=(a) i2: add r2,r1,r1 // r2 <=(r1)+(r1) Az i2 utasítás az r1 regisztert, mint forrást használja. Így az i2 utasítás mindaddig nem hajtható végre helyesen, míg az i1 utasítás nem hajtódik végre és eredménye nem
áll rendelkezésre Ezért i2 utasítás RAW-függőségben van az i1 utasítástól. A RAW függőségek fajtái Behívási függőség: a kívánt operandust előbb be kell olvasni (r1-be) ahhoz, hogy i2 végrehatható legyen. i1: load r1, a // r1<=(a) i2: add r2,r1,r1 // r2<=(r1)+(r1) Műveleti függőség: ha a keresett operandust a megelőző utasítás aritmetikai, logikai stb. műveletek eredményeként állítja elő i1: mul r1, r4, r5 // r1<=(r4)*(r5) i2: add r2, r1, r1 // r2<=(r1)+(r1) WAR-függőség (olvasást követő írásfüggőség, anti dependence) Valamely utasítás célregisztere megegyezik az előző utasítás forrásregiszterével i1: mul r1, r2, r3 //r1<=(r2)*(r3) i2: add r2, r4, r5 //r2<=(r4)+(r5) 47. oldal, összesen: 95 Ebben az esetben, az i2 utasítás az r2 regiszterbe ír, míg az i1 utasítás r2 tartalmát forrásoperandusként használja. Ha bármely okból i2 előbb hajtódik végre, mint i1, akkor r2 tartalmát i2 korábban
írná át, mint ahogy azt i1 olvasná, és ez nyilvánvalóan hibát eredményezne. WAW-függőség (írást követő írásfüggőség, output dependence) Valamely utasítás célregisztere megegyezik az előző utasítás célregiszterével i1: mul r1,r2,r3 // r1<=(r2)*(r3) i2: add r1,r4,r5 // r1<=(r4)+(r5) A ciklusbeli adatfüggőség: Ciklusokban megjelenő függőségek. Akkor van, ha a ciklusmag valamely utasítása olyan értékre hivatkoznak, amely valamely előző ciklus eredménye Fontos probléma, mivel a futásidőt döntően a ciklusok összideje adja ki (80/20-as szabály) Kezelésük a compiler feladata Pl. do i=2, n x(i)=a(i)*x(i-1)+b enddo Elsőrendű ciklusok Ha a ciklus az őt közvetlenül megelőző ciklus eredményét használja fel. Általános formája: X(i) = a(i) * X(i-1) + b(i) Teljesítmény-korlátozó hatása - valódi adatfüggőség (RAW): ki kell várni, amíg a szükséges adat elkészül. Nem lehet kiküszöbölni - hamis adatfüggőség (WAR,
WAW): csak az ugyanarra a tároló helyre hivatkozás miatti függőség, regiszter átnevezéssel megszüntethető. Valódi adatfüggőség esetén,a teljesítménycsökkenés nem kiküszöbölhető, de csökkenthető, részlegesen feloldható utasítás várakoztatással és eredmény előreküldéssel. SzA19. Regiszter adatokra vonatkozó ál- és valódi adatfüggőségek teljesítmény korlátozó hatásának csökkentése, illetve kiküszöbölése (utasítás várakoztatás, regiszter átnevezés, eredmények előreküldése, három- operandusú utasítások elve) Utasítás várakoztatás: Az utasítás várakoztatás célja az utasítások között fellépő függőségek hatására létrejövő kibocsátási blokkolások megszüntetése. Ezt úgy éri el, hogy a VP felé függőségek vizsgálata nélkül kibocsátja (issue) a dekódolt utasításokat, majd ezek után végez függőség vizsgálatot, a VP-ben lévő utasítások között. A nem függő utasításokat
kiküldi (dispatch) a VE felé Regiszter átnevezés: Az álfüggőségek megszüntethetők, például regiszter operandusok esetén regiszterátnevezéssel. Regiszterátnevezéskor az i2 utasítás célregiszterének nevét kell egy jelenleg nem használt másik névre változtatni: i1: i2: mul r1, r2, r3 => add r2, r4, r5 => i1: mul r1, r2, r3 i2: add r36, r4, r5 48. oldal, összesen: 95 // r1 <= (r2)*(r3) // r36 <= (r4)+(r5) Az álfüggőségek jelentős mértékben akadályozzák az ILP processzorok teljesítőképességének kihasználását. Ezért ezeket vagy a fordítóprogram statikusan, vagy az ILP-processzorok dinamikusan megszüntetik (Pl: részleges RISC 6000, teljes ES/9000) Megvalósítás: minden célregisztert átneveznek, átnevezéseket követni kell források átnevezése, átnevezési tábla, átnevezések érvényességét kezelni kell., r22 tartalmát vmikor be kell írni r1-be. Eredmények előreküldése (result bypassing): Célja a RAW
időbeli negatív hatásainak csökkentése. Elve: a végrehajtó egység által szolgáltatott eredményt nemcsak a regisztertárba vezetik vissza, hanem minden olyan VE bemenetére is, amely ezt az eredményt forrás operandusként felhasználja: add sub r1, r2, r3 r4, r5, r1 // r1<=(r2)+(r3) // r4<=(r5)-(r1) Megvalósítás: FX Hármoperanduszú utasítások elve Bevezették az úgynevezett i=a*b+c szemantikájú utasításokat és ezt nevezték el 3 operandusu utasításnak több különböző néven pl. multiple add Lényege 3 operanduszal végez egyszerre műveletet és két művelet egyidejű végrehajtását szolgálja. Ezeknél az utasításoknál a párhuzamosság mértéke 2 Alkalmazása dedikált célokra hasznos az-az tudományos műszaki számítások Általános programoknál a gyorsítás mértéke elhanyagolható Mivel a 2 operandusú utasítások átnevezése 3 operandusú utasításokhoz vezet, ezért ehhez egy belső utasításformátum konverzió is
szükséges. Cél: regiszterátnevezés megvalósítása (Pl.:ES/9000) SzA20. Vezérlésfüggőségek és teljesítmény korlátozó hatásuk csökkentése (vezérlésfüggőségek fogalma, teljesítmény korlátozó hatása és annak csökkentése, a feltétlen vezérlésátadás, a statikus és dinamikus elágazásbecslés, valamint a spekulatív elágazás-kezelés elve) Vezérlőfüggőség fogalma: Elágazáskor a processzor (ugrás esetén) nem az elágazás utasítás utáni utasítást olvassa be, dekódolja, stb. hanem az ugrás címén találhatót Ehhez feltétlen ugrásnál is címet kell számítani, feltételes ugrás esetén pedig feltétel vizsgálatot is kell végezni Mindez időbe telik és addig az egységek nem tudnak dolgozni (úgynevezett buborék keletkezik). Tehát itt is függ a feldolgozás az előző (elágazás) utasítástól. Feltétlen elágazás – késleltetett ugrás: 49. oldal, összesen: 95 Probléma: MUL JMP címke ADD címke SHL Mivel a JMP
hatására feltétlen ugrás következik be, az ADD utasítás nem hajtódik végre. Nem az ADD hanem az SHL a következő (a JMP utáni) utasítás: - feleslegesen hívjuk le az ADD utasítást, sőt - veszélyeztetjük a regiszter-tartalmakat Kezelése: - utasításrés (buborék) segítségével - Kétfokozatú futószalag: 1 utasításrés - Négyfokozatú futószalag: 3 utasításrés. - n fokozatú futószalag: n-1 utasításrés (a futószalag miatt kell az n-1-edik eredmény a végeredményhez) - Statikusan történik, a compiler által o Egyszerű compiler: minden feltétlen ugrás után beszúr egy NOP-ot (kétfokozatú futószalag esetén) Értékelés: bár felesleges műveletet végzünk (egy ciklus), de már nem veszélyeztetjük a regiszter-tartalmat o Optimalizáló compiler: A compiler a JMP utasítás előtt adatmanipuláló utasításokkal kísérli meg feltölteni az utasításrést Pl.: JMP címke MUL ADD címke SHL Amennyiben az utasításrés
mérete 1 akkor a feltöltés valószínűsége 85%, ha nagyobb, akkor az esély csökken Ezt a megoldást korai RISC processzorok alkalmazták Ezzel megszűnt a ciklus-veszteség is! Elágazások gyakorisága általános célú programokban 20-30%, tudományosoknál 5-10%. Feltételes elágazások gyakorisága általános célú programoknál 20%, tudományosnál 5-10%. Általános célú programok esetén a legtöbb vizsgálat meglepően alacsony gyorsítási lehetőséget mutat, 1.2 – 30 értékek között, 2 körüli átlagértékkel Tudományos programoknál a párhuzamos végrehajtásával elérhető gyorsítás mértéke valamivel nagyobb, 12 – 17 közötti tartományokba esik, 2-4 közötti átlagértékkel Ezeknek az eredményeknek az az oka, hogy a vezérlésfüggőségek erőteljesen behatárolták az utasítások párhuzamos végrehajtását. A feltételes elágazások alapblokkokra tagolják a programot, és a párhuzamosítás alapblokkonként
külön-külön történik (alapblokk-ütemezés). Mivel az alapblokkok viszonylag rövidek (az ütemezéshez csak kisszámú utasítás áll rendelkezésre), az adódó gyorsítás mértéke is alacsony marad. 50. oldal, összesen: 95 Többirányú elágazás: egy feltételes elágazás esetén mindkét lehetséges útvonalat egyidejűleg követik a feltétel kiértékeléséig, majd a feltétel kiértékelése után a helytelennek bizonyult útvonalat elvetik, és a helyes útvonalon folytatják a program végrehajtását. Spekulatív elágazáskezeléssel: A processzor minden függő feltételes elágazás esetén becslést végez a feltétel kimenetéről és az utasítások feldolgozását e becslésnek megfelelően vagy a soros vagy az elágazási ágon folytatja. A feltétel kiértékelése után a processzor ellenőrzi a becslést. Ha a becslés helyes volt érvényesíti a feltételes elágazást követően végrehajtott utasításokat és folytatja a feldolgozást Ha a
becslés hibás volt a feltételesen végrehajtott utasításokat törli és a végrehajtást a helyes ágon folytatja A statikus módszer: a becslést a processzor a tárgykód valamely jellemzőjéből származtatja pl. műveleti kódból az elágazás irányából, vagy a fordító program által adott ajánlásból A dinamikus módszer: az elágazás történetén alapul 1 bites eljárás: a processzor elágazásonként 1 bittel írja le az elágazás történetét. Ez jelzi hogy az elágazás a legutolsó végrehajtáskor bekövetkezet –e vagy sem. 80/20-as szabály Ha az előző ugrás teljesült, akkor a következő is fog. 2 bites eljárás: ha az egyes elágazások leírásához több bit áll rendelkezésre hosszabb lesz az elágazás-történet és így a becslés várhatóan pontosabb lesz. A processzor 2 biten (telített számláló) 4 állapotú véges automata ként tartja nyilván a múltat: 1. 2. 3. 4. 5. 00: határozott soros folytatás (ugrás esetén 01,
nem ugráskor 00 az új állapot) 01: gyenge soros folytatás (ugrás esetén 10, nem ugráskor 00 az új állapot) 10: gyenge elágazás (ugrás esetén 11, nem ugráskor 01 az új állapot) 11: határozott elágazás (ugrás esetén 11, nem ugráskor 10 az új állapot) Alapállapot az 11. SzA21. Szekvenciális konzisztencia (az utasítás-feldolgozás és a kivételkezelés soros konzisztenciája, a precíz megszakítás-kezelés) Szekvenciális konzisztencia Utasításfeldolgozás Szekvenciális konzisztenciája Kivételkezelés Szekvenciális konzisztenciája Utasítás-végrehajtás Memória-hozzáférés Szekvenciális konzisztenciája Konzisztenciája Memória-konzisztencia Processzor-konzisztencia 51. oldal, összesen: 95 Kivétel-konzisztencia Processzor-konzisztencia Probléma: MUL ADD JZ (JMP ZERO) Ha nem figyelünk, akkor a MUL értékére reagál! - Soros feldolgozás esetén, amennyiben az ADD eredménye nulla, akkor ugrik. - Párhuzamos feldolgozás esetén
