A doksi online olvasásához kérlek jelentkezz be!
A doksi online olvasásához kérlek jelentkezz be!
Nincs még értékelés. Legyél Te az első!
Legnépszerűbb doksik ebben a kategóriában





Tartalmi kivonat
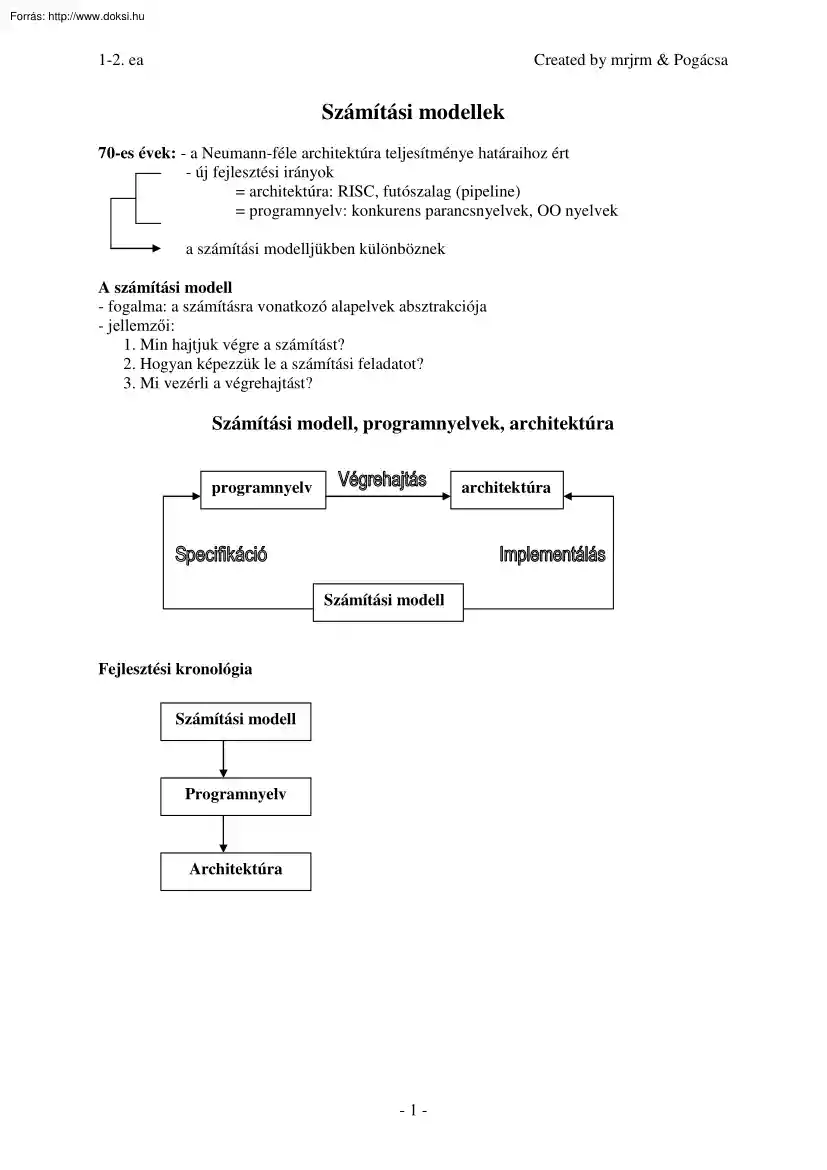
1-2. ea Created by mrjrm & Pogácsa Számítási modellek 70-es évek: - a Neumann-féle architektúra teljesítménye határaihoz ért - új fejlesztési irányok = architektúra: RISC, futószalag (pipeline) = programnyelv: konkurens parancsnyelvek, OO nyelvek a számítási modelljükben különböznek A számítási modell - fogalma: a számításra vonatkozó alapelvek absztrakciója - jellemzői: 1. Min hajtjuk végre a számítást? 2. Hogyan képezzük le a számítási feladatot? 3. Mi vezérli a végrehajtást? Számítási modell, programnyelvek, architektúra programnyelv architektúra Számítási modell Fejlesztési kronológia Számítási modell Programnyelv Architektúra -1- 1-2. ea Created by mrjrm & Pogácsa A számítási modellek osztályozása: -„Min hajtjuk végre a számítást?” elv szerint Adatalapú számítási modellek - Neumann-féle - Adatfolyam - Applikatív Objektum-alapú számítási modellek Predikátum-logika alapú
számítási modellek (Prolog) Tudásalapú számítási modellek Hibrid van piaci megvalósítása egyre bonyolultabb kísérleti stádium Adatalapú számítási modellek Adat:- az adatokat típusokhoz rendeljük - az elemi adattípus esetében a típus meghatározza: = az adat értelmezési tartományát = az adat értékkészletét és = a rajta értelmezett műveletek halmazát Pl. integer típus: - értelmezési tartomány: - 32768 ÷ + 32767 - értékkészlet: kizárólag egész érték - műveletek: +, -, *, /, Neumann-féle számítási modell 1. Min hajtjuk végre a számítást? - adatokon - az adatokat változók képviselik - biztosított, hogy a változók korlátlan számban változtathassák értékeiket deklarált változók 2. Hogyan képezzük le a számítási feladatokat? - adatmanipuláló utasítások sorozatával deklarált változó adatmanipuláció -2- adatmanipuláló programutasítások 1-2. ea Created by mrjrm & Pogácsa 3. Mi vezérli a
végrehajtást? - az adatmanipulálások szekvenciája - az explicit vezérlésátadó utasítások utasítások PC - vezérlés-meghajtó (control-driver) - programnyelvek: Basic, Pascal, C, - architektúra: Neumann-féle architektúra Adatfolyam számítási modell 1. Min hajtjuk végre a számítást? - adatokon 2. Hogyan képezzük le a számítási feladatot? - a bemenő adatok halmazának értelmezésével és - adatfolyam gráffal = a csomópontok jelentik a műveletet = élek az adat input-outputot, azaz adat-utakat, ahol az adat közlekedik X Y pl. z = ( x + y ) * ( x – y ) + - * Z - míg a Neumann-féle modellben a példa 3 db utasítást igényel: - összeadás - kivonás - szorzás - addig az adatfolyam modellnél az összeadás és kivonás párhuzamosan végezhető, tehát példánkban 33%-os időmegtakarítást értünk el. -3- 1-2. ea Created by mrjrm & Pogácsa 3. Mi vezérli a végrehajtást? - adat Stréber modell 1. adat még nincs @ 2. az egyik
operandus rendelkezésre áll @ 3. mindkét operandus biztosított, műveletvégzés @ 4. az eredmény előállt @ Neumann-féle modell 1. 2. 3. Változók: közös operatív tár (program + adat) Adatmanipuláló utasítások Implicit szekvencia, explicit vezérlés-átadás adatfolyam számítási modell Egyszeres értékadás, az adattárolást a csomópontok végzik Adatfolyam - gráf Adat meghajtott, nincs PC, nincs szekvencia Programnyelvek: pl. Sigal Architektúra: The Manchester Dataflow Machine -4- 3-4. ea Created by mrjrm & Pogácsa Architektúra Fogalmak: -1964 Amdahl: Mindazon ismeretek összessége, amit egy alacsony szintű nyelven programozónak ismerni kell ahhoz, hogy hatékony programot írjon. Pl.: regiszterek, címzési módok, memória, utasításkészlet -1970: Bell: Szinteket rendel az architektúra fogalmához. - PMS (Processor, Memory, Switches) - Programozói szint o Magas szintű o Alacsony szintű - Logikai áramköri szint -
Áramköri szint Egyéb: - külső jellemző - a belső felépítés - és működés együttese Adott absztrakciós szinten ( L ) a számítási modell ( M ), a specifikáció ( S ) és az implementáció ( I ) együttese. = {M,S,I}L = logikai + fizikai Architektúra = külső + belső = absztrakt + konkrét = Instruction Set Architecture + Microarchitecture Logikai architektúra - logikai architektúra az adott absztrakciós szinten = {M,S}L adott absztrakciós szinten a fizikai architektúra megvalósítása adott absztrakciós szinten a fekete doboz külső jellemzőinek viselkedése A processzor-szintű logikai architektúra részei: - adattér - adatmanipulációs fa - állapottér - állapotműveletek Fizikai architektúra - fizikai architektúra az adott absztrakciós szinten = {M,I}L adott absztrakciós szinten a logikai architektúra megvalósítása adott absztrakciós szinten a fekete doboz belseje A processzor-szintű fizikai architektúra részei - műveletvégző -
vezérlő - memória - I/O rendszer - Sínrendszer - Megszakítási rendszer -5- 3-4. ea Created by mrjrm & Pogácsa Egy korszerű számítógép szintjei: - Alkalmazások (Pl. Word, Excel) ------------------------------------------------------------------------- Problémaorientált nyelv (Pl. Pascal, C) - Assembly szintű nyelvek (?) - Operációs rendszer gépi része (Operációs rendszerek) - Utasításrendszer architektúra (Architektúra) - Mikrotechnika (Architektúra) - Digitális rendszer szintje (Digitális technika) ------------------------------------------------------------------------- Áramköri szint (Elektronika) Logikai architektúra Adattér A processzor által manipulálható tér Adattér Memóriatér Regisztertér Nagyobb Lassabb Külső lapkán Olcsóbb Lehet közös az I/O címtérrel Kisebb Gyorsabb A processzor lapkáján Drágább Mindig önálló címtér Memóriatér • Tárolási kapacitása az egyik legfontosabb tulajdonsága •
Kétféle címtér o Modell címtere // ezt a címsín szélessége határozza meg o Implementáció címtere // alkalmazás igénye, ill. anyagi lehetőségek határozzák meg • A valós memória tárolási kapacitásának fejlődése: o 40-es évek: néhányszáz szó o 1950 IAS 10 bites címrész, vagyis 1024 címet címezhetett meg o 1964 IBM360 16Mbyte Virtuális tár • megjelenése: 1960, • elterjedése: az IBM370-es gépcsaládhoz köthető. Alapjellemzői • kétféle címtér o valós címtér o virtuális címtér Létezik olyan, a programozó számára transzparens mechanizmus, mely az éppen futó program számára nem szükséges program- és adatrészeket kiviszi a valós memóriatérből a virtuális memóriatérbe, majd amikor ezen adatok szükségessé válnak, visszaviszi a valós memóriatérbe. Létezik egy olyan, a programozó számára transzparens mechanizmus, mely a programozó által használt virtuális címeket a futási fázisban lefordítja valós
címekké. -6- 3-4. ea Created by mrjrm & Pogácsa Címtér Valós címtér Virtuális címtér Félvezető lapka Itt fut a program Sokkal kisebb Ezt látja a processzor Drágább Gyorsabb Háttértár Itt vár a program Sokkal nagyobb Ezt látja a programozó Olcsóbb Lassabb Az INTEL processzorcsalád címtere Típus Dátum Valós Virtuális 8086 80286 80386 1978 1982 1985 1 16 4096 1Gbyte 64Tbyte Regisztertér • egyszerű • adattípusonként különböző • többszörös Egyszerű • 40-es évek: egyetlen akkumulátor • 50-es évek: egyetlen akkumulátor+ dedikált regiszter + • 60-as évek: általános célú regiszterek • veremregiszter -7- 3-4. ea Created by mrjrm & Pogácsa Egyetlen akkumulátor Hátránya • szűk keresztmetszet • bizonyos műveleteknek két eredménye van és az egyik az operatív tárba szorul ⇒ lassú Egyetlen akkumulátor+ dedikált regiszter Előnye • hányados bevezetése gyorsította az osztást
Hátránya • drága és az esetek 95%-ban üresen áll Általános célú regiszter Előnye • Igen jó a regiszterek kihasználtsága • Új programozási stílus: igyekeznek regiszter - operandusokkal végezni a műveleteket Veremregiszter Előnye • Igen gyors • Implicit biztosítja a verem adatstruktúráját Hátránya • Mivel csak a verem tetejét látjuk ⇒ szűk keresztmetszet -8- 5-6. ea Created by mrjrm & Pogácsa Adattípusonként különböző regisztertér Célja: az adatfeldolgozás gyorsítása - különös tekintettel a lebegőpontos adatábrázolásra 1 8 mantissza előjele 23 karakterisztika mantissza 1964: IBM 360 lebegőpontos regiszterkészlet általános célú regiszterkészlet: fixpontos, karakteres, logikai típusú adatok feldolgozásra 1998: Pentium III (Katmai) általános célú regiszterkészlet Típus IBM 360 Intel 80386 IBM RISC 6000 Intel Pentium III lebegőpontos regiszterkészlet Megjelenés éve 1964 1985 1990 1998 MMX2
(Katmai) regiszterkészlet Általános célú Lebegőpontos Katmai regiszterkészlet regiszterkészlet regiszterkészlet 16*32 4*64 8*32 8*80 32*32 32*64 8*32 8*80 8*128 -9- 5-6. ea Created by mrjrm & Pogácsa Többszörös regiszterkészlet Háttér információ: - kontextus: = a regiszterek aktuális tartalma és = az állapot-információk (flag, PC, ) - megszakítás esetén le kell mentenünk az éppen futó program kontextusát, annak érdekében, hogy majd a programot folytatni lehessen - a többfeladatos és több felhasználós feldolgozásnál igen sok a megszakítás. Amennyiben a kontextust az operatív tárba mentjük ⇒ lassú Helyette: többszörös regiszterkészlet A többszörös regiszterkészlet tervezési tere több egymástól független regiszterkészlet átfedő regiszterkészlet stack-cache 1964: Sigma 7 1980: RISC I 1982: C-Machine Több egymástól független regiszterkészlet: - független folyamatoknál ideális, pl. I/O megszakítás -
paraméter-átadásos eljárásnál nem gyorsít, mivel a paraméterátadás a memórián belül történik Átfedő regiszterkészlet: INS LOCALS OUTS INS LOCALS OUTS INS LOCALS Jellemzői: - a hívó eljárás OUTS része fizikailag megegyezik a hívott eljárás INS részével - a regiszterek száma merev, viszonylag üres regiszterkészlet mellett is előfordulhat a túlcsordulás: ez a memória igénybevételével kerül feldolgozásra ⇒ lassul a feldolgozás OUTS - 10 - 5-6. ea Created by mrjrm & Pogácsa -a regiszterkészlet száma: = az ábrán látható, hogy 6-8 regiszterkészlet esetén már igen csekély %-os a túlcsordulás = a programozás módszertan sem ajánlja, hogy 8-nál több eljárást ágyazzunk egymásba Stack-cache: Ötvözi - a cache-veremszervezését és - a regiszterek közvetlen címezhetőségét Működése: - a compiler minden eljáráshoz hozzárendel egy változó hosszúságú aktiválási rendszert (regiszterkészletet) az előző
aktiválási rekord Aktuális aktiválási rekord előző SP Stack Pointer (SP) - a hívó eljárás OUTS része fizikailag megegyezik a hívott eljárás INS részével - az adott aktiválási rekordot az SP segítségével közvetlenül is elérhetjük - egy adatot is elérhetünk közvetlenül az SP és a relatív távolság megadásával - az aktiválási rekordok számának csak a stack-cache fizikai mérete szab határt - 11 - 5-6. ea Created by mrjrm & Pogácsa Adatmanipulációs fa Adattípusok: FX1 FX2 FX3 FX4 Műveletek: Operandusok: rrr + - * / Címzési módok (memória): R+D Gépi kód: r: regiszter m: memória D: displacement - eltolás rmr mmm PC+D RI+D . Az adatmanipulációs fa megmutatja, - a lehetséges műveletek halmazát - másrészt egy al-fája megmutatja egy konkrét implementáció műveleteinek halmazát Az ideális az lenne, ha minden processzor képes lenne az összes adattípus, művelet, operandustípus, és címzési mód
kezelésére. Ennek azonban akadályai vannak - a 80-as évekig: = technológiai korlát: a lapka mérete korlátozta a lehetőségeket általános célú lebegőpontos stb. cím zési m űvelet = gazdasági korlát: igen drága a hardver, ezért célkonfigurációk: - gazdasági célú: karakteres és BCD műveletek - műszaki-tudományos célú: lebegőpontos számítás - napjainkban: a technológiai fejlődés és az árak csökkenése eredményeképpen univerzális processzorok különféle műveletvégzőkkel. - 12 - 5-6. ea Created by mrjrm & Pogácsa Adattípusok Elemi Összetett (adatstruktúrák vagy adatszerkezetek) Az összetett adattípusok az elemi adattípusokból épülnek fel. - verem - sor - fa - tömb Elemi adattípusok Numerikus karakteres logikai . pixel Numerikus fixpontos lebegőpontos BCD Fixpontos adattípusok egyes komplemens kettes komplemens előjeles byte (8 bit) félszó (16 bit) . többletes előjel nélküli szó (32 bit)
duplaszó (64 bit) quadroszó (128 bit) Lebegőpontos normalizált hexára normalizál IBM egyszeres pontosságú 32 bit nem normalizált binárisra normalizál IEEE VAX kétszeres pontosságú 64 bit - 13 - kiterjesztett pontosságú 128 bit 5-6. ea Created by mrjrm & Pogácsa BCD pakolt EBCDIC zónázott ASCII szabványos kiterjesztett logikai karakter EBCDIC 1 bájt ASCII szabványos 2 bájt 4 bájt változó hosszúságú kiterjesztett Műveletek - pontosan kell a műveleteket definiálni, beleértve a kivételek kezelését is - 14 - 7-8. ea Created by mrjrm & Pogácsa Az utasítás-feldolgozás menete Egy gépi kódú utasítás általános formája: MK Címrész Mit? Mivel? MK = műveleti kód Az utasítás-feldolgozás nagyvonalú folyamatábrája: Megszakítás igen nem I. utasításlehívás (Fetch) A megszakítás feldolgozása II. Utasítás-végrehajtás (Execute) adatsín MAR: Memory Address Register Memória
címsín MDR: Memory Data Register MAR MDR Vezérlőegység PC IR DEC PC: Program Counter IR: Instruction Register DEC: Decoder általános célú regiszter ALU Processzor - 15 - ALU: AricmeticalLogical Unit 7-8. ea Created by mrjrm & Pogácsa I. Utasítás-lehívás A PC mindig a következő végrehajtandó utasítás címét tartalmazza MAR MDR IR PC PC (MAR) MDR PC+1 Az utasítás lehívás minden utasítás esetén megegyezik. II. Utasítás-végrehajtás - adatbehívás (load) DEC IR MAR IR PC DEC címrész MDR PC+1 - aritmetikai-logikai utasítás, pl. összeadás DEC IR MAR MDR AC AC AC AC DEC címrész (MAR) AC + MDR vagy AC – MDR vagy AC * MDR vagy AC / MDR - adattárolás (store) DEC IR MAR MDR (MAR) DEC címrész AC MDR - a feltételes ugrás DEC IR PC DEC címrész - 16 - 7-8. ea Created by mrjrm & Pogácsa Az utasítások fajtái (utasítás-típusok) MK Címrész op – operandus s – Source (forrás) d – destination