várhatóan a MUL utasítás fejeződik be később, tehát biztosítani kell, hogy az ugrás továbbra is az ADD utasítás nulla eredménye esetén történjen Kivételek konzisztenciája Gyenge konzisztencia Erős konzisztencia Pontatlan megszakítás-kezelés Pontos megszakítás-kezelés Pontatlan megszakításkezelés: Probléma: MUL ADD JZ - - Párhuzamos feldolgozás esetén várhatóan az ADD utasítás fejeződik be hamarabb, és lehet, hogy pl. túlcsordulással – amennyiben ezt a processzor elfogadja, akkor az állapottere elveszti korrektséget, ami csak kiegészítő eljárásokkal lehet helyreállítani Ennek oka, hogy a korábbi MUL utasítás még definiálatlan s így felborulhat a kivételkezelés soros konzisztenciája Pl.: Power1 (1990) és Power 2 (1993) – csak a lebegőpontos utasításoknál Az Alpha processzorok viszont minden utasításnál Pontos megszakításkezelés - A processzor kizárólag az eredeti utasítás szekvenciának megfelelő
sorrendben fogadja el a megszakításkéréseket - Ehhez általában átrendező-puffert használ, így a processzor csak akkor fogadja el a megszakításkérést, amikor az adott utasítást kiírjuk az átrendező-pufferből. Pl: Az Intel processzorcsalád, és a mai processzorok 52. oldal, összesen: 95 SzA22. Az utasítások időben párhuzamos feldolgozásának alapvető lehetőségei (prefetching, átlapolt utasítás végrehajtás, futószalag elvű feldolgozás, ebből adódó szűk keresztmetszetek (memória sávszélesség és elágazások) feloldása) Futószalagos feldolgozás: - Előfeltételei (két fokozatot figyelembe véve): o Két egymástól teljesen független hardver egységet kell kialakítani o Mindkét egység feldolgozási ideje megegyezik o Az egyik egység kimenete lesz a másik bemenete Időbeli párhuzamosság (átlapolás) Következtetés: Kellően nagy számú utasítás esetén, két hardveregység használva, elvben megduplázódik a feldolgozás
sebessége - El Bontsuk négy részre az utasítás-feldolgozási ciklust: F Fetch D-S/O Decoding – Source Operand E Execution W/B Write Back Ekkor elvben megnégyszereződik az utasítás-feldolgozás sebessége, de a teljesítmény növekedését a függőségek mérséklik! - Előlehívás: Az előző utasítás visszaírási fázisát és az aktuális utasítás lehívási fázisát párhuzamosítjuk o maximum egy óraciklus nyerhetünk, amit a függőségek mérsékelnek o Példa: A hatvanas évek nagyszámítógépeinek egy része A 8086-os mikroprocesszor - Csak a végrehajtás fázisban (futószalag-elvű kialakítás): o Példa: Nagyszámítógépek: a 60-as évek vektorprocesszoros gépei Mikroszámítógépek: ez a fázis kimaradt 53. oldal, összesen: 95 - A teljes utasítás-feldolgozási fázisban o Maximum óraciklusonként tudunk feldolgozni egy utasítás, amit a függőségek mérsékelnek o Példa: Nagyszámítógépek (1960)
Mikroszámítógépek: 80286 A futószalagos feldolgozás következményei - Memóriakezelés: o A memória lassabb, mint a processzor. Hagyományos, szekvenciális elvű 4 ciklusú utasítás: Négyfokozatú futószalag esetén: Míg a hagyományos szekvenciális feldolgozásnál – a példánk esetében – csak minden negyedik óraciklusban kell utasítást lehívni, addig 4 fokozatú futószalagnál már maximum óraciklusonként, amit a függőségek csökkenthetnek. o A memória-alrendszert gyorsításokkal egészítették ki o A gyorsítótárak a 80-as évek második felében terjedtek el robbanásszerűen, a futószalagos feldolgozás terjedésével párhuzamosan - Vezérlés-függőségek: o Az okozott teljesítmény-redukció mértéke: Feltétlen vezérlésátadás esetén az ugrási rés (buborék) mérete N-1, ahol N a futószalag fokozatainak száma Feltételes vezérlésátadás esetén ehhez hozzájön a feltétel kiértékelés, az ugrási cím
számítása és a bonyolultabb dekódolás is o A teljesítmény-csökkenés mérséklése: A korai gépekben hardver-kiegészítéssel lehetővé tették, hogy a dekódolás végére előálljon az ugrási cím A korai RISC gépekben késleltetett ugrást alkalmaztak A CISC gépek esetén megjelent: A fix előrejelzés: A következő végrehajtandó utasítás mindig az ugrási címen helyezkedik el Az ugrási cím előáll a dekódolási szakasz végére, majd folytatják az utasítások lehívását az ugrási címet követően A feltételes vezérlés-átadásokban a feltételek kiértékelése az execution szakasz végén következett be: 54. oldal, összesen: 95 o Az előrejelzés helyes volt s folytatódott az utasítások feldolgozása az elkezdett irányba o Hibás volt, ekkor az elkezdett utasításokat eldobták és elkezdték a feldolgozást a helyes irányba. Pl: 80486 Feloldatlan feltételes vezérlési függőség: amikor a feltétel
nagy késleltetésű (látenciájú) (szorzás, osztás) utasításra vonatkozik, ami nem hajtódik végre a feltételes vezérlésátadási utasítás execution szakaszának végére ezért blokkolódik a feldolgozás. Pl.: a=x/y if a=1 (várnia kell az előzőre) SzA23. A futószalag (pipeline) elvű utasítás-végrehajtás, futószalag processzorok (a futószalag elve; jellemzői; logikai és fizikai futószalagok kiváltott szűk keresztmetszetek és feloldásuk) Futószalag (pipeline) => Gyakorlati vonatkozás: T – egy termék elkészülésének időtartalma. t – egy egység mennyi ideig van egy munkaállomáson Egyszerre n db készül! (t időközön- ként egy termék) n – futószalagon lévő egységek száma A futószalagos feldolgozás jellemzői 1. A fokozatok száma: A függőségek miatt sok utasítást kell eldobni! - Pl.: 1980, RISC I. – kétfokozatú, 1982, RISC II – háromfokozatú, napjainkban 15 – 20 fokozat 2. Újrafeldolgozás
Újrafeldolgozás nélkül: Újrafeldolgozással, pl.: szorzás, osztás esetén igen hosszú lenne, ha a részeredményeket műveletenként kimentenénk a regiszterekbe Helyette a részeredményeket az E fokozat végéről visszavezetjük az E fokozat bemenetére. (elemi műveletek sorozata) 3. Operandus-előrehozás 55. oldal, összesen: 95 4. Szinkron – aszinkron: napjainkban szinkron az elterjedt A futószalag logikai felépítése 1. szint: A futószalagok funkcionális meghatározása pl.: 2. szint: az egyes fokozatok által végrehajtandó elemi műveletek pl.: Fetch MAR ← PC MDR ← (MAR) IR ← (MDR) PC ← PC+1 A futószalagok fizikai felépítése - általános fizikai felépítés 1960-80 90-es évek (itt jelenik meg a többszörözés): 56. oldal, összesen: 95 - fizikai megvalósítás: o Univerzális futószalag: minden logikai futószalagot egyetlen fizikai futószalagon valósítunk meg, Pl.: RISC I o Master futószalag (Pentium I.): Két futószalag
közül: Az egyik minden utasítás végrehajtására alkalmas, A másik csak az egyszerűbb utasítások végrehajtására képes o Dedikált futószalag, pl.: ProwerPC 604 FX összetett: szorzás, osztás. Képes az újrafeldolgozásra Soros konzisztencia (CO): A konzisztencia biztosítja, hogy az utasítások az eredeti sorrendjüknek megfelelően kerüljenek kiírásra. CISC – RISC futószalagok: A CISC futószalagok jellemzően hosszabbak: - A címszámító fokozat illetve, - A gyorsítótár-elérés miatt SzA24. Szuperskalár processzorok megjelenése (az ötlet megjelenése, kísérleti és a kezdeti kereskedelmi rendszerek áttekintése, elterjedésük) A szuperskalár kibocsátás ötletét TJADEN és FLYNN már 1970-ben publikálta, de az elv pontosabb megfogalmazására csak jóval később, a ’80-as években került sor (TORN, 1982, ACOSTA és mások, 1986). A szuperskalár elnevezés egy IBM technical report-ban látott napvilágot 1987-ben (Super-Scalar
kísérlet), az elnevezés feltehetőleg a korabeli fejlesztésekkel (America, RS/6000) kapcsolatban született. Az IBM hatalmas előnyt és tapasztalatot szerzett azzal, hogy 1982-ben a Cheetah projektet, majd 1985-ben az America projektet útjára indította. A Cheetah szolgált az America alapjául, melyből később az RS/6000 nőtte ki magát (1990), melyet később Power 1-re keresztelték át. A DEC szintén fontos szerepet játszott a szuperskalár fejlesztések területén Multititan elnevezésű szuperskalár projektje révén, melynek fejlesztési munkái 1985-87 között folytak. Az azóta ismertté vált Alpha sorozat azonban nem ebből született, hanem egy későbbi, teljesen új, 1988-as RISCy VAX kódnevű projektből. Említést érdemel még két további fejlesztés 1988-89 környékén, a Stanford University és a japán Kyushu University projektjei. 57. oldal, összesen: 95 Projektek: The designation "superscalar" Cheetah project IBM America
project (4) Multititan (2) DEC Stanford U. MATCH (2) Kyushu U. SIMP (4) 1982 1987 1983 1988 1989 TORCH (2) DSNS (4) 1990 1991 A szuperskalár CISC-processzorok csak jelentős késéssel jelentek meg a piacon. Ennek oka a RISC-ekhez képest nagyobb bonyolultságban rejlik, mely két okra vezethető vissza. Először is, a RISC-ekkel szemben, a CISC-processzoroknak változó hosszúságú utasításokat kell dekódolnia. Másodszor, a memória architektúrájú CISC-processzorok csak sokkal nagyobb ráfordítással valósíthatók meg, mint a behívó/tároló (LOAD/STORE) architektúrájú RISCprocesszorok Megjelenésük a kereskedelmi rendszerekben: RISC processors Intel 960 960KA/KB M 88000 MC 88100 960CA (3) MC 88110 (2) HP PA PA 7000 PA7100 (2) SPARC MicroSparc SuperSparc (3) R 4000 MIPS R R 8000 (4) 29040 29000 sup (4) Am 29000 Power1(4) RS/6000 IBM Power 21064(2) DEC PPC 601 (3) PPC 603 (3) PowerPC 88 89 90 91 92 93 94 95 CISC
processors i486 Intel x86 Pentium(2) M 68040 M 68000 M 68060 (2) Gmicro/100p Gmicro Gmicro500(2) AMD K5 K5 (4) CYRIX M1 M1 (2) Denotes superscalar processors. 58. oldal, összesen: 95 A szuperskalárok megjelenése két csoportra bontható: Az egyik út a már meglévő (skalár) RISC-processzorcsaládok átkonvertálása volt szuperskalár családokká szuperskalár modellek bevezetésével. Pl: Intel 960, MC88000 és Sun Sparc processzorcsaládok. A másik út, eleve szuperskalár feldolgozást feltételező, új architektúrájú processzorcsaládok kifejlesztését jelentette. Pl: IBM RS/6000 (Power 1), a DEC Aplha proceszszorai, vagy a Power PC processzorcsalád SzA25. Első generációs (keskeny) szuperskalár processzorok áttekintése(közvetlen kibocsátás, végrehajtási modelljük, kibocsátási szűk keresztmetszetük) Jellemzői: - Közvetlen (nem pufferelt) utasítás-kibocsátás. - Statikus elágazásbecslés: o A programkód jellemzői
alapján történik az írás becslése o Pontosabb, mint a fix előrejelzés - A memória-alrendszer kétszintű gyorsítótárat tartalmaz: o L1: A processzorlapkán helyezkedik el Külön adat- és utasítás-gyorsítótár egyportos o L2: Külön lapkákon helyezkedik el Közös gyorsítótár az adatok és az utasítások számára A processzorsínre csatlakozik Közvetlen utasítás-kibocsátás: Megvalósítása: Utasítás-puffer Működési alternatívák: - Az utasítások sorrendiségének tekintetében o Sorrendben történő kibocsátás: a függő utasítások blokkolják az utasításkibocsátást 59. oldal, összesen: 95 o Sorrenden kívül történő kibocsátás: a függő utasítások nem blokkolják az utasítás-kibocsátást - Az utasítás-ablak feltöltése: o Az utasításokat egyenként pótoljuk o Az utasítások ablak teljes kiürülése után az egészet pótoljuk Tipikus példa az első generációs szuperskalárra: -
Sorrendben történő utasítás kibocsátás - Az utasítás-ablak teljes kiürülése után a teljes feltöltése - Az utasítás-ablak 3 db utasítást tartalma - Jelölés: Az i-edik ciklusban egyetlen utasítás tudunk kibocsátani, mert az i2 blokkolja a további utasítás kibocsátást. Az i+1 ciklusban időközben feloldódott az i2 függősége, ezért kibocsátható mind az i2, mind pedig az i3. Az utasítás-ablak ezáltal teljesen kiürül Az i+2 cikusban teljesen feltöltjük az utasítás-ablakot, és két független utasítást tudunk kibocsátani. Az első generációs szuperskalár RISC processzor működési modellje - Az utasítás feldolgozási rendszert alrendszerekre tudjuk bontani, és ezeket külön vizsgálhatjuk - Értelmezhetjük a rendszer átbocsátó-képességét (rátáját, szélességét) 60. oldal, összesen: 95 - A teljes utasítás-feldolgozási rendszer átbocsátási rátáját a legszűkebb keresztmetszetű alrendszer átbocsátási
rátája határozza meg Az egyes alkalmazások utasítás-mixe sajátos és távol áll az utasítás feldolgozásának szempontjából ideális utasítás-mixtől minden alkalmazásnak más az átbocsátási rátája Kibocsátási szűk keresztmetszet Kezeljük a: o Behívási függőségeket gyorsítótárakkal o A vezérlés-függőségeket statikus elágazás-becsléssel Az adatfüggőségek (a valódi és álfüggőségek) okoznak főképpen teljesítménycsökkenést o A tipikus példákból láthatjuk, hogy a 3 utasítás-szélességű ablakból nem mindig sikerül kibocsátani 3 utasítást, a függőségek miatt o A gyakorlatban: RISC esetén 2-3, CISC esetén 2 utasítás feldolgozása történik óraciklusonként o Tehát az első generációs szuperskalárokat keskeny szuperskalároknak nevezzük Jellemző megvalósítások: - Viszonylag általános célú 2 db futószalag (Pentium I) - 2-4 db dedikált futószalag (Alpha 21064) SzA26. Második generációs
(széles) szuperskalár processzorok áttekintése(a kibocsátási szűk keresztmetszet kiküszöbölése: dimnamikus utasítás-ütemezés és regiszter-átnevezés, végrehajtási modelljük, értékelésük) Jellemzői: - Dinamikus utasítás-ütemezés - Regiszter-átnevezés Dinamikus utasítás-ütemezés (részei): - Pufferelt utasítás-kibocsátás - Sorrenden kívüli utasítás-végrehajtás 61. oldal, összesen: 95 Megvalósítása: Működés: - Kibocsátási puffereket alakítottak ki - A kibocsátás során nem történik semmiféle függőség-ellenőrzés (adat, vezérlés, erőforrásfüggőséget sem) - A várakoztató-állomásokban addig tartózkodnak az utasítások, amíg függetlenné nem válnak - Minden óraciklusban ellenőrzésre kerül a várakoztató állomásokban levő összes utasítás függőség szempontjából, és az összes független utasítás kiküldésre kerül, mégpedig sorrenden kívül. - Az utasításablak több tucat utasítást
tartalmaz rendkívül kiszélesedett, azaz eltűnt a kibocsátási szűk keresztmetszet Regiszter-átnevezés: - Lényege: minden eredmény-regiszter átnevezésre kerül. Kezeli ennek következményeit is: o Amennyiben később forrásregiszterként hivatkozunk rá, akkor az átnevezési regisztert fogja használni o Amikor egy utasítás-feldolgozás a befejeződött, akkor átmásolja az átnevezési regiszter tartalmát az architekturális regisztertárba, és felszabadítja az átnevezés regisztert. o Hibás elágazásbecslés esetén az átnevezési regiszterek alapján történik a visszajátszás; kezeli a kivételeket is. - A második generációs szuperskalároknál jelent meg, pl.: PowerPC 603 (1993), PentiumPro (1995), Alpha 21264 (1998) 62. oldal, összesen: 95 A második generációs szuperskalár RISC gépek végrehajtási modellje Működése: - Az első rész feladata az utasításablak feltöltése - A forrás-operandusok lehívása architektúrától
függően lehet: o kibocsátáshoz kötött vagy o kiküldéshez kötött - A kiküldés során a független utasításokat sorrenden kívül tölti ki - A végrehajtás során az átnevezési regiszterekbe kerülnek az eredmények - Visszaíráskor az eredmények az utasítások eredeti sorrendjében másolódnak át az átnevezési regiszterekből az architekturális regiszterekbe Sávszélesség: - Kibocsátás ráta: 4 utasítás / ciklus - Kiküldési ráta: 5-8 utasítás / ciklus - Végrehajtási ráta: még magasabb Oka: - Bizonyos végrehajtó egységek nem képesek minden ciklusban utasítást fogadni (a bonyolultabb utasítások miatt) - Az utasítás-mix az egyes alkalmazásoknál nem egyezik meg a végrehajtható egységek eloszlásával CISC gépek: - A CISC processzorok belsejében RISC magot alakítottak ki - A CISC utasítások lefordítják RISC utasításokká - Egy CISC utasításból átlagosan 1,2-1,5 RISC utasítás keletkezik. Mivel a bonyolult CISC
utasításokat elhagyták, ezért ezeket valahogy helyettesíteni kell. Pl: for ciklus esetén (bonyolult utasítás): egy if, egy inkrementálás, egy goto és egy ciklus vége utasítás szükséges. - Óraciklusonként ~3 CISC utasítás kerül lehívásra, tehát 3 x (1,2-1,5), azaz ~4 db RISC utasítás kerül kibocsátásra 63. oldal, összesen: 95 Adatfolyam modell: - Mivel a függőségeket kezeljük csak műveleti és a behívási függőség feloldását kell kivárni - Mihelyt a bemenő operandusok rendelkezésre állnak, a kiküldés elvben bekövetkezhet (erőforrás-függőség lehetséges), s a végrehajtó egység azonnal működésbe lép (adatmeghajtott elv) SzA27. Harmadik generációs szuperskalár processzorok: az utasításon belüli párhuzamos végrehajtás áttekintése (három-operandusú utasítások, SIMD-utasítások, VLIW-architektúrák) Utasításon belüli párhuzamosság Duál-műveletes utasítások SIMD Multimédia (fixpontos) VLIW 3D
(lebegőpontos) A logikai architektúra kiterjesztése Teljesen új logikai architektúra Duál műveletes utasítások: - Fogalma: egyetlen utasításban kettő darab művelet - Pl.: X=a*b+c (A szorzatok eredményét c-ben felgyűjtjük) LOAD/OP (Betöltés után azonnal elvégzi a műveletet is) - A 70-es években jelentek meg - Numerikus feldolgozásoknál használják, de az általános célúaknál nem jellemző SIMD: - Fogalma: egyetlen utasításban ugyanazon művelet több operanduson van értelmezve - Fajtái: Fixpontos: ~ 2-8-szoros gyorsítás Lebegőpontos: 2-4-szeres gyorsítás - Ez képezi a processzorok fejlődésének fő irányvonalát: ~ 1994-től - Sajátosságai: o A logikai architektúra módosítást igényel o Az L2 gyorsítótár felkerül a processzor lapkájára o A rendszer-architektúra is módosul: megjelenik az AGP (Accelerated Graphics Port) VLIW: - Fogalma: egyetlen utasításokban sok műveletet írunk elő - Korai VLIW-ek: o Igen hosszú
utasítások, pl.: a TRACE VLIW processzor esetén: 256-1024 bites utasítások 7-28 műveletet tartalmaz o A statikus ütemezés során a compiler gondoskodik a függőségek feloldásáról 64. oldal, összesen: 95 o A compiler szoros kapcsolatban áll a fizikai architektúrával, pl.: ismernie kell a végrehajtó egységek számát, azok késleltetését, a behívási késleltetést, stb. o A 80-as évek első felében papíron, második felében a piacon is megjelentek (pl.: TRACE) o Gyorsan leállt a forgalmazásuk, mivel a compiler túlságosan kötődött a fizikai architektúrához - Mai VLIW-ek: o A compilerek fejlődtek, ezért a 90-es évek végén újra megjelentek o Szerverek piaca: INTEL Itanium: 6 db végrehajtó egységgel rendelkezik A szuperskalárok 4 db / ciklus feldolgozási rátáját kívánják a 6 db végrehajtó egységgel túlszárnyalni o Hordozható gépek piaca: a Transmeta cég processzorai: A statikus ütemezés egyszerűbb
processzort eredményez kisebb áramfogyasztás (2W DVD-lejátszás közben!) Fajtái: 4 db végrehajtó egységgel 8 db végrehajtó egységgel 65. oldal, összesen: 95 Számítógép architektúrák záróvizsga-kérdések 2 SzA28. 2 és 3 generációs szuperskalár processzorok tervezési tere (a tervezési tér főbb komponensei) Szuperskalár processzorok tervezési tere Utasítás lehívás Dekódolás Utasítás kibocsátás Utasítás végrehajtás Szekvenciális konzisztencia megőrzése Kivételkezelés 1. Utasítás lehívás: feladata a következő utasítás címének átadása az utasítás cache-nek 2. Dekódolás: minden órajelben több utasítást bocsát ki egyszerre, ezért párhuzamos dekódolásra van szükség 3. Szuperskalár utasítás kibocsátás: Magasabb utasítás kibocsátási ráta nagyobb teljesítményt eredményez, de egyben erősíti a vezérlési és adatfüggőségek teljesítmény-visszafogó hatását is. Ennek
mérséklésére különböző kiküldési politikákat (dispatch policy) alkalmaznak, mint például shelving, regiszter átnevezés, spekulatív elágazás kezelés. 4. Párhuzamos végrehajtás: a szuperskalár feldolgozás alapfeltétele 5. Szekvenciális konzisztencia biztosítása: az utasítások párhuzamosan hajtódnak végre, de szekvenciális logika szerint 6. Kivételkezelés: A szekvenciális konzisztenciát a kivételkezelésnél is biztosítani kell Dekódolás: 1) Elődekódolás a) Van b) Nincs Utasítás kibocsátás: 1) Kibocsátási politika a) Kibocsátási mód Direkt Pufferelt b) Kibocsátás sorrendje Sorrendi Sorrenden kívüli c) Kibocsátás illesztése Fix ablakos Csúszó ablakos d) Függőségek kezelése Vezérlés függőségek 66. oldal, összesen: 95 • Spekulatív • Nem spekulatív Ál-adatfüggőségek • Van regiszter át nevezés • Nincs regiszter át nevezése 2) Kibocsátási ráta SzA29.