(cél) @ - tetszőleges művelet 4 címes utasítás: - opd := ops1 @ ops2 , op4 d s1 s2 op4 - a 4. operandus a következő végrehajtandó utasítás címét tartalmazta Hátránya: = memóriapazarlás = további adatrögzítési hibák = merev program-struktúra ⇒ nehéz a karbantartása - Pl. ENIAC 3 címes utasítás: - opd := ops1 @ ops2 - az eredmény helyének explicit deklarálása - előnye: = az előző utasítás eredményének mentésével párhuzamosan tölthetjük az aktuális utasítás két bemenő operandusát. - hátránya: = Neumann szerint tipikusan az előző művelet eredménye a következő művelet egyik bemenő operandusa - Pl. RISC 2 címes utasítás - ops1 := os1 @ ops2 ops2 := ops1 @ os2 - pl. ADD[100],[102] - előnye: = kevesebb tárhelyet igényel (regiszter v. memória) = kielégíti a Neumann féle követelményt - Pl. IBM 360/370, Intel processzorokban; - 17 - 7-8. ea Created by mrjrm & Pogácsa 1 címes utasítás Pl - be kell
tölteni az egyik operandust az akkumulátorba LOAD[100] - az összeadó utasításban lévő operandust hozzáadjuk az AC-hoz és az eredmény az AC-ban keletkezik ADD[102] - az AC tartalmát kimentjük STORE[100] Az utasítások maguk rövidebbek, de több utasításra van szükség Pl. 1951 1AS – ötvenes-hatvanas években fordultak elő ilyen architektúrák 0 címes utasítás - fajtái = NOP – no operation = a műveleti kód tartalmazza az operandust is, pl. CLEARD ⇒ a Dflag törlése = verem-műveletek PUSH, POP Napjaink trendje 3 címes utasítások a RISC gépekben, mindhárom cím regiszterre mutat. 2 címes utasítások a mai CISC gépeket jellemzik: - általában az első operandus helyén keletkezik az eredmény - általában nem engednek meg 2 memória-operandust Operandus-típusok akkumulátor (a) memória (m) regiszter (r) verem (stack - s) immediate (i) immediate: magában a programban adunk értéket a változónak ⇒ a gyakorlatban ez bemenő operandus
Architektúrák szabályos akkumulátor a-r aar memória a-m ara kombinált(pl. a+m) - a mai CISC processzorok 2 címes regiszter 3 címes 2 címes aam ama m1m1m2 m2m1m2 m1m2m3 r1r1r2 - 18 - verem 3 címes r2r1r2 SSS r1r2r3 7-8. ea Created by mrjrm & Pogácsa Akkumulátor - előny: gyors rövid cím - hátrány: szűk keresztmetszett - napjainkban nem aktuális Memória - előny: nagy címtér - hátrány: lassú hosszú cím ⇒ hosszú utasítás - napjainkban nem aktuális Regiszter - előny igen gyors rövid cím - napjainkban RISC gépekben Verem - előny: gyors 0 hosszúságú cím - hátrány: szűk keresztmetszett - Pl. HP 3000, VT 1005 - 19 - 9-10. ea Created by mrjrm & Pogácsa Gépi kód Minden architektúra esetén más. Állapottér a felhasználó számára látható a felhasználó számára transzparens virtuális memória PC állapotjelzők CC állapot-indikátorok CC - Condition Code - 2 bites ⇒ négy érték felvétele - IBM
360 megszakítások verem . egyéb, a felhasználó számára látható állapotformáció adattípusonként különböző állapot-indikátorok nyomkövetés (debug) indexelés állapot-indikátorok (flag): - minden helyiérték saját jelentéssel bír, pl. negatív, nulla, túlcsordulás adattípusonként különböző állapot-indikátorok: - minden regiszterkészlet típushoz hozzárendelnek külön állapot-indikátor készletet, pl. az általános célú processzorhoz tartozó flag-eken kívül a lebegőpontos processzorhoz is hozzárendelnek külön flag-készletet. - a lebegőpontos flag-készlet eseményei pl. alul-, túlcsordulás, denormalizált szám, 0 Megszakítás esetén történő mentés: - IBM 370 ⇒ PSW ⇒ Program Status Word ⇒ megszakításkor a PSW-t mentették - kontextus: = a regiszterek aktuális értékei és = az állapottér aktuális értékei (flag, PC) - megszakítás esetén a kontextus kerül lementésre Állapotműveletek flag - save
(mentés) - load (visszatöltés) - set (beállítás) - clear (törlés) - reset (kezdeti értékkel beállítás) PC - inkrementálás - felülírás egy utasításból vett címmel - 20 - 9-10. ea Created by mrjrm & Pogácsa A processzorszintű architektúra Processzor = műveletvégző + vezérlő Szinkron-aszinkron - Szinkron: = egy elektronikus óra meghatározott időnként órajelet generál = minden elemi művelet órajelre kezdődik órajel az elemi műveletek t holtidő = hátránya: az elemi műveletek különböző ideig tartanak ⇒ holtidőt eredményez = előnye: az elektronikus óra és az órajel vezetése egyszerű és olcsó - Aszinkron: = minden elemi művelet befejeződése egyben jelzés a következő elemi művelet elkezdésére az előző művelet befejeződése az előző művelet befejeződésének érzékelése és a következő elemi művelet kezdete = az elemi művelet befejeződésének érzékelése időt vesz igénybe ⇒ időveszteség = az
elemi művelet befejeződésének érzékelője bonyolult, drága A ma piacon lévő processzorok szinkron vezérlésűek ~3GHz frekvenciával Műveletvégző egység Részei: - Regiszterek - Adat utak - Kapcsolópontok - Szűk értelemben vett ALU Regiszterek - a felhasználó számára látható (amire a programozó hivatkozni tud) – ezt vizsgáltuk a logikai architektúrában - rejtett regiszterek az adat feldolgozási technológiához szükséges puffer regiszterek - 21 - 9-10. ea Created by mrjrm & Pogácsa Adat utak - a memóriához való hozzáférést a vezérlő rész kezeli. A műveletvégzőben tehát nem értelmezett a címek kezelése ⇒ ezért adatút r0 r1 r2 . . rn Általános célú regiszterkészlet ADD r0r1r2 src0 r0 ⇐ r1 @ r2 Az utasítás végrehajtás hipotézise: src0 ⇐ r1 src1 ⇐ r2 rslt ⇐ src0 @ src1 r0 ⇐ rslt src1 adatút ALU rslt - az src0, az src1 és a rslt rejtett regiszterek Kapcsolópontok - a sín megosztott eszköz ⇒
egy időben csak egyetlen adó lehet U1 U2 U3 . Un kapcsolópontok közös sín - a kimenő kapu 3 állású: =0 =1 = zárva - a bemenő kapu 2 állású: =nyitva =zárva - a kapcsolópontok architekturálisan általában a regiszterek részét képezi - 22 - 9-10. ea Created by mrjrm & Pogácsa Szűk értelemben vett ALU lebegőpontos - összeadás - kivonás - szorzás - osztás -multimédia fixpontos - összeadás - kivonás - szorzás - osztás - multimédia BCD - összeadás egyéb - logikai - léptetés Fixpontos összeadás - mivel a kivonást, a szorzást és az osztást az összeadásra vezetjük vissza, ezért a sebesség meghatározó Egybites fél-összeadó A Jelölése: A 1 B S ∑/2 C 1 B Igazságtáblázat: 0 S 1 összeg (Sum-S) átvitel (Carry-C) A 0 0 1 1 Logikai függvények felírása: S=A⊕B C = AB Megvalósítás: A B ⊕ & S C Hátránya: - nem kezeli a bejövő Carry-t - 23 - B 0 1 0 1 S 0 1 1 0 C 0 0 0 1
9-10. ea Created by mrjrm & Pogácsa Egybites teljes összeadó - kezeli a bejövő átvitelt A S ∑ B Carry Out Carry In - megvalósítása 2 db fél-összeadóval CIn A ∑/2 ∑/2 B S 1 COut Tervezése: 1, Az igazságtábla felírása A 0 0 0 0 1 1 1 1 B 0 0 1 1 0 0 1 1 Cin 0 1 0 1 0 1 0 1 S 0 1 1 0 1 0 0 1 Cout 0 0 0 1 0 1 1 1 2, logikai függvények felírása (Cin ⇒ C) Cout: nABC + AnBC + ABnC + ABC 3, Azonos átalakítások a következő célfüggvényekkel - az elemszám minimalizálásával - a végrehajtási idő minimalizálásával Felhasznált azonosságok: ABC = ABC + ABC + ABC nA + A = 1 Cout = nABC + AnBC + ABnC + ABC +ABC +ABC = (nA + A)BC + (nB + B)AC + + (nC+C)AB = BC + AC + AB /ii/= AB + (A + B)Cin /i/ i: - 4db elem - 20% megtakarítás - Ha 1 elem késleltetése d, akkor T = 3d ii: - 33% időmegtakarítás - T = 2d - 24 - 11-12. ea Created by mrjrm & Pogácsa N – bites soros összeadó Megjelenésének oka: a
számítógépben a számokat tipikusan n - bit hosszúságú regiszterben tárolják ⇒ ezek tartalmát kell összeadni. Megvalósítása: S A ∑ B Cin Cout 1 Késleltető vagy tároló Jellemzői: - az eredmény az első operandus (A) helyén képződik - az A és a B léptető regiszter - a Cout esetén biztosítani kell, hogy az előző bithelyiértéken képződő átvitel az aktuális bithelyiérték összeadásakor érkezzen be. Erre szolgál a tároló vagy késleltető elem. - a bejövő átvitel (Cin) csak az első bithelyiérték esetén vesszük figyelembe. Értékelése: Ha az egybites teljes összeadó végrehajtási idejét t, akkor az n - bit összeadási ideje: T = n*t. Gyorsítás: - t csökkentése: igen gyors egybites teljes összeadó alkalmazása. - csökkentsük az n értékét egyre oly módon, hogy minden bithelyiértékhez hozzárendelünk egy egybites teljes összeadót ⇒ n - bites párhuzamos összeadó. Megvalósítás: An Bn A2 B2 A1 B1 A0 B0
Cout ∑ Sn ∑ Cn C2 ∑ S2 C1 - 25 – ∑ S1 C0 Cin S0 11-12. ea Működése: I. A 0101 B 1010 1111 II. A 0101 B 1010 1.lépés 1110 2.lépés 1100 3.lépés 1000 4.lépés 0000 Created by mrjrm & Pogácsa Cin=0, Tmin=t ; Cin=1, Tmax = n*t ; C0=1 C1=1 C2=1 C3=1 Értékelése: - igen nagy befektetés árán (megtöbbszöröztük az egybites összeadók számát) - csupán hullámzó teljesítményt értünk el, mert meg kell várni az átvitel terjedését. Átvitel előrejelzés (Carry-Look-Ahead = CLA) Alapelve: Cout = A * B + (A + B) Cin Az egyes bithelyiértékeken képződő átvitel függ - a két bejövő összeadandótól és ez előre ismert - a kívülről bejövő átviteltől, de nem függ az egyes bithelyiértékeken képződő átviteltől. A * B ⇒ G (Generate) A + B ⇒ P (Propagate) Ci = Gi + Pi * Ci-1 C0 = G0 + P0 * Cin C1 = G1 + P1 * C0 = G1 + P1 G0 + P1 P0 Cin C2 = G2 + P2 * C1 = G2 + P2 G1 + P2 P1 G0 + P2 P1 P0 Cin C3 = G3 +
P3 * C2 = G3 + P3 G2 + P3 P2 G1 + P3 P2 P1 G0 + P3 P2 P1 P0Cin Értékelés: - minden átvitel meghatározásához szükség van = ÉS kapuk sorozatára és 2 fokozat = ezeket összekapcsoljuk VAGY kapuval - a P és G meghatározása további 1 fokozat ∑:3 fokozat Amennyiben egy fokozat késleltetése d, akkor az egyes bithelyiértéken képződő átvitel meghatározásának ideje: T=3d. Jelölések: Megvalósítás, pl C3 meghatározása előre A3 B3 A2 B2 1 P3 1 & & C3 & C2 & - 26 – 11-12. ea Created by mrjrm & Pogácsa Megvalósítási alternatívák 1. Katalógus áramkörökkel egybites teljes összeadó + CLA CLA An-1 Cout Bn-1 A2 ∑ B2 A1 ∑ Sn-1 C2 B1 A0 ∑ S2 C1 B0 ∑ S1 C0 Cin S0 2. Az egybites teljes összeadót kiegészítjük egy ÉS, és egy VAGY kapuval, hogy meghatározzuk a P és a G értékét. P G P ∑ G P ∑ G ∑ Cin S S S 3. A VAGY kapu bemeneteinek száma technológiai
korlátokba ütközik, ezért maximum 8 bit vonatkozásában építhető meg a CLA. 32 bit megvalósítási lehetősége CLA CLA CLA CLA Hátrány: a CLA egységek között az átvitel sorosan terjed. 4. CLA a CLA-k számára: CLA CLA CLA CLA - 27 – CLA Cin 11-12. ea Created by mrjrm & Pogácsa Fixpontos kivonás Alapelvek: - a fixpontos összeadáshoz hasonlóan megtervezhető = az 1 bites fél-kivonó = az 1 bites teljes kivonó - az alkalmazásának hátrányai: = a kivonó csak akkor ad bit helyes eredményt, ha a nagyobb számból vonjuk ki a kisebbet. Ehhez minden kivonás előtt komparálni kell ⇒ lassú = a kivonó megvalósítása megduplázza a műveletvégző elemszámát ⇒ a lapka mérete viszont korlátozott ⇒ nem célszerű Megvalósítása: a számok átkódolása, kivonás visszavezetése összeadásra. Hagyományos kivonás: A 13 1101 -B -(+7) 0111 X ezt másképpen végezzük Egyes komplemens A 13 0|1101 -B +(-7) 1|1000 X 6 10|0101 = +5 1
0110 = +6 Egyes komplemens meghatározása: - pozitív számé maga a szám - negatív szám esetén bitenként invertálunk Megvalósítás: A B invertáló Cout Cin - 28 – 13-14. ea Created by mrjrm & Pogácsa Kettes komplemens Meghatározása: - az egyes komplemenshez hozzáadunk egyet - a bináris számból hátulról leírjuk az összes nullát és az első egyest, és utána bitenként invertáluk. Pl. A A 13 0|1101 segédszámítás: 7=0111 => 1001–kettes komplemense - B +(-B) +(-7) 1|1001 X X +6 00110 = +6 Az ideális: tudjon összeadni is. TRANS egység kialakítása: Igazságtábla: Vezérlés B B’ 0 0 0 0 1 1 1 0 1 1 1 0 - kizáró vagy (XOR) - amennyiben a vezérlés nulla, akkor a B értékeit változatlanul átengedi, amennyiben 1, akkor bitenként invertál. Megvalósítás: B 0/1 vezérlés TRANS A B’ ∑ Cin X Szorzás/Osztás - minden műveletvégzőnek kell tudni = összeadni = invertálni = léptetni, de nem kell tudni
szorozni/osztani, mivel az felépíthető az említett három műveletből. - 29 - 13-14. ea Created by mrjrm & Pogácsa Architekturális megvalósítása a szorzás/osztásnak Régen: - olcsó processzor – gépi kódú programmal - közepes áru processzor – mikro programmal - drága processzor – hardveres úton valósították meg Napjainkban: - PowerPC 603 = kettő db műveletvégző az egyszerű fixpontos műveletekhez ( + , - ) = egy db műveletvégző az összetett fixpontos műveletekhez ( * , / ) - Pentium Pro fixpontos műveletvégzői = általános célú = léptető = egész osztó = összeadó / kivonó = szorzó = osztó Hagyományos szorzás Algoritmizált változat Léptetéssel X=A*B=13123 39 26 13 1599 13*123 0000 20 39 100 0039 260 299 1300 1599 13*123 0000 39 0039 26 299 13 1599 felveszünk egy gyűjtőt és kinullázzuk Az összeadás ciklus annyiszor fut, ahány helyiértékű a szorzó Bináris szorzás sajátosságai • A bináris szám
hossza Decimális Helyiértékek száma Pl.: 1 9 2 99 3 999 Bináris Helyiértékek száma 4 7 10 Konklúzió: a bináris számok hosszabbak, mint a decimális számok az összeadási ciklusok száma magasabb lesz - 30 - 13-14. ea • Created by mrjrm & Pogácsa A szorzat hossza Decimális helyiértékek száma A 1 2 2 B 1 1 2 X 2 3 4 Általános formában m n m+n Konklúzió: mivel a szorzandó és a szorzó is egy-egy regiszterben helyezkedik el, így a szorzat kettő regiszterben keletkezik. Pl.: a szorzat kisebb helyiértékű része a szorzó helyén képződik Legyen 3 helyiértékes a regiszterünk 1 1 2 3 9 1 2 9 9 1 5 9 9 Gyorsítás - bitcsoportokkal való szorzás = a léptetés nem egyesével, hanem csoportonként hajthatjuk végre ⇒ gyorsabb = Pl. 2-es bitcsoportok • 00 – kettőt léptetek balra • 01 – hozzáadom a szorzat egyszeresét, majd léptetek kettővel balra • 10 – hozzáadom a szorzat kétszeresét, majd léptetek
kettővel balra • 11 – hozzáadom a szorzat háromszorosát, majd léptetek kettővel balra Segédszámítás: a szorzandó kétszeresének meghatározása 7*9 = 63 0111 * 1001 0000 0111 1110 111111 = 63 A, összeadással: 0111 0111 1110 B, léptetéssel Booth – féle algoritmus =bináris számok esetén az összeadási ciklus annyiszor fut, amíg egyes van a szorzóban =Pl. *62 111110 5 db összeadás *64 *2 100000 000010 1 db összeadás 1 db összeadás 1 db kivonás 3 db összeadás helyette: - - 31 - 40%-os gyorsítás 13-14. ea Created by mrjrm & Pogácsa Hagyományos osztás: X=A/B=150/48 150 -48 102 -48 54 -48 60 -48 120 I. 3,1 Fixpontos osztás Geometriai értelmezés: 0,48 II. III. 0 50 4,8 I. 100 48 48 150 48 Hátrány: minden kivonás előtt kell komparálnunk ⇒ lassú Visszatérés a nullán át 150 -48 102 -48 54 -48 6 -48 -42 +48 60 -48 12 -48 -36 +48 120 I. 3,1 II. Geometriai értelmezés: III. 4,8 I. -50 I.
Visszatérés nélküli osztás X=11/6 11 I. 1,83 -6 5 10.lépés -6 -10 9.lépés +6 - 4 8.lépés +6 +20 I. -6 14 II. -6 8 III. -6 2 -6 -40 0 50 100 150 48 48 48 Előny: a kivonások előtti komparálások helyett csak flag-et vizsgálunk ⇒ gyors Hátrány: felesleges munkát végzünk a visszatérés során Geometriai értelmezés: 0,6 0,6 0 5 6 - 32 - 10 11 6 15-16. ea Created by mrjrm & Pogácsa Fixpontos multimédia műveletek Hangfeldolgozás A probléma: • A hang analóg jel • A digitális jelfeldolgozáshoz digitalizálnunk kell az ún. analóg-digitális átalakítóval (A/D konverter) +128 +64 0 -64 -128 t Amplitúdó vagy felbontás • Az analóg jel minimális és maximális értékéhez hozzárendeljük a számtartományunk minimális és maximális értékét Lehetőségek: • 8 bit 256 féle lehetőség • 16 bit 65536 féle lehetőség Mintavétel: Pl.: 50 kHz 1 másodperc alatt 50000 mintát veszünk Alkalmazás kHz Telefon
8 Audio CD 44 DVD 48 Minőségi DVD 96 A tárigény meghatározása: • 1sec: Audio CD 2*2(sztereo)16(bites)=4400022= 176000 byte/sec ~ 170 kbyte/sec • 1min tárigénye: 60*170 ~ 10 Mbyte/perc Feladat: nagy tömegű fixpontos adat tárolása, továbbítása és feldolgozása Pixeles képfeldolgozás A probléma megfogalmazása: Felbontás: • • Egy fénykép vagy festmény analóg jelekből áll; fények, árnyékok, színek folyamatos átmenetei A képre helyezett mátrix egy pontját pixelnek nevezzükminél sűrűbben helyezkednek el a pixelek, annál tökéletesebb a kép leképzése - 33 - 15-16. ea • Created by mrjrm & Pogácsa Pl.: o 800*600 o 1024*768 o 1280*1024 Képpont, vagy pixel • a pixeleket 3 színből (RGB) építhetjük fel, tehát minden képponthoz 3 kódot kell hozzárendelni • az egyszerűsítés érdekében ezeket önálló kódértékekkel látták el: kódsor kód o 000 0 o 001 1 Lehetőségek • 1 bit = két érték; sötét, vagy
világos • 1 bájt = 8 bit 256 féle szín • 2 bájt = 16 bit 65536 féle szín (High-Color) • 3 bájt = 24 bit 224 féle szín (True-Color) • 4 bájt = ún. alfa csatorna az effektek számára; pl: átlátszóság mértéke Képméret 1 bájt 2 bájt 800*600 480 Kbyte 960 Kbyte 1280*1024 1,3 Mbyte 2,6 Mbyte Feladat: nagy tömegű fixpontos adat tárolása, továbbítása és feldolgozása Megoldás: • a tárolási és továbbítási probléma tömörítéssel oldható meg • feldolgozás o 2 kép összeadása beolvassuk az első kép első bájtját az akkumulátorba hozzáadjuk a második kép első bájtját az eredmény az akkumulátorban keletkezik az eredmény átvivése az akkumulátorból a memóriaterületre ez a ciklus 800*600-as képnél 480 ezerszer fut le SIMD – Single Instruction Multicle Data o az Intel 1997-ben vezette be az ún. MMX feldolgozást (Matrix Math eXportion) o pakolt adattípus 64 bites a belső sín szélessége
64 bit db Hossza(bit) Pakolt byte 8 64 Pakolt félszó 4 64 Pakolt szó 2 64 • műveletképzés SIMD esetében, pakolt byte alkalmazásával A + + + + + + + = = = = = = = B ~ 8-szoros sebességnövekedés X - 34 - 15-16. ea • • Created by mrjrm & Pogácsa logikai architektúra o a négy alapművelet és a logikai műveletek vonatkozásában új utasítások mind a 3 alaptípusra fizikai architektúra o annak érdekében, hogy ne kelljen újabb regisztereket kialakítani, az MMX utasítások a lebegőpontos regisztereket használják fizikailag o egy év múlva már nem egy, hanem kettő MMX műveletvégzőt integrált az Intel a processzoraiba Lebegőpontos műveletek A lebegőpontos ábrázolás kialakulásának oka: A fixpontos ábrázolás hátrányai • szűk értelmezési tartomány. Pl: integer esetén: - 32768 ÷ + 32767 • a tört számok pontatlan ábrázolása o Ha a kettedes pontot a regiszter végébe tesszük, akkor pl. 7/4=1 A lebegőpontos
ábrázolás kiküszöböli ezeket a hátrányokat • A számokat hatványkitevős formában ábrázolja M : mantissza ±M*r+k r : radix (számrendszer alapja) k: karakterisztika Története • 1933 Konrad Zusen a Zuse 3-ban alkalmazta • Neumann: ellenezte, mivel a számok maguk hosszúak, memóriaigényesek, a számítás velük bonyolult összetett vezérlőrészt igényelt nem javasolta használatát A hetvenes évek főbb vonulatai • UAX • Cray • IBM 370/390 1985-ben az IEEE szabványosította. Jellemzői radix • A megállapodás szerinti architektúrán belül állandó • Tipikusan kettő • IBM 370/390 esetén 16 Nem normalizált • 123,567*100=0,1234567103=12345,6710-1 ezt a formátumot az architektúrák tipikusan nem alkalmazták A normalizált formátum • képlettel 1/r ≤M<1 • szövegesen: a törtpontot az első értékes számjegy elé helyezzük • pl.: ½ ≤ M < 1 ; 1/10 ≤ M < 1; + n fenn van tartva a végtelen jelölésére -
0,999*10+n-1 -0,1*10-n +0,1*10-n + 0,999*10+n-1 0 overflow underflow Felhasználható régió - 35 - overflow 15-16. ea Created by mrjrm & Pogácsa over- underflow • underflow esetén következmény o kijelzi o vagy nullát, vagy denormalizált számot ábrázol • overflow o kijelzi o vagy a lehető legnagyobb számot, vagy előjeles végtelent ábrázol denormalizált szám a denormalizált számok ábrázolását a mai architektúrák többsége lehetővé teszi 0 0,04 0,1 17-18.ea Értelmezési tartomány A karakterisztika helyiértékeinek száma Pl. Tízes számrendszer Konklúzió 1 9 9 Függ a karakterisztika 2 999 helyiértékeinek száma 1 Kettes számrendszer Függ a számrendszer alapjától milliárd 2 1 Pontosság = ha a regiszterünk mantissza része 3 helyiértékes, akkor 0,3456 mantisszát csak 0,345-ként tudjuk felírni. Pl 106 karakterisztika esetén 600-zal torzul az eredmény = tehát a pontosság függ a mantissza
helyiértékeinek számától A 0 körüli számok = amennyiben a mantissza értéke nulla, akkor az architektúrától elvárt, hogy a karakterisztika is nulla legyen Rejtett bit ½≤M<1 0,111010 = mivel a kettedes pont utáni első értékbitnek nincs információ tartalma, hanem kötelezően egyesnek kell lennie, ezért • a memóriába vagy a háttértárra való kiírás előtt ezt a bitet balra léptetik, s jobbról beléptetünk egy értékes bitet ⇒ ily módon egy helyiértékkel megnöveljük a mantissza hosszát ⇒ növekszik a számpontosság • amikor egy lebegőpontos számot betöltünk az operatív tárból vagy a háttértárról, akkor legelőször visszaállításra kerül a rejtett bit, hiszen a számításnál szükség van rá a rejtett bitet már alkalmazta a Zuse is (1933) a rejtett bitet minden mai piacon lévő processzor használja - 36 - 15-16. ea Created by mrjrm & Pogácsa Őrző bitek = a processzoron belül, mind a
lebegőpontos regiszterek mantissza része, mind a műveletvégző 4-6 bittel hosszabb, mint a tárolási formátum ⇒ ezek az őrző bitek = az őrző bitek felhasználása: • a rejtett bit helyén történő léptetésekor jobbról értékes bitet lehet beléptetni • a tárolási formátum kérésekor kerekített értéket írhatunk ki⇒pontosabb • az eredmény normalizálásakor jobbról értékes bitet tudunk beléptetni = minden mai piacon lévő architektúra alkalmazza az őrző biteket mantissza kódolása = a mantisszát az architektúrák 2-es komplemens formában ábrázolják karakterisztika kódolása = a karakterisztika kódolása többletes kód • a többletes kód kialakítása gyorsabb, mint a 2-es komplemens • mivel a karakterisztikával csak + , - és léptetés műveleteket kell végrehajtani – ez a többletes kód esetében is elvégezhető – ezért alkalmazzák. = minden ma piacon lévő architektúra esetén ezt a megoldást alkalmazzák - 37 -
17-18. ea Created by mrjrm & Pogácsa IEEE 754-es lebegőpontos szabvány - 1977-ben kezdték a kidolgozását - célja: a lebegőpontos számok adat-szintű portabilitásának megteremtése - minden architektúrából összegyűjtötték a legjobb megoldásokat - rendszerszinten gondolkoztak, azaz nem írták elő, hogy mit kell megvalósítani hardver- és mit szoftverszinten - a szabvány fejezetei: = formátumok = műveletek = kerekítések = kivételek formátumok szabványos egyszeres kiterjesztett kétszeres pontosság egyszeres kétszeres pontosság = szabványos - kiterjesztett: • a szabványos az operatív tárban illetve a háttértáron használt tárolási formátum • a kiterjesztett a processzoron belüli feldolgozási formátum • a tárolási a rövidebb, a feldolgozási a hosszabb • a szabványost szigorúbb szabályokkal rögzítették • a kiterjesztett esetén maximális szabadságot biztosítottak a gyártóknak = szabványos: • Kizárólag
az egyszeres pontosság a kötelező, a kétszeres pontosság opcionális • Egyszeres pontosság: Gyorsabb futás Kisebb memóriaigény Kevésbé pontos az eredmény • Kétszeres pontosság: Lassabb futás Nagyobb memóriaigény Pontosabb eredmény • A kétféle formátum között a programozó dönt • Egyszeres pontosság 32-bites formátum 38 38 Értelmezési tartománya: ~-10± ÷ +10± 1 8 23 mantissza előjele karakterisztika mantissza • Kétszeres pontosság 64-bites formátum 308 308 értelmezési tartomány: ~-10± ÷ +10± 1 11 55 - 38 - 17-18. ea Created by mrjrm & Pogácsa = kiterjesztett formátum = kizárólag a processzoron belül használják = egyszeres pontosság ⇒ min 43 bit hosszú (32+11(őrzőbit)) = kétszeres pontosság ⇒ min 79 bit hosszú (64+15(őrzőbit)) - műveletek - min. a 4 aritmetikai művelet - maradékképzés - négyzetgyökvonás - bináris, decimális konverzió = értelmezett a
végtelennel való műveletvégzés is pl.(3+(+∞))=+∞ (3+(-∞))=-∞ - kerekítések = a legközelebbi felé történő kerekítés (mint a hagyományos kerekítés, pl. 83,4 ⇒ 83) = a pozitív végtelen felé = a negatív végtelen felé • az utóbbi kettő az intervallumalgebrához kapcsolódik • kétszer hajtják végre a számításokat: egyszer a pozitív végtelen felé egyszer a negatív végtelen felé • az eredmény a két kapott eredmény között helyezkedik el • amennyiben a két eredmény közti intervallum a számítási igényünk szempontjából túl nagy, akkor elemezni kell a feladat megnevezését illetve a számítási algoritmust = levágja vagy trunc (pl. 83,9⇒83) - kivételkezelés: = nullával való osztás = overflow = underflow = négyzetgyök negatív számból - 39 - 17-18. ea Created by mrjrm & Pogácsa Esettanulmányok Intel processzorcsalád: = 1981-ben az Intel 8087-es processzorban valósul meg először
1985-ben megjelent IEEE 754-es szabvány - Logikai architektúra: = a radix 2 = underflow esetén denormalizált számot ábrázol = overflow esetén előjeles végtelen ábrázolása = létezik a rejtett bit = léteznek az őrző bitek = a mantissza 2-es komplemens = karakterisztika többletes kódolású = a szabályos formátumok közül megvalósításra került, mind az egyszeres, mind a kétszeres pontosság = a kiterjesztett formátum 80 bit hosszú 1 15 64 - a programozó dönti el, hogy ebből a formátumból egyszeres vagy kétszeres formában íratja ki - Fizikai architektúra: = az Intel 8087-es társprocesszor volt, mivel nem fért rá a 8088-as lapkára technikai okok miatt - hasonló elvű 80287 és a 80387 is - 80486DX ⇒ a miniatürizálás eredményeképpen már közös lapkán helyezkedi el a lebegőpontos és az általános célú processzor = teljesítményjellemző: Processzor Sebesség Relatív MIPS 80386 25MHz ~17 80486 66MHz ~1700 Pentium 133MHz ~6000 •
relatív MIPS: az eredeti 1981-ben megjelent IBM PC teljesítménye=1 • a 100-szoros növekedés annak köszönhető, hogy hardveres úton valósították meg a lebegőpontos műveleteket • a 3-szoros növekedés a futószalag bevezetésének eredménye - 40 - 19-20. ea Created by mrjrm & Pogácsa Műveletek lebegőpontos számokkal Példa Összeadás A=0,90*103 0,09104 B=0,95*104 0,95104 1,04*104 0,104105 X=A+B A=±mA*r±kA B=±mB*r±kB Algoritmus • A kitevőket megvizsgáljuk: csak azonos kitevőjű számok adhatók össze. • Amennyiben a kitevők nem egyenlők, akkor o A kisebb kitevőjű szám mantisszájának törtpontját balra léptetjük, és közben inkrementáljuk a karakterisztika értékét o A ciklus addig fut, amíg a kitevők meg nem egyeznek. • Mantisszákat összeadjuk, karakterisztikákat változatlanul hagyjuk • Normalizálás szükség esetén Szorzás X=A*B=(mA)(mB)rkA+kB Algoritmus • A mantisszákat összeszorozzuk,
karakterisztikákat összeadjuk Osztás X=A/B=(mA)/(mB)*rkA-kB Algoritmus • Mantisszákat elosztjuk, karakterisztikákat kivonjuk egymásból Megvalósítás Univerzális végrehajtó egység • Általános célú ALU parciálásával (részekre bontásával) karakterisztika • mantissza A vezérlőrész bonyolítását eredményezi ALU Szervezési megoldás o Külön elvégezzük a műveleteket a mantisszán és a karakterisztikán külön regiszterekben tárolódnak műveletvégzés közben, majd a művelet után közös regiszterekben egyesítjük. - Dedikált Adatsín Kar. Mantissza Vezérlő - 41 - 19-20. ea Created by mrjrm & Pogácsa Dedikált jellemzői • Míg a mantissza egységnek szorozni/osztani is kell tudni, a karakterisztika egységnek elég összeadni/kivonni • A mantissza és a karakterisztika egység párhuzamosan is működhet, ekkor a mantissza egység jelenti a szűk keresztmetszetet a szorzás/osztás miatt, tehát azt kell igen
gyors végrehajtásúra tervezni. Lebegőpontos, vektorgrafikus multimédia műveletek Probléma megfogalmazása A vonalakkal, görbékkel határolható objektumok geometriailag definiálhatók. Elegendő geometriai jellemzőit tárolni Példa: • Egyenes: kettő pontjának koordinátája • Kör: középpont koordinátája és a sugár hossza 2D jellemzői • A tárolt geometriai koordináta alapján a számítógép számítja ki magát az objektumot • A képletet tipikusan sokszögekre, háromszögekre bontjuk, melyek száma jellemzően képenként ~20000 • Az egyes objektumok közötti átmenet érdekében a képre textúrát helyezünk. Műveletek • Kicsinyítés • Nagyítás • Forgatás • Kitöltés színnel • Több objektum csoportosítása/lebontása Feladat • Viszonylag kevés lebegőpontos adaton sok művelet végrehajtása 3D jellemzői • Plusz egy harmadik dimenzió • A természetes hatás érdekében biztosítják a párhuzamosoknak
végtelenbeli összefutását és egy atmoszférikus kiegészítéssel a közeli tárgyak élesek, távoliak elmosódottak. • Jellemző a 3D filmek alkalmazása o Annak érdekében, hogy folyamatosnak érzékeljük, min 15 frame/sec sebesség kell. Számítások száma: 20000*15=300000 objektum/sec (mostanság ez az érték már inkább többmillió/sec) Feladat • Viszonylag kevés lebegőpontos adaton igen sok művelet végrehajtása adott idő alatt. Megoldás az Intel processzoroknál • 1998: MMX2 vagy KNI (Katmai New Instruction) Elve: SIMD 8 db. 128 bites új regisztert vezettek be egyszerre 4 ill 2 db lebegőpontos szám • 1985 óta először bővült a regiszterkészlet az Intel processzorokban • egyszerre 4 ill. 2 db számon lehet lebegőpontos műveletet végezni + + + + • • = = = = 70 db. új utasítás Operációs rendszer módosítását is igényelte: Gondoskodni kellett az új regiszterek mentéséről. Először a Windows’98 biztosította - 42 -
19-20. ea Created by mrjrm & Pogácsa A lebegőpontos feldolgozás jellemzői • • a tudományos és vektorgrafikus műveletek esetében nélkülözhetetlen a technikai fejlődés és a fajlagos árcsökkenés eredményeképpen ma már minden processzorban hardveres úton valósítják meg BCD Megjelenésének oka: • Fixpontos ábrázolással a törtszámok pontatlanok • Lebegőpontos ábrázolással a mantissza-, karakterisztikaforma nem teljesen pontos. • A kettes komplemens esetében: 10-es számrendszerű számokat átszámítjuk kettesbe, majd vissza • BCD esetében decimális számrendszerből átkódoljuk a számokat kettesbe és vissza. Kódolás = egyértelmű megfeleltetés A BCD pontosabb ábrázolás Jellemzői • Ábrázolási forma o Zónázott Z BCD Z BCD Z BCD. Előjel BCD Egy byte két részre oszlik. Magas tetrád a zóna, kisebb tetrád a BCD. A zóna tipikusan nyomtatható karakterre egészíti ki a BCD számot ASCII esetén tipikusan