Utasításlehívás (főbb feladatok, a címképzés általános sémája, az ugrási cím meghatározása, a BTIC és a BTAC eljárás elve, példák) Főbb feladatok: Elődekódolás azaz elágazás becslés Elágazási címszámítása Feladata a következő utasítás címének átadása az utasítás cache-nek (I$). Ez skalár processzoroknál, amelyek nem tartalmaznak elágazásbecslést a PC-vel történik, IPC (Initial PC) vagy BTA (Branch Target Address) segítségével. Mivel csak egy utasítást hív le, ez nem jelent gondot. A szuperskalár processzorok 4 utasítás/ciklus lehívását végzik, ha nem lenne elágazásbecslés, akkor az jelentős teljesítménycsökkenéshez vezetne A szuperskalárok IFA-t (Instruction Fetch Address) használnak, IIFA (Initial IFA) vagy BTA segítségével a címmeghatározáshoz. A BTA-t elágazásbecsléssel (branch prediction) határozzák meg A címképzés általános sémája Szuperskalár elágazásbecsléssel: 67. oldal,
összesen: 95 Az ugrásí cím meghatározása: Az elágazási ág elérésének módszerei Kiszámítási lehívási módszer BTAC BTIC A köv. lehívási címre mutató index Kiszámítási lehívási módszer elve: Elágazás észlelésekor a processzor előbb kiszámítja az elágazási címet (BTA) majd a soros ágon következő utasítás címét felülírja vele. Így a kiszámított elágazási cím lesz a következő utasítás címe (IFA). A következő ciklusban a processzor behívja az utasítás gyorsítótárból az elágazási címen lévő célutasítást (BTI). Pl 486, Power1, PowerPC 601 Elágazási címpuffer BTAC: BA 1000 BA 1000 BTA 9879 A BTAC a legutoljára végrehajtott elágazási utasítások címeit (BTA) és a vonatkozó elágazási címeket (BA) tartalmazza. Ha az aktuális utasítás behívási cím (IFA) egy elágazási utasítás címe (BA) és ehhez bejegyzés található a BTAC-ben akkor a proc. miközben az utasítás gyorsító tárból
beolvassa az elágazási utasítást a BTAC-ből egyidejűleg az elágazási címet is kiolvassa A következő ciklusban a proc ezt a címet használja az elágazási célutasítás eléréséhez Pl. Pentium, PA8000, PowerPC 604, 620 Célutasítás puffer BTIC: BA BTI1 címx ut1 BTI2 ut2 BTI3 ut3 BTI4 ut4 BA A BTIC módszer elve abban az esetben ha a BTIC-ben az elágazási ág folytatásának címe (BTA+) is el van tárolva. A BTIC az utolsó teljesült elágazások címeit, a hozzájuk tartozó célutasításokat, valamint a folytatási címeket tárolja. Amikor az aktuális utasítás behívási címhez tartozik egy bejegyzés aBTIC-ben akkor a proc. A következő utasítást a BTIC-ből és nem az utasítás gyorsítóárból hívja le majd dekódolja. Egyúttal a proc a BTIC-ből kiolvassa az elágazási ág soron következő utasításának címét (BTA+) is. A következő utasítást a proc erről a címről hívja le. Pl Hitachi Gmicro/200 A BTIC módszer elve abban az
esetben ha a BTIC-ben az elágazási ág folytatási címét a proc. számítja ki. A BTIC az utolsó teljesült elágazások címeit (BA), és a hozzájuk tartozó elágazási ágak első két utasítását tárolja (BTI, ill BTI+1) Ha az aktuális utasításlehívási címhez (IFA) a BTIC-ben tartozik bejegyzés akkor a processzor a következő két utasítást nem az utasítás gyorsítótárból hanem a BTIC-ből hívja le. Az elágazási ág soron következő utasítás behívási címét (BTA+) a proc az elágazási címből számítja ki annak inkrementálásával Pl Am 29000, MC88110 68. oldal, összesen: 95 SzA30. Dekódolás (alkalmazott eljárások áttekintése, párhuzamos hagyományos dekódolók, elődekódolás, a trace cache használata, példák) Dekódolási lehetőségek: Hagyományos dekódolók, Elődekódolók (prefetching): L2-ből hozzák be az utasítást 2G AMD Trace cache: eltárolja a dekódolt utasítást Mivel a szuperskalár
processzorokat jellemzően több utasítás kibocsátása jellemzi, ezért a párhuzamos dekódolás itt egy komplexebb feladat, mint az egyszerű skalár processzorokban. Magasabb kibocsátási ráták esetén túlzottan megnőhet a dekódolási ciklus hossza vagy ez a dekódolás továbbfejlesztése nélkül oda vezethet, hogy egy dekódolási ciklus helyett a processzornak két vagy több ciklusra lesz szüksége. Skalár processzoroknak ciklusonként csak egyetlen utasítást kell dekódolnia, ezen felül ellenőriznie kell, hogy a kibocsátandó utasítás függ-e a végrehajtás alatt állóktól és így kibocsátható-e. A szuperskalár processzor ennél összetettebb Minden ciklusban több, általában négy utasítást kell egy időben dekódolni, ezen felül meg kell vizsgálnia, hogy a kibocsátás alatt álló utasítások függenek-e a jelenleg végrehajtás alatt állóktól, illetve, hogy van-e függőség a következő ciklusban kibocsátásra váró utasítások
között. Mivel a szuperskalár processzorban több végrehajtó egység is van, ezért ezek a függőség vizsgálatok sokkal több összehasonlítást jelentenek, mint a skalárokban. Összességében tehát a kibocsátási ráta növelésével nő a dekódolás komplexitása Ez nyilván a teljesítményben mutatkozik meg Hagyományos: A hagyományos dekódolás egy egyszerű párhuzamos dekódolás. Ezt az első generációs RISC-ek és a későbbi CISC processzorok használják. A második generációs CISC proceszszorokban többnyire egy RISC magot valósítottak meg Ilyenkor a dekódolás során a CPU előtt egy CISC-RISC konverziót végez, melynek során egy CISC utasítást RISC utasítások sorára bontja. Pentium Pro-ban 16 bájt töltödik fel a dekóderekben Ezekből az 1 elfogad bármilyen CISC utasítást, ami maximum három RISC utasítással dekódolható. A másodikharmadik, egyszerű dekóder viszont csak egy RISC utasítással dekódolható CISC-eket fogad el (pl
load vagy egy regiszter operáció). Akkor van tehát hármas feltöltés, ha az utasítás legfeljebb három RISC utasítással dekódolható és rögtön utána két olyan utasítás jön, melyek egy-egy RISC utasításokkal dekódolhatóak. Ez nagyon ritkán fordul elő A komplexebb utasításokhoz egy mikor-utasítás ROM tartozik, mely ciklusonként három utasítást bocsát ki Ezek felváltva dolgoznak, vagyis vagy a három alapdekóder működik vagy a mikro-utasítás ROM. Az AMD K6 processzorának egy nagyon hasonló dekódere van. Ebben a három alapdekóder mellett egy ún. vektor dekóderrel találkozunk, mely gyakorlatilag megegyezik a Pentium Pro mikro-utasítás ROM-jával. Az Athlon (K7) abban különbözik az előzőektől, hogy a három alapdekóder teljesen egyenrangú: 69. oldal, összesen: 95 A dekódolás után a kibocsátáshoz egy visszaalakítást végez. Ennek során összeláncolják az egy CISC utasításhoz tartozó RISC utasításokat, és csak
együtt engedik őket kibocsátani (ROB). Elődekódolás A növekvő kibocsátás hatásának csökkentésére a szuperskalár processzorokban bevezették az elődekódolás folyamatát. Az utasítás cache feltöltésekor az L2 cache (vagy ennek híján a memória) és az utasítás cache közé egy hardware egység kerül, mely utasításokhoz RISCeknél 4-7, CISC-eknél 2-5 bitet fűz hozzá. Egyszerre 128 bit jön le az L2 cache-ből Ez tehát még a feltöltéskor történik, így nem jelent időkritikus műveletet. Az elődekódolás megjelenése jellemzően 1995-re tehető, vagyis a második generációs rendszereknél, mivel itt nőt meg a kibocsátási ráta, itt vált szükségessé ennek a technikának a bevezetése. Ez nem sokkal az első generációs rendszerek megjelenése után jött, 2-3 évvel ezek bevezetése után. Rohamos elterjedésük elsősorban annak köszönhető, hogy az ilyen technikákkal kapcsolatos tervek hamar kikerülnek a titok köréből, így
többnyire egyszerre tudnak kijönni a gyártók az új megoldásokkal. A többlet bitekre jellemző, hogy elsősorban CISC rendszereknél terjedtek el és az idő előrehaladtával csökkentek (pl K8-ban már csak 2 bit). Trace cache: Jellemzően az Intel P4-ben, vagyis egy harmadik generációs CISC rendszerben jelent meg. Lényege az a felismerés, hogy az utasítások kb. 80%-át a ciklusok végrehajtása jelenti, így azonos utasítások folyamatos lehívásával és dekódolásával felesleges műveleteket végzünk. Ötlet: a dekódolt utasításokat tárolni kell, s a ciklusok végrehajtását a tároltak lehívásával gyorsítani. SzA31. Az elődekódolás megvalósítása (szükségessége, elve, szükséges többletbitek száma, felhasználása, példák) Szükségessége: A skalár processzoroknak ciklusonként csak 1 utasítást kell dekódolnia. Ezen felül ellenőriznie kell azt is, hogy a kibocsátandó utasítás függ-e a végrehajtás alatt állóktól, és így
kibocsátható-e Ezzel szemben a szuperskalár processzor feladata sokkal összetettebb 70. oldal, összesen: 95 Minden ciklusban általában több, pl 4 utasítást kell egy időben dekódolni. Ezen felül kétféle függőségvizsgálatot is el kell végezni, egyrészt meg kell vizsgálni, hogy a kibocsátásra váró utasítások függetlenek-e a jelenleg végrehajtás alatt állóktól, illetve, hogy vannak-e függőségek a következő ciklusban kibocsátásra váró utasítások között. Mivel a szuperskalár proceszszorokban általában több VE van, mint a skalár-ban, a végrehajtás alatt álló utasítások száma is általában sokkal nagyobb, mint a skalár-nál. Ez azt jelenti, hogy a függőségvizsgálatok során jóval több összehasonlításra van szükség Elve: Cél: idő csökkentése, órajel frekvencia növelése. A dekódolási feladatok egy részét a processzor már aközben végrehajtja, mikor az utasításokat a másodszintű L2 cache-ből vagy a
memóriából az utasítás, L1 cache-be írja. Szükséges többletbitek száma és felhasználása: Az elődekódoláshoz használt bitek száma RISC processzorok esetében általában 4-7 bit, melyek a következő jellegű információkat hordoznak: • • • melyik feldolgozó egységhez kell tenni = az utasítás milyen osztályba tartozik (milyen típusú) végrehajtáshoz szükséges erőforrások típusa elágazás detektálás, néha BTA kiszámítása A CISC processzorok esetében további többletinformációkat is tartalmazhatnak, például egy utasítás hol kezdődik és hol végződik. Az AMD K5 processzora pl minden byte-hoz 5 bitet fűz (+60%!). Példák: Először 1995-ben jelentek meg elődekódolást használó szuperskalár processzorok: PA-7200 (1995), PA-8000 (1996), PowerPC 620 (1995), R10000 (1995), UltraSparc (1995), AMD K5 (1995). Gyakorlatilag azonnal elterjedt Az egyes meghatározó processzorcsaládok legújabb tagjai rendszerint már használják,
viszont néhány nagyon elterjedt processzor ugyanakkor nem használ elődekódolást, pl. Pentium Pro, PII, PIII 71. oldal, összesen: 95 SzA32. Utasítás várakoztatás I (célja, elve, függőség vizsgálat tartalma, tervezési terének áttekintése) Utasítás várakoztatás célja és elve: Az utasítás várakoztatás célja az utasítások között fellépő függőségek hatására létrejövő kibocsátási blokkolások megszüntetése. Ezt úgy éri el, hogy a várakoztató állomások felé függőségek vizsgálata nélkül kibocsátja (issue) a dekódolt utasításokat, majd ezek után végez függőség vizsgálatot, a várakoztató állomásban lévő utasítások között A független utasításokat kiküldi (dispatch) a végrehajtó egység felé. Függőség vizsgálat tartalma: (Spekulatív elágazás kezelés és regiszter átnevezést feltételezve.) A spekulatív elágazás kezelés megszűnteti a feloldatlan vezérlésfüggőségek következtében
fellépő kibocsátási blokkolódásokat, míg az átnevezéssel az ál-adat függőségek, azaz a WAR és WAW függőségek és a miattuk előálló kibocsátási blokkolódások küszöbölhetőek ki. Így az utasítások kiküldése során függőségvizsgálat már csak a RAW adatfüggőségek vizsgálatára korlátozódik. Tervezési tere: Várakoztatás A várakoztatás hatóköre A várakoztató pufferek megvalósítása Operandusz lehívási politikák Az utasítás kiküldés módja Várakozatás hatóköre: • Néhány utasításra terjed ki a várakoztatás • Minden utasításra terjed ki a várakoztatás Várakoztató pufferek megvalósítása: Várakoztató pufferek megvalósítása A várakoztató pufferek típusa A várakoztató pufferek kapacitása Csak várakoztató állomás Egyedi VÁ Csoportos VÁ Ki és bemeneti kapuk száma Kombinált pufferek várakoztatásra utasítás átrendezésre és regiszter átnevezésre is szolgál Központi VÁ
Operandus lehívási politikák: Kibocsátáshoz kötött operandus lehívás: az operandusokat a processzor az utasítások kibocsátása alatt hívja be. Ebben az esetben a várakoztató pufferek a forrásoperandusok értékeit tárolják 72. oldal, összesen: 95 Kiküldéshez kötött operandus lehívás: az operandusokat a processzor az utasítások kiküldése alatt hívja be. Ebben az esetben a várakoztató pufferek a forrásregiszterek azonosítóit tárolják. Utasítás kiküldés módja: Utasítások kiküldési módja Kiküldési politika Kiküldési sorrend Kiküldési ráta Üres várakoztató állomás kezelése Döntési szabály Kiválasztási szabály Az operandusok rendelkezésre állása megállapításának módja Sorrendben történő Részben sorrenden Sorrenden kívüli kívüli kiküldés kiküldés kiküldés SzA33. Utasítás várakoztatás II (utasítás várakoztató pufferek megvalósítási alternatívái, operandus lehívási
politikák, értékelésük) Utasítás várakoztató pufferek megvalósításai: Várakoztató pufferek megvalósítása A várakoztató pufferek típusa A várakoztató pufferek kapacitása Csak várakoztató állomás Egyedi VÁ Csoportos VÁ Ki és bemeneti kapuk száma Kombinált pufferek várakoztatásra utasítás átrendezésre és regiszter átnevezésre is szolgál Központi VÁ Várakozó állomás (Csak várakoztató pufferek): Egyedi: minden egyes végrehajtó egységnek saját puffere van Példa: AMD K5, PowerPC 620 (ábra – 7.102) Ráfordítás: nagy Teljesítmény: az egyik pufferből a másikba nem lehet utasításokat áttenni Kapacitás: 2-4 hely Csoport: az azonos típusú (pl. FX) VE-ek egy közös pufferből táplálkoznak Ehhez nyilván nagyobb pufferre van szükség. Ez a tendencia Példa: Pentium 4, Athlon, Opteron, R10000 (ábra – 7.100): két buszon keresztül történik az utasítások kiküldése. Az egyik a
fixpontoshoz, a másik a FP és gyökvonáshoz Az FP osztás 20-40 ciklusig tart. Ez egy buszról táplálva, nem hoz érdemi 73. oldal, összesen: 95 teljesítménycsökkenést, mivel a FP utasítások aránya 10% még a műszaki programokban is. Teljesítmény: bármelyik VE-be kerülhetnek a várakozó utasítások Kapacitás: 8-20 Központi: Minden VE egyetlen pufferből táplálkozik, ezért nagy kapacitásúra van szükség. Példa: Pentium Pro, P2, P3 (ábra 7.105) Pentium Pro: egy 20 elemű központi állomás szolgálja ki mind a 10 VE-t. Egy buszon keresztül lassú egységeket látnak el: +/ FP/*. Ráfordítás: a pufferméret csökkenthető az egyedihez képest. Nagyobb ráfordítású, de nem gyorsabb, mint a csoport típusú. Teljesítmény: az FP VE nem tudja végrehajtani az FX-et, és fordítva Kapacitás: 20 fölött Kombinált pufferek: A várakoztatáson kívül egyéb funkciókat is ellát: o Várakoztató és átnevező o
Várakoztató és átrendező o Várakoztató, átrendező és átnevező Operandusz lehívási politikák: Kibocsátáshoz kötött operandus lehívás: Azt jelenti, hogy a processzor az operandusokat az utasítások kibocsátásakor hívja le, vagyis akkor, amikor azok a dekódolás után bekerülnek a várakoztató pufferekbe. Ilyenkor ezek a forrás operandusok értékeit tárolják elsősorban. A processzor a kibocsátás során a forrás operandusok regisztereinek azonosítóját a regisztertárba továbbítja a hivatkozott operandusok behívása céljából. A várakozó állomásba bekerül a dekódolt műveleti kód, a célregiszterek azonosítói, valamint a behívott operandus értékek. A behívás során a processzornak ellenőriznie kell, hogy a hivatkozott regiszter értékek rendelkezésre állnak-e Ha nem, akkor az azt jelenti, hogy egy már végrehajtás alatt álló utasítás célregisztere a hivatkozott forrásregiszter, vagyis a két utasítás között RAW
adatfüggőség van (ahogy már korábban említettem, regiszterátnevezés és spekulatív elágazás kezelés mellett a processzornak a várakoztató pufferekben csupán a RAW függőségeket kell vizsgálnia). Az operandusok rendelkezésre állásának eldöntéséhez érvényességi biteket alkalmaznak (scoreboarding) Ennek során a regisztertárban minden regiszterhez egy további bitet rendelünk, mely érvényességi bitként funkcionál (V bit – valid bit). Egy utasítás kibocsátása során annak célregiszterének érvényességi bitjét a processzor mindig 0-ba állítja mindaddig, amíg az utasítás végrehajtása be nem fejeződik és az eredmény vissza nem íródik a regisztertárba. A várakozó állomásokban is elhelyeznek a forrásoperandusok mellé egy-egy ilyen érvényességi bitet Amikor a processzor lehívja a forrás operandusok értékeit, ellenőrzi, hogy a hozzájuk tartozó érvényességi bit a regisztertárban be van-e állítva. Ha igen, akkor a
kiolvasott értéket beteszi a pufferben a megfelelő helyre és 1-es ír az operandus mellé érvényességi bitnek. Amennyiben nincs beállítva ez a bit, akkor a hivatkozott forrásregiszter azonosítóját írja be a pufferbe és mellette 0-s érvényességi bittel jelzi, hogy az adott érték egy regiszter azonosító és nem az operandus értéke Miután a vezérlőegység elvégezte a rá bízott műveletet, az előállított eredménnyel frissíteni kell mind a regisztertárat, mind a várakoztató puffereket. Ekkor a célregiszter azonosítóját, mint asszociatív címet felhasználva előbb kikeresi a regisztertár megfelelő helyét, majd a várakoztató pufferekben is frissíti azon forrás regiszter értékeket, ahol az érvényességi bit 0 és 74. oldal, összesen: 95 mellette a regiszter azonosító a most előállított eredmény célregiszter azonosítójával egyezik meg. Itt fontos megjegyezni, hogy a várakoztató pufferek frissítése globális művelet,
vagyis minden olyan várakoztató pufferbe továbbítani kell az eredményt, amelyben a létrehozott eredményre várakozó utasítások lehetnek. I-buffer D e c o d e /I s s u e So ur c e r e g. n um b e r s Issue R e g . f ile O p c o d e s, d e st in a t io n r e g . n u m b e r s So ur c e 1 o p e r a n ds So ur c e 2 o p e r a n ds R S R S RS E U E U E U Kiküldéshez kötött operandus lehívás: Azt jelenti, hogy a processzor a várakoztató pufferekbe a kibocsátás során csak a forrás regiszterek azonosítóit teszi be és a konkrét értékeket csak akkor hívja le, amikor az utasításokat a vezérlőegység felé kiküldi. Kiküldés során fordul tehát csak a regisztertárhoz, így csak a regisztertárban szükséges érvényességi biteket eltárolni. Amennyiben mindkét forrás operandus érvényességi bitje 1 a regisztertárban, úgy az adott utasítás kiküldhető Amennyiben bármelyik is 0, függőség lépett fel, így az utasítás nem küldhető ki
Ennek a megvalósításnak a másik következménye, hogy az eredmény előállásakor nincs szükség a várakoztató pufferek aktualizálására sem. I-buffer Deco de/Issue In st ruct io n s Disp at ch RS RS RS So urce regist er n um bers Op. co des, dest inat io n reg. n um bers Reg. file So urce 1 o p eran ds So urce 2 o p eran ds EU EU EU Értékelésük: - A kiküldéshez kötött kibocsátás előnyösebb az időkritikus dekódolás/kibocsátási fázis szempontjából, mivel nem tartalmaz regiszterolvasást - A kiküldéshez kötött lehívás esetén a VP-ek sokkal kisebb méretűek lehetnek, mivel a regiszterazonosítók lényegesen kevesebb helyet igényelnek 75. oldal, összesen: 95 - A hivatkozott forrásoperandusok rendelkezésre állásának ellenőrzése tekintetében a kibocsátáshoz kötött előnyösebb, mivel a VP-ben lévő érvényességi bitek értékeinek ellenőrzése sokkal egyszerűbb feladat, - A kimenő kapuk számát tekintve bonyolultabb
az összehasonlítás, általában a kiküldéshez kötött operandus behívási politika igényel kevesebb olvasási kaput SzA34. Utasítás kiküldés I (tervezési tere, kiküldési szabály (dispatch rule) értelmezése, kiküldési sorrend alternatívái, trendje, példák) Tervezése tere: Utasítások kiküldési módja Kiküldési politika Kiküldési sorrend Kiküldési ráta Üres várakoztató állomás kezelése Döntési szabály Kiválasztási szabály Az operandusok rendelkezésre állása megállapításának módja Sorrendben történő Részben sorrenden Sorrenden kívüli kívüli kiküldés kiküldés kiküldés Kiküldési politika: milyen módon válasszuk ki az utasítást a végrehajtáshoz, és hogyan kezelje a kiküldési blokkolást. Kiküldési ráta: definiálja az egy ciklusban a várakozó pufferekből kiküldhető utasítások számát Operandusok rendelkezésre állásának megállapítási módja: az utasítások kiküldhetők-e járulékos
késés nélkül vagy sem. Üres várakoztató puffer kezelése: el kell döntenünk, hogy egy üres várakozó állomás elkerülhető-e Kiküldési szabályok értelmezése: Kiválasztási szabály. Ez határozza meg, hogy a várakoztató pufferekben tárolt utasítások mikor minősülnek végrehajthatónak. Amennyiben a processzor fejlett utasítás-kibocsátást alkalmaz (regiszterátnevezés + spekulatív elágazás-kezelés) ennek eldöntése arra a vizsgálatra korlátozódik, hogy az utasítás forrásoperandusai rendelkezésre állnak-e. Döntési szabályra akkor van szükség, ha a továbbíthatónál több alkalmas utasítás áll rendelkezésre. Általánosságban elmondhatjuk, hogy ahány szabad vezérlőegységhez kapcsolódik egy várakoztató puffer, annyi végrehajtható utasítás előállítása jelent optimális működést ciklusonként, hiszen ekkor biztosítható az, hogy minden ciklusban, minden vezérlőegység valamilyen hasznos munkát végezzen. Ha ennél
több végrehajtható utasítás szerepel a pufferben, akkor dönt a döntési szabály. A legtöbb processzor ilyenkor egy nagyon egyszerű döntést hoz: a „legidősebb” utasítást küldi ki. Kiküldési sorrend alternatívái: A kiküldési sorrend szabja meg azt, hogy egy nem végrehajtható utasítás megakadályozza-e a sorban következő végrehajtható utasítás vagy utasítások kiküldését. 76. oldal, összesen: 95 Ha sorrendben (in-order) küldi ki az utasításokat, egy nem végrehajtható utasítás a pufferben meggátolja a soron következő utasítást vagy utasításokat a kiküldésben, vagyis blokkolódás jön létre. Ez nyilván csökkenti a teljesítményt, ugyanakkor csökkenti a komplexitást is, mivel elegendő csupán a várakoztató puffer utolsó elemét leellenőrizni. Ha részben sorrenden kívül (partially out-of-order) küldi ki az utasítást, akkor kismértékű teljesítménynövekedés érhető el. Ez jelentheti azt is, hogy a sorrenden
kívüli kiküldést csak bizonyos típusú vezérlőegységeknél alkalmazza, de azt is jelentheti, hogy csak egy nem kiküldhető utasítást tud átlépni. Például a Power2 csak a lebegőpontos utasításokat várakoztatja, és kiküldéskor csak egyetlen nem végrehajtható lebegőpontos utasítást tud átlépni. Ha sorrenden kívül (out-of-order) küldi ki az utasításokat, mely a leghatékonyabb eljárás egyike a három közül. Itt egy nem végrehajtható utasítás nem blokkolja a várakoztató pufferben sorban következő végrehajtható utasítások kiküldését A legkorszerűbb processzorok ezt a kiküldési módot alkalmazzák, bár az IBM360/91 is implementálta már. Ennek oka egyszerű: a mai architektúrák többnyire csoportos vagy központi várakoztató puffereket alkalmaznak, melyeknél több vezérlőegységhez egy várakoztató puffer kapcsolódik. Ilyenkor, ha a blokkoló sorrendben kiküldést alkalmazná a processzor, az jelentős
teljesítménycsökkenéshez vezetne. Trendek és példák: Egyértelműen a sorrenden kívüli kiküldés felé mutat. A csoportos vagy központi várakoztató állomást használó processzoroknál ez szinte követelmény, különben rendkívüli teljesítménycsökkenés következne be. Sorrendi kiküldés: IBM Power1, PowerPC 603. Részben sorrendi kiküldés: IBM Power2, PowerPC 604. Sorrenden kívüli kiküldés: Pentium Pro, R10000. SzA35. Utasítás kiküldés II (a kiküldött utasítások multiplicitása, forrás operanduszok meglétének vizsgálati elvei, üres várakoztató pufferek kezelése) Kiküldési ráta: A várakozó puffereknek minden ciklusban el kell tudni látnia minden hozzárendelt EU-t utasítással. Ennek megfelelően: Egyedi várakoztató állomás: csak 1 utasítás kiküldésére képes ciklusonként, csak saját EU-ját kell ellátnia Csoport várakoztató állomás: több utasítás kiküldésére is alkalmasnak kell lennie, de a
kiküldendő utasítás típusától is függ a kiküldési ráta. Egyszerű utasítás (R10000, load/store): esetén 2, bonyolultabb utasítás (R10000 FX, FP, div, mul) azonban csak 1. Központi várakozató állomás: ciklusonként több (P6-nál 5) utasítást is kell tudnia küldeni, de ezek megvalósítása összetettebb Forrás operandoszok meglétének vizsgálati elvei: Közvetlen ellenőrzés (kiküldéshez kötött): nincsenek konkrét állapotbitek, melyek jeleznék az operandusok jelenlétét, így külön meg kell vizsgálni azokat. Az RS-ben csak az opcode-t és a hivatkozott forrás és célregiszterek számát tárolják. A regiszter elérhetőségét egy a register file-ban lévő scoreboard jelzi. Minden regiszternél még egy validity bit Ha egy regisztert valamelyik utasítás használja V bitje 0 Ha eredmény megérkezett és beíródott, akkor V=1 lesz. A regiszterek hozzáférhetőségét ezzel a bittel ellenőrzik Komplex logika, több ezer komparátor.