„3” és EBCDIC esetén tipikusan „F”. Általában nem lehet műveletet végezni a zónázott számokkal (IBM, VAX), de az Intel kivétel, nála lehet! o Pakolt Minden bájtban 2 db. tetrád helyezkedik el BCD BCD BCD BCD BCD • • • Pl.: Intelnél 10 db bájt hosszú, ahol Az első bájt első bitje az előjel A bájt többi bitje nem használatos A további kilenc bájt tartalmazza a BCD számokat Az értelmezési tartomány: (-9.99˙*1018) ÷ (+9.99˙*1018) jellemzően ezzel a formátummal végzik a műveleteket A szám hossza o Fix o Változó jelölni kell a hosszát is. Az előjel hossza o 4 bit – tipikusan a zónázott ábrázolásnál o 8 bit – tipikusan a pakolt ábrázolásnál Az előjel értéke o Érvénytelen tetrád A, C, E, F a pozitív B, D a negatív o A + és a – az ASCII kódja! - 43 - 21-22. ea Created by mrjrm & Pogácsa Összeadás BCD számokkal Ugyanúgy adjuk össze a BCD számokat is, mint a
binárisakat, csak - fel kell ismernünk az érvénytelen tetrádokat és - ezek esetén korrekciót kell végrehajtani. A, Az érvénytelen tetrádok felismerése A BCD számok Decimális BCD kód 0 0000 1 0001 2 0010 3 0011 4 0100 5 0101 6 0110 7 0111 8 1000 9 1001 A 1010 B 1011 C 1100 D 1101 E 1110 F 1111 Felismerésünk: - az első bithelyeiértéken 1-es áll ÉS - a második VAGY a harmadik bithelyiértéken is 1-es áll. Érvényes tetrádok B, Korrekció: az érvénytelen tetrádok esetén = kivonunk belőle 10-et és = lépünk egy 10-es átvitelt pl.: A 8 1000 +B +7 0111 X 15 1111 +(-10) 0110 5 1|0101 10-es átvitel Segédszámítás: 10D = 1010B = 0110kettes komplemens 5D - 44 - 21-22. ea Created by mrjrm & Pogácsa Megvalósítás: A3 1 Cout B3 A2 ∑ ∑/2 A1 ∑ S3’ & B2 C2 B1 A0 ∑ S2’ C1 ∑ S1’ C0 B0 Cin Összeadó fokozat S0 1 Érvénytelen tetrádokat felismerő fokozat ∑ ∑/2 Korrekció S3 S2 S1 A BCD
műveletvégzők megvalósítása - univerzális műveletvégzőben, a BCD-nek megfelelő vezérléssel - dedikált: külön BCD műveletvégző A BCD jelentősége: - előnye: pontosság - hátránya: = a komplexebb és ezért lassúbb műveletvégzés = a memória kihasználtság rosszabb, hiszen a 16-féle BCD számból csak kb. 60%-át, 10 félét használunk ⇒ a BCD számok hosszabbak, mint a binárisak Pl.: 12D = 1100B = 00010010BCD - 45 - 21-22. ea Created by mrjrm & Pogácsa Fixpontos, lebegőpontos, BCD ⇒ melyiket használjam? Fixpontos: - igen gyors a fixpontos műveletvégzés - a memória igény kisebb, mert többféle formátumot alkalmaz: 8, 16, 32, 64, 128 bites - a formátumok közül mindig a számunkra szükséges értelmezési tartománynak megfelelően válasszuk - egész számok esetén teljesen pontos az ábrázolás, pl. if a=1 csak fixpontos és BCD ábrázolás esetén adható ki, lebegőpontosnál nem - törtnél teljesen pontatlan (7/4=1)
Lebegőpontos: - akkor alkalmazzuk, amikor = a számunk értelmezési tartománya túllép a fixpontos által biztosítotton, ill. = törtszámok ábrázolási igénye esetén - a lebegőpontos ábrázolás a gyakorlatban kielégítő pontosságot biztosít - csak indokolt esetben alkalmazzuk a kétszeres pontosságot, mert lassúbb. BCD: - a lebegőpontos ábrázolás egy alternatívája a pontosabb BCD ábrázolás Az ALU egyéb műveletei - mind a 16 Boole-algebrai műveletre képes (Pl.: VAGY, ÉS, kizáró VAGY, NEM) - léptetés - invertálás - címszámítás: = korai gépekben az univerzális ALU végezte = később dedikált címszámító egység - karakteres műveletek tipikusan az általános célú műveletvégző által kerülnek végrehajtásra Vezérlőrész Fejlődése Futószalag Párhuzamos (decentralizált) vezérlés Szuperskalár Mikroprogramozott (vezérlés) Szekvenciális (centralizált) vezérlés huzalozott 1947 első elektronikus számítógép 1954
Wilkes 1963 CDC660 1967 t - a decentralizált vezérlés a huzalozott ill. mikroprogramozott vezérlési elemekből épül fel - 46 - 21-22. ea Created by mrjrm & Pogácsa Huzalozott vagy áramköri vezérlés Tervezése: - igazságtábla - logikai függvények - azonos átalakítások a következő célfüggvénnyel: = az elemszám minimalizálása (a lapkaméret korlátozott volta) = a végrehajtási idő minimalizálása - megvalósítás Hátrányai: - ember számára nehezen áttekinthető (az azonos átalakítása után, azok következtében) - merev nehezen módosítható (midig az igazságtáblázatból kell kiindulni) Előnyei: - igen gyors Megvalósítása MEMÓRIA MDR MAR IR PC DEC címsín Vezérelt objektum Elve: Ütemező CLOCK RESET Külső feltételek (flag-ek) Egy forrásregiszter tartalmát módosító áramkörön keresztül egy célregiszterbe vezetjük. Regiszter: - ALU ⇒ pl. AC, általános célú regiszterek - Memória ⇒ MAR, MDR -
Vezérlősín ⇒ IR, PC - I/O regiszterek ⇒ vezérlőkártyában - 47 - 21-22. ea Created by mrjrm & Pogácsa Módosító áramkörök: - inkrementálás - léptetés - invertálás - összeadás - stb. Működése: - a forrásregiszter kimenetét rákapuzzuk a módosító áramkör bemenetére - előírja a módosító áramkör számára, hogy milyen módosítást hajtson végre (pl. inkrementálás, léptetés, stb.) - a módosított áramkör kimenetét rákapuzza a célregiszter bemenetére Egy mai tipikus processzorban több száz vezérlési pont van. - 48 - 23-24. ea Created by mrjrm & Pogácsa & Pheenix Mikroprogramozott vezérlés 1954 Maurice Wilkes (University of Cambridge) Célja: - az ember számára áttekinthetővé tegye a vezérlést = mikroutasítások definiáltak, melyek meghatározott vezérlővonalat vagy vezérlővonalakat aktiválnak = mikroutasítások sorozata szolgál egy-egy gépi kódú utasítás végrehajtásának elemi
szintű vezérlésére = a hagyományos Neumann-féle „makroszámítógépen” belül értelmezünk egy „mikroszámítógépet”, mely saját mikroutasításkészlettel rendelkezik - a vezérlőrész rugalmassá, könnyen módosíthatóvá alakítása = a mikroprogram a mikroprogramtárban helyezkedik el, így az módosítható A Wilkes-féle modell Pl. add MK Címrész CM CMAR mikroutasítások CLOCK DEC 0001 0010 0011 0101 1001 00 01 02 S 03 04 Control mátrix C0 C1 C2 Cn AnA2 A1 A0 Vezérelt objektum Address mátrix CMAR – Control Memory Address Register CM – Control Memory S - feltétel Működése: A. Mikroutasítás szekvencia: 1. A feldolgozandó gépi kódú utasítás műveleti kód része - megfelelően kódolva - letöltésre kerül a CMAR-ba. Megfelelő kódolás: a CMAR-ba az adott gépi kódú utasítás végrehajtását elemi műveleti szinten vezérlő mikroprogram kezdő címe kerül. 2. Ez a CMAR-ból a DEC-be kerül, amely az adott című
mikroutasítást érvényes állapotba helyezi. 3. Az érvényesített mikroutasítás végrehajtása során - aktiválja a vezérlőmátrixban a kijelölt vezérlővonalakat, ezt bizonyos ideig kitartja, majd - az adott mikroutasítás címrészében lévő következő végrehajtandó mikroutasítás címét beírja a CMAR-ba 4. vissza a 2 pontra - 49 - 23-24. ea Created by mrjrm & Pogácsa & Pheenix B. Feltételes mikroutasítás végrehajtása - amennyiben feltételes ugrás mikroutasítás végrehajtása következik, akkor: = aktiválásra kerülnek a mikroutasítás által kijelölt vezérlőútvonalak, ezek egy bizonyos ideig kitartódnak, majd = az adott mikroutasítás címrészében lévő kettő db. cím közül a feltétel igaz vagy hamis voltától függően vagy az egyik vagy a másik cím kerül a CMAR-ba letöltésre Pl. Az ADD utasítás végrehajtása DEC IR MAR DEC címrész MDR(MAR) ACAC+MDR Egy korszerű mikro-utasítás felépítése:
Vezérlőrész feltétel kiválasztó mező ugrási cím - a feltétel kiválasztó mező : megmutatja, hogy a tesztelendő feltételek közül melyiket választjuk ki - ugrási cím: ugró mikroutasítás esetén, amikor a feltétel igaz erre a címre adódik át a vezérlés - a vezérlőrész: kijelöli melyik vezérlővonalakat kell aktiválni Egy korszerű mikro-vezérlő megvalósítása Külső feltételek MUX MPC Külső forrás inkrementálás MPC Mikro-Program Counter CM Control Memory CMDR Control Memory Data Register MUX Multiplexer CM CMDR DEC - 50 - 23-24. ea Created by mrjrm & Pogácsa & Pheenix Működése: A. Mikro-utasítás szekvencia 1. az MPC-ben lévő következő végrehajtandó mikroutasítás címe által meghatározott mikroutasítás a CM-ből eljut a CMDR-be 2. a CMDR-ben lévő mikroutasítás vezérlő része aktiválja a kijelölt vezérlővonalakat, és azt meghatározott ideig kitartja 3. az MPC tartalma inkrementálódik és
vissza az első pontra B. feltételes ugrási mikroutasítás -. amennyiben a CMDR-ben feltételes ugrási mikro-utasítás van, akkor = a vezérlő része aktiválja a kijelölt vezérlővonalakat, és azt meghatározott ideig kitartja = a feltétel kiválasztó mező által meghatározott külső feltétel tesztelésre kerül, és annak igaz vagy hamis voltától függően • vagy a mikroutasításban tárolt címmel felülíródik az MPC tartalma • vagy pedig az MPC tartalma inkrementálódik Megjegyzések: - míg a Neumann-féle „makroszámítógép” operatív tárában együtt tároljuk az adatokat és az utasításokat, s ezért szükség van külön PC-re, MAR-re - addig a mikroprogramozott vezérlő CM-jében csak mikroprogramozott utasítások vannak, ezért * amennyiben nincs szükség, lehetőség inkrementálásra, akkor CMAR-t használunk, * amennyiben szükséges az inkrementálás, akkor MPC-t. A mikro-utasítás hosszát meghatározó tényezők A probléma:
célszerű - régen a CM drága volt, takarékoskodni a - jelenleg a lapkán van méretével - a feltétel kiválasztó mező rövid - Címrész: A, a következő végrehajtandó utasítás címe - maga a mikroutasítás tartalmazza (Wilkes féle modell) - MPC alkalmazásával határozzuk meg (korszerű mikrovezérlő) B, Ugrási cím - kisebb az ugrási címtér, mint a CM címtere CM címtere Pl. 1024=210 CM Ugrás címtere Pl. 256=28 - külső forrásból töltjük fel - az ugrási cím ritkán van kihasználva, utasítás szekvenciák esetén hasznosítható vezérlő részként Ugrási cím - kétszintű mikroutasítás (pl. Motorola) 17 bit 68 bit Jelzőbit -cím vagy -vezérlőrész Megtakarítás: Több mutató is mutathat ugyanarra a hosszú vezérlőrészre (ezt ugyan csak egyszer tároljuk) - 51 - 23-24. ea Created by mrjrm & Pogácsa & Pheenix - vezérlőrész = horizontális mikroutasítás • hosszú mikroutasítások • csekély mértékű
kódolás • magas szintű párhuzamosság • pl. IBM 360, PDP 8, Motorola; • Esettanulmány o IBM 360 90 bit 21 vezérlőmező 21 db azaz 21 db, hardverileg egymástól független egységet kell vezérelni ⇒ maximum 21-szeres párhuzamosság érhető el 55.-57 bithelyiértékek vezérlik az ALU jobboldali bemenetét: azaz mely regisztereket kell rákapuzni 58.-61 bithelyiértékek írják elő az ALU számára, hogy milyen műveletet hajtson végre. A lehetőségek: bináris vagy BCD összeadás a bejövő és a kimenő átvitel különféle kezelésével. o PDP 8 a vezérlőrész 128 bit hosszú hipotézis: 27=128, azaz 7 biten kódoljuk le a 128 féle értéket. Ez az elve a vertikális mikroutasításnak. = vertikális mikroutasítás • rövidek • erős kódolás • csekély mértékű párhuzamosság • Pl. IBM 370, Intel processzorok • Esettanulmány: IBM 370 o a mikroutasítás a gépi kódú utasításra emlékeztet: Opcod =
napjaink gyakorlata DEC 1.cím 2.cím CM, címképzési információ négy bájt hosszú a címek tipikusa processzor-regisztert címeznek a címképzési információ emlékeztet a Wilkes-féle modellre DEC Vezérelt objektum • a gyakorlatban szükséges vezérlések horizontálisak, a ritkábban használtak tömörített formában helyezkednek el a vezérlőrészben, amit a dekóder old fel. - 52 - 25-26. ea Created by mrjrm & Pogácsa A mikroprogramok időzítése A mikroutasítások fajtái: - monofázisú mikroutasítások: a mikroutasítás végrehajtási ciklusa megegyezik az óraütemmel - polifázisú mikroutasítás: egy mikroutasítás több óraütem alatt hajtódik végre ⇒ egy mikroutasításban egy egész elemi műveleti szekvenciasort írhatunk elő = pl. R1 ← f(R0) - az elemi műveleti szekvencia 1. a mikroutaítás lehívása a CM-ből 2. az R0 kimeneti kapuját rávezetjük az „f” módosító áramkör bemenetére 3. előírjuk, hogy az
„f” módosító áramkör milyen módosítást hajtson végre 4. az f módosító áramkör kimenetét rákapuzzuk az R1 regiszter bemenetére mikroutasítási ciklus 1. Következtetés: mivel a huzalozott vezérlésnél nincs értelmezve a mikroutasítás lehívása, ezért a huzalozott vezérlés mindig gyorsabb, mint a mikroprogramozott 2. 31 4. t óraütem A mikroprogramozott vezérlés gyorsítása Amennyiben a mikroprogramozott vezérlés mellett döntöttünk, akkor a lehető leggyorsabb vezérlés érdekében horizontális mikroutasítást és igen gyors CM-t kell alkalmazni. - szervezési gyorsítási lehetőségek: prefetch azaz elő lehívás alkalmazása. 1. Amíg a vezérlés a CMDR0-ban lévő mikroutasítás alapján történik, azzal párhuzamosan lehívjuk a következő végrehajtandó mikroutasítást a CMDR1-be 2. A vezérlés most a CMDR1-ből fog történni, s ezzel párhuzamosan lehívjuk a következő CMDR0 CMDR1 végrehajtandó mikroutasítást a CMDR0-ba
CM DEC Vezérelt objektum - 53 - 25-26. ea Created by mrjrm & Pogácsa Megjegyzés: • Általában egy vezérlővonalon egy óraütem alatt aktív • Abban az esetben, ha bizonyos vezérlésre hosszabb ideig van szükség – pl. adatátvitel esetén -, akkor a vezérlőrészt egy regiszterbe mentik, s onnan tartják ki a vezérlést. Ezt maradékvezérlésnek (residnal control) nevezzük. Mikroprogramozás: - a mikroprogram utasításai numerikus kódok az assembly szintű nyelvekre emlékeztet - létezik mikroassembler, azaz fordítóprogram, mely a forrás nyelvű mikroprogramot végrehajtó formátumra fordítja ⇒ az utóbbi tölthető be a CM-ba - a mikroprogramozás igen mély hardverismeretet igényel. Ezt a szintet a gyártók tipikusan nem publikálják. - a mikroprogram hiba következményei: = a hardverműködés képtelenné válik (nem segít a Reset) = az operációs rendszer lefagy Huzalozott kontra mikroprogramozott Sebesség Mindig gyorsabb Mindig
lassabb Áttekinthetőség Ember számára nem Ember számára áttekinthető áttekinthető Módosíthatóság Merev, nehézkesen Mikroprogramcsere lévén módosítható cserélhető Sínrendszer (Buszrendszer) Bevezetés: - a sínrendszer az egységek közötti kommunikációra szolgál - maga a sínrendszer a kommunikáció infrastrukturális része, később önálló I/O rendszerként tárgyalni fogjuk a perifériáknak a processzorral, ill. a memóriával való kapcsolatának sajátosságait - a sínrendszer egy történelmi fejlődés eredménye ⇒ ez bizonyult a legjobbnak - az egységek egymással kizárólag a sínrendszeren keresztül kommunikálnak, mégpedig szervezett, egységes módon - pl. Falu1 Falu2 Hegy Út - 54 - 25-26. ea Created by mrjrm & Pogácsa Kommunikáció fajtái: - Egységen belüli kommunikáció (pl. a processzoron belül) = kicsik a távolságok ⇒ a késleltetés elhanyagolható = egy központi óraütemadó vezérli mind az adót,
mind a vevőt viszonylag egyszerű megvalósítás - Egységek közötti kommunikáció (pl. a processzor és a perifériák között) = viszonylag nagyok a távolságok, jelentős a késleltetés = jelentősek az optimális sebességek közti különbségek az egyes egységek vonatkozásában (pl. más az optimális sebessége a processzornak és más a billentyűzetnek) nem célszerű a központi óraütemadó alkalmazása = szabványosítása • a processzor-memória közötti sínen szintén lehetetlen és értelmetlen • a perifériák esetében már jelenhetnek meg szabványok (pl. PCI) - 55 - 27-28. ea Created by mrjrm & Pogácsa A sínrendszer fogalma: - műszaki: olyan vezetékrendszer, melynek minden egyes erén = vagy csak a logikai nullának megfelelő 0V = vagy a logikai egyesnek megfelelő 12V; 5V; 3,3V; 2,8V - funkcionális: olyan vezetékköteg, mely biztosítja, hogy a forrásból a célba egyidejűleg, azaz párhuzamosan n db. bit juthasson el Ebben a
kontextusban (értelmi összefüggésben) a sín alatt nem csupán a vezetékeket értjük, hanem = a sínfoglalást, valamint = az adatátvitelt biztosító intelligenciát is. Jellemzői: - vezetékek száma vagy sínszélesség - napjainkban tipikusan megosztott (shared) eszköz: = minden vezetéke egy időpillanatban csak egy bitnyi információt továbbít = minden időpillanatban vagy csak a logikai nullának, vagy csak a logikai egynek megfelelő feszültségszint lehet egy vezetéken databus ← r0 - regiszter-tulajdonsággal rendelkezik. Értelmezett a következő: r1 ← databus Fajtája - az adatátvitel szerint: = simplex: egyirányú = duplex: időben csak egyirányú (vagy az egyik vagy a másik irányba történhet az átvitel egyidejűleg) = full duplex: egy időben kétirányú forgalom - pl. egyirányú: órajel, reset, címvonal; kétirányú: adatvonalak; - az átvitel jellege szerint: = dedikált: • Jellemzői: U1 U2 Minden egységet minden egységgel