77. oldal, összesen: 95 Állapotbitek vizsgálata (kibocsátáshoz kötött): az operandusok meglétét külön erre a célra definiált állapotbitek jelzik Az RS-ben az opcode mellett a hivatkozott forrásregiszterek értéke és a hozzáférhetőségüket jelző státusz bitek mellett a célregiszter számát tárolják. V=1 esetén a regiszter tartalma, V=0 esetén csak a hivatkozott regiszter száma van az RS-ben. Decoded instructions Decoded instructions RS1, RS2 , RD OC RS1 RS2 Update R D, set V-bit Reset V-bit of R D RD V Check V-bits of source operands Reservation Station Reg. file Scoreboard bits RS1, RS2, RD Update R D, set V-bit Reset V-bit of R D V Reg. file Associative update of I S1, I S2 with R D1 set Reservation Station Check the status bits (VS1 , V S2) related VS-bits OS1 OC, OS1 , OS2 , R OC OS1 /I S1 VS1 OS2 /I S2VS2 R D OS2 Scoreboard bits OC, OS1, OS2 , RD D EU EU Result, R D Result, R D Üres várakozó pufferek kezelése:
Egyszerű kezelés (straightforward): ha egy utasítás egy üres pufferhez ér, akkor az adott ciklusban beíródik a pufferbe, és csak a következő ciklusban lesz kiküldve, így egy egész ciklust fölöslegesen várakozik a pufferben (Pl.: Nx586) Hatékonyabb megoldás a kikerülés (bypassing): ha az utasítás üres pufferhez érkezik, akkor „kikerüli” azt és még az adott ciklusban kiküldésre kerül, így nincs fölösleges várakoztatás (Pl.: Power PC604) SzA36. Regiszter átnevezés I (statikus, dinamikus átnevezés, a megvalósítás elve és a főbb feladatok utasításvárakoztatást feltételezve, kibocsátáshoz kötött operandusz lehívás esetén) Statikus átnevezés: Statikus átnevezés: Az átnevezésre fordításkor kerül sor, a regisztereket a fordítóprogram nevezi át (korai futószalag-processzorok, szuperskalár processzorok párhuzamosan optimalizáló fordítóprogramjai). Dinamikus átnevezés: Dinamikus átnevezés: Az átnevezésre futási
időben kerül sor, és a processzor végzi el. Ehhez jelentős többlethardverre van szükség, ezért később is jelent meg. Elsőként az IBM valósította meg részlegesen (Power1, Power2), majd az IBM és a Motorola teljes körűen (PowerPC, Power3, MC 88110). Ma már gyakorlatilag minden fejlett processzor alkalmazza 78. oldal, összesen: 95 Regiszter átnevezés megvalósítási elve és főbb feladatai utasítás várakoztatást és kibocsátáshoz kötött operandusz lehívás esetén: Az utasítások kibocsátásakor a processzornak át kell neveznie mind a kibocsátott utasítás célregiszterét, minden a forrásregisztereket, majd be kell olvasnia a forrásregiszterek tartalmát. A célregiszterek átnevezése állandó, mindig megtörténik, forrásregisztert azonban csak akkor kell átnevezni, ha korábban a processzor már átnevezte. Az operandus értéket betöltése során a gyakorlatban a processzor egyszerre fordul a regiszterazonosítóval mind az
architektúrális, mind az átnevező tárhoz. Amelyik eredményt szolgáltat, azt használja fel Ha mindkettő egyszerre küld eredményt, úgy általában az átnevező puffertár adatát használja fel. Az utasítások kiküldésekor a várakozó pufferekben az érvényességi bitek ellenőrzése. Ha az utasítás kiküldhető vagyis végrehajtható, akkor várakozó pufferek a szabad VE-k felé továbbítják. Amikor a végrehajtóegység létrehozta az eredményt, mint a várakozóállomást, mind az átmeneti puffertárat frissítenie kell. Itt az a különbség a várakoztatásnál megismertekhez képest, hogy célregiszternek egy átnevező puffer azonosítót használ, és ezzel címzi a várakozóállomás olyan forrásoperandusok után kutatva, mely a kapott eredményre várnak. Ezt követően frissül az átnevező puffertár tartalma. Az architektúrális regisztertárhoz ilyenkor nem nyúl a processzor, mivel minden célregisztert átnevez, vagyis minden eredményt az
átnevező puffertárba kell írni. Az utolsó feladat (az utasítás befejezésekor) a már nem használatos puffertár elemek visszanyerése. Erre akkor van lehetőség, ha az adott puffere a processzornak már nincs szüksége Ez két esetben lehetséges: ha egy utasítás egy olyan célregiszterre hivatkozik, amelyiket már átneveztek, de még nem zárult le a végrehajtás, a korábbi átnevezésre már nincs szükség, hiszen azt az eredményét felül fogja írni az éppen átnevezés alatt álló utasítás. A másik eset, amikor befejeződik az utasítás végrehajtása, visszaíródik az architektúrális regisztertárba az adat. 79. oldal, összesen: 95 SzA37. Regiszter átnevezés II (a megvalósítás elve és a főbb feladatok utasítás várakoztatást feltételezve, kiküldéshez kötött operandusz lehívás esetén) Regiszter átnevezés megvalósítási elve és főbb feladatai utasítás várakoztatást és kiküldéshez kötött operandusz lehívás esetén:
Az utasítások kibocsátása során a processzornak át kell neveznie a célregisztert, valamint a forrásregiszterek közül azokat, amelyeket már korábban átnevezett. Az operációs kód, a forrás (címei)- és cél regiszterek a VÁ-ba kerülnek. Az utasítások kiküldésekor a processzor elvégzi hivatkozott forrás operandusok érvényességi bitjeinek vizsgálatát a VÁ-ban, majd a végrehajtható utasításokat továbbítja a szabad VEkbe. A hivatkozott forrás operandusok beolvasása vagy az ÁPT-ből (Átnevező puffer tár) vagy az ART-ből (Arch. Regiszter Tár) Amikor előáll az eredmény a végrehajtóegységben, a processzor frissíti az átnevező puffertár tartalmát. Itt nincs szükség a várakozóállomások frissítésére, mivel azok csak azonosítókat és nem adatokat tárolnak A már nem használt pufferek felszabadítása (utasítás befejezésekor) itt kicsit bonyolultabb feladat, mint a kibocsátáshoz kötött esetben. Amikor ugyanis a processzor
visszaírja az architektúrális regisztertárba az eredményt, előfordulhat, hogy a várakozóállomások még tartalmaznak olyan utasítást, amelyek forrásoperandusa az átnevezett regiszterre hivatkozik. En- 80. oldal, összesen: 95 nek megoldására bevezethetünk egy számlálót, amelyet inkrementál a processzor, valahányszor egy forrásoperandus hivatkozik az átnevező pufferre és csökkenti a számláló értékét, amikor ennek az utasításnak a végrehajtása befejeződött. Ha a számláló újra eléri a nulla értéket (vagyis minden olyan utasítás végrehajtása befejeződött, amelynek valamelyik forrásoperandusa hivatkozott a pufferre), akkor a puffer felszabadítható és újra fel lehet használni átnevezésre 81. oldal, összesen: 95 SzA38. Regiszter átnevezés III (tervezési tere, a regiszter átnevezés kiterjedése (scope), átnevező regiszterek megvalósítási alternatívái) Tervezési tere: Regiszterátnevezés Átnevezés hatóköre
részleges Átnevező pufferek megvalósításának módja Átnevezési ráta teljes Átnevező pufferek típusa Összevont architektúrális és átnevező regiszter Regiszterleképzések megvalósítása Önálló átnevező regiszter Átnevező pufferek száma Átnevező pufferek megvalósítása ROB- ban Átnevezések nyilvántartási módja Átnevező pufferek megvalósítása DRIS- ben Nyilvántartás átnevező pufferekben Nyilvántartás leképző táblában A regiszter átnevezés kiterjedése (scope): A szuperskalár processzorok megjelenésekor még nem alkalmazták a regiszterátnevezést. Elterjedésükkor néhány processzorban nevezették a részleges átnevezést. Ilyenkor a folyamat csak egy vagy néhány utasítás típusra korlátozódik. Ilyen volt pl a Power1 (FP behívó) vagy a Power2 (összes FP). Később elterjedt a teljes átnevezés, melynek során valamennyi utasításnál alkalmazzák az átnevezést, mely egy adatregiszter tartalmát
módosítja A trend a teljes átnevezés felé mutat. Átnevezések nyilvántartási módjai: Asszociatív átnevező tábla (rename buffer) -- Nyilvántartás átnevező pufferekben Ez esetben a pufferek három információt tárolnak: a célregiszterek azonosítóját, értékét és bizonyos állapotinformációkat. Amikor egy utasítás célregiszteréhez átnevező puffert kell allokálni, a processzor keres egy szabad bejegyzést, lefoglalja és a célregiszter azonosító mezőbe beírja az architektúrális regiszter sorszámát. Az eredmény a puffer indexe lesz. A mechanizmus sajátossága, hogy egy regiszterhez több puffert is lehet rendelni. Ez akkor fordulhat elő, ha egy utasítás célregisztere megegyezik egy már átnevezett regiszterrel. Indexelt átnevező tábla (mapping table) -- Nyilvántartás leképző táblában Ebben az esetben az aktuális leképzéseket a processzor egy táblában tartja nyilván, mely az architektúrális regiszter
azonosítójával címezhető, és számon tartja az 82. oldal, összesen: 95 egyes architektúrális regiszterekhez hozzárendelt átnevező pufferek indexét. Az átnevezés során a processzor létrehoz ebben a táblában egy bejegyzést. Ekkor a célregiszterhez hozzárendel egy átnevező puffert és a célregiszter számának megfelelő táblasorba beírja ennek indexét Átnevező regiszterek megvalósítási alternatívái: Összevont architektúrális és átnevező regisztertár: (Power 1,2, R10000, P4) Ebben az esetben a processzor egy közös regisztertárat tartalmaz, melyek elemei dinamikusan vagy architektúrális regiszterek vagy átnevező pufferek. Összevont átnevező regiszterek állapot-átmenet diagramja: Külön átnevező regisztertár: (PowerPc 603,604,620) Csak az átnevezésre szolgál. FX-re és FP-re külön RRF és ARF van Önálló átnevező regiszterek állapot-átmenet diagramja: 83. oldal, összesen: 95 Átnevező pufferek
megvalósítása ROB-ban: (AMD K5,K6, PPro,PII,PIII) Párhuzamos végrehajtás esetén mindenképpen szükséges, hogy a processzor az állapotteret a soros konzisztenciának megfelelően módosítsa. Ennek megvalósítására egy átrendező buffert alkalmaznak. Ennek a buffernek minden eleme egy utasítás Ezt hívjuk ROB-nak. A regiszterátnevezést meg lehet valósítani ebben a ROB-ban is. Ilyenkor az utasítás mellé elmentjük annak célregiszterének tartalmát is, így amikor a ROB-ból a soros konzisztencia szerint kikerül az utasítás, meg lesz a proceszszornak az az információ is, hogy mivel módosítsa a regisztertár tartalmát Átnevező pufferek megvalósítása DRIS-ben: (csak elvi megoldás): A kombinált várakoztató pufferben valósítják meg az átnevező puffereket. Ilyenkor a várakoztató állomás tartalmazza a regiszterátnevezéshez szükséges többlet információkat. Átnevezési ráta: A ciklusonként átnevezhető utasítások maximális
számát jelenti. Mivel kibocsátáskor a kibocsátási korlátok elkerülése érdekében a processzornak minden ciklusban képesnek kell lennie minden kibocsátott utasítás átnevezésére, az átnevezési rátának meg kell egyeznie a kibocsátási rátával. SzA39. Regiszter átnevezés IV (a leggyakrabban használt átnevezési eljárások áttekintése) A leggyakrabban használt átnevezési eljárások áttekintése: Összevont architektúrális és átnevező regiszter, nyilvántartás leképző táblában, kiküldéshez kötött operandus lehívás: Power1, Power2, R10000, Pentium4, K7-FP (Athlon) Önálló átnevező regiszter, nyilvántartás átnevező pufferekben, kibocsátáshoz kötött operandus lehívás: PowerPC 603, 604, 620 Átnevező pufferek megvalósítása ROB-ban, nyilvántartás leképző táblában, kiküldéshez kötött operandus lehívás: Pentium Pro, Pentium II, Pentium III Átnevező pufferek megvalósítása ROB-ban, nyilvántartás
átnevező pufferekben, kibocsátáshoz kötött operandus lehívás: AMD K5 Átnevező pufferek megvalósítása ROB-ban, nyilvántartás átnevező pufferekben, kiküldéshez kötött operandus lehívás: AMD K6, K7-FX 84. oldal, összesen: 95 SzA40. Szuperskalár processzorok mikroarchitektúrájának megvalósítási alternatívái (a processzorok főbb megvalósítási alternatíváit meghatározó szempontok, megvalósítási alternatívák áttekintése) A processzorok főbb megvalósítási alternatíváit meghatározó szempontok: A mikroarchitektúra magjának felépítését alapvetően 2 jellemző határozza meg: az utasítás várakoztatás és a regiszterátnevezés megvalósítási módja. Az utasításvárakoztatás tervezési teréből két összetevő maradt, mely szignifikáns a fejlett szuperskalár processzorok mikroarchitektúrájának megvalósítása szempontjából. A VP-ek típusa, és a használt operandus behívási politika A
regiszterátnevezés tervezési teréből egyetlen kvalitatív tervezési szempont veendő figyelembe, ez pedig a választott ÁP-ek típusa. Spekulatív elágazásbecslés módja (van vagy nincs). Szekvenciális konzisztencia megvalósításának módja A megvalósítási alternatívák áttekintése: Shelving Reservation station Individual RS Issue bound Group RS Dispatch bound 2. Nx586 1. 3. Power1 Fig. 10/1 Fig. 10/2 9. PPC603 10. 17. Am 29000 18. Central RS Issue bound Dispatch bound PM1 4. ES-9000 Fig. 10/3 11. Power2 R10000 Alpha 21264 Pentium 4 Athlon (FP) Issue bound 5. 12. Shelving within the ROB Dispatch bound 6. 13. Fig. 10/6 14. Power3 19. supersc. K5 Fig. 10/10 Fig. 10/11 20. Issue bound 7. Fig. 10/5 Fig. 10/4 PPC604 PPC620 Fig. 10/9 Combined buffers Dispatch bound Issue bound Dispatch bound 8. Fig. 10/7 15. Shelving and renaming within the ROB Fig. 10/8 16. PA-8000 PA-8200 PA-8500 21. 22. Athlon (FX) Pentium Pro
Pentium II Pentium III Fig. 10/12 Fig. 10/13 Fig. 10/14 23. 24. Lightning K6 Fig. 10/15 85. oldal, összesen: 95 Fig. 10/16 SzA41. Fontosabb szuperskalár processzorok mikroarchitektúrájának áttekintése (a Pentium Pro, a Pentium 4, a K6, az Athlon (K7) és az Opteron (K8) mikroarchitektúrájának főbb jellemzői) A Pentium Pro mikroarchitektúrájának főbb jellemzői Szuperskalár CISC proci RISC maggal Nincs elődekódolás BTAC a BTA kiszámításához (BTB) Kibocsátási ráta: 3, kiküldési ráta 5 20 bejegyzéses központi várakoztató állomás Sorrenden kívüli kiküldés Kibocsátáshoz kötött operandusz lehívás Soros konzisztenciát ROB biztosítja ROB-ban megvalósított átnevező regiszterek Gyenge memória, erős processzor konzisztencia A Pentium 4 mikroarchitektúrájának főbb jellemzői Elődekódolás mikroarchitektúra szinten, trace cache BTAC a BTA kiszámításához (BTB) 20 fokozatú
futószalag Mikrocode ROM L1 data-cache (8k, 4 utas) L2 data-cache (256 kbyte, 8 utas) Dedikált, csoport várakoztató állomás Sorrenden kívüli kiküldés Kiküldéshez kötött operandusz lehívás Összevont architekturális és átnevező regiszterek Gyenge memória, erős processzor konzisztencia A K6 mikroarchitektúrájának főbb jellemzői Elődekódolás BTIC a BTA kiszámításához Kombinált várakozó állomás Kiküldéshez kötött operandus lehívás Átnevezés és várakoztatás (ROB-ban) Gyenge memória, erős processzor konzisztencia A K7 (Athlon) mikroarchitektúrájának főbb jellemzői Elődekódolás, 3 BTAC a BTA kiszámításához (BTB) Dedikált, csoport várakoztató állomás Sorremden kívüli kiküldés Kiküldéshez kötött operandusz lehívás Összevont architekturális és átnevező regiszterek lebegőpontosnál ROB-ban megvalósított átnevezés fixpontosnál
Makro utasítások kezelése Gyenge memória, erős processzor konzisztencia 86. oldal, összesen: 95 Az Opteron mikroarchitektúrájának főbb jellemzői elődekódolás, predecode cache BTAC a BTA kiszámításához dedikált, csoport várakoztató állomás out-of-order dispatch kiküldéshez kötött operandusz lehívás összevont architekturális és átnevező regiszterek lebegőpontosnál ROB-ban megvalósított átnevezés fixpontosnál gyenge memória, erős processzor konzisztencia SzA42. Többszálas processzorok (megjelenésük szükségessége, megvalósítási alternatívák és értékelésük, példák) Megjelenésük szükségessége: Nem kikerülhető fejlődési fokozat Soros proc (i286(1982)), Futószalagos proc (i386 - i486), szuperskalár (Pentium, Pentium Pro) Az általános célú programokban az utasításszintű párhuzamosság kimerült a: • multimédia támogatással (PII), illetve • a
multimédia + 3D támogatással (PIII, PIV) A dedikált növelés is kimerült A következő lépcsőfokot a hardveresen többszálú architektúrák jelentik Technikák: Egyszálas: egyetlen utasításfolyamban a processzor már kimeríti a rendelkezésre álló párhuzamosságot (párhuzamosan feldolgozható utasítások – utasításfolyam) Többszálas: több szál egyidejű futtatása A processzorok fejlődése (2) (jelen és jövő) Egyszálas technika Többszálas technika Utasításfolyam Több szál Egyetlen utasításfolyamban a processzor már kimeríti a rendelkezésre álló párhuzamosságot (párhuzamosan feldolgozható utasításokat) IBM Power4 (2001) Pentium 4 Prestonia (2002) Pentium 4 Northwood (2002) 3.06 GHz-től Megvalósítási alternatívái: Többmagos egyszálas: egy lapkán két vagy több processzor-maggal A cache-ekben osztoznak, a megvalósítás az egyes rendszerekben eltér Egy mag egy szálat dolgoz fel, közös
cache Értékelés: 87. oldal, összesen: 95 o Többlethardver: 60-70%-kal több o Többletteljesítmény: 50-60% általános célú alkalmazásokban Többszálas egymagos: egyetlen többszálas processzor-maggal SMT, pl. kétszálas mag: ezen belül tesznek különbséget az állapotok között, pl külön regiszterkészlettel Értékelés: Többlethardver: 5%-kal több Többletteljesítmény: erősen alkalmazásfüggő: -10-20%-tól +20%-ig (zavarhatják egymást) Az egyprocesszoros rendszerekben a disszipáció okozza a korlátot. Két mag 200W+, léghűtéssel érdemben nem kezelhető. A többmagos technikához csökkenteni kell a disszipációt. Többszálas több magos: a kettő ötvözése Példák: Többmagos egyszálas IBM Power4: kétmagos UltraSparc IV Sun Niagara: 8 mag, 4 szál,2006-7 (5 futószalag fokozat, egyszerű magok) AMD Opteron Dual Intel két Prescott maggal: Tulsa Többmagos egyszálas HT helyett,
Pentium M-mel. Kétmagos VLIW Itanium: két szálat kezel Egymagos többszálas Intel Hyperthreading, ami megfelel az SMT-nek = Symmetrical MultiThreading A feldolgozás keverve történik, a jelzőbitek kezelik az állapotmódosításokat Szimmetrikus, a kettő között nincs különbség Többmagos többszálas Power5: AS/400 és OS/400 összehozva, a Power5 már mindkét célra alkalmas (konvergencia), kialakult a virtuális technika, logikai particionálás (a hardver erőforrásokat futás közben kezeli). Figyeli a kihasználtságokat, átcsoportosítani is képes. Dinamikus allokáció 88. oldal, összesen: 95 Többszálas processzorok jelene és jövője Egymagos többszálas IBM Sun Többmagos egyszálas Többmagos többszálas Power4 Power5 (2001) dual core (2004) dual core/2T 0.13 /276 mtrs UltraSparc V UltraSparc IV (2006) dual core/2T 0.09 (IH 2004) 2*USIII 0.13 /66 mtrs Opteron AMD (4/05) dual core 0.09 /233
mtrs Athlon 64 X2 (06/05) dual core 0.09 Intel Pentium 4/HT (11/2002) 2T 0.13 /55 mtrs Smithfield (Pentium D) (5/05) dual core 0.09 Pentium EE 840 (4/05) 2T 0.09 /230 mtrs Complexity SzA43. Rendszerarchitektúrák I (fejlődésük főbb állomásai, processzor buszok fejlődése, a frekvencianövelés korlátja és annak feloldása) Rendszerarchitektúrák fejlődésének főbb állomásai: • ISA alapú • PCI alapú o Straightforward o IDE/ATA és USB–vel o AGP, IDE/ATA és USB-vel • Port alapú - ISA a buszvezérlő gondoskodik a memória és a billentyűzet kezeléséről minden kártyákon keresztül valósul meg (ISA based system architectures) - Straight forward PCI-based system architecture A vezérlés kettéválik, északi és déli híd, amelyek a PCI-on keresztül kapcsolódik Északi: L2 és memóriakezelés, itt nagyobb sávszélesség szükséges A perifériák PCI vagy ISA buszra is kialakíthatók, jellemzően 4-5 PCI