összekapcsoljuk: - egyirányú kapcsolat esetén: n*(n-1) vonal U3 U4 - kétirányú kapcsolat esetén: n*(n-1)/2 vonal • Előnyei: Igen gyors: elvben minden egység minden egységgel kommunikálhat párhuzamosan Megbízható: architekturális feltétele következtében pl. az U1 és U2 közötti kapcsolat megszakadása esetén a kommunikáció történhet az U3-on vagy U4-en keresztül is • Hátrányai Drága: nem annyira a vezeték, mind inkább az átviteli intelligencia biztosítása Új egységek kialakítása bonyolult A miniatürizálás miatt sok csatlakozó láb kialakítása technológiai nehézségekbe ütközik - 56 - 27-28. ea Created by mrjrm & Pogácsa = megosztott (shared) sín: U1 U2 Un • Jellemzői: Minden egység a közös sínen keresztül kommunikál egyidejűleg csak egy adó lehet • Előnyei: Viszonylag olcsó Szabványos kialakítása lévén új egységek csatlakoztatása egyszerű • Hátrányai:
Mivel egyidejűleg csak egyetlen adó használhatja a közös sínt, ezért viszonylag lassú A közös sínhasználat vezérlése bonyolult, nem olcsó Érzékennyé válik a rendszer a közös sín meghibásodására - funkcionális csoportosítás: • Címsín Feladata: az egységek (pl. hálózati kártya) valamint az egységek egy részének (pl memóriacím) azonosítása Fejlődése Intel processzorok esetén: 20 bit (1 Mb) 20 bit (1 Mb) 8088 80286 vezérlővezeték 16 Mb vezérlővezeték 4 bit vezérlővezeték 20 bit (1 Mb) 80386 vezérlővezeték 4 bit vezérlővezeték 8 bit vezérlővezeték - a fokozatos bővítés nem eredményez tiszta tervet - 57 - 20+4+8=32 bit 4Gb 27-28. ea • • Created by mrjrm & Pogácsa adatsín: feladata: adatok továbbítása fejlődése: - 8088: 8 vezeték - 80286: 16 vezeték - 80386: 32 vezeték - a fokozatos fejlesztés nem eredményezett tiszta tervet (lásd címsín) elfogadott megoldás,
hogy ugyanazon vezetékeken keresztül továbbítják a címeket és az adatokat: - ezzel egyrészt vezetékeket takarítanak meg - a csatlakozó lábak számát tudják csökkenteni - pl. PCI = időbeli multiplexelés, azaz ugyanazon vezetékeken átviszi a blokk kezdőcímét, majd ciklikusan az adatokat, közben inkrementálással állapítva meg a címet - ez a megoldás előnyös blokkos átvitelnél - szükséges egy olyan vezérlővonal, mely megmutatja, hogy a közös vezetéken adat vagy cím van vezérlő vezetékek: feladata: a vezérlési feladatok továbbítása számuk tipikusan: 10-15 fajtái: - adatátvitellel kapcsolatos vezérlővezetékek M/IO a címvezetéken memória-cím vagy I/O cím található R/W read/write: a processzor felől nézve az átvitel iránya B/W byte/word: párhuzamosan átvitt bitek száma AS address strobe: a cím a címsínre lett helyezve DS data strobe: az adat az adatsínre lett helyezve A/D address/data: a közös sínen most
éppen cím vagy adat van RDY ready – kész - megszakítással kapcsolatos vezérlővezetékek: megszakítás kérése és megszakítás engedélyezése - sínkezeléssel kapcsolatos vezérlővezetékek: sínhasználat kérése, sínfoglalás jelzése és sínhasználat engedélyezése - egyéb CLCK – órajel Reset – reset-jel - az összekapcsolt területek alapján M0 M1 bővítő-sín, vagy I/O sín, vagy helyi sín sínvezérlő CPU rendszersín, vagy memória-sín, vagy processzorsín - 58 - I/O0 I/On 27-28. ea • • Created by mrjrm & Pogácsa rendszersín feladata: a processzor-memória és a sínvezérlő forgalmának biztosítása jellemzői: - az átviteli sebessége napjainkban már sokszorosa a bővítő-sínénél - processzor közeli lévén a teljesítmény-növelés érdekében célszerű figyelembe venni az architekturális sajátosságokat: nem szabványosították sikerrel elnevezések: - rendszersín: a rendszer-forgalmat
továbbítja (cím, adat, vezérlősín) - memória-sín: a memória-elemeket köti össze - processzorsín napjainkban: = az adatok blokkos átvitel esetén a DMA vezérletével közvetlenül mennek a winchester és a memória között = a processzor a másodlagos gyorsítótárral kommunikál bővítő-sín feladata: az I/O egységek csatlakoztatása a processzor-memória kettőshöz története: - kezdetben összekábelezték az egységeket - DEC első gépei már sín-orientáltak voltak: csatlakozó helyeket alakítottak ki tesztelő készülékek csatlakoztatására. Szerzői joggal védték le - 1976: az Altair tervezője kialakította az S-100-as bővítő-sín szabványt, csatlakozóhelyenként 100 db érintkezővel. Ezt az IEEE szabványként fogadta el - 1981: az IBM PC megjelenése. - 59 -
számítási modellek (Prolog) Tudásalapú számítási modellek Hibrid van piaci megvalósítása egyre bonyolultabb kísérleti stádium Adatalapú számítási modellek Adat:- az adatokat típusokhoz rendeljük - az elemi adattípus esetében a típus meghatározza: = az adat értelmezési tartományát = az adat értékkészletét és = a rajta értelmezett műveletek halmazát Pl. integer típus: - értelmezési tartomány: - 32768 ÷ + 32767 - értékkészlet: kizárólag egész érték - műveletek: +, -, *, /, Neumann-féle számítási modell 1. Min hajtjuk végre a számítást? - adatokon - az adatokat változók képviselik - biztosított, hogy a változók korlátlan számban változtathassák értékeiket deklarált változók 2. Hogyan képezzük le a számítási feladatokat? - adatmanipuláló utasítások sorozatával deklarált változó adatmanipuláció -2- adatmanipuláló programutasítások 1-2. ea Created by mrjrm & Pogácsa 3. Mi vezérli a
végrehajtást? - az adatmanipulálások szekvenciája - az explicit vezérlésátadó utasítások utasítások PC - vezérlés-meghajtó (control-driver) - programnyelvek: Basic, Pascal, C, - architektúra: Neumann-féle architektúra Adatfolyam számítási modell 1. Min hajtjuk végre a számítást? - adatokon 2. Hogyan képezzük le a számítási feladatot? - a bemenő adatok halmazának értelmezésével és - adatfolyam gráffal = a csomópontok jelentik a műveletet = élek az adat input-outputot, azaz adat-utakat, ahol az adat közlekedik X Y pl. z = ( x + y ) * ( x – y ) + - * Z - míg a Neumann-féle modellben a példa 3 db utasítást igényel: - összeadás - kivonás - szorzás - addig az adatfolyam modellnél az összeadás és kivonás párhuzamosan végezhető, tehát példánkban 33%-os időmegtakarítást értünk el. -3- 1-2. ea Created by mrjrm & Pogácsa 3. Mi vezérli a végrehajtást? - adat Stréber modell 1. adat még nincs @ 2. az egyik
operandus rendelkezésre áll @ 3. mindkét operandus biztosított, műveletvégzés @ 4. az eredmény előállt @ Neumann-féle modell 1. 2. 3. Változók: közös operatív tár (program + adat) Adatmanipuláló utasítások Implicit szekvencia, explicit vezérlés-átadás adatfolyam számítási modell Egyszeres értékadás, az adattárolást a csomópontok végzik Adatfolyam - gráf Adat meghajtott, nincs PC, nincs szekvencia Programnyelvek: pl. Sigal Architektúra: The Manchester Dataflow Machine -4- 3-4. ea Created by mrjrm & Pogácsa Architektúra Fogalmak: -1964 Amdahl: Mindazon ismeretek összessége, amit egy alacsony szintű nyelven programozónak ismerni kell ahhoz, hogy hatékony programot írjon. Pl.: regiszterek, címzési módok, memória, utasításkészlet -1970: Bell: Szinteket rendel az architektúra fogalmához. - PMS (Processor, Memory, Switches) - Programozói szint o Magas szintű o Alacsony szintű - Logikai áramköri szint -
Áramköri szint Egyéb: - külső jellemző - a belső felépítés - és működés együttese Adott absztrakciós szinten ( L ) a számítási modell ( M ), a specifikáció ( S ) és az implementáció ( I ) együttese. = {M,S,I}L = logikai + fizikai Architektúra = külső + belső = absztrakt + konkrét = Instruction Set Architecture + Microarchitecture Logikai architektúra - logikai architektúra az adott absztrakciós szinten = {M,S}L adott absztrakciós szinten a fizikai architektúra megvalósítása adott absztrakciós szinten a fekete doboz külső jellemzőinek viselkedése A processzor-szintű logikai architektúra részei: - adattér - adatmanipulációs fa - állapottér - állapotműveletek Fizikai architektúra - fizikai architektúra az adott absztrakciós szinten = {M,I}L adott absztrakciós szinten a logikai architektúra megvalósítása adott absztrakciós szinten a fekete doboz belseje A processzor-szintű fizikai architektúra részei - műveletvégző -
vezérlő - memória - I/O rendszer - Sínrendszer - Megszakítási rendszer -5- 3-4. ea Created by mrjrm & Pogácsa Egy korszerű számítógép szintjei: - Alkalmazások (Pl. Word, Excel) ------------------------------------------------------------------------- Problémaorientált nyelv (Pl. Pascal, C) - Assembly szintű nyelvek (?) - Operációs rendszer gépi része (Operációs rendszerek) - Utasításrendszer architektúra (Architektúra) - Mikrotechnika (Architektúra) - Digitális rendszer szintje (Digitális technika) ------------------------------------------------------------------------- Áramköri szint (Elektronika) Logikai architektúra Adattér A processzor által manipulálható tér Adattér Memóriatér Regisztertér Nagyobb Lassabb Külső lapkán Olcsóbb Lehet közös az I/O címtérrel Kisebb Gyorsabb A processzor lapkáján Drágább Mindig önálló címtér Memóriatér • Tárolási kapacitása az egyik legfontosabb tulajdonsága •
Kétféle címtér o Modell címtere // ezt a címsín szélessége határozza meg o Implementáció címtere // alkalmazás igénye, ill. anyagi lehetőségek határozzák meg • A valós memória tárolási kapacitásának fejlődése: o 40-es évek: néhányszáz szó o 1950 IAS 10 bites címrész, vagyis 1024 címet címezhetett meg o 1964 IBM360 16Mbyte Virtuális tár • megjelenése: 1960, • elterjedése: az IBM370-es gépcsaládhoz köthető. Alapjellemzői • kétféle címtér o valós címtér o virtuális címtér Létezik olyan, a programozó számára transzparens mechanizmus, mely az éppen futó program számára nem szükséges program- és adatrészeket kiviszi a valós memóriatérből a virtuális memóriatérbe, majd amikor ezen adatok szükségessé válnak, visszaviszi a valós memóriatérbe. Létezik egy olyan, a programozó számára transzparens mechanizmus, mely a programozó által használt virtuális címeket a futási fázisban lefordítja valós
címekké. -6- 3-4. ea Created by mrjrm & Pogácsa Címtér Valós címtér Virtuális címtér Félvezető lapka Itt fut a program Sokkal kisebb Ezt látja a processzor Drágább Gyorsabb Háttértár Itt vár a program Sokkal nagyobb Ezt látja a programozó Olcsóbb Lassabb Az INTEL processzorcsalád címtere Típus Dátum Valós Virtuális 8086 80286 80386 1978 1982 1985 1 16 4096 1Gbyte 64Tbyte Regisztertér • egyszerű • adattípusonként különböző • többszörös Egyszerű • 40-es évek: egyetlen akkumulátor • 50-es évek: egyetlen akkumulátor+ dedikált regiszter + • 60-as évek: általános célú regiszterek • veremregiszter -7- 3-4. ea Created by mrjrm & Pogácsa Egyetlen akkumulátor Hátránya • szűk keresztmetszet • bizonyos műveleteknek két eredménye van és az egyik az operatív tárba szorul ⇒ lassú Egyetlen akkumulátor+ dedikált regiszter Előnye • hányados bevezetése gyorsította az osztást
Hátránya • drága és az esetek 95%-ban üresen áll Általános célú regiszter Előnye • Igen jó a regiszterek kihasználtsága • Új programozási stílus: igyekeznek regiszter - operandusokkal végezni a műveleteket Veremregiszter Előnye • Igen gyors • Implicit biztosítja a verem adatstruktúráját Hátránya • Mivel csak a verem tetejét látjuk ⇒ szűk keresztmetszet -8- 5-6. ea Created by mrjrm & Pogácsa Adattípusonként különböző regisztertér Célja: az adatfeldolgozás gyorsítása - különös tekintettel a lebegőpontos adatábrázolásra 1 8 mantissza előjele 23 karakterisztika mantissza 1964: IBM 360 lebegőpontos regiszterkészlet általános célú regiszterkészlet: fixpontos, karakteres, logikai típusú adatok feldolgozásra 1998: Pentium III (Katmai) általános célú regiszterkészlet Típus IBM 360 Intel 80386 IBM RISC 6000 Intel Pentium III lebegőpontos regiszterkészlet Megjelenés éve 1964 1985 1990 1998 MMX2
(Katmai) regiszterkészlet Általános célú Lebegőpontos Katmai regiszterkészlet regiszterkészlet regiszterkészlet 16*32 4*64 8*32 8*80 32*32 32*64 8*32 8*80 8*128 -9- 5-6. ea Created by mrjrm & Pogácsa Többszörös regiszterkészlet Háttér információ: - kontextus: = a regiszterek aktuális tartalma és = az állapot-információk (flag, PC, ) - megszakítás esetén le kell mentenünk az éppen futó program kontextusát, annak érdekében, hogy majd a programot folytatni lehessen - a többfeladatos és több felhasználós feldolgozásnál igen sok a megszakítás. Amennyiben a kontextust az operatív tárba mentjük ⇒ lassú Helyette: többszörös regiszterkészlet A többszörös regiszterkészlet tervezési tere több egymástól független regiszterkészlet átfedő regiszterkészlet stack-cache 1964: Sigma 7 1980: RISC I 1982: C-Machine Több egymástól független regiszterkészlet: - független folyamatoknál ideális, pl. I/O megszakítás -
paraméter-átadásos eljárásnál nem gyorsít, mivel a paraméterátadás a memórián belül történik Átfedő regiszterkészlet: INS LOCALS OUTS INS LOCALS OUTS INS LOCALS Jellemzői: - a hívó eljárás OUTS része fizikailag megegyezik a hívott eljárás INS részével - a regiszterek száma merev, viszonylag üres regiszterkészlet mellett is előfordulhat a túlcsordulás: ez a memória igénybevételével kerül feldolgozásra ⇒ lassul a feldolgozás OUTS - 10 - 5-6. ea Created by mrjrm & Pogácsa -a regiszterkészlet száma: = az ábrán látható, hogy 6-8 regiszterkészlet esetén már igen csekély %-os a túlcsordulás = a programozás módszertan sem ajánlja, hogy 8-nál több eljárást ágyazzunk egymásba Stack-cache: Ötvözi - a cache-veremszervezését és - a regiszterek közvetlen címezhetőségét Működése: - a compiler minden eljáráshoz hozzárendel egy változó hosszúságú aktiválási rendszert (regiszterkészletet) az előző
aktiválási rekord Aktuális aktiválási rekord előző SP Stack Pointer (SP) - a hívó eljárás OUTS része fizikailag megegyezik a hívott eljárás INS részével - az adott aktiválási rekordot az SP segítségével közvetlenül is elérhetjük - egy adatot is elérhetünk közvetlenül az SP és a relatív távolság megadásával - az aktiválási rekordok számának csak a stack-cache fizikai mérete szab határt - 11 - 5-6. ea Created by mrjrm & Pogácsa Adatmanipulációs fa Adattípusok: FX1 FX2 FX3 FX4 Műveletek: Operandusok: rrr + - * / Címzési módok (memória): R+D Gépi kód: r: regiszter m: memória D: displacement - eltolás rmr mmm PC+D RI+D . Az adatmanipulációs fa megmutatja, - a lehetséges műveletek halmazát - másrészt egy al-fája megmutatja egy konkrét implementáció műveleteinek halmazát Az ideális az lenne, ha minden processzor képes lenne az összes adattípus, művelet, operandustípus, és címzési mód
kezelésére. Ennek azonban akadályai vannak - a 80-as évekig: = technológiai korlát: a lapka mérete korlátozta a lehetőségeket általános célú lebegőpontos stb. cím zési m űvelet = gazdasági korlát: igen drága a hardver, ezért célkonfigurációk: - gazdasági célú: karakteres és BCD műveletek - műszaki-tudományos célú: lebegőpontos számítás - napjainkban: a technológiai fejlődés és az árak csökkenése eredményeképpen univerzális processzorok különféle műveletvégzőkkel. - 12 - 5-6. ea Created by mrjrm & Pogácsa Adattípusok Elemi Összetett (adatstruktúrák vagy adatszerkezetek) Az összetett adattípusok az elemi adattípusokból épülnek fel. - verem - sor - fa - tömb Elemi adattípusok Numerikus karakteres logikai . pixel Numerikus fixpontos lebegőpontos BCD Fixpontos adattípusok egyes komplemens kettes komplemens előjeles byte (8 bit) félszó (16 bit) . többletes előjel nélküli szó (32 bit)