slot és 2-3 ISA - PCI-based system a with IDE/ATA and USB ports A déli híd a vinyók kezelését, két csatorna, négy eszköz, és néhány usb-s rendszer Megmarad az ISA, de a a sebessége miatt a PCI dominál - PCI-based system a with AGP, IDE/ATA and USB ports ISA a háttérbe szorul (1 vagy semennyi) - Ports-based Szinte minden portokon keresztül kapcsolódik a rendszerhez, az ISA nem 89. oldal, összesen: 95 tartozék, csak egy hídon keresztül csatlakoztatható (opcionális) A PCI is elvesztette jelentőségét, mivel minden a déli hídhoz kötődik Super IO: keyb, ms, fd, sp, pp, ir AC ’97 FPM-EDO-SD RAM - Soros buszokat és portokat használó rendszerarchitektúra Az FSB (Front Side Bus) 64bites, megjelennek a 0-1 átmenetek, az északi híd bemenetén megjelenik egy SKEW, ami a futási idők eltéréseit jelenti. Azért van eltérés, mert az egyes biteknek eltérő távolságot kell megtenniük a híd és a proci között
Korlátozza a teljesítményt A kapacitív terhelés sem azonos: különböző meredekségű a felfutás. A buszkorlátot 3-4Ghz környékén érték el HT: soros buszok, annyi van belőle, amennyi kell. 1 bit = 2 Gbit sávszél 2GHz mellett. RS-242 USB, ATA SATA, SCSI SAS, PCI PCI X, AGP 16 bit PCI Express AMD FSB HyperTransport, az Intel is megjelenik majd a soros busszal Processzor buszának szélesség bitben (Address/Data bus): 8086 (20-16) 8088 (20-8) 80286 (24-16) 80386 (32-32) 80486 (32-32) Pentium (32-64) Pentium Pro – P4 (36-64+8) Processzor FSB frekvencia: P(60) PII(100) PIII(133) P4(400,533,800,1066 MHz) Az fc gyorsabban növekedett, mint az FSB. Tapasztalat: FSB/fc > ~0,2 kell lennie, hogy ne okozzon szűk keresztmetszetet Jelenlegi technológia mellett 4GHz-nél elérték az FSB max. határát Tovább nem növelhető a frekvencia, az eltérő futási idők és az eltérő meredekségű felfutás miatt. Megoldás: Soros buszra váltás. AMD: Hyper
Transport bus 90. oldal, összesen: 95 SzA44. Rendszerarchitektúrák II (az elmúlt évek busz innovációinak áttekintése, a GbE, SCSI vezérlők és a grafika csatolása) Gigabit Ethernet: o Déli hídhoz PCI-on keresztül o Déli híd (ICH) PCI-E x1 keresztül, 1 esetleg több o Északi híd (MCH): Megosztják a PCI-E x8-at, ebből egy x4 a PCI-X hídra megy, amihez GbE c. kapcsolódhat o Bridge nélkül közvetlenül kapcsolódhat a 2 db GbE c. az északi hídhoz P4 P4 GbE MCH GbE c. PCI PCI-X CSA GbE MCH GbE c. PCI-X ICH 82540EM 845xx E75011 E7205 82541GI 875P 915xx 925X E7210 P4 HI 2.0 MCH brigde MCH HI 1.5 ICH GbE c. P4 P4 HI 1.5 HI 1.5 GbE P4 HI 1.5 ICH PCI-X GbE GbE c. ICH (6300ESB) Examples 82541PI 4 82547EI 848P 865xx 4 875P 4 82547GI 875P E7210 5 82545EM E7500/7501/7505 82546EB (D) E7500/7501/7505 82541GI E7320/7525 (w/6300ESB) 2 82541PI E7320/7525 (w/6300ESB) 3 82541GB E7320/7525 (w/6300ESB) 3 E7221
E7520(w/ICH5R) All categories Early DP servers/workstations Mainstream desktops Advanced DP servers/workstations (Furthermore the E7210) 1 Ususally in companion with a MbE controller such as the 82550PM or the 82551QM. 2 The 82541GI is used either in 32-bit/33MHz or 32-bit/66 MHz mode. The 82541PI and the 8254GB is used in the 32-bit/33 MHz mode. 4 Most of the enlisted motherboards provide either a MbE controller attached to the LAN 10/100 interface or a GbE controller attached to the CSA interface. 5 Ususally in companion with a MbE controller such as the 82551QM. 3 P4 P4 PCI-X MCH GbE GbE c. PCI-X bridge P4 x4 P4 GbE PCI E. x8 GbE c. MCH x4 DMI P4 x4 PCI E. x8 x4 MCH HI 1.5 HI 1.5 PCI E. x1 GbE c. GbE c. GbE c. ICH ICH ICH (ICH6/ ICH6R) (ICH5R) (ICH5/ 6300ESB) Examples 82570EI 1 2 (88E8050 ) 3 (BCM5721 ) 915GV 925X 82546GB (D) E7520/E7525 (w/ICH5R) E7221 Advanced single processor motherboards Advanced DP servers/workstations 1 Used to date
(2/05) in Commel's FS-979 motherboards. From Marvell 3 From Broadcom 2 91. oldal, összesen: 95 82571EB E7320 E7520 E7525 Advanced DP servers/workstations Small Computer System Interface (SCSI): o Északi hídhoz: PCI-X hídon keresztül, egy majd két csatorna P4 P4 FSB HI 2.0 SCSI c. PCI-X bridge PCI-X (P64H2) P4 P4 FSB PCI E. x8 MCH PCI-X bridge (PXH-V) SCSI c. (E7500/7501) PCI-X x8 P4 MCH (E7320) SCSI c. PCI-X bridge PCI-X (PXH) LSI Logic 53C1020 (Ultra 320, single channel) Adaptec AIC-7902 (Ultra 320, dual channel) LSI Logic 53C1030 (Ultra 320, dual channel) Advanced high-end DP-servers Advanced mid-range DP-servers Early DP-servers Display: o MCH-ból közvetlenül (Északi hídba integrált video vezérlő) o ICH PCI buszon keresztül on-board video vezérlő o MCH AGP, PCI-E buszon keresztül off-board video vezérlő P4 VGA MCH P4 VGA Off-board video c. P4 P4 P4 AGP 4x/8x/ PCI E. x8/x16 ICH MCH ICH MCH VGA On-board video c.
PCI 32 bit/33 MHz ICH (mostly ATI Rage XL) Typical use: Value/mainstream desktops with the letter G in their designation (e.g 845G/GL/GV) Entry level servers based on the E7221 Value/mainstream desktops excluding those with the letters GL or GV in their designation (e.g 845GL/GV) High end desktops/entry level workstations DP-workstations Periféria buszok fejlődése Párhuzamos buszok ideje lejárt, váltás soros buszra. PCI PCI-X ATA SATA SCSI SAS FSB HT soros buszra (AMD) AGP PCI-X 16x USB (alapból soros) 92. oldal, összesen: 95 MCH (E7520) ICH Typical use: Adaptec A16-7899W (Ultra 160, dual channel) Adaptec AIC-7901 (Ultra 320, single channel) Adaptec AIC-7902 (Ultra 320, dual channel) FSB PCI E. x8 ICH ICH P4 Entry level servers based on the E7210 DP-servers SzA45. Alaplapok I (alaplap típusok fejlődésének áttekintése, az AT és a korai ill. fejlett Baby AT alaplapok karakterisztikus jegyei) Alaplapok típusai: • 1981 IBM/PC az eredet • 1984
AT minden kártyákon keresztül valósul meg • 1985 Baby AT: méretcsökkenés, oka: chipkészletek, memórialapkák megjelenése • 1985 Pentium alapú Baby AT: PCI slotok megjelenése • 1987LPX célja keskeny házak megvalósítása, megjelent a Riser Card • 1996 ATX funkcionális javítás • 1997 NLX funkcionális javítás • 1998 microATX • 2000 ATX w/riser • 2004 BTX; microBTX; picoBTX hűtés megoldása AT 8/84 LPX 2 NLX 4 1987 11/96 Baby AT 1 ATX3 ~1985 8/95 ATX w/riser 5 12/99 BTX 7 microBTX 7 microATX 6 1/98 picoBTX 7 9/03 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 00 01 02 03 1 Baby AT: Smaller board size through higher integrated components (chip sets) 2 Non-standardized slimline design with a central mounted riser card allowing 2-3 expansion slots 3 Through better component arrangement reduced cost and EMI emission, integrated AGP (from version 2.02 on) 4 Standardized, improved slimline design with an edge mounted riser
card, integrated AGP 5 Low cost slimline ATX design by using a riser card with 2-3 expansion slots 6 Reduced size low cost ATX design with up to four expansion slots 7 In-line core layout to improve system cooling with scalable board dimensions AT alaplapok karakterisztikus jegyei: • Nem tartalmazott chipkészletet • Rögzített memória az alaplapon (DIPP) • Ezekből következik: nagy méret • 8/16-os ISA billentyűzet (KYB) kivételével minden periféria ezen keresztül kapcsolódik. Korai Baby AT karakterisztikus jegyei: • Megjelenik a chipkészlet • Memória külön lapkán • Ezekből következik: kisebb helyigény • 8/16 bites ISA 93. oldal, összesen: 95 04 05 • • • • CPU: 386 SIMM/30 L2 cache DIPP (alaplapra integrálva) KYB csatlakozó Fejlett Pentium alapú Baby AT alaplapok karakterisztikus jegyei: • Megjelenik a chipkészlet • Memória külön lapkán • Ezekből következik: kisebb helyigény • 16 bites ISA • PCI 32 bites •
CPU: Pentium • SIMM/72 • L2 cache DIPP • KYB, FD, HD on-board vezérlők SzA46. Alaplapok II (a riser card fogalma, célja, alkalmazása, az ATX és a BTX alaplap szabványok) Riser Card: Fogalma: Olyan kártya, melybe több periféria illesztőkártya (ISA, PCI) helyezhető. Az alaplapra merőleges a riser card, így párhuzamosan helyezkednek el a periféria illesztőkártyák az alaplappal. Cél: méretek csökkentése Slim alaplap típusok: LPX, NLX, ATX w/riser ATX alaplap szabvány tulajdonságai: • A CPU-t a tápegység mellé helyezi, így egyszerre hűthető a kettő. • HD és FD csatolók közel helyezkednek el a meghajtókhoz, így is csökkentve az EMI-t (Elektromágneses interferencia) 94. oldal, összesen: 95 • Kétsoros I/O csatlakozók megjelenése Korai ATX alaplapok tulajdonságai: • 1 ISA (egyre kevesebb ISA slotra van szükség) • PCI • AGP • Slot1 (PII/III) • DIMM/168 • Kétsoros I/O csatlakozók Jelenlegi ATX alaplapok
tulajdonságai: • Nincs ISA, PCI-32 • PCI-E 1x, PCI-E 16x • L2 cache a chipen belül van • Socket 478 (P4) • 1 ATA; 4 SATA BTX alaplap szabvány megjelenésének oka: BTX alaplap szabvány megjelenésének legfőbb oka a processzorok magas disszipációja volt. Ennek a problémának a megoldására az alaplapi chipkészletet és a CPU-t egy légáramba helyezték. 95. oldal, összesen: 95
 Just like you draw up a plan when you’re going to war, building a house, or even going on vacation, you need to draw up a plan for your business. This tutorial will help you to clearly see where you are and make it possible to understand where you’re going.
Just like you draw up a plan when you’re going to war, building a house, or even going on vacation, you need to draw up a plan for your business. This tutorial will help you to clearly see where you are and make it possible to understand where you’re going.