duplaszó (64 bit) quadroszó (128 bit) Lebegőpontos normalizált hexára normalizál IBM egyszeres pontosságú 32 bit nem normalizált binárisra normalizál IEEE VAX kétszeres pontosságú 64 bit - 13 - kiterjesztett pontosságú 128 bit 5-6. ea Created by mrjrm & Pogácsa BCD pakolt EBCDIC zónázott ASCII szabványos kiterjesztett logikai karakter EBCDIC 1 bájt ASCII szabványos 2 bájt 4 bájt változó hosszúságú kiterjesztett Műveletek - pontosan kell a műveleteket definiálni, beleértve a kivételek kezelését is - 14 - 7-8. ea Created by mrjrm & Pogácsa Az utasítás-feldolgozás menete Egy gépi kódú utasítás általános formája: MK Címrész Mit? Mivel? MK = műveleti kód Az utasítás-feldolgozás nagyvonalú folyamatábrája: Megszakítás igen nem I. utasításlehívás (Fetch) A megszakítás feldolgozása II. Utasítás-végrehajtás (Execute) adatsín MAR: Memory Address Register Memória
címsín MDR: Memory Data Register MAR MDR Vezérlőegység PC IR DEC PC: Program Counter IR: Instruction Register DEC: Decoder általános célú regiszter ALU Processzor - 15 - ALU: AricmeticalLogical Unit 7-8. ea Created by mrjrm & Pogácsa I. Utasítás-lehívás A PC mindig a következő végrehajtandó utasítás címét tartalmazza MAR MDR IR PC PC (MAR) MDR PC+1 Az utasítás lehívás minden utasítás esetén megegyezik. II. Utasítás-végrehajtás - adatbehívás (load) DEC IR MAR IR PC DEC címrész MDR PC+1 - aritmetikai-logikai utasítás, pl. összeadás DEC IR MAR MDR AC AC AC AC DEC címrész (MAR) AC + MDR vagy AC – MDR vagy AC * MDR vagy AC / MDR - adattárolás (store) DEC IR MAR MDR (MAR) DEC címrész AC MDR - a feltételes ugrás DEC IR PC DEC címrész - 16 - 7-8. ea Created by mrjrm & Pogácsa Az utasítások fajtái (utasítás-típusok) MK Címrész op – operandus s – Source (forrás) d – destination
(cél) @ - tetszőleges művelet 4 címes utasítás: - opd := ops1 @ ops2 , op4 d s1 s2 op4 - a 4. operandus a következő végrehajtandó utasítás címét tartalmazta Hátránya: = memóriapazarlás = további adatrögzítési hibák = merev program-struktúra ⇒ nehéz a karbantartása - Pl. ENIAC 3 címes utasítás: - opd := ops1 @ ops2 - az eredmény helyének explicit deklarálása - előnye: = az előző utasítás eredményének mentésével párhuzamosan tölthetjük az aktuális utasítás két bemenő operandusát. - hátránya: = Neumann szerint tipikusan az előző művelet eredménye a következő művelet egyik bemenő operandusa - Pl. RISC 2 címes utasítás - ops1 := os1 @ ops2 ops2 := ops1 @ os2 - pl. ADD[100],[102] - előnye: = kevesebb tárhelyet igényel (regiszter v. memória) = kielégíti a Neumann féle követelményt - Pl. IBM 360/370, Intel processzorokban; - 17 - 7-8. ea Created by mrjrm & Pogácsa 1 címes utasítás Pl - be kell
tölteni az egyik operandust az akkumulátorba LOAD[100] - az összeadó utasításban lévő operandust hozzáadjuk az AC-hoz és az eredmény az AC-ban keletkezik ADD[102] - az AC tartalmát kimentjük STORE[100] Az utasítások maguk rövidebbek, de több utasításra van szükség Pl. 1951 1AS – ötvenes-hatvanas években fordultak elő ilyen architektúrák 0 címes utasítás - fajtái = NOP – no operation = a műveleti kód tartalmazza az operandust is, pl. CLEARD ⇒ a Dflag törlése = verem-műveletek PUSH, POP Napjaink trendje 3 címes utasítások a RISC gépekben, mindhárom cím regiszterre mutat. 2 címes utasítások a mai CISC gépeket jellemzik: - általában az első operandus helyén keletkezik az eredmény - általában nem engednek meg 2 memória-operandust Operandus-típusok akkumulátor (a) memória (m) regiszter (r) verem (stack - s) immediate (i) immediate: magában a programban adunk értéket a változónak ⇒ a gyakorlatban ez bemenő operandus
Architektúrák szabályos akkumulátor a-r aar memória a-m ara kombinált(pl. a+m) - a mai CISC processzorok 2 címes regiszter 3 címes 2 címes aam ama m1m1m2 m2m1m2 m1m2m3 r1r1r2 - 18 - verem 3 címes r2r1r2 SSS r1r2r3 7-8. ea Created by mrjrm & Pogácsa Akkumulátor - előny: gyors rövid cím - hátrány: szűk keresztmetszett - napjainkban nem aktuális Memória - előny: nagy címtér - hátrány: lassú hosszú cím ⇒ hosszú utasítás - napjainkban nem aktuális Regiszter - előny igen gyors rövid cím - napjainkban RISC gépekben Verem - előny: gyors 0 hosszúságú cím - hátrány: szűk keresztmetszett - Pl. HP 3000, VT 1005 - 19 - 9-10. ea Created by mrjrm & Pogácsa Gépi kód Minden architektúra esetén más. Állapottér a felhasználó számára látható a felhasználó számára transzparens virtuális memória PC állapotjelzők CC állapot-indikátorok CC - Condition Code - 2 bites ⇒ négy érték felvétele - IBM
360 megszakítások verem . egyéb, a felhasználó számára látható állapotformáció adattípusonként különböző állapot-indikátorok nyomkövetés (debug) indexelés állapot-indikátorok (flag): - minden helyiérték saját jelentéssel bír, pl. negatív, nulla, túlcsordulás adattípusonként különböző állapot-indikátorok: - minden regiszterkészlet típushoz hozzárendelnek külön állapot-indikátor készletet, pl. az általános célú processzorhoz tartozó flag-eken kívül a lebegőpontos processzorhoz is hozzárendelnek külön flag-készletet. - a lebegőpontos flag-készlet eseményei pl. alul-, túlcsordulás, denormalizált szám, 0 Megszakítás esetén történő mentés: - IBM 370 ⇒ PSW ⇒ Program Status Word ⇒ megszakításkor a PSW-t mentették - kontextus: = a regiszterek aktuális értékei és = az állapottér aktuális értékei (flag, PC) - megszakítás esetén a kontextus kerül lementésre Állapotműveletek flag - save
(mentés) - load (visszatöltés) - set (beállítás) - clear (törlés) - reset (kezdeti értékkel beállítás) PC - inkrementálás - felülírás egy utasításból vett címmel - 20 - 9-10. ea Created by mrjrm & Pogácsa A processzorszintű architektúra Processzor = műveletvégző + vezérlő Szinkron-aszinkron - Szinkron: = egy elektronikus óra meghatározott időnként órajelet generál = minden elemi művelet órajelre kezdődik órajel az elemi műveletek t holtidő = hátránya: az elemi műveletek különböző ideig tartanak ⇒ holtidőt eredményez = előnye: az elektronikus óra és az órajel vezetése egyszerű és olcsó - Aszinkron: = minden elemi művelet befejeződése egyben jelzés a következő elemi művelet elkezdésére az előző művelet befejeződése az előző művelet befejeződésének érzékelése és a következő elemi művelet kezdete = az elemi művelet befejeződésének érzékelése időt vesz igénybe ⇒ időveszteség = az
elemi művelet befejeződésének érzékelője bonyolult, drága A ma piacon lévő processzorok szinkron vezérlésűek ~3GHz frekvenciával Műveletvégző egység Részei: - Regiszterek - Adat utak - Kapcsolópontok - Szűk értelemben vett ALU Regiszterek - a felhasználó számára látható (amire a programozó hivatkozni tud) – ezt vizsgáltuk a logikai architektúrában - rejtett regiszterek az adat feldolgozási technológiához szükséges puffer regiszterek - 21 - 9-10. ea Created by mrjrm & Pogácsa Adat utak - a memóriához való hozzáférést a vezérlő rész kezeli. A műveletvégzőben tehát nem értelmezett a címek kezelése ⇒ ezért adatút r0 r1 r2 . . rn Általános célú regiszterkészlet ADD r0r1r2 src0 r0 ⇐ r1 @ r2 Az utasítás végrehajtás hipotézise: src0 ⇐ r1 src1 ⇐ r2 rslt ⇐ src0 @ src1 r0 ⇐ rslt src1 adatút ALU rslt - az src0, az src1 és a rslt rejtett regiszterek Kapcsolópontok - a sín megosztott eszköz ⇒
egy időben csak egyetlen adó lehet U1 U2 U3 . Un kapcsolópontok közös sín - a kimenő kapu 3 állású: =0 =1 = zárva - a bemenő kapu 2 állású: =nyitva =zárva - a kapcsolópontok architekturálisan általában a regiszterek részét képezi - 22 - 9-10. ea Created by mrjrm & Pogácsa Szűk értelemben vett ALU lebegőpontos - összeadás - kivonás - szorzás - osztás -multimédia fixpontos - összeadás - kivonás - szorzás - osztás - multimédia BCD - összeadás egyéb - logikai - léptetés Fixpontos összeadás - mivel a kivonást, a szorzást és az osztást az összeadásra vezetjük vissza, ezért a sebesség meghatározó Egybites fél-összeadó A Jelölése: A 1 B S ∑/2 C 1 B Igazságtáblázat: 0 S 1 összeg (Sum-S) átvitel (Carry-C) A 0 0 1 1 Logikai függvények felírása: S=A⊕B C = AB Megvalósítás: A B ⊕ & S C Hátránya: - nem kezeli a bejövő Carry-t - 23 - B 0 1 0 1 S 0 1 1 0 C 0 0 0 1
9-10. ea Created by mrjrm & Pogácsa Egybites teljes összeadó - kezeli a bejövő átvitelt A S ∑ B Carry Out Carry In - megvalósítása 2 db fél-összeadóval CIn A ∑/2 ∑/2 B S 1 COut Tervezése: 1, Az igazságtábla felírása A 0 0 0 0 1 1 1 1 B 0 0 1 1 0 0 1 1 Cin 0 1 0 1 0 1 0 1 S 0 1 1 0 1 0 0 1 Cout 0 0 0 1 0 1 1 1 2, logikai függvények felírása (Cin ⇒ C) Cout: nABC + AnBC + ABnC + ABC 3, Azonos átalakítások a következő célfüggvényekkel - az elemszám minimalizálásával - a végrehajtási idő minimalizálásával Felhasznált azonosságok: ABC = ABC + ABC + ABC nA + A = 1 Cout = nABC + AnBC + ABnC + ABC +ABC +ABC = (nA + A)BC + (nB + B)AC + + (nC+C)AB = BC + AC + AB /ii/= AB + (A + B)Cin /i/ i: - 4db elem - 20% megtakarítás - Ha 1 elem késleltetése d, akkor T = 3d ii: - 33% időmegtakarítás - T = 2d - 24 - 11-12. ea Created by mrjrm & Pogácsa N – bites soros összeadó Megjelenésének oka: a
számítógépben a számokat tipikusan n - bit hosszúságú regiszterben tárolják ⇒ ezek tartalmát kell összeadni. Megvalósítása: S A ∑ B Cin Cout 1 Késleltető vagy tároló Jellemzői: - az eredmény az első operandus (A) helyén képződik - az A és a B léptető regiszter - a Cout esetén biztosítani kell, hogy az előző bithelyiértéken képződő átvitel az aktuális bithelyiérték összeadásakor érkezzen be. Erre szolgál a tároló vagy késleltető elem. - a bejövő átvitel (Cin) csak az első bithelyiérték esetén vesszük figyelembe. Értékelése: Ha az egybites teljes összeadó végrehajtási idejét t, akkor az n - bit összeadási ideje: T = n*t. Gyorsítás: - t csökkentése: igen gyors egybites teljes összeadó alkalmazása. - csökkentsük az n értékét egyre oly módon, hogy minden bithelyiértékhez hozzárendelünk egy egybites teljes összeadót ⇒ n - bites párhuzamos összeadó. Megvalósítás: An Bn A2 B2 A1 B1 A0 B0
Cout ∑ Sn ∑ Cn C2 ∑ S2 C1 - 25 – ∑ S1 C0 Cin S0 11-12. ea Működése: I. A 0101 B 1010 1111 II. A 0101 B 1010 1.lépés 1110 2.lépés 1100 3.lépés 1000 4.lépés 0000 Created by mrjrm & Pogácsa Cin=0, Tmin=t ; Cin=1, Tmax = n*t ; C0=1 C1=1 C2=1 C3=1 Értékelése: - igen nagy befektetés árán (megtöbbszöröztük az egybites összeadók számát) - csupán hullámzó teljesítményt értünk el, mert meg kell várni az átvitel terjedését. Átvitel előrejelzés (Carry-Look-Ahead = CLA) Alapelve: Cout = A * B + (A + B) Cin Az egyes bithelyiértékeken képződő átvitel függ - a két bejövő összeadandótól és ez előre ismert - a kívülről bejövő átviteltől, de nem függ az egyes bithelyiértékeken képződő átviteltől. A * B ⇒ G (Generate) A + B ⇒ P (Propagate) Ci = Gi + Pi * Ci-1 C0 = G0 + P0 * Cin C1 = G1 + P1 * C0 = G1 + P1 G0 + P1 P0 Cin C2 = G2 + P2 * C1 = G2 + P2 G1 + P2 P1 G0 + P2 P1 P0 Cin C3 = G3 +
P3 * C2 = G3 + P3 G2 + P3 P2 G1 + P3 P2 P1 G0 + P3 P2 P1 P0Cin Értékelés: - minden átvitel meghatározásához szükség van = ÉS kapuk sorozatára és 2 fokozat = ezeket összekapcsoljuk VAGY kapuval - a P és G meghatározása további 1 fokozat ∑:3 fokozat Amennyiben egy fokozat késleltetése d, akkor az egyes bithelyiértéken képződő átvitel meghatározásának ideje: T=3d. Jelölések: Megvalósítás, pl C3 meghatározása előre A3 B3 A2 B2 1 P3 1 & & C3 & C2 & - 26 – 11-12. ea Created by mrjrm & Pogácsa Megvalósítási alternatívák 1. Katalógus áramkörökkel egybites teljes összeadó + CLA CLA An-1 Cout Bn-1 A2 ∑ B2 A1 ∑ Sn-1 C2 B1 A0 ∑ S2 C1 B0 ∑ S1 C0 Cin S0 2. Az egybites teljes összeadót kiegészítjük egy ÉS, és egy VAGY kapuval, hogy meghatározzuk a P és a G értékét. P G P ∑ G P ∑ G ∑ Cin S S S 3. A VAGY kapu bemeneteinek száma technológiai
korlátokba ütközik, ezért maximum 8 bit vonatkozásában építhető meg a CLA. 32 bit megvalósítási lehetősége CLA CLA CLA CLA Hátrány: a CLA egységek között az átvitel sorosan terjed. 4. CLA a CLA-k számára: CLA CLA CLA CLA - 27 – CLA Cin 11-12. ea Created by mrjrm & Pogácsa Fixpontos kivonás Alapelvek: - a fixpontos összeadáshoz hasonlóan megtervezhető = az 1 bites fél-kivonó = az 1 bites teljes kivonó - az alkalmazásának hátrányai: = a kivonó csak akkor ad bit helyes eredményt, ha a nagyobb számból vonjuk ki a kisebbet. Ehhez minden kivonás előtt komparálni kell ⇒ lassú = a kivonó megvalósítása megduplázza a műveletvégző elemszámát ⇒ a lapka mérete viszont korlátozott ⇒ nem célszerű Megvalósítása: a számok átkódolása, kivonás visszavezetése összeadásra. Hagyományos kivonás: A 13 1101 -B -(+7) 0111 X ezt másképpen végezzük Egyes komplemens A 13 0|1101 -B +(-7) 1|1000 X 6 10|0101 = +5 1
0110 = +6 Egyes komplemens meghatározása: - pozitív számé maga a szám - negatív szám esetén bitenként invertálunk Megvalósítás: A B invertáló Cout Cin - 28 – 13-14. ea Created by mrjrm & Pogácsa Kettes komplemens Meghatározása: - az egyes komplemenshez hozzáadunk egyet - a bináris számból hátulról leírjuk az összes nullát és az első egyest, és utána bitenként invertáluk. Pl. A A 13 0|1101 segédszámítás: 7=0111 => 1001–kettes komplemense - B +(-B) +(-7) 1|1001 X X +6 00110 = +6 Az ideális: tudjon összeadni is. TRANS egység kialakítása: Igazságtábla: Vezérlés B B’ 0 0 0 0 1 1 1 0 1 1 1 0 - kizáró vagy (XOR) - amennyiben a vezérlés nulla, akkor a B értékeit változatlanul átengedi, amennyiben 1, akkor bitenként invertál. Megvalósítás: B 0/1 vezérlés TRANS A B’ ∑ Cin X Szorzás/Osztás - minden műveletvégzőnek kell tudni = összeadni = invertálni = léptetni, de nem kell tudni
szorozni/osztani, mivel az felépíthető az említett három műveletből. - 29 - 13-14. ea Created by mrjrm & Pogácsa Architekturális megvalósítása a szorzás/osztásnak Régen: - olcsó processzor – gépi kódú programmal - közepes áru processzor – mikro programmal - drága processzor – hardveres úton valósították meg Napjainkban: - PowerPC 603 = kettő db műveletvégző az egyszerű fixpontos műveletekhez ( + , - ) = egy db műveletvégző az összetett fixpontos műveletekhez ( * , / ) - Pentium Pro fixpontos műveletvégzői = általános célú = léptető = egész osztó = összeadó / kivonó = szorzó = osztó Hagyományos szorzás Algoritmizált változat Léptetéssel X=A*B=13123 39 26 13 1599 13*123 0000 20 39 100 0039 260 299 1300 1599 13*123 0000 39 0039 26 299 13 1599 felveszünk egy gyűjtőt és kinullázzuk Az összeadás ciklus annyiszor fut, ahány helyiértékű a szorzó Bináris szorzás sajátosságai • A bináris szám
hossza Decimális Helyiértékek száma Pl.: 1 9 2 99 3 999 Bináris Helyiértékek száma 4 7 10 Konklúzió: a bináris számok hosszabbak, mint a decimális számok az összeadási ciklusok száma magasabb lesz - 30 - 13-14. ea • Created by mrjrm & Pogácsa A szorzat hossza Decimális helyiértékek száma A 1 2 2 B 1 1 2 X 2 3 4 Általános formában m n m+n Konklúzió: mivel a szorzandó és a szorzó is egy-egy regiszterben helyezkedik el, így a szorzat kettő regiszterben keletkezik. Pl.: a szorzat kisebb helyiértékű része a szorzó helyén képződik Legyen 3 helyiértékes a regiszterünk 1 1 2 3 9 1 2 9 9 1 5 9 9 Gyorsítás - bitcsoportokkal való szorzás = a léptetés nem egyesével, hanem csoportonként hajthatjuk végre ⇒ gyorsabb = Pl. 2-es bitcsoportok • 00 – kettőt léptetek balra • 01 – hozzáadom a szorzat egyszeresét, majd léptetek kettővel balra • 10 – hozzáadom a szorzat kétszeresét, majd léptetek
kettővel balra • 11 – hozzáadom a szorzat háromszorosát, majd léptetek kettővel balra Segédszámítás: a szorzandó kétszeresének meghatározása 7*9 = 63 0111 * 1001 0000 0111 1110 111111 = 63 A, összeadással: 0111 0111 1110 B, léptetéssel Booth – féle algoritmus =bináris számok esetén az összeadási ciklus annyiszor fut, amíg egyes van a szorzóban =Pl. *62 111110 5 db összeadás *64 *2 100000 000010 1 db összeadás 1 db összeadás 1 db kivonás 3 db összeadás helyette: - - 31 - 40%-os gyorsítás 13-14. ea Created by mrjrm & Pogácsa Hagyományos osztás: X=A/B=150/48 150 -48 102 -48 54 -48 60 -48 120 I. 3,1 Fixpontos osztás Geometriai értelmezés: 0,48 II. III. 0 50 4,8 I. 100 48 48 150 48 Hátrány: minden kivonás előtt kell komparálnunk ⇒ lassú Visszatérés a nullán át 150 -48 102 -48 54 -48 6 -48 -42 +48 60 -48 12 -48 -36 +48 120 I. 3,1 II. Geometriai értelmezés: III. 4,8 I. -50 I.
Visszatérés nélküli osztás X=11/6 11 I. 1,83 -6 5 10.lépés -6 -10 9.lépés +6 - 4 8.lépés +6 +20 I. -6 14 II. -6 8 III. -6 2 -6 -40 0 50 100 150 48 48 48 Előny: a kivonások előtti komparálások helyett csak flag-et vizsgálunk ⇒ gyors Hátrány: felesleges munkát végzünk a visszatérés során Geometriai értelmezés: 0,6 0,6 0 5 6 - 32 - 10 11 6 15-16. ea Created by mrjrm & Pogácsa Fixpontos multimédia műveletek Hangfeldolgozás A probléma: • A hang analóg jel • A digitális jelfeldolgozáshoz digitalizálnunk kell az ún. analóg-digitális átalakítóval (A/D konverter) +128 +64 0 -64 -128 t Amplitúdó vagy felbontás • Az analóg jel minimális és maximális értékéhez hozzárendeljük a számtartományunk minimális és maximális értékét Lehetőségek: • 8 bit 256 féle lehetőség • 16 bit 65536 féle lehetőség Mintavétel: Pl.: 50 kHz 1 másodperc alatt 50000 mintát veszünk Alkalmazás kHz Telefon
8 Audio CD 44 DVD 48 Minőségi DVD 96 A tárigény meghatározása: • 1sec: Audio CD 2*2(sztereo)16(bites)=4400022= 176000 byte/sec ~ 170 kbyte/sec • 1min tárigénye: 60*170 ~ 10 Mbyte/perc Feladat: nagy tömegű fixpontos adat tárolása, továbbítása és feldolgozása Pixeles képfeldolgozás A probléma megfogalmazása: Felbontás: • • Egy fénykép vagy festmény analóg jelekből áll; fények, árnyékok, színek folyamatos átmenetei A képre helyezett mátrix egy pontját pixelnek nevezzükminél sűrűbben helyezkednek el a pixelek, annál tökéletesebb a kép leképzése - 33 - 15-16. ea • Created by mrjrm & Pogácsa Pl.: o 800*600 o 1024*768 o 1280*1024 Képpont, vagy pixel • a pixeleket 3 színből (RGB) építhetjük fel, tehát minden képponthoz 3 kódot kell hozzárendelni • az egyszerűsítés érdekében ezeket önálló kódértékekkel látták el: kódsor kód o 000 0 o 001 1 Lehetőségek • 1 bit = két érték; sötét, vagy
világos • 1 bájt = 8 bit 256 féle szín • 2 bájt = 16 bit 65536 féle szín (High-Color) • 3 bájt = 24 bit 224 féle szín (True-Color) • 4 bájt = ún. alfa csatorna az effektek számára; pl: átlátszóság mértéke Képméret 1 bájt 2 bájt 800*600 480 Kbyte 960 Kbyte 1280*1024 1,3 Mbyte 2,6 Mbyte Feladat: nagy tömegű fixpontos adat tárolása, továbbítása és feldolgozása Megoldás: • a tárolási és továbbítási probléma tömörítéssel oldható meg • feldolgozás o 2 kép összeadása beolvassuk az első kép első bájtját az akkumulátorba hozzáadjuk a második kép első bájtját az eredmény az akkumulátorban keletkezik az eredmény átvivése az akkumulátorból a memóriaterületre ez a ciklus 800*600-as képnél 480 ezerszer fut le SIMD – Single Instruction Multicle Data o az Intel 1997-ben vezette be az ún. MMX feldolgozást (Matrix Math eXportion) o pakolt adattípus 64 bites a belső sín szélessége
64 bit db Hossza(bit) Pakolt byte 8 64 Pakolt félszó 4 64 Pakolt szó 2 64 • műveletképzés SIMD esetében, pakolt byte alkalmazásával A + + + + + + + = = = = = = = B ~ 8-szoros sebességnövekedés X - 34 - 15-16. ea • • Created by mrjrm & Pogácsa logikai architektúra o a négy alapművelet és a logikai műveletek vonatkozásában új utasítások mind a 3 alaptípusra fizikai architektúra o annak érdekében, hogy ne kelljen újabb regisztereket kialakítani, az MMX utasítások a lebegőpontos regisztereket használják fizikailag o egy év múlva már nem egy, hanem kettő MMX műveletvégzőt integrált az Intel a processzoraiba Lebegőpontos műveletek A lebegőpontos ábrázolás kialakulásának oka: A fixpontos ábrázolás hátrányai • szűk értelmezési tartomány. Pl: integer esetén: - 32768 ÷ + 32767 • a tört számok pontatlan ábrázolása o Ha a kettedes pontot a regiszter végébe tesszük, akkor pl. 7/4=1 A lebegőpontos
ábrázolás kiküszöböli ezeket a hátrányokat • A számokat hatványkitevős formában ábrázolja M : mantissza ±M*r+k r : radix (számrendszer alapja) k: karakterisztika Története • 1933 Konrad Zusen a Zuse 3-ban alkalmazta • Neumann: ellenezte, mivel a számok maguk hosszúak, memóriaigényesek, a számítás velük bonyolult összetett vezérlőrészt igényelt nem javasolta használatát A hetvenes évek főbb vonulatai • UAX • Cray • IBM 370/390 1985-ben az IEEE szabványosította. Jellemzői radix • A megállapodás szerinti architektúrán belül állandó • Tipikusan kettő • IBM 370/390 esetén 16 Nem normalizált • 123,567*100=0,1234567103=12345,6710-1 ezt a formátumot az architektúrák tipikusan nem alkalmazták A normalizált formátum • képlettel 1/r ≤M<1 • szövegesen: a törtpontot az első értékes számjegy elé helyezzük • pl.: ½ ≤ M < 1 ; 1/10 ≤ M < 1; + n fenn van tartva a végtelen jelölésére -
0,999*10+n-1 -0,1*10-n +0,1*10-n + 0,999*10+n-1 0 overflow underflow Felhasználható régió - 35 - overflow 15-16. ea Created by mrjrm & Pogácsa over- underflow • underflow esetén következmény o kijelzi o vagy nullát, vagy denormalizált számot ábrázol • overflow o kijelzi o vagy a lehető legnagyobb számot, vagy előjeles végtelent ábrázol denormalizált szám a denormalizált számok ábrázolását a mai architektúrák többsége lehetővé teszi 0 0,04 0,1 17-18.ea Értelmezési tartomány A karakterisztika helyiértékeinek száma Pl. Tízes számrendszer Konklúzió 1 9 9 Függ a karakterisztika 2 999 helyiértékeinek száma 1 Kettes számrendszer Függ a számrendszer alapjától milliárd 2 1 Pontosság = ha a regiszterünk mantissza része 3 helyiértékes, akkor 0,3456 mantisszát csak 0,345-ként tudjuk felírni. Pl 106 karakterisztika esetén 600-zal torzul az eredmény = tehát a pontosság függ a mantissza
helyiértékeinek számától A 0 körüli számok = amennyiben a mantissza értéke nulla, akkor az architektúrától elvárt, hogy a karakterisztika is nulla legyen Rejtett bit ½≤M<1 0,111010 = mivel a kettedes pont utáni első értékbitnek nincs információ tartalma, hanem kötelezően egyesnek kell lennie, ezért • a memóriába vagy a háttértárra való kiírás előtt ezt a bitet balra léptetik, s jobbról beléptetünk egy értékes bitet ⇒ ily módon egy helyiértékkel megnöveljük a mantissza hosszát ⇒ növekszik a számpontosság • amikor egy lebegőpontos számot betöltünk az operatív tárból vagy a háttértárról, akkor legelőször visszaállításra kerül a rejtett bit, hiszen a számításnál szükség van rá a rejtett bitet már alkalmazta a Zuse is (1933) a rejtett bitet minden mai piacon lévő processzor használja - 36 - 15-16. ea Created by mrjrm & Pogácsa Őrző bitek = a processzoron belül, mind a
lebegőpontos regiszterek mantissza része, mind a műveletvégző 4-6 bittel hosszabb, mint a tárolási formátum ⇒ ezek az őrző bitek = az őrző bitek felhasználása: • a rejtett bit helyén történő léptetésekor jobbról értékes bitet lehet beléptetni • a tárolási formátum kérésekor kerekített értéket írhatunk ki⇒pontosabb • az eredmény normalizálásakor jobbról értékes bitet tudunk beléptetni = minden mai piacon lévő architektúra alkalmazza az őrző biteket mantissza kódolása = a mantisszát az architektúrák 2-es komplemens formában ábrázolják karakterisztika kódolása = a karakterisztika kódolása többletes kód • a többletes kód kialakítása gyorsabb, mint a 2-es komplemens • mivel a karakterisztikával csak + , - és léptetés műveleteket kell végrehajtani – ez a többletes kód esetében is elvégezhető – ezért alkalmazzák. = minden ma piacon lévő architektúra esetén ezt a megoldást alkalmazzák - 37 -
17-18. ea Created by mrjrm & Pogácsa IEEE 754-es lebegőpontos szabvány - 1977-ben kezdték a kidolgozását - célja: a lebegőpontos számok adat-szintű portabilitásának megteremtése - minden architektúrából összegyűjtötték a legjobb megoldásokat - rendszerszinten gondolkoztak, azaz nem írták elő, hogy mit kell megvalósítani hardver- és mit szoftverszinten - a szabvány fejezetei: = formátumok = műveletek = kerekítések = kivételek formátumok szabványos egyszeres kiterjesztett kétszeres pontosság egyszeres kétszeres pontosság = szabványos - kiterjesztett: • a szabványos az operatív tárban illetve a háttértáron használt tárolási formátum • a kiterjesztett a processzoron belüli feldolgozási formátum • a tárolási a rövidebb, a feldolgozási a hosszabb • a szabványost szigorúbb szabályokkal rögzítették • a kiterjesztett esetén maximális szabadságot biztosítottak a gyártóknak = szabványos: • Kizárólag
az egyszeres pontosság a kötelező, a kétszeres pontosság opcionális • Egyszeres pontosság: Gyorsabb futás Kisebb memóriaigény Kevésbé pontos az eredmény • Kétszeres pontosság: Lassabb futás Nagyobb memóriaigény Pontosabb eredmény • A kétféle formátum között a programozó dönt • Egyszeres pontosság 32-bites formátum 38 38 Értelmezési tartománya: ~-10± ÷ +10± 1 8 23 mantissza előjele karakterisztika mantissza • Kétszeres pontosság 64-bites formátum 308 308 értelmezési tartomány: ~-10± ÷ +10± 1 11 55 - 38 - 17-18. ea Created by mrjrm & Pogácsa = kiterjesztett formátum = kizárólag a processzoron belül használják = egyszeres pontosság ⇒ min 43 bit hosszú (32+11(őrzőbit)) = kétszeres pontosság ⇒ min 79 bit hosszú (64+15(őrzőbit)) - műveletek - min. a 4 aritmetikai művelet - maradékképzés - négyzetgyökvonás - bináris, decimális konverzió = értelmezett a
végtelennel való műveletvégzés is pl.(3+(+∞))=+∞ (3+(-∞))=-∞ - kerekítések = a legközelebbi felé történő kerekítés (mint a hagyományos kerekítés, pl. 83,4 ⇒ 83) = a pozitív végtelen felé = a negatív végtelen felé • az utóbbi kettő az intervallumalgebrához kapcsolódik • kétszer hajtják végre a számításokat: egyszer a pozitív végtelen felé egyszer a negatív végtelen felé • az eredmény a két kapott eredmény között helyezkedik el • amennyiben a két eredmény közti intervallum a számítási igényünk szempontjából túl nagy, akkor elemezni kell a feladat megnevezését illetve a számítási algoritmust = levágja vagy trunc (pl. 83,9⇒83) - kivételkezelés: = nullával való osztás = overflow = underflow = négyzetgyök negatív számból - 39 - 17-18. ea Created by mrjrm & Pogácsa Esettanulmányok Intel processzorcsalád: = 1981-ben az Intel 8087-es processzorban valósul meg először
1985-ben megjelent IEEE 754-es szabvány - Logikai architektúra: = a radix 2 = underflow esetén denormalizált számot ábrázol = overflow esetén előjeles végtelen ábrázolása = létezik a rejtett bit = léteznek az őrző bitek = a mantissza 2-es komplemens = karakterisztika többletes kódolású = a szabályos formátumok közül megvalósításra került, mind az egyszeres, mind a kétszeres pontosság = a kiterjesztett formátum 80 bit hosszú 1 15 64 - a programozó dönti el, hogy ebből a formátumból egyszeres vagy kétszeres formában íratja ki - Fizikai architektúra: = az Intel 8087-es társprocesszor volt, mivel nem fért rá a 8088-as lapkára technikai okok miatt - hasonló elvű 80287 és a 80387 is - 80486DX ⇒ a miniatürizálás eredményeképpen már közös lapkán helyezkedi el a lebegőpontos és az általános célú processzor = teljesítményjellemző: Processzor Sebesség Relatív MIPS 80386 25MHz ~17 80486 66MHz ~1700 Pentium 133MHz ~6000 •
relatív MIPS: az eredeti 1981-ben megjelent IBM PC teljesítménye=1 • a 100-szoros növekedés annak köszönhető, hogy hardveres úton valósították meg a lebegőpontos műveleteket • a 3-szoros növekedés a futószalag bevezetésének eredménye - 40 - 19-20. ea Created by mrjrm & Pogácsa Műveletek lebegőpontos számokkal Példa Összeadás A=0,90*103 0,09104 B=0,95*104 0,95104 1,04*104 0,104105 X=A+B A=±mA*r±kA B=±mB*r±kB Algoritmus • A kitevőket megvizsgáljuk: csak azonos kitevőjű számok adhatók össze. • Amennyiben a kitevők nem egyenlők, akkor o A kisebb kitevőjű szám mantisszájának törtpontját balra léptetjük, és közben inkrementáljuk a karakterisztika értékét o A ciklus addig fut, amíg a kitevők meg nem egyeznek. • Mantisszákat összeadjuk, karakterisztikákat változatlanul hagyjuk • Normalizálás szükség esetén Szorzás X=A*B=(mA)(mB)rkA+kB Algoritmus • A mantisszákat összeszorozzuk,
karakterisztikákat összeadjuk Osztás X=A/B=(mA)/(mB)*rkA-kB Algoritmus • Mantisszákat elosztjuk, karakterisztikákat kivonjuk egymásból Megvalósítás Univerzális végrehajtó egység • Általános célú ALU parciálásával (részekre bontásával) karakterisztika • mantissza A vezérlőrész bonyolítását eredményezi ALU Szervezési megoldás o Külön elvégezzük a műveleteket a mantisszán és a karakterisztikán külön regiszterekben tárolódnak műveletvégzés közben, majd a művelet után közös regiszterekben egyesítjük. - Dedikált Adatsín Kar. Mantissza Vezérlő - 41 - 19-20. ea Created by mrjrm & Pogácsa Dedikált jellemzői • Míg a mantissza egységnek szorozni/osztani is kell tudni, a karakterisztika egységnek elég összeadni/kivonni • A mantissza és a karakterisztika egység párhuzamosan is működhet, ekkor a mantissza egység jelenti a szűk keresztmetszetet a szorzás/osztás miatt, tehát azt kell igen
gyors végrehajtásúra tervezni. Lebegőpontos, vektorgrafikus multimédia műveletek Probléma megfogalmazása A vonalakkal, görbékkel határolható objektumok geometriailag definiálhatók. Elegendő geometriai jellemzőit tárolni Példa: • Egyenes: kettő pontjának koordinátája • Kör: középpont koordinátája és a sugár hossza 2D jellemzői • A tárolt geometriai koordináta alapján a számítógép számítja ki magát az objektumot • A képletet tipikusan sokszögekre, háromszögekre bontjuk, melyek száma jellemzően képenként ~20000 • Az egyes objektumok közötti átmenet érdekében a képre textúrát helyezünk. Műveletek • Kicsinyítés • Nagyítás • Forgatás • Kitöltés színnel • Több objektum csoportosítása/lebontása Feladat • Viszonylag kevés lebegőpontos adaton sok művelet végrehajtása 3D jellemzői • Plusz egy harmadik dimenzió • A természetes hatás érdekében biztosítják a párhuzamosoknak
végtelenbeli összefutását és egy atmoszférikus kiegészítéssel a közeli tárgyak élesek, távoliak elmosódottak. • Jellemző a 3D filmek alkalmazása o Annak érdekében, hogy folyamatosnak érzékeljük, min 15 frame/sec sebesség kell. Számítások száma: 20000*15=300000 objektum/sec (mostanság ez az érték már inkább többmillió/sec) Feladat • Viszonylag kevés lebegőpontos adaton igen sok művelet végrehajtása adott idő alatt. Megoldás az Intel processzoroknál • 1998: MMX2 vagy KNI (Katmai New Instruction) Elve: SIMD 8 db. 128 bites új regisztert vezettek be egyszerre 4 ill 2 db lebegőpontos szám • 1985 óta először bővült a regiszterkészlet az Intel processzorokban • egyszerre 4 ill. 2 db számon lehet lebegőpontos műveletet végezni + + + + • • = = = = 70 db. új utasítás Operációs rendszer módosítását is igényelte: Gondoskodni kellett az új regiszterek mentéséről. Először a Windows’98 biztosította - 42 -
19-20. ea Created by mrjrm & Pogácsa A lebegőpontos feldolgozás jellemzői • • a tudományos és vektorgrafikus műveletek esetében nélkülözhetetlen a technikai fejlődés és a fajlagos árcsökkenés eredményeképpen ma már minden processzorban hardveres úton valósítják meg BCD Megjelenésének oka: • Fixpontos ábrázolással a törtszámok pontatlanok • Lebegőpontos ábrázolással a mantissza-, karakterisztikaforma nem teljesen pontos. • A kettes komplemens esetében: 10-es számrendszerű számokat átszámítjuk kettesbe, majd vissza • BCD esetében decimális számrendszerből átkódoljuk a számokat kettesbe és vissza. Kódolás = egyértelmű megfeleltetés A BCD pontosabb ábrázolás Jellemzői • Ábrázolási forma o Zónázott Z BCD Z BCD Z BCD. Előjel BCD Egy byte két részre oszlik. Magas tetrád a zóna, kisebb tetrád a BCD. A zóna tipikusan nyomtatható karakterre egészíti ki a BCD számot ASCII esetén tipikusan
„3” és EBCDIC esetén tipikusan „F”. Általában nem lehet műveletet végezni a zónázott számokkal (IBM, VAX), de az Intel kivétel, nála lehet! o Pakolt Minden bájtban 2 db. tetrád helyezkedik el BCD BCD BCD BCD BCD • • • Pl.: Intelnél 10 db bájt hosszú, ahol Az első bájt első bitje az előjel A bájt többi bitje nem használatos A további kilenc bájt tartalmazza a BCD számokat Az értelmezési tartomány: (-9.99˙*1018) ÷ (+9.99˙*1018) jellemzően ezzel a formátummal végzik a műveleteket A szám hossza o Fix o Változó jelölni kell a hosszát is. Az előjel hossza o 4 bit – tipikusan a zónázott ábrázolásnál o 8 bit – tipikusan a pakolt ábrázolásnál Az előjel értéke o Érvénytelen tetrád A, C, E, F a pozitív B, D a negatív o A + és a – az ASCII kódja! - 43 - 21-22. ea Created by mrjrm & Pogácsa Összeadás BCD számokkal Ugyanúgy adjuk össze a BCD számokat is, mint a
binárisakat, csak - fel kell ismernünk az érvénytelen tetrádokat és - ezek esetén korrekciót kell végrehajtani. A, Az érvénytelen tetrádok felismerése A BCD számok Decimális BCD kód 0 0000 1 0001 2 0010 3 0011 4 0100 5 0101 6 0110 7 0111 8 1000 9 1001 A 1010 B 1011 C 1100 D 1101 E 1110 F 1111 Felismerésünk: - az első bithelyeiértéken 1-es áll ÉS - a második VAGY a harmadik bithelyiértéken is 1-es áll. Érvényes tetrádok B, Korrekció: az érvénytelen tetrádok esetén = kivonunk belőle 10-et és = lépünk egy 10-es átvitelt pl.: A 8 1000 +B +7 0111 X 15 1111 +(-10) 0110 5 1|0101 10-es átvitel Segédszámítás: 10D = 1010B = 0110kettes komplemens 5D - 44 - 21-22. ea Created by mrjrm & Pogácsa Megvalósítás: A3 1 Cout B3 A2 ∑ ∑/2 A1 ∑ S3’ & B2 C2 B1 A0 ∑ S2’ C1 ∑ S1’ C0 B0 Cin Összeadó fokozat S0 1 Érvénytelen tetrádokat felismerő fokozat ∑ ∑/2 Korrekció S3 S2 S1 A BCD
műveletvégzők megvalósítása - univerzális műveletvégzőben, a BCD-nek megfelelő vezérléssel - dedikált: külön BCD műveletvégző A BCD jelentősége: - előnye: pontosság - hátránya: = a komplexebb és ezért lassúbb műveletvégzés = a memória kihasználtság rosszabb, hiszen a 16-féle BCD számból csak kb. 60%-át, 10 félét használunk ⇒ a BCD számok hosszabbak, mint a binárisak Pl.: 12D = 1100B = 00010010BCD - 45 - 21-22. ea Created by mrjrm & Pogácsa Fixpontos, lebegőpontos, BCD ⇒ melyiket használjam? Fixpontos: - igen gyors a fixpontos műveletvégzés - a memória igény kisebb, mert többféle formátumot alkalmaz: 8, 16, 32, 64, 128 bites - a formátumok közül mindig a számunkra szükséges értelmezési tartománynak megfelelően válasszuk - egész számok esetén teljesen pontos az ábrázolás, pl. if a=1 csak fixpontos és BCD ábrázolás esetén adható ki, lebegőpontosnál nem - törtnél teljesen pontatlan (7/4=1)
Lebegőpontos: - akkor alkalmazzuk, amikor = a számunk értelmezési tartománya túllép a fixpontos által biztosítotton, ill. = törtszámok ábrázolási igénye esetén - a lebegőpontos ábrázolás a gyakorlatban kielégítő pontosságot biztosít - csak indokolt esetben alkalmazzuk a kétszeres pontosságot, mert lassúbb. BCD: - a lebegőpontos ábrázolás egy alternatívája a pontosabb BCD ábrázolás Az ALU egyéb műveletei - mind a 16 Boole-algebrai műveletre képes (Pl.: VAGY, ÉS, kizáró VAGY, NEM) - léptetés - invertálás - címszámítás: = korai gépekben az univerzális ALU végezte = később dedikált címszámító egység - karakteres műveletek tipikusan az általános célú műveletvégző által kerülnek végrehajtásra Vezérlőrész Fejlődése Futószalag Párhuzamos (decentralizált) vezérlés Szuperskalár Mikroprogramozott (vezérlés) Szekvenciális (centralizált) vezérlés huzalozott 1947 első elektronikus számítógép 1954
Wilkes 1963 CDC660 1967 t - a decentralizált vezérlés a huzalozott ill. mikroprogramozott vezérlési elemekből épül fel - 46 - 21-22. ea Created by mrjrm & Pogácsa Huzalozott vagy áramköri vezérlés Tervezése: - igazságtábla - logikai függvények - azonos átalakítások a következő célfüggvénnyel: = az elemszám minimalizálása (a lapkaméret korlátozott volta) = a végrehajtási idő minimalizálása - megvalósítás Hátrányai: - ember számára nehezen áttekinthető (az azonos átalakítása után, azok következtében) - merev nehezen módosítható (midig az igazságtáblázatból kell kiindulni) Előnyei: - igen gyors Megvalósítása MEMÓRIA MDR MAR IR PC DEC címsín Vezérelt objektum Elve: Ütemező CLOCK RESET Külső feltételek (flag-ek) Egy forrásregiszter tartalmát módosító áramkörön keresztül egy célregiszterbe vezetjük. Regiszter: - ALU ⇒ pl. AC, általános célú regiszterek - Memória ⇒ MAR, MDR -
Vezérlősín ⇒ IR, PC - I/O regiszterek ⇒ vezérlőkártyában - 47 - 21-22. ea Created by mrjrm & Pogácsa Módosító áramkörök: - inkrementálás - léptetés - invertálás - összeadás - stb. Működése: - a forrásregiszter kimenetét rákapuzzuk a módosító áramkör bemenetére - előírja a módosító áramkör számára, hogy milyen módosítást hajtson végre (pl. inkrementálás, léptetés, stb.) - a módosított áramkör kimenetét rákapuzza a célregiszter bemenetére Egy mai tipikus processzorban több száz vezérlési pont van. - 48 - 23-24. ea Created by mrjrm & Pogácsa & Pheenix Mikroprogramozott vezérlés 1954 Maurice Wilkes (University of Cambridge) Célja: - az ember számára áttekinthetővé tegye a vezérlést = mikroutasítások definiáltak, melyek meghatározott vezérlővonalat vagy vezérlővonalakat aktiválnak = mikroutasítások sorozata szolgál egy-egy gépi kódú utasítás végrehajtásának elemi
szintű vezérlésére = a hagyományos Neumann-féle „makroszámítógépen” belül értelmezünk egy „mikroszámítógépet”, mely saját mikroutasításkészlettel rendelkezik - a vezérlőrész rugalmassá, könnyen módosíthatóvá alakítása = a mikroprogram a mikroprogramtárban helyezkedik el, így az módosítható A Wilkes-féle modell Pl. add MK Címrész CM CMAR mikroutasítások CLOCK DEC 0001 0010 0011 0101 1001 00 01 02 S 03 04 Control mátrix C0 C1 C2 Cn AnA2 A1 A0 Vezérelt objektum Address mátrix CMAR – Control Memory Address Register CM – Control Memory S - feltétel Működése: A. Mikroutasítás szekvencia: 1. A feldolgozandó gépi kódú utasítás műveleti kód része - megfelelően kódolva - letöltésre kerül a CMAR-ba. Megfelelő kódolás: a CMAR-ba az adott gépi kódú utasítás végrehajtását elemi műveleti szinten vezérlő mikroprogram kezdő címe kerül. 2. Ez a CMAR-ból a DEC-be kerül, amely az adott című
mikroutasítást érvényes állapotba helyezi. 3. Az érvényesített mikroutasítás végrehajtása során - aktiválja a vezérlőmátrixban a kijelölt vezérlővonalakat, ezt bizonyos ideig kitartja, majd - az adott mikroutasítás címrészében lévő következő végrehajtandó mikroutasítás címét beírja a CMAR-ba 4. vissza a 2 pontra - 49 - 23-24. ea Created by mrjrm & Pogácsa & Pheenix B. Feltételes mikroutasítás végrehajtása - amennyiben feltételes ugrás mikroutasítás végrehajtása következik, akkor: = aktiválásra kerülnek a mikroutasítás által kijelölt vezérlőútvonalak, ezek egy bizonyos ideig kitartódnak, majd = az adott mikroutasítás címrészében lévő kettő db. cím közül a feltétel igaz vagy hamis voltától függően vagy az egyik vagy a másik cím kerül a CMAR-ba letöltésre Pl. Az ADD utasítás végrehajtása DEC IR MAR DEC címrész MDR(MAR) ACAC+MDR Egy korszerű mikro-utasítás felépítése:
Vezérlőrész feltétel kiválasztó mező ugrási cím - a feltétel kiválasztó mező : megmutatja, hogy a tesztelendő feltételek közül melyiket választjuk ki - ugrási cím: ugró mikroutasítás esetén, amikor a feltétel igaz erre a címre adódik át a vezérlés - a vezérlőrész: kijelöli melyik vezérlővonalakat kell aktiválni Egy korszerű mikro-vezérlő megvalósítása Külső feltételek MUX MPC Külső forrás inkrementálás MPC Mikro-Program Counter CM Control Memory CMDR Control Memory Data Register MUX Multiplexer CM CMDR DEC - 50 - 23-24. ea Created by mrjrm & Pogácsa & Pheenix Működése: A. Mikro-utasítás szekvencia 1. az MPC-ben lévő következő végrehajtandó mikroutasítás címe által meghatározott mikroutasítás a CM-ből eljut a CMDR-be 2. a CMDR-ben lévő mikroutasítás vezérlő része aktiválja a kijelölt vezérlővonalakat, és azt meghatározott ideig kitartja 3. az MPC tartalma inkrementálódik és
vissza az első pontra B. feltételes ugrási mikroutasítás -. amennyiben a CMDR-ben feltételes ugrási mikro-utasítás van, akkor = a vezérlő része aktiválja a kijelölt vezérlővonalakat, és azt meghatározott ideig kitartja = a feltétel kiválasztó mező által meghatározott külső feltétel tesztelésre kerül, és annak igaz vagy hamis voltától függően • vagy a mikroutasításban tárolt címmel felülíródik az MPC tartalma • vagy pedig az MPC tartalma inkrementálódik Megjegyzések: - míg a Neumann-féle „makroszámítógép” operatív tárában együtt tároljuk az adatokat és az utasításokat, s ezért szükség van külön PC-re, MAR-re - addig a mikroprogramozott vezérlő CM-jében csak mikroprogramozott utasítások vannak, ezért * amennyiben nincs szükség, lehetőség inkrementálásra, akkor CMAR-t használunk, * amennyiben szükséges az inkrementálás, akkor MPC-t. A mikro-utasítás hosszát meghatározó tényezők A probléma:
célszerű - régen a CM drága volt, takarékoskodni a - jelenleg a lapkán van méretével - a feltétel kiválasztó mező rövid - Címrész: A, a következő végrehajtandó utasítás címe - maga a mikroutasítás tartalmazza (Wilkes féle modell) - MPC alkalmazásával határozzuk meg (korszerű mikrovezérlő) B, Ugrási cím - kisebb az ugrási címtér, mint a CM címtere CM címtere Pl. 1024=210 CM Ugrás címtere Pl. 256=28 - külső forrásból töltjük fel - az ugrási cím ritkán van kihasználva, utasítás szekvenciák esetén hasznosítható vezérlő részként Ugrási cím - kétszintű mikroutasítás (pl. Motorola) 17 bit 68 bit Jelzőbit -cím vagy -vezérlőrész Megtakarítás: Több mutató is mutathat ugyanarra a hosszú vezérlőrészre (ezt ugyan csak egyszer tároljuk) - 51 - 23-24. ea Created by mrjrm & Pogácsa & Pheenix - vezérlőrész = horizontális mikroutasítás • hosszú mikroutasítások • csekély mértékű
kódolás • magas szintű párhuzamosság • pl. IBM 360, PDP 8, Motorola; • Esettanulmány o IBM 360 90 bit 21 vezérlőmező 21 db azaz 21 db, hardverileg egymástól független egységet kell vezérelni ⇒ maximum 21-szeres párhuzamosság érhető el 55.-57 bithelyiértékek vezérlik az ALU jobboldali bemenetét: azaz mely regisztereket kell rákapuzni 58.-61 bithelyiértékek írják elő az ALU számára, hogy milyen műveletet hajtson végre. A lehetőségek: bináris vagy BCD összeadás a bejövő és a kimenő átvitel különféle kezelésével. o PDP 8 a vezérlőrész 128 bit hosszú hipotézis: 27=128, azaz 7 biten kódoljuk le a 128 féle értéket. Ez az elve a vertikális mikroutasításnak. = vertikális mikroutasítás • rövidek • erős kódolás • csekély mértékű párhuzamosság • Pl. IBM 370, Intel processzorok • Esettanulmány: IBM 370 o a mikroutasítás a gépi kódú utasításra emlékeztet: Opcod =
napjaink gyakorlata DEC 1.cím 2.cím CM, címképzési információ négy bájt hosszú a címek tipikusa processzor-regisztert címeznek a címképzési információ emlékeztet a Wilkes-féle modellre DEC Vezérelt objektum • a gyakorlatban szükséges vezérlések horizontálisak, a ritkábban használtak tömörített formában helyezkednek el a vezérlőrészben, amit a dekóder old fel. - 52 - 25-26. ea Created by mrjrm & Pogácsa A mikroprogramok időzítése A mikroutasítások fajtái: - monofázisú mikroutasítások: a mikroutasítás végrehajtási ciklusa megegyezik az óraütemmel - polifázisú mikroutasítás: egy mikroutasítás több óraütem alatt hajtódik végre ⇒ egy mikroutasításban egy egész elemi műveleti szekvenciasort írhatunk elő = pl. R1 ← f(R0) - az elemi műveleti szekvencia 1. a mikroutaítás lehívása a CM-ből 2. az R0 kimeneti kapuját rávezetjük az „f” módosító áramkör bemenetére 3. előírjuk, hogy az
„f” módosító áramkör milyen módosítást hajtson végre 4. az f módosító áramkör kimenetét rákapuzzuk az R1 regiszter bemenetére mikroutasítási ciklus 1. Következtetés: mivel a huzalozott vezérlésnél nincs értelmezve a mikroutasítás lehívása, ezért a huzalozott vezérlés mindig gyorsabb, mint a mikroprogramozott 2. 31 4. t óraütem A mikroprogramozott vezérlés gyorsítása Amennyiben a mikroprogramozott vezérlés mellett döntöttünk, akkor a lehető leggyorsabb vezérlés érdekében horizontális mikroutasítást és igen gyors CM-t kell alkalmazni. - szervezési gyorsítási lehetőségek: prefetch azaz elő lehívás alkalmazása. 1. Amíg a vezérlés a CMDR0-ban lévő mikroutasítás alapján történik, azzal párhuzamosan lehívjuk a következő végrehajtandó mikroutasítást a CMDR1-be 2. A vezérlés most a CMDR1-ből fog történni, s ezzel párhuzamosan lehívjuk a következő CMDR0 CMDR1 végrehajtandó mikroutasítást a CMDR0-ba
CM DEC Vezérelt objektum - 53 - 25-26. ea Created by mrjrm & Pogácsa Megjegyzés: • Általában egy vezérlővonalon egy óraütem alatt aktív • Abban az esetben, ha bizonyos vezérlésre hosszabb ideig van szükség – pl. adatátvitel esetén -, akkor a vezérlőrészt egy regiszterbe mentik, s onnan tartják ki a vezérlést. Ezt maradékvezérlésnek (residnal control) nevezzük. Mikroprogramozás: - a mikroprogram utasításai numerikus kódok az assembly szintű nyelvekre emlékeztet - létezik mikroassembler, azaz fordítóprogram, mely a forrás nyelvű mikroprogramot végrehajtó formátumra fordítja ⇒ az utóbbi tölthető be a CM-ba - a mikroprogramozás igen mély hardverismeretet igényel. Ezt a szintet a gyártók tipikusan nem publikálják. - a mikroprogram hiba következményei: = a hardverműködés képtelenné válik (nem segít a Reset) = az operációs rendszer lefagy Huzalozott kontra mikroprogramozott Sebesség Mindig gyorsabb Mindig
lassabb Áttekinthetőség Ember számára nem Ember számára áttekinthető áttekinthető Módosíthatóság Merev, nehézkesen Mikroprogramcsere lévén módosítható cserélhető Sínrendszer (Buszrendszer) Bevezetés: - a sínrendszer az egységek közötti kommunikációra szolgál - maga a sínrendszer a kommunikáció infrastrukturális része, később önálló I/O rendszerként tárgyalni fogjuk a perifériáknak a processzorral, ill. a memóriával való kapcsolatának sajátosságait - a sínrendszer egy történelmi fejlődés eredménye ⇒ ez bizonyult a legjobbnak - az egységek egymással kizárólag a sínrendszeren keresztül kommunikálnak, mégpedig szervezett, egységes módon - pl. Falu1 Falu2 Hegy Út - 54 - 25-26. ea Created by mrjrm & Pogácsa Kommunikáció fajtái: - Egységen belüli kommunikáció (pl. a processzoron belül) = kicsik a távolságok ⇒ a késleltetés elhanyagolható = egy központi óraütemadó vezérli mind az adót,
mind a vevőt viszonylag egyszerű megvalósítás - Egységek közötti kommunikáció (pl. a processzor és a perifériák között) = viszonylag nagyok a távolságok, jelentős a késleltetés = jelentősek az optimális sebességek közti különbségek az egyes egységek vonatkozásában (pl. más az optimális sebessége a processzornak és más a billentyűzetnek) nem célszerű a központi óraütemadó alkalmazása = szabványosítása • a processzor-memória közötti sínen szintén lehetetlen és értelmetlen • a perifériák esetében már jelenhetnek meg szabványok (pl. PCI) - 55 - 27-28. ea Created by mrjrm & Pogácsa A sínrendszer fogalma: - műszaki: olyan vezetékrendszer, melynek minden egyes erén = vagy csak a logikai nullának megfelelő 0V = vagy a logikai egyesnek megfelelő 12V; 5V; 3,3V; 2,8V - funkcionális: olyan vezetékköteg, mely biztosítja, hogy a forrásból a célba egyidejűleg, azaz párhuzamosan n db. bit juthasson el Ebben a
kontextusban (értelmi összefüggésben) a sín alatt nem csupán a vezetékeket értjük, hanem = a sínfoglalást, valamint = az adatátvitelt biztosító intelligenciát is. Jellemzői: - vezetékek száma vagy sínszélesség - napjainkban tipikusan megosztott (shared) eszköz: = minden vezetéke egy időpillanatban csak egy bitnyi információt továbbít = minden időpillanatban vagy csak a logikai nullának, vagy csak a logikai egynek megfelelő feszültségszint lehet egy vezetéken databus ← r0 - regiszter-tulajdonsággal rendelkezik. Értelmezett a következő: r1 ← databus Fajtája - az adatátvitel szerint: = simplex: egyirányú = duplex: időben csak egyirányú (vagy az egyik vagy a másik irányba történhet az átvitel egyidejűleg) = full duplex: egy időben kétirányú forgalom - pl. egyirányú: órajel, reset, címvonal; kétirányú: adatvonalak; - az átvitel jellege szerint: = dedikált: • Jellemzői: U1 U2 Minden egységet minden egységgel
összekapcsoljuk: - egyirányú kapcsolat esetén: n*(n-1) vonal U3 U4 - kétirányú kapcsolat esetén: n*(n-1)/2 vonal • Előnyei: Igen gyors: elvben minden egység minden egységgel kommunikálhat párhuzamosan Megbízható: architekturális feltétele következtében pl. az U1 és U2 közötti kapcsolat megszakadása esetén a kommunikáció történhet az U3-on vagy U4-en keresztül is • Hátrányai Drága: nem annyira a vezeték, mind inkább az átviteli intelligencia biztosítása Új egységek kialakítása bonyolult A miniatürizálás miatt sok csatlakozó láb kialakítása technológiai nehézségekbe ütközik - 56 - 27-28. ea Created by mrjrm & Pogácsa = megosztott (shared) sín: U1 U2 Un • Jellemzői: Minden egység a közös sínen keresztül kommunikál egyidejűleg csak egy adó lehet • Előnyei: Viszonylag olcsó Szabványos kialakítása lévén új egységek csatlakoztatása egyszerű • Hátrányai:
Mivel egyidejűleg csak egyetlen adó használhatja a közös sínt, ezért viszonylag lassú A közös sínhasználat vezérlése bonyolult, nem olcsó Érzékennyé válik a rendszer a közös sín meghibásodására - funkcionális csoportosítás: • Címsín Feladata: az egységek (pl. hálózati kártya) valamint az egységek egy részének (pl memóriacím) azonosítása Fejlődése Intel processzorok esetén: 20 bit (1 Mb) 20 bit (1 Mb) 8088 80286 vezérlővezeték 16 Mb vezérlővezeték 4 bit vezérlővezeték 20 bit (1 Mb) 80386 vezérlővezeték 4 bit vezérlővezeték 8 bit vezérlővezeték - a fokozatos bővítés nem eredményez tiszta tervet - 57 - 20+4+8=32 bit 4Gb 27-28. ea • • Created by mrjrm & Pogácsa adatsín: feladata: adatok továbbítása fejlődése: - 8088: 8 vezeték - 80286: 16 vezeték - 80386: 32 vezeték - a fokozatos fejlesztés nem eredményezett tiszta tervet (lásd címsín) elfogadott megoldás,
hogy ugyanazon vezetékeken keresztül továbbítják a címeket és az adatokat: - ezzel egyrészt vezetékeket takarítanak meg - a csatlakozó lábak számát tudják csökkenteni - pl. PCI = időbeli multiplexelés, azaz ugyanazon vezetékeken átviszi a blokk kezdőcímét, majd ciklikusan az adatokat, közben inkrementálással állapítva meg a címet - ez a megoldás előnyös blokkos átvitelnél - szükséges egy olyan vezérlővonal, mely megmutatja, hogy a közös vezetéken adat vagy cím van vezérlő vezetékek: feladata: a vezérlési feladatok továbbítása számuk tipikusan: 10-15 fajtái: - adatátvitellel kapcsolatos vezérlővezetékek M/IO a címvezetéken memória-cím vagy I/O cím található R/W read/write: a processzor felől nézve az átvitel iránya B/W byte/word: párhuzamosan átvitt bitek száma AS address strobe: a cím a címsínre lett helyezve DS data strobe: az adat az adatsínre lett helyezve A/D address/data: a közös sínen most
éppen cím vagy adat van RDY ready – kész - megszakítással kapcsolatos vezérlővezetékek: megszakítás kérése és megszakítás engedélyezése - sínkezeléssel kapcsolatos vezérlővezetékek: sínhasználat kérése, sínfoglalás jelzése és sínhasználat engedélyezése - egyéb CLCK – órajel Reset – reset-jel - az összekapcsolt területek alapján M0 M1 bővítő-sín, vagy I/O sín, vagy helyi sín sínvezérlő CPU rendszersín, vagy memória-sín, vagy processzorsín - 58 - I/O0 I/On 27-28. ea • • Created by mrjrm & Pogácsa rendszersín feladata: a processzor-memória és a sínvezérlő forgalmának biztosítása jellemzői: - az átviteli sebessége napjainkban már sokszorosa a bővítő-sínénél - processzor közeli lévén a teljesítmény-növelés érdekében célszerű figyelembe venni az architekturális sajátosságokat: nem szabványosították sikerrel elnevezések: - rendszersín: a rendszer-forgalmat
továbbítja (cím, adat, vezérlősín) - memória-sín: a memória-elemeket köti össze - processzorsín napjainkban: = az adatok blokkos átvitel esetén a DMA vezérletével közvetlenül mennek a winchester és a memória között = a processzor a másodlagos gyorsítótárral kommunikál bővítő-sín feladata: az I/O egységek csatlakoztatása a processzor-memória kettőshöz története: - kezdetben összekábelezték az egységeket - DEC első gépei már sín-orientáltak voltak: csatlakozó helyeket alakítottak ki tesztelő készülékek csatlakoztatására. Szerzői joggal védték le - 1976: az Altair tervezője kialakította az S-100-as bővítő-sín szabványt, csatlakozóhelyenként 100 db érintkezővel. Ezt az IEEE szabványként fogadta el - 1981: az IBM PC megjelenése. - 59 -
